Diferenciación automática con Python y C++ para el aprendizaje profundo
Diferenciación automática en Python y C++ para el deep learning
Esta historia explora la diferenciación automática, una característica de los frameworks modernos de Deep Learning que calcula automáticamente los gradientes de los parámetros durante el bucle de entrenamiento. La historia presenta esta tecnología en conjunción con ejemplos prácticos utilizando Python y C++.
Hoja de ruta
- Diferenciación automática: qué es, la motivación, etc.
- Diferenciación automática en Python con TensorFlow
- Diferenciación automática en C++ con Eigen
- Conclusión
Diferenciación automática
Los frameworks modernos como PyTorch o TensorFlow tienen una funcionalidad mejorada llamada diferenciación automática [1], o, en resumen, autodiff. Como su nombre sugiere, autodiff calcula automáticamente la derivada de las funciones, reduciendo la responsabilidad de los desarrolladores de implementar esas derivadas ellos mismos.
¿Cuál es la relevancia de autodiff?
Cada framework de Deep Learning utiliza actualmente autodiff para calcular los gradientes de los parámetros entrenables.
Antes de que autodiff estuviera ampliamente disponible, la mayor parte del tiempo dedicado al desarrollo de modelos se invertía en implementar código para calcular gradientes (o en realidad depurar o eliminar errores del código de gradiente).
- Este artículo de IA de GSAi China presenta un estudio exhaustivo de agentes autónomos basados en LLM
- Revolucionando la Interacción Humano-Máquina La Emergencia de la Ingeniería de Instrucciones
- Router Langchain Cómo crear asistencia de programación utilizando Langchain
Por lo tanto, autodiff fue un cambio de juego para la popularización del deep learning. Permitió incluso a los desarrolladores sin sólidos conocimientos de cálculo implementar algoritmos de machine learning complejos con confianza. Incluso para los desarrolladores con sólidos conocimientos de cálculo, autodiff es útil porque reduce la posibilidad de un error o de una implementación subóptima.
¿Por qué es importante entender autodiff?
En el machine learning, autodiff abstrae por completo el cálculo de gradientes, generalmente proporcionando cálculos excepcionalmente precisos y rápidos sin ningún esfuerzo por parte del desarrollador del modelo. Generalmente. Pero no siempre.
Debido a factores como la inestabilidad numérica, autodiff puede fallar en algunas situaciones raras. Por lo tanto, entender cómo funciona autodiff te prepara para (i) utilizar autodiff al máximo, (ii) detectar cuándo autodiff falla y (iii) solucionarlo cuando sea necesario.
También es importante destacar que, en la retropropagación, el cálculo de los gradientes es la parte más crítica y costosa, y se realiza por completo mediante autodiff. Por lo tanto, entender autodiff se vuelve absolutamente obligatorio.
Diferenciación automática utilizando TensorFlow
Si utilizas Google TensorFlow, es posible que nunca hayas pensado en derivar una capa por ti mismo. Comencemos con un ejemplo sencillo [2]:
import tensorflow as tfclass CustomLayer(tf.keras.layers.Layer): def __init__(self, num_outputs, activation): super(CustomLayer, self).__init__() self.num_outputs = num_outputs self.activation = activation def build(self, input_shape): self.kernel = self.add_weight("kernel", shape=[int(input_shape[-1]), self.num_outputs]) def call(self, inputs): Z = tf.matmul(inputs, self.kernel) Y = self.activation(Z) return YEsta capa personalizada es básicamente un clon de tf.keras.layers.Dense sin sesgo. Podemos usarla de la siguiente manera:
def sin_activation(x): return tf.sin(x)my_custom_layer = CustomLayer(2, sin_activation)input = tf.constant([[-1., 0., 1.], [2., 3., 4.], [-1., -5., 2.]])with tf.GradientTape() as tape: output = my_custom_layer(input) loss = tf.reduce_sum(output**2)gradient = tape.gradient(loss, my_custom_layer.trainable_variables)print("my_custom_layer.trainable_variables:\n", my_custom_layer.trainable_variables[0].numpy())print("\ngradient:\n", gradient[0].numpy())Este código produce algo similar a:
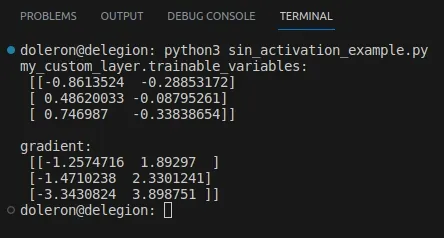
Dado que no estamos utilizando una función de activación incorporada (como tf.keras.activation.relu), ¿cómo sabe TensorFlow cómo calcular ese gradiente? La respuesta es simple: utilizando la diferenciación automática.
