Detección de anomalías temporales del mundo real a través del aprendizaje automático supervisado y la teoría de conjuntos
Detección de anomalías temporales a través del aprendizaje automático supervisado y la teoría de conjuntos
Seattle Burke Gilman Trail
Explora los datos abiertos de la Ciudad de Seattle
Tabla de contenidos:
I. Declaración del problema
- Navegando por los formatos de datos con Pandas para principiantes
- Esta investigación de IA de UCLA indica que los grandes modelos de lenguaje (como GPT-3) han adquirido la capacidad emergente de encontrar soluciones sin guía para una amplia gama de problemas de analogía.
- Mejorando los Pipelines de Procesamiento del Lenguaje Natural con spaCy
II. Remodelación de series de tiempo en un problema supervisado
III. Modelado y análisis supervisados
I. Declaración del problema
Los datos se pueden descargar desde aquí: Seattle Burke Gilman Trail | Kaggle
La esencia de esta declaración del problema es que necesitamos detectar anomalías con 3 horas de anticipación. Una anomalía se define como >500 personas en total en el sendero dentro de 3 horas. Para resolver este problema, se nos ha proporcionado datos por hora del tráfico del sendero, tanto de peatones como de bicicletas.
II. Remodelación de series de tiempo en un problema supervisado
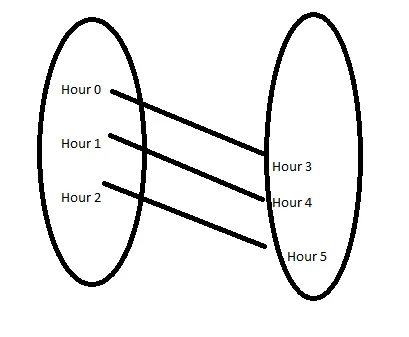
Entonces, lo que podemos hacer es hacer dos copias de los datos, y luego podemos unir los datos de manera que la hora 0 se mapee a la hora 3 en la misma fila.
¿Cómo se hace esto?
Primero, traemos los datos:
import pandas as pd
df = pd.read_csv(r'/content/burke-gilman-trail-north-of-ne-70th-st-bike-and-ped-counter.csv')A continuación:
# cambiamos df a un dataframe
df = pd.DataFrame(df)
df = df.fillna(0)Una vez hecho esto, ahora hagamos una copia de nuestros datos que comienza en la fila 3:
# creamos df2 que comienza en la 4ta fila
df2 = df[df.index >= 3]
df2.head()Ahora, agregaremos una columna de índice a ambos dataframes que comienza en 1:
# agregamos una columna de numeración a df1 y df2. la primera fila debe ser 1, la segunda fila es 2 y así sucesivamente. Ambas columnas del dataframe deben comenzar en 1
df['index'] = list(range(1, len(df) + 1))
df2['index'] = list(range(1, len(df2) + 1))La razón por la que hacemos esto es para poder unir en la columna de índice. El índice 1 se unirá al índice 1 de df2, pero en esa fila, veremos la hora 0 en el lado izquierdo y la hora 3 en el lado derecho…
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de IA de Salesforce presentan la evolución de los agentes autónomos mejorados con LLM y la innovadora estrategia BOLAA
- ¿NP-Qué? Tipos de Complejidad de Problemas de Optimización Explicados
- ¿Qué es Azure Data Factory (ADF)? Características y Aplicaciones
- Cómo la IA está ayudando a los clientes a comprar mejor en Amazon
- Tabnine presenta Tabnine Chat una aplicación de chat centrada en el código de grado empresarial en beta que permite a los desarrolladores interactuar con los modelos de IA de Tabnine utilizando lenguaje natural.
- Noticias de VoAGI, 16 de agosto Use ChatGPT para convertir texto en una presentación de PowerPoint • Hoja de trucos de las mejores herramientas de Python para construir aplicaciones de IA generativas
- Conoce Embroid Un método de IA para unir un LLM con información de incrustación de múltiples modelos más pequeños, lo que permite corregir automáticamente las predicciones del LLM sin supervisión.






