Dominando las Expresiones Regulares con Python
Dominando Expresiones Regulares Python

Introducción
Las expresiones regulares, o regex, son una herramienta poderosa para manipular texto y datos. Proporcionan un medio conciso y flexible para ‘coincidir’ (especificar y reconocer) cadenas de texto, como caracteres específicos, palabras o patrones de caracteres. Se utilizan regex en varios lenguajes de programación, pero en este artículo nos centraremos en el uso de regex con Python.
Python, con su sintaxis clara y legible, es un gran lenguaje para aprender y aplicar regex. El módulo re de Python proporciona soporte para operaciones de regex en Python. Este módulo contiene funciones para buscar, reemplazar y dividir texto en función de patrones especificados. Al dominar regex en Python, puede manipular y analizar eficientemente datos de texto.
- Pythia Un conjunto de 16 LLMs para investigación en profundidad
- Una guía completa sobre la arquitectura UNET | Dominando la segmentación de imágenes
- Un enfoque sistemático para elegir la mejor tecnología/proveedor versión MLOps
Este artículo lo guiará desde lo básico hasta las operaciones más complejas con regex en Python, brindándole las herramientas para manejar cualquier desafío de procesamiento de texto que se presente. Comenzaremos con coincidencias simples de caracteres, luego exploraremos coincidencias de patrones más complejos, agrupaciones y afirmaciones de búsqueda anticipada. ¡Comencemos!
Patrones básicos de regex
En su esencia, regex opera en el principio de coincidencia de patrones en una cadena. La forma más directa de estos patrones son las coincidencias literales, donde el patrón buscado es una secuencia directa de caracteres. Pero los patrones regex pueden ser más sutiles y capaces que una simple coincidencia literal.
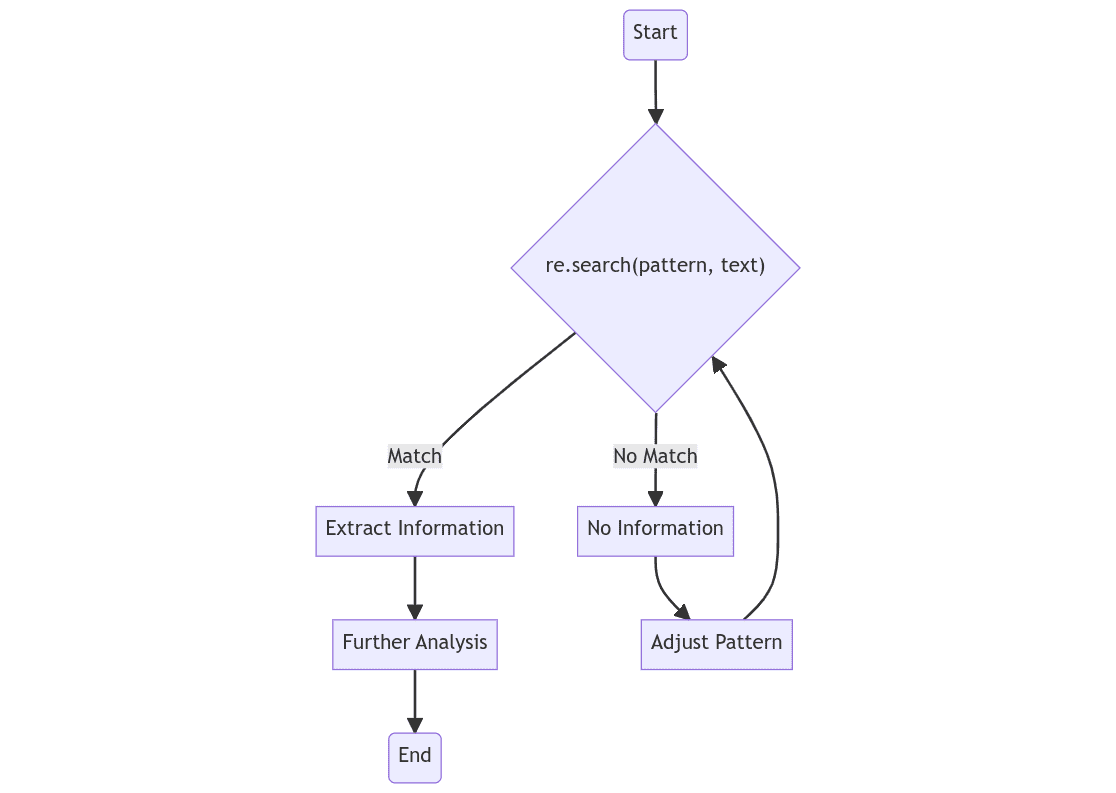
En Python, el módulo re proporciona un conjunto de funciones para manejar expresiones regulares. La función re.search(), por ejemplo, escanea una cadena dada en busca de cualquier ubicación donde se ajuste un patrón regex. Ilustremos con un ejemplo:
import re
# Definir un patrón
patrón = "Python"
# Definir un texto
texto = "¡Amo Python!"