Cómo funciona la diferenciación automática
En lugar de pedirle al desarrollador que proporcione una derivada explícita de sin_activation, TensorFlow calcula el gradiente utilizando la diferenciación automática. Pero, ¿cómo funciona la diferenciación automática?
Tal vez hayas tomado largas clases de cálculo aprendiendo cómo calcular derivadas de funciones utilizando las reglas de diferenciación. ¿La diferenciación automática utiliza esas mismas reglas para encontrar las derivadas? Sí, pero no de la misma manera que lo hiciste tú.
La idea central [3] en la diferenciación automática es descomponer el grafo de cálculo en operaciones elementales en las que las derivadas son simples y conocidas, y luego aplicar la regla de la cadena de forma recursiva para calcular la derivada más alta.
Por ejemplo, examinemos cómo se calculó la pérdida en el último ejemplo:
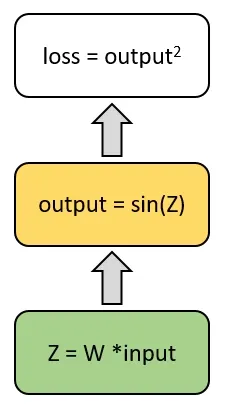
Esta imagen representa el flujo de cálculo del valor de pérdida. Utilizando la regla de la cadena, podemos encontrar la fórmula para el gradiente de la pérdida con respecto a los pesos:
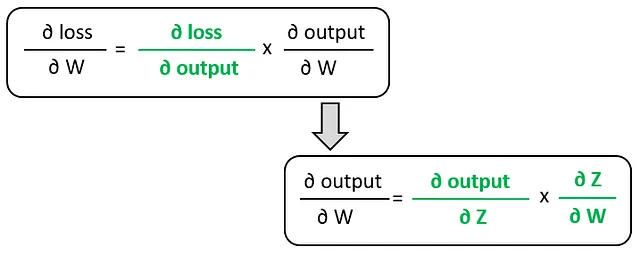
Lo cual se puede reducir a:
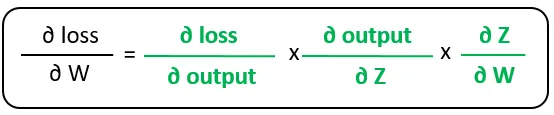
Observa que esas derivadas parciales en el lado derecho son las hojas del grafo de cálculo del gradiente. Son de alguna manera elementales, lo que significa que no podemos derivar ninguna otra derivada a partir de ellas.
Ahora, la diferenciación automática necesita encontrar el valor de estos gradientes de hojas, lo cual se puede resolver de manera bastante directa utilizando reglas básicas de cálculo:
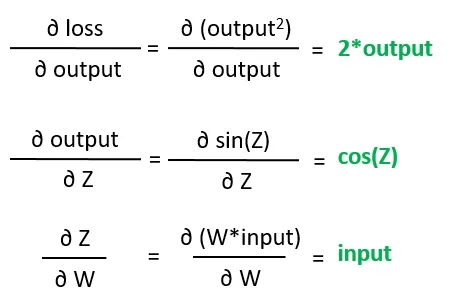
Finalmente, el gradiente de la pérdida con respecto a los pesos se encuentra utilizando el siguiente cálculo:
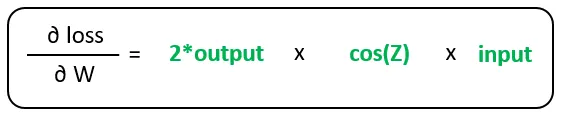
La diferenciación automática realiza este cálculo del grafo sin interferencia explícita por parte del desarrollador. ¡Genial! Entonces, ¿cuál es el problema? ¡El problema radica en los detalles!
