Despliega miles de conjuntos de modelos con puntos finales multinivel de Amazon SageMaker en GPU para minimizar tus costos de alojamiento
Despliega conjuntos de modelos en GPU de Amazon SageMaker para minimizar costos de alojamiento.
La adopción de la inteligencia artificial (IA) se está acelerando en todas las industrias y casos de uso. Los recientes avances científicos en aprendizaje profundo (DL), modelos de lenguaje grandes (LLMs) e IA generativa permiten a los clientes utilizar soluciones avanzadas de última generación con un rendimiento casi humano. Estos modelos complejos a menudo requieren aceleración de hardware porque permite no solo un entrenamiento más rápido, sino también una inferencia más rápida al utilizar redes neuronales profundas en aplicaciones en tiempo real. El gran número de núcleos de procesamiento en paralelo de las GPUs los hace adecuados para estas tareas de DL.
Sin embargo, además de la invocación del modelo, estas aplicaciones de DL a menudo requieren preprocesamiento o postprocesamiento en un pipeline de inferencia. Por ejemplo, las imágenes de entrada para un caso de uso de detección de objetos pueden necesitar ser redimensionadas o recortadas antes de ser utilizadas por un modelo de visión por computadora, o la tokenización de los textos de entrada antes de ser utilizados en un LLM. NVIDIA Triton es un servidor de inferencia de código abierto que permite a los usuarios definir dichos pipelines de inferencia como un conjunto de modelos en forma de Grafo Acíclico Dirigido (DAG). Está diseñado para ejecutar modelos a gran escala tanto en CPU como en GPU. Amazon SageMaker admite la implementación de Triton de manera transparente, lo que le permite utilizar las características de Triton y beneficiarse también de las capacidades de SageMaker: un entorno gestionado y seguro con integración de herramientas de MLOps, escalado automático de los modelos alojados y más.
AWS, en su dedicación por ayudar a los clientes a lograr el mayor ahorro, ha innovado continuamente no solo en opciones de precios y servicios proactivos de optimización de costos, sino también en el lanzamiento de funciones de ahorro de costos como los puntos finales de múltiples modelos (MMEs, por sus siglas en inglés). Los MMEs son una solución rentable para implementar un gran número de modelos utilizando la misma flota de recursos y un contenedor de servicio compartido para alojar todos sus modelos. En lugar de utilizar múltiples puntos finales de un solo modelo, puede reducir los costos de alojamiento al implementar varios modelos y pagar solo por un entorno de inferencia único. Además, los MMEs reducen la sobrecarga de implementación porque SageMaker se encarga de cargar los modelos en memoria y escalarlos según los patrones de tráfico hacia su punto final.
En esta publicación, mostramos cómo ejecutar varios modelos de ensamble de aprendizaje profundo en una instancia de GPU con un MME de SageMaker. Para seguir este ejemplo, puede encontrar el código en el repositorio público de ejemplos de SageMaker.
- Decodificando la Sinfonía del Sonido Procesamiento de Señales de Audio para la Ingeniería Musical
- Este boletín de inteligencia artificial es todo lo que necesitas #59
- Ajuste fino de Llama 2 con DPO
Cómo funcionan los MMEs de SageMaker con GPU
Con los MMEs, un solo contenedor alberga varios modelos. SageMaker controla el ciclo de vida de los modelos alojados en el MME cargándolos y descargándolos en la memoria del contenedor. En lugar de descargar todos los modelos en la instancia del punto final, SageMaker carga y almacena en caché de forma dinámica los modelos a medida que se invocan.
Cuando se realiza una solicitud de invocación para un modelo en particular, SageMaker realiza lo siguiente:
- En primer lugar, enruta la solicitud a la instancia del punto final.
- Si el modelo no se ha cargado, descarga el artefacto del modelo desde el Servicio de Almacenamiento Simple de Amazon (Amazon S3) al volumen de almacenamiento de bloques elástico de Amazon (Amazon EBS) de esa instancia.
