¿Cómo funciona realmente la Difusión Estable? Una explicación intuitiva
Difusión Estable ¿Cómo funciona? Explicación intuitiva.
Los modelos de “Difusión Estable”, como comúnmente se conocen, o los Modelos de Difusión Latente, como se conocen en el mundo científico, han causado sensación en todo el mundo, con herramientas como Midjourney captando la atención de millones. En este artículo, intentaré despejar algunos misterios sobre estos modelos y espero pintar una imagen conceptual en tu mente de cómo funcionan. Como siempre, este artículo no entrará en los detalles, pero proporcionaré algunos enlaces al final que lo hacen. El paper, que es la principal fuente de información detrás de este artículo, será el primer enlace incluido.

Motivación
Existen algunos enfoques para la síntesis de imágenes (crear imágenes nuevas desde cero), y estos incluyen GANs, que tienen un rendimiento deficiente en datos diversos; Transformers Autoregresivos, que son lentos para entrenar y ejecutar (similar a los transformers LLM que generan texto token por token, generan imágenes parche por parche), y los modelos de difusión que por sí mismos contrarrestan algunos de estos problemas, pero aún así siguen siendo computacionalmente costosos. Todavía se necesitan cientos de días de CPU para entrenarlos, y utilizar realmente el modelo implica ejecutarlo paso a paso para producir una imagen final, lo cual también lleva mucho tiempo y cálculo.
Resumen rápido de los Modelos de Difusión
- Detección de formas de nubes de puntos 3D para modelado de interiores
- Explicando la atención en Transformers [Desde el punto de vista del codificador]
- Optimiza el rendimiento del equipo con datos históricos, Ray y Amazon SageMaker
Para entender cómo funcionan los modelos de Difusión, primero veamos cómo se entrenan, lo cual se hace de una manera ligeramente no intuitiva. Comenzamos aplicando ruido a una imagen repetidamente, lo que crea una “cadena de Markov” de imágenes. De esta manera, podemos obtener un número T de imágenes repetidamente más ruidosas a partir de una única imagen original.
Luego, nuestro modelo aprende a predecir el ruido exacto que se aplicó en un cierto paso de tiempo, y podemos usar su salida para “desruidizar” la imagen en ese paso de tiempo. Esto nos permite efectivamente pasar de la imagen T a la imagen T-1. Para reiterar, el modelo se entrena dándole la imagen con el ruido aplicado en algún momento T, y el tiempo T en sí, ¡y la salida es qué ruido se aplicó para llevarla del tiempo T-1 al T!
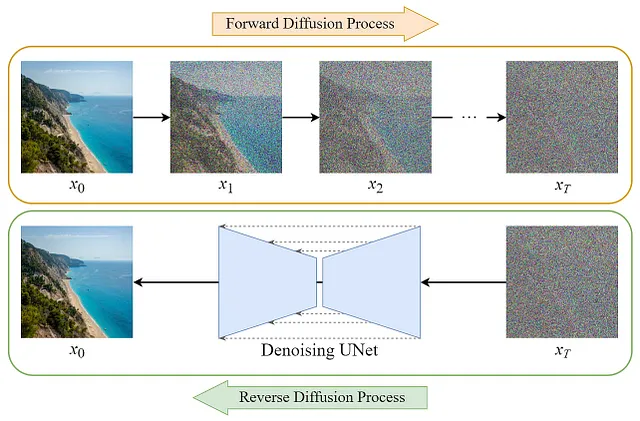
Una vez que tenemos entrenado dicho modelo, podemos aplicarlo repetidamente a ruido aleatorio para producir una imagen nueva y novedosa. El excelente artículo del maravilloso Steins, de donde proviene la imagen anterior, explica esto con más profundidad.
Modelo UNet
El modelo que se utiliza comúnmente para predecir el ruido en cada paso de tiempo es un modelo de arquitectura “UNet”. Este es un tipo de arquitectura que aplica repetidamente capas convolucionales, capas de agrupación y conexiones de salto para primero reducir la escala de una imagen pero aumentar la profundidad (mapas de características), y luego se utilizan convoluciones transpuestas para aumentar la escala de los mapas de características de nuevo a las dimensiones de la imagen original. Aquí hay un excelente artículo de Maurício Cordeiro que explica este modelo con mayor profundidad.
Problemas
Aquí es donde surgen los problemas de los modelos de difusión tradicionales. El primer problema es el tiempo de entrenamiento. Suponiendo que tenemos N imágenes, y aplicamos ruido a una imagen T veces, eso significa N*T posibles entradas a nuestro modelo. Y muchas veces, estas son imágenes de alta resolución, y cada entrada incorporaría las grandes dimensiones de la imagen. Después de todo, no queremos que Midjourney produzca arte pixelado…
Y luego, suponiendo que tenemos nuestro modelo entrenado, ¡debemos aplicar los pesos T veces repetidamente para volver del ruido aleatorio a una imagen! Recuerda, nuestro modelo solo puede darnos la imagen del paso de tiempo anterior, y debemos llegar desde el paso de tiempo T hasta el paso de tiempo 0.
El otro problema radica en la utilidad de dicho modelo. Si te diste cuenta, no se mencionó el texto de entrada ni una sola vez; sin embargo, todos estamos acostumbrados a implementaciones que convierten texto en imágenes, no ruido aleatorio en imágenes. Entonces, ¿cómo y dónde exactamente entra esta característica?
Modelos de Difusión Latente
Una idea clave que solucionaría estos problemas es dividir nuestro modelo en dos modelos separados.
El primer modelo se entrena para codificar y decodificar imágenes en un “espacio latente” que retiene muchos de los detalles “perceptuales” detrás de la imagen, pero reduce las dimensiones de los datos. Como una forma de entender esto intuitivamente, se puede pensar en algo de ruido en las imágenes que realmente no necesitamos aprender (un cielo azul con píxeles que cambian ligeramente su tono).