Entra en juego la inestabilidad numérica
Como se mencionó en la primera parte de esta historia, en algunas circunstancias, la diferenciación automática falla debido a la inestabilidad numérica de los gradientes intermedios o de las hojas. Considera el siguiente ejemplo:
import tensorflow as tfinput = tf.Variable(100.0)def function_using_autodiff(x): return 1./tf.exp(x)with tf.GradientTape() as tape: output = function_using_autodiff(input)gradient = tape.gradient(output, input)print("output usando autodiff: ", output.numpy())print("gradiente usando autodiff: ", gradient.numpy())Este programa produce la siguiente salida:
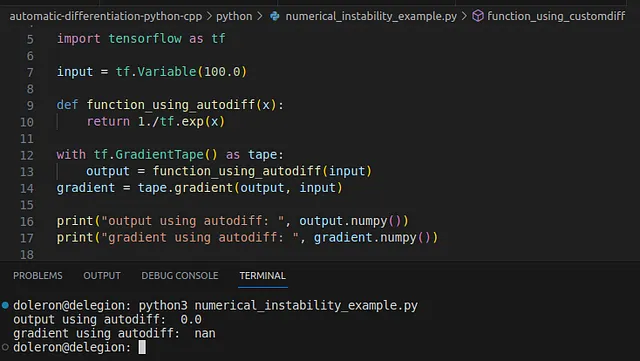
En este caso, aunque la función fue evaluada correctamente en x=100, el gradiente proporcionado por autodiff fue nan. Resolvamos este problema utilizando un gradiente personalizado. Primero, verifiquemos la expresión de la función:
La derivada de esta función es:
Ahora, podemos implementar esta derivada como un gradiente personalizado [4] de la siguiente manera:
import tensorflow as [email protected]_gradientdef function_using_customdiff(x): e = tf.exp(x) def grad(upstream): return upstream * -tf.exp(-x) return 1./tf.exp(x), gradwith tf.GradientTape() as tape: output = function_using_customdiff(input)gradient = tape.gradient(output, input)print("output using custom diff: ", output.numpy())print("gradient using custom diff: ", gradient.numpy())Esta vez, el gradiente se evalúa correctamente:
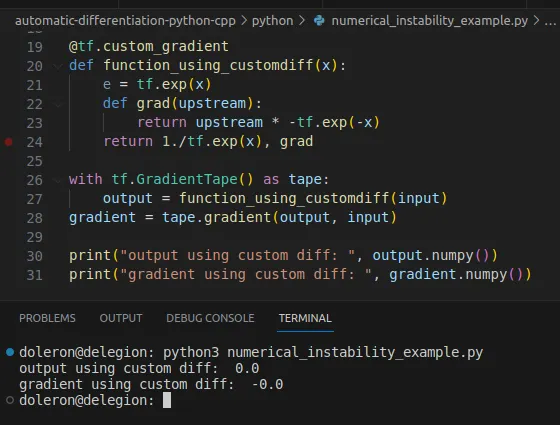
A veces, la inestabilidad numérica proviene de una propiedad teórica de la función en cuestión. Por ejemplo, la derivada de la siguiente función:
es
¡que claramente está indefinido cuando x = 0, a pesar de que f(0) = 0! También podemos usar un gradiente personalizado para proporcionar una solución conveniente (de ingeniería) para casos como este.
Ahora que entendemos cómo usar autodiff en Python/TensorFlow, aprendamos cómo usar esta tecnología en programas C++ con Eigen.
Autodiff en C++ con Eigen
Eigen es una de las bibliotecas de álgebra de alto rendimiento más exitosas para C++ hasta ahora. Si no estás familiarizado con Eigen, te recomiendo leer una de mis historias anteriores en VoAGI.
Usar Eigen Autodiff [5] es bastante sencillo. Comencemos con un ejemplo simple pero ilustrativo. Considera la siguiente función:
template<typename T>T my_function(const T& x){ T result = T(1)/(T(1) + exp(-x)); return result;}Observa que estamos definiendo esta función como una función de plantilla. Sin entrar en detalles, una función de plantilla es una plantilla para una función. No es realmente una función. Las plantillas como esta son útiles porque podemos reutilizar my_function con diferentes tipos de datos.