# Buscar el patrón
coincidencia = re.search(patrón, texto)
print(coincidencia)
Este código de Python busca en la cadena en la variable texto el patrón definido en la variable patrón. La función re.search() devuelve un objeto Match si se encuentra el patrón dentro del texto, o None si no se encuentra.
El objeto Match incluye información sobre la coincidencia, incluida la cadena de entrada original, la expresión regular utilizada y la ubicación de la coincidencia. Por ejemplo, utilizando coincidencia.start() y coincidencia.end() se obtendrán las posiciones de inicio y fin de la coincidencia en la cadena.
Sin embargo, a menudo no solo buscamos palabras exactas, sino que queremos coincidir con patrones. Ahí es donde entran en juego los caracteres especiales. Por ejemplo, el punto (.) coincide con cualquier carácter excepto un salto de línea. Veamos esto en acción:
# Definir un patrón
patrón = "P.th.n"
# Definir un texto
texto = "¡Amo Python y Pithon!"
# Buscar el patrón
coincidencias = re.findall(patrón, texto)
print(coincidencias)
Este código busca en la cadena cualquier palabra de cinco letras que comience con una “P”, termine con una “n” y tenga “th” en el medio. El punto representa cualquier carácter, por lo que coincide tanto con “Python” como con “Pithon”. Como puede ver, incluso con solo caracteres literales y el punto, regex proporciona una herramienta poderosa para la coincidencia de patrones.
En las secciones siguientes, profundizaremos en patrones más complejos y características poderosas de regex. Al comprender estos elementos básicos, podrá construir patrones más complejos para coincidir con casi cualquier tarea de procesamiento y manipulación de texto.
Meta caracteres
Si bien los caracteres literales forman la base de las expresiones regulares, los meta caracteres amplifican su poder al proporcionar definiciones de patrones flexibles. Los meta caracteres son símbolos especiales con significados únicos, que dan forma a cómo el motor regex coincide con los patrones. Aquí hay algunos meta caracteres comúnmente utilizados y su significado y uso:
- . (punto) – El punto es un comodín que coincide con cualquier carácter excepto un salto de línea. Por ejemplo, el patrón “a.b” puede coincidir con “acb”, “a+b”, “a2b”, etc.
- ^ (acento circunflejo) – El símbolo de acento circunflejo denota el comienzo de una cadena. “^a” coincidiría con cualquier cadena que comience con “a”.
- $ (signo de dólar) – A la inversa, el signo de dólar corresponde al final de una cadena. “a$” coincidiría con cualquier cadena que termine con “a”.
- * (asterisco) – El asterisco denota cero o más ocurrencias del elemento anterior. Por ejemplo, “a*” coincide con “”, “a”, “aa”, “aaa”, etc.
- + (más) – Similar al asterisco, el signo más representa una o más ocurrencias del elemento anterior. “a+” coincide con “a”, “aa”, “aaa”, etc., pero no con una cadena vacía.
- ? (signo de interrogación) – El signo de interrogación indica cero o una ocurrencia del elemento anterior. Hace que el elemento anterior sea opcional. Por ejemplo, “a?” coincide con “” o “a”.
- { } (llaves) – Las llaves cuantifican el número de ocurrencias. “{n}” denota exactamente n ocurrencias, “{n,}” significa n o más ocurrencias y “{n,m}” representa entre n y m ocurrencias.
- [ ] (corchetes) – Los corchetes especifican un conjunto de caracteres, donde cualquier carácter único encerrado en los corchetes puede coincidir. Por ejemplo, “[abc]” coincide con “a”, “b” o “c”.
- \ (barra invertida) – La barra invertida se utiliza para escapar caracteres especiales, tratando efectivamente al carácter especial como un literal. “\$” coincidiría con un signo de dólar en la cadena en lugar de denotar el final de la cadena.
- | (barra vertical) – La barra vertical funciona como un O lógico. Coincide con el patrón antes o el patrón después de la barra vertical. Por ejemplo, “a|b” coincide con “a” o “b”.
- ( ) (paréntesis) – Los paréntesis se utilizan para agrupar y capturar coincidencias. El motor regex trata todo lo que está dentro de los paréntesis como un solo elemento.
El dominio de estos meta caracteres abre un nuevo nivel de control sobre tus tareas de procesamiento de texto, permitiéndote crear patrones más precisos y flexibles. El verdadero poder de las expresiones regulares se hace evidente a medida que aprendes a combinar estos elementos en expresiones complejas. En la siguiente sección, exploraremos algunas de estas combinaciones para mostrar la versatilidad de las expresiones regulares.