- Carga el modelo en la memoria del contenedor en la instancia de cómputo acelerado por GPU. Si el modelo ya se ha cargado en la memoria del contenedor, la invocación es más rápida porque no se necesitan más pasos.
Cuando se necesita cargar un modelo adicional y la utilización de memoria de la instancia es alta, SageMaker descargará los modelos no utilizados del contenedor de esa instancia para asegurarse de que haya suficiente memoria. Estos modelos descargados permanecerán en el volumen de EBS de la instancia para que puedan ser cargados en la memoria del contenedor más adelante, lo que elimina la necesidad de descargarlos nuevamente desde el bucket de S3. Sin embargo, si el volumen de almacenamiento de la instancia alcanza su capacidad, SageMaker eliminará los modelos no utilizados del volumen de almacenamiento. En casos en los que el MME recibe muchas solicitudes de invocación y hay instancias adicionales (o una política de escalado automático), SageMaker enruta algunas solicitudes a otras instancias en el clúster de inferencia para adaptarse al alto tráfico.
Esto no solo proporciona un mecanismo de ahorro de costos, sino que también le permite implementar nuevos modelos de forma dinámica y descontinuar los antiguos. Para agregar un nuevo modelo, simplemente súbalo al bucket de S3 configurado para el MME e invóquelo. Para eliminar un modelo, deje de enviar solicitudes y elimínelo del bucket de S3. ¡Agregar o eliminar modelos de un MME no requiere actualizar el punto final en sí!
Ensamble de Triton
El ensamble de modelos de Triton representa un pipeline que consta de un modelo, lógica de preprocesamiento y postprocesamiento, y la conexión de tensores de entrada y salida entre ellos. Una única solicitud de inferencia a un ensamble desencadena la ejecución de todo el pipeline como una serie de pasos utilizando el programador de ensambles. El programador recopila los tensores de salida en cada paso y los proporciona como tensores de entrada para otros pasos según la especificación. Para aclarar: el ensamble de modelos aún se ve como un solo modelo desde una vista externa.
La arquitectura del servidor Triton incluye un repositorio de modelos: un repositorio basado en sistema de archivos de los modelos que Triton pondrá a disposición para la inferencia. Triton puede acceder a modelos desde una o más rutas de acceso locales o desde ubicaciones remotas como Amazon S3.
Cada modelo en un repositorio de modelos debe incluir una configuración de modelo que proporcione información requerida y opcional sobre el modelo. Por lo general, esta configuración se proporciona en un archivo config.pbtxt especificado como ModelConfig protobuf. Una configuración de modelo mínima debe especificar la plataforma o backend (como PyTorch o TensorFlow), la propiedad max_batch_size, y los tensores de entrada y salida del modelo.
Triton en SageMaker
SageMaker permite implementar modelos utilizando Triton server con código personalizado. Esta funcionalidad está disponible a través de los contenedores de Triton Inference Server administrados por SageMaker. Estos contenedores admiten marcos comunes de aprendizaje automático (ML) (como TensorFlow, ONNX y PyTorch, así como formatos de modelo personalizados) y variables de entorno útiles que le permiten optimizar el rendimiento en SageMaker. Se recomienda utilizar las imágenes de SageMaker Deep Learning Containers (DLC) porque se mantienen y actualizan regularmente con parches de seguridad.
Recorrido de la solución
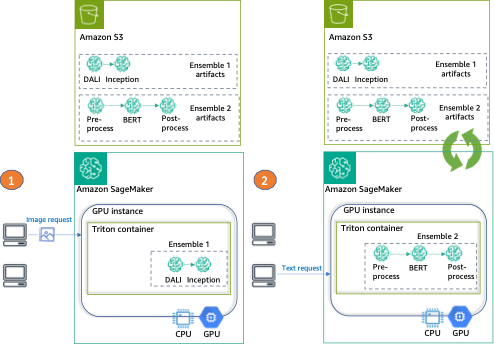
Para este artículo, implementamos dos tipos diferentes de conjuntos en una instancia de GPU, utilizando Triton y un solo punto de conexión de SageMaker.
