Dominando la Interpretabilidad del Modelo Un Análisis Integral de los Gráficos de Dependencia Parcial
'Dominando la Interpretabilidad del Modelo Análisis Completo de los Gráficos de Dependencia Parcial'
Comenzando tu viaje en el mundo de la IA interpretable.
Saber cómo interpretar tu modelo es esencial para entender si no está haciendo cosas extrañas. Cuanto más conozcas tu modelo, menos probabilidades tendrás de sorprenderte por su comportamiento cuando se ponga en producción.
Además, cuánto más dominio tengas sobre tu modelo, mejor podrás venderlo a tu unidad de negocio. Lo peor que puede suceder es que se den cuenta de que en realidad no estás seguro de lo que les estás vendiendo.
Nunca he desarrollado un modelo en el que no se me haya pedido explicar cómo se realizaron las predicciones dadas las variables de entrada. Como mínimo, declarar a la empresa qué características contribuyeron positiva o negativamente fue esencial.
Una herramienta que puedes utilizar para entender cómo funciona tu modelo es el Gráfico de Dependencia Parcial (PDP), que exploraremos en esta publicación.
- People Analytics es lo nuevo y grande, y aquí te explicamos por qué debes conocerlo.
- Esta Investigación de IA Explica los Rasgos de Personalidad Sintéticos en los Modelos de Lenguaje de Gran Escala (LLMs)
- Aprendiendo Transformers Code First Parte 1 – La Configuración
¿Qué es el PDP?
El PDP es un método de interpretación global que se centra en mostrarte cómo se relacionan los valores de las características de tu modelo con la salida de tu modelo.
No es un método para entender tus datos, solo genera ideas para tu modelo, por lo que no se puede inferir una relación causal entre el objetivo y las características a partir de este método. Sin embargo, te permite hacer inferencias causales sobre tu modelo.
Esto se debe a que el método sondea tu modelo, por lo que puedes ver exactamente qué hace el modelo cuando cambia la variable de la característica.
Cómo funciona
En primer lugar, el PDP nos permite investigar solo una o dos características a la vez. En esta publicación, nos vamos a centrar en el caso de análisis de una sola característica.
Después de que tu modelo esté entrenado, generamos un conjunto de datos de sondeo. Este conjunto de datos se crea siguiendo el siguiente algoritmo:
- Seleccionamos cada valor único para la característica en la que estamos interesados
- Para cada valor único, hacemos una copia de todo tu conjunto de datos, estableciendo el valor de la característica en ese valor único
- Luego, utilizamos nuestro modelo para hacer las predicciones para este nuevo conjunto de datos
- Finalmente, calculamos el promedio de las predicciones del modelo para cada valor único
Veamos un ejemplo. Digamos que tenemos el siguiente conjunto de datos:

Ahora, si queremos aplicar el PDP a la Característica 0, repetiremos el conjunto de datos para cada valor único de la característica, como este:

Luego, después de aplicar nuestro modelo, tendremos algo como esto:

Entonces, calculamos la salida promedio para cada valor, obteniendo el siguiente conjunto de datos:

Entonces, solo se trata de trazar estos datos con un gráfico de línea.
Para problemas de regresión, es fácil calcular la salida promedio para cada valor de característica. Para métodos de clasificación, podemos usar la probabilidad predicha para cada clase y luego promediar esos valores. En este caso, tendremos un PDP para cada par de característica y clase en nuestro conjunto de datos.
Interpretación matemática
La interpretación del PDP es que estamos marginalizando una o dos características para evaluar su efecto marginal en la salida predicha del modelo. Esto se da mediante la fórmula:

Donde $f$ es el modelo de aprendizaje automático, $x_S$ es el conjunto de características que nos interesa analizar y $x_C$ es el conjunto de otras características sobre las cuales vamos a promediar. La función anterior se puede calcular utilizando la siguiente aproximación:
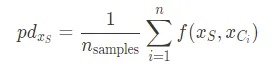
Problemas con el PDP
El PDP tiene algunas limitaciones de las cuales debemos ser conscientes. En primer lugar, dado que promediamos las salidas para cada valor de la característica, terminaremos con un gráfico que abarca todos los valores en el conjunto de datos, incluso si ese valor ocurre solo una vez.
Debido a eso, es posible que veamos algunos comportamientos en áreas muy poco pobladas de nuestro conjunto de datos que pueden no ser representativos de lo que ocurriría si ese valor fuera más frecuente. Por lo tanto, siempre es útil observar la distribución de una característica al ver su PDP para saber qué valores son más probables que ocurran.
Otro problema ocurre cuando tenemos una característica con valores que se cancelan entre sí. Por ejemplo, si nuestra característica tiene la siguiente distribución:

Al calcular el PDP para esta característica, terminaremos con algo como esto:

Observa que el impacto de la característica no es en absoluto cero, pero en promedio es cero. Esto puede llevarte a creer erróneamente que la característica no tiene utilidad cuando en realidad sí la tiene.
Otro problema con este enfoque es cuando la característica que estamos analizando está correlacionada con las características sobre las cuales estamos promediando. Esto se debe a que si tenemos características correlacionadas y obligamos a que cada valor del conjunto de datos tenga cada valor para la característica de interés, crearemos puntos poco realistas.
Imagina un conjunto de datos con la cantidad de lluvia y la cantidad de nubes en el cielo. Cuando promediamos los valores para la cantidad de lluvia, vamos a tener puntos que indican que hubo lluvia sin nubes en el cielo, lo cual es un punto poco factible.
Interpretando el PDP
Veamos cómo analizar un Gráfico de Dependencia Parcial. Observa la imagen a continuación:

En el eje x, tenemos los valores de la característica 0, en el eje y tenemos la salida promedio del modelo para cada valor de la característica. Observa que para valores menores a -0.10, el modelo produce predicciones de destino muy bajas, después de eso las predicciones aumentan y luego varían alrededor de 150 hasta que el valor de la característica supera 0.09, momento en el cual las predicciones comienzan a aumentar drásticamente.
Por lo tanto, podemos decir que existe una correlación positiva entre la característica y la predicción del destino, sin embargo, esta correlación no es lineal.
Gráficos ICE
Los gráficos ICE intentan resolver el problema de los valores de las características que se cancelan entre sí. Básicamente, en un gráfico ICE, trazamos cada predicción individual que el modelo hizo para cada valor, no solo su valor promedio.
Implementando el PDP en Python
Implementemos el PDP en Python. Para ello, primero vamos a importar las bibliotecas necesarias:
import numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdmfrom sklearn.datasets import load_diabetesfrom sklearn.ensemble import RandomForestRegressorVamos a utilizar el conjunto de datos de diabetes de sklearn. La biblioteca tqdm se utilizará para mostrar barras de progreso en nuestros bucles.
A continuación, vamos a cargar el conjunto de datos y ajustar un Regresor de Bosque Aleatorio a él:
X, y = load_diabetes(return_X_y=True)rf = RandomForestRegressor().fit(X, y)Ahora, para cada característica en nuestro conjunto de datos, vamos a calcular la predicción promedio del modelo para el conjunto de datos con esa característica fija en ese valor:
características = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
medias_características = {}
for característica in tqdm(características):
medias_características[característica] = ([], []) # Para cada valor único en la característica
for valor_característica in np.unique(X[:, característica]):
medias_características[característica][0].append(valor_característica)
# Removemos la característica del conjunto de datos
aux_X = np.delete(X, característica, axis=1)
# Agregamos el valor de la característica para cada fila del conjunto de datos
aux_X = np.hstack((aux_X, np.array([valor_característica for i in range(aux_X.shape[0])])[:, None]))
# Calculamos la predicción promedio
medias_características[característica][1].append(np.mean(rf.predict(aux_X)))
Ahora, trazamos el PDP para cada característica:
for característica in medias_características:
plt.figure(figsize=(5,5))
valores = medias_características[característica][0]
predicciones = medias_características[característica][1]
plt.plot(valores, predicciones)
plt.xlabel(f'Característica: {característica}')
plt.ylabel('Objetivo')
Por ejemplo, el gráfico para la Característica 3 es:

Conclusión
Ahora tienes otra herramienta en tu arsenal para utilizar y mejorar tu trabajo, y ayudar a la unidad de negocio a comprender qué está sucediendo con ese modelo de caja negra que les estás mostrando.
Pero no dejes que la teoría desaparezca. Toma un modelo que estés desarrollando actualmente y aplica la visualización de PDP. Comprende lo que el modelo está haciendo y sé más preciso en tus hipótesis.
Además, este no es el único método de interpretabilidad disponible. De hecho, tenemos otros métodos que funcionan mejor con características correlacionadas. Estén atentos a mis próximas publicaciones donde se cubrirán estos métodos.
Referencias
https://ethen8181.github.io/machine-learning/model_selection/partial_dependence/partial_dependence.html
https://scikit-learn.org/stable/modules/partial_dependence.html
https://christophm.github.io/interpretable-ml-book/pdp.html
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El diablo está en los detalles Conviértete en un campeón de Power BI pensando fuera de lo convencional.
- Evita estos 3 costosos errores y salva tus pruebas A/B.
- Intenciones de Código de IA
- ¿Cómo convertirse en un analista de datos sin experiencia?
- OpenAI desactiva la función Navegar con Bing en ChatGPT ¿Qué sucedió?
- Mejor Software Antivirus 2023
- Conoce a SAM-PT Un nuevo método de IA que amplía la capacidad del modelo Segment Anything (SAM) para rastrear y segmentar cualquier cosa en videos dinámicos.