Normalmente, llamaríamos a nuestras funciones usando tipos como float, double o int. Sin embargo, para que Eigen Autodiff funcione, tenemos que pasar los valores como Eigen::AutoDiffScalar. Mira el siguiente ejemplo:
#include <iostream>#include <unsupported/Eigen/AutoDiff>int main(int, char **){ Eigen::AutoDiffScalar<Eigen::VectorXd> X; X.derivatives() = Eigen::VectorXd::Unit(1, 0); X.value() = 2.f; auto Y = my_function(X); std::cout << "Y: " << Y << "\n\n"; std::cout << "derivatives:\n" << Y.derivatives() << "\n"; return 0;}El primer punto aquí es el encabezado unsupported/Eigen/AutoDiff. En este archivo, Eigen define el tipo Eigen::AutoDiffScalar utilizado para tipar la variable X. Observa nuevamente las siguientes dos líneas:
X.derivatives() = Eigen::VectorXd::Unit(1, 0);X.value() = 2.f;Estas líneas establecen el valor de X y su índice. Dado que X es la única variable en este ejemplo, su índice es 0.
Ahora, podemos pasar X a my_function como de costumbre:
auto Y = my_function(X);Y también es un Eigen::AutoDiffScalar. Como podemos ver en el código, el valor de cada derivada parcial de Y se almacena en el arreglo derivatives(). Al ejecutar este código, se obtiene la siguiente salida:
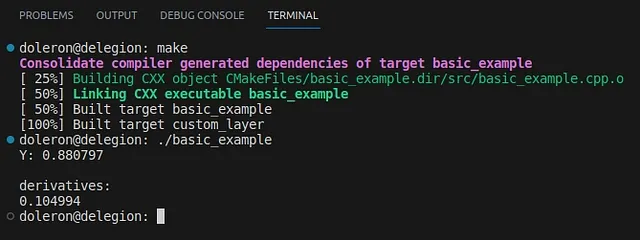
Y almacena tanto el valor de salida de la función como la derivada con respecto a X. ¿Cómo podemos saber si estos valores son correctos? Puede notar que my_function es, de hecho, la fórmula de la función sigmoide:

La fórmula de la derivada de la sigmoide es bien conocida:

Por lo tanto, una calculadora simple puede verificar los valores de σ(2) = 0.8808 y σ’(2) = 0.10499.
Este fue, intencionalmente, un ejemplo muy simple. Ahora intentemos algo un poco más desafiante.
Implementando la capa personalizada usando C++ y Eigen
Una vez que sabemos cómo usar autodiferenciación en C++ con Eigen, finalmente podemos reescribir el ejemplo de CustomLayer, esta vez usando C++:
#include <unsupported/Eigen/CXX11/Tensor>template <typename T>Eigen::Tensor<T, 2> CustomLayer(Eigen::Tensor<T, 2> &X, Eigen::Tensor<T, 2> &W, std::function<Eigen::Tensor<T, 2>(Eigen::Tensor<T, 2>&)> activation){ Eigen::array<Eigen::IndexPair<Eigen::Index>, 1> dims = { Eigen::IndexPair<Eigen::Index>(1, 0) }; Eigen::Tensor<T, 2> Z = X.contract(W, dims); Eigen::Tensor<T, 2> result = activation(Z); return result;};Aquí, es importante destacar tres puntos:
- Estamos usando tensores de Eigen en lugar de matrices de Eigen. Si no estás familiarizado con los tensores en Eigen, lee esta historia;
- Estamos realizando una contracción. Las contracciones son la generalización multidimensional del producto de matrices.
- Estamos usando una función de plantilla. Una clase de plantilla también funcionaría. El punto aquí es definirlo como una plantilla como lo hicimos en el ejemplo anterior.