El primer conjunto consta de dos modelos: un modelo DALI para el preprocesamiento de imágenes y un modelo TensorFlow Inception v3 para la inferencia real. El conjunto de canalización toma imágenes codificadas como entrada, las cuales deben descodificarse, redimensionarse a una resolución de 299×299 y normalizarse. Este preprocesamiento será realizado por el modelo DALI. DALI es una biblioteca de código abierto para tareas comunes de procesamiento de imágenes y voz, como decodificación y aumento de datos. Inception v3 es un modelo de reconocimiento de imágenes que consta de convoluciones simétricas y asimétricas, capas de agrupación promedio y máxima, y capas completamente conectadas (por lo tanto, es perfecto para su uso en GPU).
El segundo conjunto transforma frases de texto en incrustaciones y consta de tres modelos. Primero, se aplica un modelo de preprocesamiento a la tokenización del texto de entrada (implementado en Python). Luego usamos un modelo BERT preentrenado (sin mayúsculas) del Hugging Face Model Hub para extraer incrustaciones de tokens. BERT es un modelo de lenguaje en inglés que fue entrenado utilizando un objetivo de modelado de lenguaje enmascarado (MLM). Finalmente, aplicamos un modelo de posprocesamiento donde las incrustaciones de tokens sin procesar del paso anterior se combinan en incrustaciones de oraciones.
Después de configurar Triton para utilizar estos conjuntos, mostramos cómo configurar y ejecutar el SageMaker MME.
Finalmente, proporcionamos un ejemplo de invocación de cada conjunto, como se puede ver en el siguiente diagrama:
- Conjunto 1 – Invocar el punto de conexión con una imagen, especificando DALI-Inception como el conjunto objetivo
- Conjunto 2 – Invocar el mismo punto de conexión, esta vez con entrada de texto y solicitando el conjunto de preprocesamiento-BERT-posprocesamiento
Configurar el entorno
Primero, configuramos el entorno necesario. Esto incluye actualizar las bibliotecas de AWS (como Boto3 y el SDK de SageMaker) e instalar las dependencias necesarias para empaquetar nuestros conjuntos y ejecutar inferencias utilizando Triton. También utilizamos el rol de ejecución predeterminado del SDK de SageMaker. Utilizamos este rol para permitir que SageMaker acceda a Amazon S3 (donde se almacenan nuestros artefactos de modelo) y al registro de contenedores (donde se utilizará la imagen de NVIDIA Triton). Consulte el siguiente código:
import boto3, json, sagemaker, time
from sagemaker import get_execution_role
import nvidia.dali as dali
import nvidia.dali.types as types
# Variables de SageMaker
sm_client = boto3.client(service_name="sagemaker")
runtime_sm_client = boto3.client("sagemaker-runtime")
sagemaker_session = sagemaker.Session(boto_session=boto3.Session())
role = get_execution_role()
# Otras variables
instance_type = "ml.g4dn.4xlarge"
sm_model_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_config_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
endpoint_name = "triton-tf-dali-ensemble-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())Preparar conjuntos
En este paso siguiente, preparamos los dos conjuntos: el conjunto TensorFlow (TF) Inception con procesamiento DALI y BERT con procesamiento y postprocesamiento en Python.
Esto implica descargar los modelos pre-entrenados, proporcionar los archivos de configuración de Triton y empaquetar los artefactos para ser almacenados en Amazon S3 antes de implementarlos.
