Difusión estable XL en Mac con cuantificación avanzada de Core ML
Difusión estable XL en Mac con Core ML avanzado
Stable Diffusion XL fue lanzado ayer y es increíble. Puede generar imágenes de alta calidad grandes (1024×1024); se ha mejorado la adherencia a las indicaciones con algunos trucos nuevos; puede producir sin esfuerzo imágenes muy oscuras o muy brillantes gracias a las últimas investigaciones sobre programadores de ruido; ¡y es de código abierto!
La desventaja es que el modelo es mucho más grande, por lo que es más lento y más difícil de ejecutar en hardware de consumo. Usando la última versión de la biblioteca diffusers de Hugging Face, puede ejecutar Stable Diffusion XL en hardware CUDA en 16 GB de RAM de GPU, lo que permite usarlo en la capa gratuita de Colab.
Los últimos meses han demostrado que las personas están claramente interesadas en ejecutar modelos de ML localmente por diversas razones, como la privacidad, la comodidad, la experimentación más fácil o el uso sin límites. Hemos estado trabajando arduamente tanto en Apple como en Hugging Face para explorar este espacio. Hemos mostrado cómo ejecutar Stable Diffusion en Apple Silicon, o cómo aprovechar los últimos avances en Core ML para mejorar el tamaño y el rendimiento con paletización de 6 bits.
Para Stable Diffusion XL hemos hecho algunas cosas:
- Los desarrolladores buscan OpenUSD en la era de la IA y la digitalización industrial
- 3 prácticas emergentes para una IA generativa responsable
- INDIAai y Meta se unen Abren camino para la innovación y colaboración en IA
- Portamos el modelo base a Core ML para que puedas usarlo en tus aplicaciones nativas de Swift.
- Actualizamos el repositorio de conversión e inferencia de Apple para que puedas convertir los modelos tú mismo, incluyendo cualquier ajuste fino en el que estés interesado.
- Actualizamos la aplicación de demostración de Hugging Face para mostrar cómo usar los nuevos modelos Core ML Stable Diffusion XL descargados del Hub.
- Exploramos la paletización de bits mixtos, una técnica avanzada de compresión que logra reducciones importantes en el tamaño al tiempo que minimiza y controla la pérdida de calidad que se produce. ¡También puedes aplicar la misma técnica a tus propios modelos!
Todo es de código abierto y está disponible hoy, sigamos adelante.
Contenido
- Usando modelos SD XL desde el Hub de Hugging Face
- ¿Qué es la paletización de bits mixtos?
- ¿Cómo se crean las recetas de bits mixtos?
- Conversión de modelos ajustados
- Recursos publicados
Usando modelos SD XL desde el Hub de Hugging Face
Como parte de este lanzamiento, publicamos dos versiones diferentes de Stable Diffusion XL en Core ML.
apple/coreml-stable-diffusion-xl-basees un pipeline completo, sin cuantización.apple/coreml-stable-diffusion-mixed-bit-palettizationcontiene (entre otros artefactos) un pipeline completo en el que se ha reemplazado la UNet con una receta de paletización de bits mixtos que logra una compresión equivalente a 4.5 bits por parámetro. El tamaño se redujo de 4.8 a 1.4 GB, una reducción del 71%, y en nuestra opinión la calidad sigue siendo excelente.