Además, estamos pasando la activación como una std::function. Ahora definámosla:
template <typename T>T sine(T t) { return sin(t);}template <typename T>Eigen::Tensor<T, 2> sin_activation(Eigen::Tensor<T, 2> & P) { Eigen::Tensor<T, 2> result = P.unaryExpr(std::ref(sine<T>)); return result;};Nuevamente, estamos usando plantillas. Todo aquí es sencillo. Simplemente estamos usando unaryExpr para mapear P utilizando la función sin(t). Ahora, finalmente podemos invocar CustomLayer:
#include <unsupported/Eigen/AutoDiff>
typedef typename Eigen::AutoDiffScalar<Eigen::VectorXf> AutoDiff_T;
int main(int, char **){
Eigen::Tensor<float, 2> x_in(3, 3);
x_in.setValues({{-1., 0., 1.}, {2., 3., 4.}, {-1., -5., 2.}});
Eigen::Tensor<float, 2> w_in(3, 2);
w_in.setRandom();
Eigen::Tensor<AutoDiff_T, 2> X = convert(x_in);
Eigen::Tensor<AutoDiff_T, 2> W = convert(w_in, 0, w_in.size());
auto Y = CustomLayer(X, W, sin_activation<AutoDiff_T>);
auto output = Y * Y;
auto LOSS = ((Eigen::Tensor<AutoDiff_T, 0>)output.sum())(0);
auto dY_dW = gradients(LOSS, W);
std::cout << "trainable_variables:\n" << W << "\n\n";
std::cout << "gradient:\n" << dY_dW << "\n\n";
std::cout << "output:\n" << output << "\n\n";
std::cout << "loss:\n" << LOSS << "\n\n";
return 0;
}Como su nombre lo indica, la función convert convierte los tensores canónicos originales x_in y w_in en tensores Eigen::Tensor<AutoDiff_T, 2>. Como discutimos en el último ejemplo, el tipo Eigen::AutoDiffScalar es obligatorio para que funcione la diferenciación automática de Eigen. convert se define de la siguiente manera:
auto convert = [](const Eigen::Tensor<float, 2> &tensor, int offset = 0, int size = 0){
const int rows = tensor.dimension(0);
const int cols = tensor.dimension(1);
Eigen::Tensor<AutoDiff_T, 2> result(rows, cols);
for (int i = 0; i < rows; ++i)
{
for (int j = 0; j < cols; ++j)
{
int index = i * cols + j;
result(i, j).value() = tensor(i, j);
if (size) {
result(i, j).derivatives() = Eigen::VectorXf::Unit(size, offset + index);
}
}
}
return result;
};Observe las dos líneas cuando invocamos convert:
Eigen::Tensor<AutoDiff_T, 2> X = convert(x_in);
Eigen::Tensor<AutoDiff_T, 2> W = convert(w_in, 0, w_in.size());Resulta que solo estamos buscando las derivadas parciales de W. La siguiente sección explica cómo calcular las derivadas parciales con respecto a X también.
Al final, Y tiene el valor de salida de la capa y las derivadas parciales con respecto a W. Luego, se puede utilizar una función gradients para desempaquetar los gradientes:
auto gradients(const AutoDiff_T &LOSS, const Eigen::Tensor<AutoDiff_T, 2> &W){
auto derivatives = LOSS.derivatives();
int index = 0;
Eigen::Tensor<float, 2> result(W.dimension(0), W.dimension(1));
for (int i = 0; i < W.dimension(0); ++i)
{
for (int j = 0; j < W.dimension(1); ++j)
{
float val = derivatives[index];
result(i, j) = val;
index++;
}
}
return result;
}Después de construirlo y ejecutarlo, este código produce algo como esto:
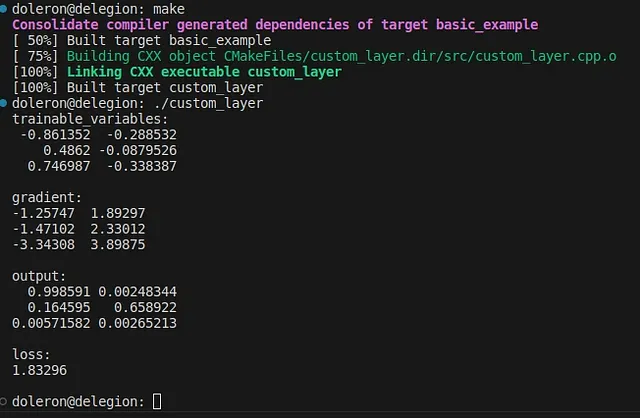
Como se esperaba, una salida similar a la generada por el ejemplo de Python/TensorFlow.