Preparar el conjunto TF y DALI
Primero, preparamos los directorios para almacenar nuestros modelos y configuraciones: para el TF Inception (inception_graphdef), para el procesamiento DALI (dali) y para el conjunto (ensemble_dali_inception). Como Triton admite la versión del modelo, también agregamos la versión del modelo a la ruta del directorio (denotado como 1 porque solo tenemos una versión). Para obtener más información sobre la política de versión de Triton, consulte la Política de versión. A continuación, descargamos el modelo Inception v3, lo extraemos y lo copiamos al directorio del modelo inception_graphdef. Consulte el siguiente código:
!mkdir -p model_repository/inception_graphdef/1
!mkdir -p model_repository/dali/1
!mkdir -p model_repository/ensemble_dali_inception/1
!wget -O /tmp/inception_v3_2016_08_28_frozen.pb.tar.gz \
https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz
!(cd /tmp && tar xzf inception_v3_2016_08_28_frozen.pb.tar.gz)
!mv /tmp/inception_v3_2016_08_28_frozen.pb model_repository/inception_graphdef/1/model.graphdefAhora, configuramos Triton para utilizar nuestra tubería de conjuntos. En un archivo config.pbtxt, especificamos las formas y tipos de los tensores de entrada y salida, y los pasos que el planificador de Triton debe realizar (procesamiento DALI y el modelo Inception para la clasificación de imágenes):
%%writefile model_repository/ensemble_dali_inception/config.pbtxt
name: "ensemble_dali_inception"
platform: "ensemble"
max_batch_size: 256
input [
{
name: "INPUT"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1001 ]
}
]
ensemble_scheduling {
step [
{
model_name: "dali"
model_version: -1
input_map {
key: "DALI_INPUT_0"
value: "INPUT"
}
output_map {
key: "DALI_OUTPUT_0"
value: "preprocessed_image"
}
},
{
model_name: "inception_graphdef"
model_version: -1
input_map {
key: "input"
value: "preprocessed_image"
}
output_map {
key: "InceptionV3/Predictions/Softmax"
value: "OUTPUT"
}
}
]
}A continuación, configuramos cada uno de los modelos. Primero, la configuración del modelo para el backend DALI:
%%writefile model_repository/dali/config.pbtxt
name: "dali"
backend: "dali"
max_batch_size: 256
input [
{
name: "DALI_INPUT_0"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "DALI_OUTPUT_0"
data_type: TYPE_FP32
dims: [ 299, 299, 3 ]
}
]
parameters: [
{
key: "num_threads"
value: { string_value: "12" }
}
]A continuación, la configuración del modelo para TensorFlow Inception v3 que descargamos anteriormente:
%%writefile model_repository/inception_graphdef/config.pbtxt
name: "inception_graphdef"
platform: "tensorflow_graphdef"
max_batch_size: 256
input [
{
name: "input"
data_type: TYPE_FP32
format: FORMAT_NHWC
dims: [ 299, 299, 3 ]
}
]
output [
{
name: "InceptionV3/Predictions/Softmax"
data_type: TYPE_FP32
dims: [ 1001 ]
label_filename: "inception_labels.txt"
}
]
instance_group [
{
kind: KIND_GPU
}
]Debido a que este es un modelo de clasificación, también debemos copiar las etiquetas del modelo Inception al directorio inception_graphdef en el repositorio del modelo. Estas etiquetas incluyen 1,000 etiquetas de clase del conjunto de datos ImageNet.
!aws s3 cp s3://sagemaker-sample-files/datasets/labels/inception_labels.txt model_repository/inception_graphdef/inception_labels.txtA continuación, configuramos y serializamos la canalización DALI que manejará nuestra preprocesamiento de archivos. El preprocesamiento incluye la lectura de la imagen (usando la CPU), decodificación (acelerada usando la GPU), y redimensionamiento y normalización de la imagen.