Cualquier modelo se puede probar utilizando la aplicación de inferencia de línea de comandos Swift de Apple o la aplicación de demostración de Hugging Face. Este es un ejemplo de este último que utiliza el nuevo pipeline Stable Diffusion XL:
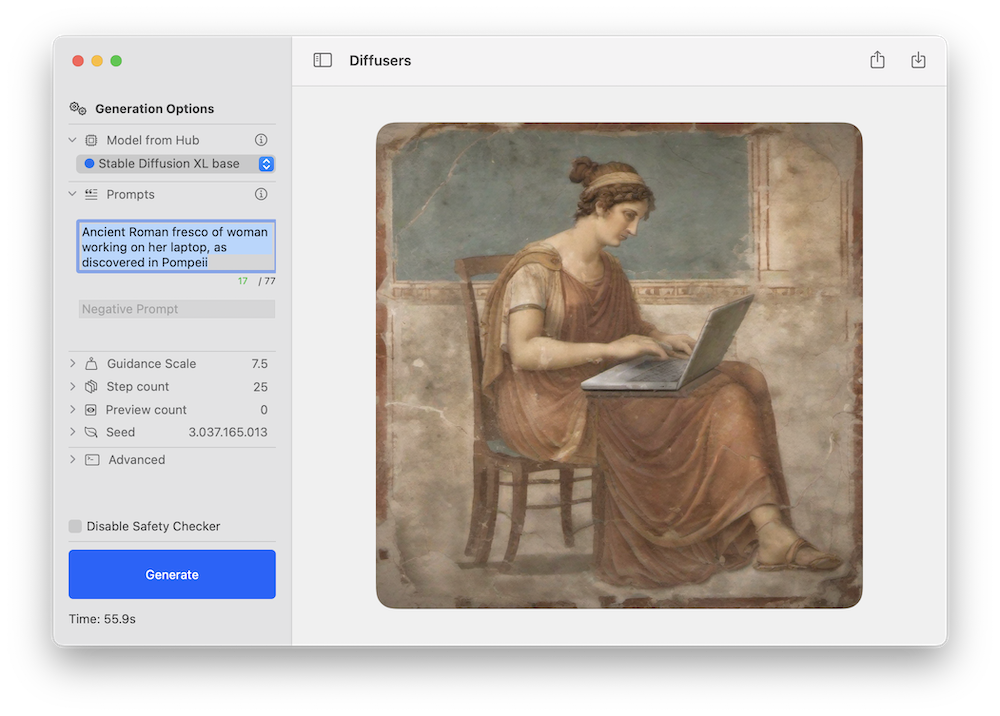
Como con las versiones anteriores de Stable Diffusion, esperamos que la comunidad desarrolle versiones ajustadas novedosas para diferentes dominios, y muchas de ellas se convertirán a Core ML. ¡Puedes estar atento a este filtro en el Hub para explorar!
Stable Diffusion XL funciona en Macs con Apple Silicon que ejecutan la beta pública de macOS 14. Actualmente utiliza la implementación de atención ORIGINAL, que está destinada a unidades de cálculo de CPU + GPU. Ten en cuenta que la etapa de refinamiento aún no se ha portado.
Para referencia, estos son los resultados de rendimiento que logramos en diferentes dispositivos:
¿Qué es la paletización de bits mixtos?
El mes pasado discutimos la paletización de 6 bits, un método de cuantización posterior al entrenamiento que convierte pesos de 16 bits a solo 6 bits por parámetro. Esto logra una reducción importante en el tamaño del modelo, pero ir más allá es complicado porque la calidad del modelo se ve cada vez más afectada a medida que se disminuye el número de bits.
Una opción para reducir aún más el tamaño del modelo es utilizar la cuantización en tiempo de entrenamiento, que consiste en aprender las tablas de cuantización mientras ajustamos el modelo. Esto funciona muy bien, pero debes ejecutar una fase de ajuste fino para cada modelo que desees convertir.
En su lugar, exploramos una alternativa diferente: paletización de bits mixtos. En lugar de utilizar 6 bits por parámetro, examinamos el modelo y decidimos cuántos bits de cuantización utilizar por capa. Tomamos la decisión en función de cuánto contribuye cada capa a la degradación general de calidad, que medimos comparando el PSNR entre el modelo cuantizado y el modelo original en modo float16, para un conjunto de entradas. Exploramos varias profundidades de bits, por capa: 1 (!), 2, 4 y 8. Si una capa se degrada significativamente cuando se utilizan, por ejemplo, 2 bits, pasamos a 4 y así sucesivamente. Algunas capas pueden mantenerse en modo de 16 bits si son críticas para preservar la calidad.
Utilizando este método, podemos lograr cuantizaciones efectivas de, por ejemplo, 2,8 bits en promedio, y medimos el impacto en la degradación para cada combinación que probamos. Esto nos permite estar mejor informados sobre la mejor cuantización a utilizar para nuestros objetivos de calidad y tamaño.