Conjuntos de caracteres
Los conjuntos de caracteres en las expresiones regulares son herramientas poderosas que te permiten especificar un grupo de caracteres que deseas encontrar. Al colocar los caracteres dentro de corchetes “[]”, creas un conjunto de caracteres. Por ejemplo, “[abc]” encuentra “a”, “b” o “c”.
Pero los conjuntos de caracteres ofrecen más que solo especificar caracteres individuales; brindan la flexibilidad de definir rangos de caracteres y grupos especiales. Veamos:
Rangos de caracteres: Puedes especificar un rango de caracteres utilizando el guión (“-“). Por ejemplo, “[a-z]” encuentra cualquier carácter alfabético en minúscula. Incluso puedes definir múltiples rangos dentro de un solo conjunto, como “[a-zA-Z0-9]”, que encuentra cualquier carácter alfanumérico.
Grupos especiales: Algunos conjuntos de caracteres predefinidos representan grupos de caracteres comúnmente utilizados. Estos son atajos convenientes:
- \d: Encuentra cualquier dígito decimal; equivalente a [0-9]
- \D: Encuentra cualquier carácter que no sea un dígito; equivalente a [^0-9]
- \w: Encuentra cualquier carácter alfanumérico (letra, número, guión bajo); equivalente a [a-zA-Z0-9_]
- \W: Encuentra cualquier carácter que no sea alfanumérico; equivalente a [^a-zA-Z0-9_]
- \s: Encuentra cualquier carácter de espacio en blanco (espacios, tabulaciones, saltos de línea)
- \S: Encuentra cualquier carácter que no sea un espacio en blanco
Conjuntos de caracteres negados: Al colocar un acento circunflejo “^” como el primer carácter dentro de los corchetes, creas un conjunto negado, que encuentra cualquier carácter que no esté en el conjunto. Por ejemplo, “[^abc]” encuentra cualquier carácter excepto “a”, “b” o “c”.
Veamos esto en acción:
import re
# Crea un patrón para un número de teléfono
patrón = "\d{3}-\d{3}-\d{4}"
# Define un texto
texto = "Mi número de teléfono es 123-456-7890."
# Busca el patrón
coincidencia = re.search(patrón, texto)
print(coincidencia)
Este código busca un patrón de un número de teléfono de EE.UU. en el texto. El patrón “\d{3}-\d{3}-\d{4}” encuentra cualquier combinación de tres dígitos, seguidos de un guion, seguidos de otros tres dígitos, otro guion y finalmente otros cuatro dígitos. Encuentra exitosamente “123-456-7890” en el texto.
Los conjuntos de caracteres y las secuencias especiales asociadas ofrecen un impulso significativo a tus capacidades de coincidencia de patrones, proporcionando una forma flexible y eficiente de especificar los caracteres que deseas encontrar. Al comprender estos elementos, estás en camino de aprovechar todo el potencial de las expresiones regulares.
Algunos Patrones Comunes
Aunque las expresiones regulares pueden parecer intimidantes, encontrarás que muchas tareas solo requieren patrones simples. Aquí hay cinco patrones comunes:
Correos Electrónicos
Extraer correos electrónicos es una tarea común que se puede hacer con expresiones regulares. El siguiente patrón encuentra la mayoría de los formatos de correo electrónico:
# Define un patrón
patrón = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
# Busca el patrón
coincidencias = re.findall(patrón, texto)
print(coincidencias)
Números de Teléfono
Los números de teléfono pueden variar en formato, pero aquí hay un patrón que encuentra números de teléfono de América del Norte:
# Define un patrón
patrón = r'\b\d{3}[-.\s]?\d{3}[-.\s]?\d{4}\b'
# Busca el patrón
...
Direcciones IP
Para encontrar una dirección IP, necesitamos cuatro números (0-255) separados por puntos:
# Definir un patrón
patrón = r'\b(?:\d{1,3}\.){3}\d{1,3}\b'
# Buscar el patrón
...
URLs Web
Las URLs web siguen un formato consistente que se puede emparejar con este patrón:
# Definir un patrón
patrón = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
# Buscar el patrón
...
Etiquetas HTML
Las etiquetas HTML se pueden emparejar con el siguiente patrón. Ten cuidado, ya que esto no capturará los atributos dentro de las etiquetas:
# Definir un patrón
patrón = r'<[^>]+>'
# Buscar el patrón
...
Consejos y Sugerencias
Aquí hay algunos consejos prácticos y mejores prácticas para ayudarte a usar las expresiones regulares de manera efectiva.