@dali.pipeline_def(batch_size=3, num_threads=1, device_id=0)
def pipe():
"""Crea una canalización que lee imágenes y máscaras, decodifica las imágenes y las devuelve."""
images = dali.fn.external_source(device="cpu", name="DALI_INPUT_0")
images = dali.fn.decoders.image(images, device="mixed", output_type=types.RGB)
images = dali.fn.resize(images, resize_x=299, resize_y=299) # redimensiona la imagen al tamaño predeterminado de 299x299
images = dali.fn.crop_mirror_normalize(
images,
dtype=types.FLOAT,
output_layout="HWC",
crop=(299, 299), # recorta la imagen al tamaño predeterminado de 299x299
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], # recorta una región central de la imagen
std=[0.229 * 255, 0.224 * 255, 0.225 * 255], # recorta una región central de la imagen
)
return images
pipe().serialize(filename="model_repository/dali/1/model.dali")Finalmente, empaquetamos los artefactos juntos y los subimos como un solo objeto a Amazon S3:
!tar -cvzf model_tf_dali.tar.gz -C model_repository .
model_uri = sagemaker_session.upload_data(
path="model_tf_dali.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("S3 model uri: {}".format(model_uri))Preparar el conjunto de TensorRT y Python
Para este ejemplo, usamos un modelo pre-entrenado de la biblioteca transformers.
Puede encontrar todos los modelos (preproceso y postproceso, junto con los archivos config.pbtxt) en la carpeta ensemble_hf. La estructura de nuestro sistema de archivos incluirá cuatro directorios (tres para los pasos del modelo individual y uno para el conjunto) así como sus respectivas versiones:
ensemble_hf
├── bert-trt
| |── model.pt
| |──config.pbtxt
├── ensemble
│ └── 1
| └── config.pbtxt
├── postprocess
│ └── 1
| └── model.py
| └── config.pbtxt
├── preprocess
│ └── 1
| └── model.py
| └── config.pbtxtEn la carpeta de trabajo, proporcionamos dos scripts: el primero para convertir el modelo al formato ONNX (onnx_exporter.py) y el script de compilación de TensorRT (generate_model_trt.sh).
Triton admite nativamente el tiempo de ejecución de TensorRT, lo que le permite implementar fácilmente un motor de TensorRT, optimizando así para una arquitectura de GPU seleccionada.
Para asegurarnos de que utilizamos la versión de TensorRT y las dependencias que son compatibles con las del contenedor Triton, compilamos el modelo utilizando la versión correspondiente de la imagen del contenedor de PyTorch de NVIDIA:
model_id = "sentence-transformers/all-MiniLM-L6-v2"
! docker run --gpus=all --rm -it -v `pwd`/workspace:/workspace nvcr.io/nvidia/pytorch:22.10-py3 /bin/bash generate_model_trt.sh $model_idLuego copiamos los artefactos del modelo al directorio que creamos anteriormente y agregamos una versión a la ruta:
! mkdir -p ensemble_hf/bert-trt/1 && mv workspace/model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf workspace/model.onnx workspace/core*Utilizamos un paquete Conda para generar un entorno Conda que el backend de Python de Triton utilizará en el preprocesamiento y el postprocesamiento:
!bash conda_dependencies.sh
!cp processing_env.tar.gz ensemble_hf/postprocess/ && cp processing_env.tar.gz ensemble_hf/preprocess/
!rm processing_env.tar.gzFinalmente, subimos los artefactos del modelo a Amazon S3:
!tar -C ensemble_hf/ -czf model_trt_python.tar.gz .
model_uri = sagemaker_session.upload_data(
path="model_trt_python.tar.gz", key_prefix="triton-mme-gpu-ensemble"
)
print("S3 model uri: {}".format(model_uri))Ejecutar ensembles en una instancia SageMaker MME con GPU
Ahora que nuestros artefactos de ensembles están almacenados en Amazon S3, podemos configurar y lanzar el SageMaker MME.