Para ilustrar el método, consideremos las siguientes “recetas” de cuantización que obtuvimos de una de nuestras ejecuciones de análisis (explicaremos más adelante cómo se generaron):
{
"model_version": "stabilityai/stable-diffusion-xl-base-1.0",
"baselines": {
"original": 82.2,
"linear_8bit": 66.025,
"recipe_6.55_bit_mixedpalette": 79.9,
"recipe_4.50_bit_mixedpalette": 75.8,
"recipe_3.41_bit_mixedpalette": 71.7,
},
}Lo que esto nos dice es que la calidad del modelo original, medida por PSNR en float16, es de aproximadamente 82 dB. Realizar una cuantización lineal de 8 bits ingenua la reduce a 66 dB. Pero luego tenemos una receta que comprime a 6,55 bits por parámetro, en promedio, manteniendo el PSNR en 80 dB. Las segunda y tercera recetas reducen aún más el tamaño del modelo, mientras aún mantienen un PSNR mayor que el de la cuantización lineal de 8 bits.
Para ejemplos visuales, estos son los resultados en la consulta una foto de alta calidad de un perro surfeando ejecutando cada una de las tres recetas con la misma semilla:
Algunas conclusiones iniciales:
- En nuestra opinión, todas las imágenes tienen buena calidad en cuanto a lo realistas que se ven. Las versiones de 6,55 y 4,50 se acercan a la versión de 16 bits en este aspecto.
- La misma semilla produce una composición equivalente, pero no preservará los mismos detalles. Las razas de perros pueden ser diferentes, por ejemplo.
- La adhesión a la consulta puede degradarse a medida que aumenta la compresión. En este ejemplo, la versión agresiva de 3,41 pierde la tabla. El PSNR solo compara cuánto difieren los píxeles en general, pero no se preocupa por los sujetos en las imágenes. Debe examinar los resultados y evaluarlos según su caso de uso.
Esta técnica es excelente para Stable Diffusion XL porque podemos mantener aproximadamente el mismo tamaño de UNet aunque el número de parámetros se haya triplicado en comparación con la versión anterior. ¡Pero no es exclusiva de ella! Puede aplicar el método a cualquier modelo Stable Diffusion Core ML.
¿Cómo se crean las recetas de bits mixtos?
El siguiente gráfico muestra la fuerza de la señal (PSNR en dB) versus la reducción del tamaño del modelo (% del tamaño en float16) para stabilityai/stable-diffusion-xl-base-1.0. Las curvas de {1,2,4,6,8} bits se generan paletizando progresivamente más capas utilizando una paleta con un número fijo de bits. Las capas se ordenaron en orden ascendente de su impacto aislado en la fuerza de la señal de extremo a extremo, de modo que el impacto acumulativo de la compresión se retrase tanto como sea posible. La curva de bits mixtos se basa en volver a un número mayor de bits tan pronto como el impacto aislado de una capa en la integridad de la señal de extremo a extremo caiga por debajo de un umbral. Tenga en cuenta que todas las curvas basadas en paletización superan a la cuantización lineal de 8 bits en el mismo tamaño de modelo, excepto la de 1 bit.
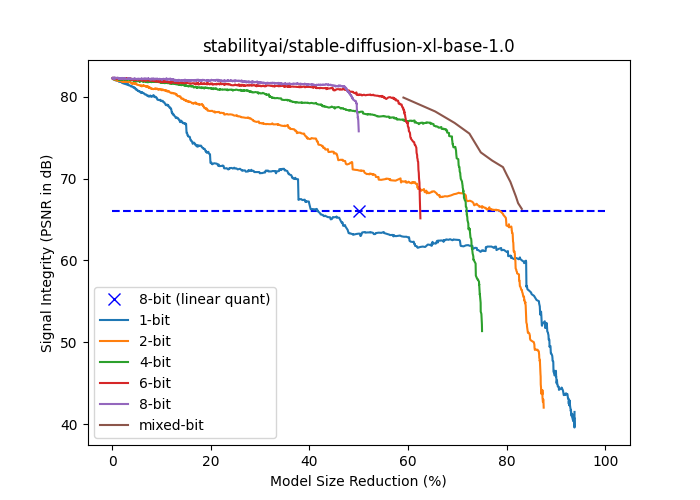
La paletización de bits mixtos se realiza en dos fases: análisis y aplicación.