- Comienza de forma simple: Comienza con patrones simples y gradualmente agrega complejidad. Tratar de resolver un problema complejo de una sola vez puede ser abrumador.
- Prueba de forma incremental: Después de cada cambio, prueba tus expresiones regulares. Esto facilita la localización y solución de problemas.
- Usa cadenas en bruto: En Python, usa cadenas en bruto para los patrones de expresiones regulares (es decir, r”text”). Esto asegura que Python interprete la cadena literalmente, evitando conflictos con las secuencias de escape de Python.
- Sé específico: Cuanto más específica sea tu expresión regular, menos probable será que coincida accidentalmente con texto no deseado. Por ejemplo, en lugar de .*, considera usar .+? para coincidir con texto de manera no codiciosa.
- Usa herramientas en línea: Las herramientas en línea de prueba de expresiones regulares pueden ayudarte a construir y probar tus expresiones regulares. Estas herramientas pueden mostrar coincidencias en tiempo real, grupos y explicaciones para tu expresión regular. Algunas herramientas populares son regex101 y regextester.
- Legibilidad sobre brevedad: Aunque las expresiones regulares permiten un código muy compacto, puede volverse difícil de leer rápidamente. Prioriza la legibilidad sobre la brevedad. Usa espacios en blanco y comentarios cuando sea necesario.
Recuerda, dominar las expresiones regulares es un viaje y es en gran medida un ejercicio de ensamblaje de bloques de construcción. Con práctica y perseverancia, podrás enfrentar cualquier tarea de manipulación de texto.
Conclusión
Las expresiones regulares, o regex, son de hecho una herramienta poderosa en el arsenal de Python. Su complejidad puede ser intimidante a primera vista, pero una vez que te adentras en sus intrincados detalles, comienzas a darte cuenta de su verdadero potencial. Proporciona una robustez y versatilidad incomparables para manejar, analizar y manipular datos de texto, lo que la convierte en una utilidad esencial en numerosos campos como la ciencia de datos, el procesamiento del lenguaje natural, el web scraping y muchos más.
Una de las principales fortalezas de las expresiones regulares radica en su capacidad para realizar operaciones complejas de coincidencia y extracción de patrones en volúmenes masivos de texto con un código mínimo. Piensa en ello como un sofisticado motor de búsqueda que puede localizar no solo cadenas de texto precisas, sino también patrones, rangos y secuencias específicas. Esto le permite identificar y extraer piezas clave de información de datos de texto sin formato y no estructurados, lo cual es una necesidad común en tareas como la recuperación de información, la limpieza de datos y el análisis de sentimientos.
Además, la curva de aprendizaje de las expresiones regulares, aunque parezca empinada, no debería desanimar al aprendiz entusiasta. Sí, las expresiones regulares tienen su propia sintaxis única y caracteres especiales que pueden parecer crípticos al principio. Sin embargo, con un aprendizaje y práctica dedicados, pronto apreciarás su estructura lógica y elegancia. La eficiencia y el tiempo ahorrado en el procesamiento de datos de texto con regex superan con creces la inversión inicial de aprendizaje. Por lo tanto, el dominio de las expresiones regulares, aunque desafiante, brinda recompensas invaluables que lo convierten en una habilidad crítica para cualquier científico de datos, programador o cualquier persona que trabaje con datos de texto en su trabajo.
Los conceptos y ejemplos que hemos discutido aquí son solo la punta del iceberg. Hay muchos más conceptos de regex para explorar, como cuantificadores, grupos, aserciones de búsqueda y más. Así que continúa practicando, experimentando y dominando las expresiones regulares con Python. ¡Feliz codificación y emparejamiento de patrones!
Matthew Mayo (@mattmayo13) es un científico de datos y el editor en jefe de VoAGI, el recurso principal en línea de ciencia de datos y aprendizaje automático. Sus intereses se centran en el procesamiento del lenguaje natural, el diseño y optimización de algoritmos, el aprendizaje no supervisado, las redes neuronales y los enfoques automatizados del aprendizaje automático. Matthew tiene una maestría en ciencias de la computación y un diploma de posgrado en minería de datos. Puedes contactarlo en editor1 en VoAGI[punto]com.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 4 formas en las que no puedes usar el intérprete de código ChatGPT que perturbarán tus análisis
- Implementación de ParDo y DoFn en Apache Beam en Detalles
- Generando datos sintéticos con Python
- Todos los Modelos de Lenguaje Grande (LLMs) que Debes Conocer en 2023
- ¿Es bueno tu modelo? Un análisis en profundidad de las métricas avanzadas de Amazon SageMaker Canvas
- Esta semana en IA, 31 de julio de 2023
- AI Equipaje para Personas con Discapacidad Visual Recibe Excelentes Críticas