Comenzamos recuperando la URI de la imagen del contenedor para la imagen Triton DLC que coincide con la del registro de contenedores de nuestra región (y se utiliza para la compilación del modelo TensorRT):
account_id_map = {
"us-east-1": "785573368785",
"us-east-2": "007439368137",
"us-west-1": "710691900526",
"us-west-2": "301217895009",
"eu-west-1": "802834080501",
"eu-west-2": "205493899709",
"eu-west-3": "254080097072",
"eu-north-1": "601324751636",
"eu-south-1": "966458181534",
"eu-central-1": "746233611703",
"ap-east-1": "110948597952",
"ap-south-1": "763008648453",
"ap-northeast-1": "941853720454",
"ap-northeast-2": "151534178276",
"ap-southeast-1": "324986816169",
"ap-southeast-2": "355873309152",
"cn-northwest-1": "474822919863",
"cn-north-1": "472730292857",
"sa-east-1": "756306329178",
"ca-central-1": "464438896020",
"me-south-1": "836785723513",
"af-south-1": "774647643957",
}
region = boto3.Session().region_name
if region not in account_id_map.keys():
raise ("UNSUPPORTED REGION")
base = "amazonaws.com.cn" if region.startswith("cn-") else "amazonaws.com"
triton_image_uri = "{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:23.03-py3".format(
account_id=account_id_map[region], region=region, base=base
)A continuación, creamos el modelo en SageMaker. En la solicitud create_model, describimos el contenedor a utilizar y la ubicación de los artefactos del modelo, y especificamos mediante el parámetro Mode que se trata de un modelo múltiple.
container = {
"Image": triton_image_uri,
"ModelDataUrl": models_s3_location,
"Mode": "MultiModel",
}
create_model_response = sm_client.create_model(
ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container
)Para alojar nuestros ensembles, creamos una configuración de punto final con la llamada a la API create_endpoint_config, y luego creamos un punto final con la API create_endpoint. SageMaker despliega todos los contenedores que has definido para el modelo en el entorno de alojamiento.
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": instance_type,
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name
)Aunque en este ejemplo estamos configurando una instancia única para alojar nuestro modelo, los MME de SageMaker admiten completamente la configuración de una política de escalado automático. Para obtener más información sobre esta función, consulta Ejecutar múltiples modelos de aprendizaje profundo en GPU con los puntos finales de modelos múltiples de Amazon SageMaker.
Crear cargas de solicitud e invocar el MME para cada modelo
Después de desplegar nuestro MME en tiempo real, es hora de invocar nuestro punto de conexión con cada uno de los conjuntos de modelos que utilizamos.
Primero, creamos una carga útil para el conjunto de modelos DALI-Inception. Utilizamos la imagen shiba_inu_dog.jpg del conjunto de datos público de imágenes de mascotas de SageMaker. Cargamos la imagen como una matriz de bytes codificada para usar en el backend de DALI (para obtener más información, consulte los ejemplos de decodificación de imágenes).
sample_img_fname = "shiba_inu_dog.jpg"
import numpy as np
s3_client = boto3.client("s3")
s3_client.download_file(
"sagemaker-sample-files", "datasets/image/pets/shiba_inu_dog.jpg", sample_img_fname
)
def load_image(img_path):
"""
Carga la imagen como una matriz de bytes codificada.
Este es un enfoque típico que deseas utilizar en el backend de DALI
"""
with open(img_path, "rb") as f:
img = f.read()
return np.array(list(img)).astype(np.uint8)
rv = load_image(sample_img_fname)
print(f"Forma de la imagen {rv.shape}")
rv2 = np.expand_dims(rv, 0)
print(f"Forma del array de imagen expandida {rv2.shape}")
payload = {
"inputs": [
{
"name": "INPUT",
"shape": rv2.shape,
"datatype": "UINT8",
"data": rv2.tolist(),
}
]
}Con nuestra imagen codificada y carga útil lista, invocamos el punto de conexión.