El objetivo de la fase de análisis es encontrar puntos en la curva de bits mixtos (la curva marrón por encima de todas las demás en la figura) para poder elegir nuestro compromiso deseado entre calidad y tamaño. Como se mencionó en la sección anterior, iteramos a través de las capas y seleccionamos las profundidades de bits más bajas que producen resultados por encima de un umbral de PSNR dado. Repetimos el proceso para varios umbrales para obtener diferentes estrategias de cuantización. El resultado del proceso es, por lo tanto, un conjunto de recetas de cuantización, donde cada receta es solo un diccionario JSON que detalla el número de bits a utilizar para cada capa en el modelo. Las capas con pocos parámetros se ignoran y se mantienen en float16 por simplicidad.
La fase de aplicación simplemente recorre la receta y aplica la paletización con el número de bits especificado en la estructura JSON.
El análisis es un proceso largo y requiere una GPU (mps o cuda), ya que tenemos que ejecutar inferencias múltiples. Una vez que esté hecho, la aplicación de la receta se puede realizar en pocos minutos.
Proporcionamos scripts para cada una de estas fases:
mixed_bit_compression_pre_analysis.pymixed_bit_compression_apply.py
Conversión de modelos ajustados finamente
Si previamente ha convertido modelos de Difusión Estable a Core ML, el proceso para XL utilizando el convertidor de línea de comandos es muy similar. Hay una nueva bandera para indicar si el modelo pertenece a la familia XL, y debe usar --attention-implementation ORIGINAL si ese es el caso.
Para obtener una introducción al proceso, consulte las instrucciones en el repositorio o una de nuestras publicaciones anteriores en el blog, y asegúrese de usar las banderas mencionadas anteriormente.
Ejecución de la paletización de bits mixtos
Después de convertir modelos de Difusión Estable o Difusión Estable XL a Core ML, opcionalmente puede aplicar la paletización de bits mixtos utilizando los scripts mencionados anteriormente.
Debido a que el proceso de análisis es lento, hemos preparado recetas para los modelos más populares:
- Recetas para Difusión Estable 1.5
- Recetas para Difusión Estable 2.1
- Recetas para Difusión Estable XL 1.0 base
Puede descargarlas y aplicarlas localmente para experimentar.
Además, también aplicamos las tres mejores recetas del análisis de Difusión Estable XL a la versión Core ML de UNet, y las publicamos aquí. ¡Siéntase libre de probarlas y ver cómo funcionan para usted!
Finalmente, como se mencionó en la introducción, creamos una tubería completa de Difusión Estable XL Core ML que utiliza una receta de 4.5 bits.
Recursos publicados
apple/ml-stable-diffusion, por Apple. Biblioteca de conversión e inferencia para Swift (y Python).huggingface/swift-coreml-diffusers. Aplicación de demostración de Hugging Face, construida sobre el paquete de Apple.- Difusión Estable XL 1.0 base (versión Core ML). Modelo listo para ejecutarse utilizando los repositorios anteriores y otras aplicaciones de terceros.
- Difusión Estable XL 1.0 base, con paletización de bits mixtos (Core ML). El mismo modelo que el anterior, con UNet cuantizado con una paletización efectiva de 4.5 bits (en promedio).
- UNets adicionales con paletización de bits mixtos.
- Recetas de paletización de bits mixtos, precalculadas para modelos populares y listas para usar.
mixed_bit_compression_pre_analysis.py. Script para ejecutar el análisis de bits mixtos y generación de recetas.mixed_bit_compression_apply.py. Script para aplicar las recetas calculadas durante la fase de análisis.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores demuestran pagos digitales cuánticos ‘incondicionalmente seguros
- En el Festival de Wagner, la nueva tecnología revela una brecha de liderazgo
- Eso es gracioso, pero los modelos de IA no entienden la broma.
- Esta herramienta podría proteger tus imágenes de la manipulación de IA
- La SEC le está dando a las empresas cuatro días para informar ciberataques
- La Evolución del Desarrollo de Software Desde Waterfall hasta Agile, DevOps y más allá
- Jugadores de World of Warcraft engañaron a una inteligencia artificial que rastreaba el sitio web del juego para publicar noticias falsas