El segundo modelo es el Diffuser real, que puede convertir esta representación del espacio latente en una imagen. Sin embargo, este Diffuser tiene una modificación especial que le permite “entender” y ser dirigido por entradas de otros dominios, como el texto.
Compresión perceptual de imágenes
Comencemos con el primer modelo, el codificador/decodificador de imágenes. Recuerda, la idea es preparar las imágenes para el Diffuser real de tal manera que se preserve la información importante mientras se reducen las dimensiones.
Este modelo de compresión se llama en realidad un “autoencoder”, y nuevamente este modelo aprende a codificar los datos en un espacio latente comprimido y luego decodificarlos de nuevo a su forma original. El objetivo de este modelo es minimizar la diferencia entre la entrada y la salida reconstruida. Para nuestra función de pérdida, utilizamos dos componentes.
- Pérdida perceptual: nuestro objetivo es minimizar las diferencias en las características de la imagen (como bordes o texturas), en lugar de las diferencias de píxeles entre las versiones original y decodificada. Hay herramientas existentes que pueden extraer estas características de las imágenes, y podemos usarlas.
- Objetivo adversarial basado en parches: un GAN (consulta mi artículo anterior sobre diferentes tipos de modelos) cuyo objetivo es imponer el realismo local, analizando el parche de imagen por parche y clasificando si un cierto parche es real o falso.
Esto tiene el beneficio adicional de evitar el desenfoque, ya que lo que estamos optimizando no es la diferencia de píxeles, sino la diferencia de características. Esto significa que si nuestro modelo produce una imagen que es ligeramente diferente en la coloración de los píxeles pero aún conserva las mismas “características”, no se penalizará mucho y esto es lo que queremos. Sin embargo, si las coloraciones de los píxeles están cerca entre sí, pero las características están mal, el modelo será penalizado bastante (de ahí la parte del desenfoque). Esto evita que el decodificador (y por extensión, el Diffuser final) “haga trampa” y cree imágenes con valores de píxeles que están cerca del conjunto de datos original, pero características reales que están “mal”.
Texto
Entonces, ¿dónde y cómo entra el texto en esto?
Cuando entrenamos nuestro modelo, no solo lo entrenamos para difuminar imágenes (o, más precisamente, las representaciones del espacio latente de estas imágenes producidas por nuestro primer modelo), también lo entrenamos para entender el texto y aprender a usar ciertas partes del texto para generar estas imágenes. Esto se debe a que la “atención cruzada”, el mecanismo que permite al modelo centrarse selectivamente en ciertas características o aspectos del texto, está incorporado en el propio modelo. Aquí hay un diagrama que muestra esto.
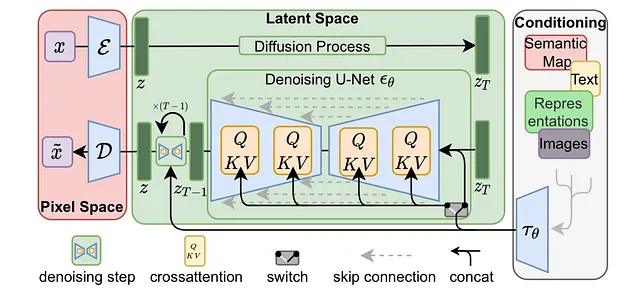
A través de un codificador separado, el texto se convierte en una “representación intermedia” (una representación en la que las partes más importantes del texto tienen más peso), y estos pesos afectan a las capas de la UNet, dirigiendo la imagen final que se producirá. Esto se debe a que el modelo tiene un componente de “atención cruzada” incorporado que, de manera similar a los transformers, permite que diferentes partes de la representación intermedia afecten ciertas partes de la imagen menos y otras más. Esto se entrena a través de un esquema estándar de propagación hacia adelante y hacia atrás. Nuestro Denoising UNet recibe el texto y algo de ruido aleatorio (ambos codificados), y su salida final se compara con la imagen original. El modelo aprende tanto a usar el texto de manera efectiva como a eliminar el ruido de manera efectiva al mismo tiempo. Si no estás familiarizado con la propagación hacia adelante y hacia atrás, te recomiendo encarecidamente que investigues estos temas, ya que son fundamentales para el aprendizaje automático.
Conclusión
Los LDM funcionan bien en todo tipo de tareas, incluyendo el relleno, la superresolución y la generación de imágenes. Este poderoso modelo se ha convertido en un elemento básico en el mundo de la inteligencia artificial en gráficos, y todavía estamos descubriendo nuevos casos de uso. Y aunque este artículo te dará una comprensión conceptual, hay muchos más detalles sobre esto. Si deseas obtener más información, consulta este artículo llamado “Síntesis de imágenes de alta resolución con modelos de difusión latente” que describe las matemáticas detrás de muchas de las cosas que mencioné.
Fuentes
- https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
- https://medium.com/@steinsfu/diffusion-model-clearly-explained-cd331bd41166
- https://medium.com/analytics-vidhya/creating-a-very-simple-u-net-model-with-pytorch-for-semantic-segmentation-of-satellite-images-223aa216e705
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo las industrias están cumpliendo las expectativas de los consumidores con la IA de voz
- Descodificación del habla
- Nuevos códigos podrían hacer que la computación cuántica sea 10 veces más eficiente
- Conoce a los ‘Super Usuarios’ de la IA Generativa el 70% de la Generación Z utiliza GenAI
- La IA podría introducir mensajes secretos en memes
- La estructura más resistente conocida descubierta por el Laboratorio de Robots Autónomos
- Douglas Lenat, quien intentó hacer que la inteligencia artificial fuera más humana, fallece a los 72 años