Obtención de las derivadas con respecto a X
En el último ejemplo, calculamos solo el gradiente de W. Si también estamos interesados en calcular las derivadas parciales de X, debemos implementar los siguientes cambios:
int size = x_in.size() + w_in.size();Eigen::Tensor<AutoDiff_T, 2> X = convert(x_in, 0, size);Eigen::Tensor<AutoDiff_T, 2> W = convert(w_in, x_in.size(), size);Este código básicamente notifica a Eigen que también debe realizar un seguimiento de la derivada de X. Tenga en cuenta que, para desempaquetar tanto X como W, también debe cambiar la función gradients:
auto gradients(const AutoDiff_T &Y, const Eigen::Tensor<AutoDiff_T, 2> &X, const Eigen::Tensor<AutoDiff_T, 2> &K){ auto derivatives = Y.derivatives(); int index = 0; Eigen::Tensor<float, 2> dY_dX(X.dimension(0), X.dimension(1)); for (int i = 0; i < X.dimension(0); ++i) { for (int j = 0; j < X.dimension(1); ++j) { float val = derivatives[index]; dY_dX(i, j) = val; index++; } } Eigen::Tensor<float, 2> dY_dK(K.dimension(0), K.dimension(1)); for (int i = 0; i < K.dimension(0); ++i) { for (int j = 0; j < K.dimension(1); ++j) { float val = derivatives[index]; dY_dK(i, j) = val; index++; } } return std::make_pair(dY_dX, dY_dK);}Ahora, debe llamar a gradients en consecuencia:
auto [dY_dX, dY_dW] = gradients(LOSS, X, W);Pasando tanto X como W. Después de estos cambios, volver a ejecutar el programa da como resultado la siguiente salida:
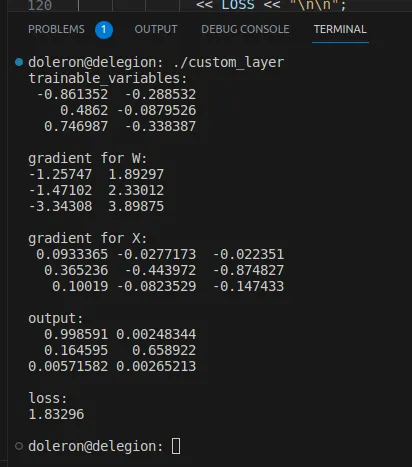
Alternativas a autodiff
La forma en que calculamos el gradiente de fourier_activation “a mano” al principio de esta historia se conoce como diferenciación simbólica.
En la diferenciación simbólica, una función de programa debe convertirse en una expresión matemática abstracta. La expresión se diferencia utilizando reglas de cálculo para obtener una forma derivada. Finalmente, la forma derivada se utiliza para obtener una salida. Un programa para implementar este proceso no suele ser eficiente. A pesar de los esfuerzos de personas altamente competentes que trabajan en este tema, temo decir que la diferenciación simbólica (solo) no es adecuada para aplicaciones de software generales.
Otra alternativa a autodiff es la diferenciación numérica. En la diferenciación numérica, la derivada se calcula mediante un proceso interactivo (discreto). En la diferenciación numérica, la derivada se aproxima mediante un número finito de pasos. Una dificultad de la diferenciación numérica es que este proceso introduce errores de redondeo debido a la discretización inevitable. Además, muy a menudo, la diferenciación numérica es más lenta que autodiff.
Conclusión
Esta historia presentó autodiff, uno de los temas más avanzados en el campo del aprendizaje profundo. El éxito de implementar esta tecnología en paquetes de código abierto ha sido un logro enorme en el desarrollo y la popularización de la inteligencia artificial en las últimas dos décadas.
Particularmente, me sorprende lo simple y conciso que es Eigen Autodiff. Desafortunadamente, no hay mucha documentación al respecto. Si estos ejemplos no son adecuados para su caso de uso, recomiendo buscar más ejemplos en el repositorio de Eigen en GitLab.
Referencias
[1] Baydin et al., Diferenciación automática en Aprendizaje Automático: un estudio, Journal of Machine Learning Research 18 (2018) 1–43
[2] Documentación de TensorFlow, Capas personalizadas
[3] Roger Grosse, CSC321 Clase 10: Diferenciación automática, CS en la Universidad de Toronto
[4] Documentación de TensorFlow, Diferenciación automática avanzada
[5] Patrick Peltzer, Johannes Lotz, Uwe Naumann, Eigen-AD: Diferenciación algorítmica de la biblioteca Eigen, ICCS 2020: 20ª Conferencia Internacional
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Qué es EDI? Sobre el Intercambio Electrónico de Datos (EDI)
- Amplios horizontes La presentación de NVIDIA señala el camino hacia nuevos avances en Inteligencia Artificial
- Estas herramientas podrían ayudar a proteger nuestras imágenes de la IA
- Superando la productividad en el desarrollo de microservicios con herramientas de IA
- Inserción de objetos con conciencia de profundidad en videos usando Python
- Estas nuevas herramientas podrían ayudar a proteger nuestras imágenes de la IA
- Asistente de Voz Personal impulsado por IA para el Aprendizaje de Idiomas