Ten en cuenta que especificamos que nuestro conjunto de modelos objetivo es el artefacto model_tf_dali.tar.gz. El parámetro TargetModel es lo que diferencia a los MME de los puntos de conexión de un solo modelo y nos permite dirigir la solicitud al modelo correcto.
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/octet-stream", Body=json.dumps(payload), TargetModel="model_tf_dali.tar.gz"
)La respuesta incluye metadatos sobre la invocación (como el nombre y la versión del modelo) y la respuesta real de la inferencia en la parte de datos del objeto de salida. En este ejemplo, obtenemos una matriz de 1.001 valores, donde cada valor es la probabilidad de la clase a la que pertenece la imagen (1.000 clases y 1 adicional para otras). A continuación, invocamos nuestro MME nuevamente, pero esta vez apuntamos al segundo conjunto de modelos. Aquí, los datos son solo dos frases de texto simples:
text_inputs = ["Frase 1", "Frase 2"]Para simplificar la comunicación con Triton, el proyecto Triton proporciona varias bibliotecas de cliente. Usamos esa biblioteca para preparar la carga útil en nuestra solicitud:
import tritonclient.http as http_client
text_inputs = ["Frase 1", "Frase 2"]
inputs = []
inputs.append(http_client.InferInput("INPUT0", [len(text_inputs), 1], "BYTES"))
batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]
input0_real = np.array(batch_request, dtype=np.object_)
inputs[0].set_data_from_numpy(input0_real, binary_data=True)
outputs = []
outputs.append(http_client.InferRequestedOutput("finaloutput"))
request_body, header_length = http_client.InferenceServerClient.generate_request_body(
inputs, outputs=outputs
)Ahora estamos listos para invocar el punto de conexión, esta vez el modelo objetivo es el conjunto model_trt_python.tar.gz:
response = runtime_sm_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/vnd.sagemaker-triton.binary+json;json-header-size={}".format(
header_length
),
Body=request_body,
TargetModel="model_trt_python.tar.gz"
)La respuesta son las incrustaciones de las frases que se pueden utilizar en una variedad de aplicaciones de procesamiento del lenguaje natural (NLP).
Limpieza
Por último, limpiamos y eliminamos el punto de conexión, la configuración del punto de conexión y el modelo:
sm_client.delete_endpoint(EndpointName=endpoint_name)
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm_client.delete_model(ModelName=sm_model_name)Conclusión
En esta publicación, mostramos cómo configurar, desplegar e invocar un MME de SageMaker con conjuntos de modelos Triton en una instancia acelerada por GPU. Hospedamos dos conjuntos de modelos en un solo entorno de inferencia en tiempo real, lo que redujo nuestro costo en un 50% (para una instancia g4dn.4xlarge, lo que representa más de $13,000 en ahorros anuales). Aunque este ejemplo utilizó solo dos pipelines, los MME de SageMaker pueden admitir miles de conjuntos de modelos, lo que lo convierte en un mecanismo extraordinario de ahorro de costos. Además, puedes utilizar la capacidad dinámica de los MME de SageMaker para cargar (y descargar) modelos para minimizar la carga operativa de gestionar los despliegues de modelos en producción.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La GPU NVIDIA H100 Tensor Core utilizada en la nueva serie de máquinas virtuales de Microsoft Azure ya está disponible de forma general
- DENZA colabora con WPP para construir e implementar configuradores avanzados de automóviles en la nube NVIDIA Omniverse
- Shutterstock lleva la IA generativa a los fondos de escenas en 3D con NVIDIA Picasso
- Charla especial SIGGRAPH El CEO de NVIDIA lleva la IA generativa a la muestra de Los Ángeles
- Optical Vectors Beam Multi-Bits’ ‘Optical Vectors Beam Multi-Bits’ (Rayos Ópticos Multibits)
- La FAA aprueba el sistema de aeronaves no tripuladas más grande de los Estados Unidos.
- La pantalla 3D podría llevar el tacto al mundo digital





