Desbloqueando el potencial del texto Un vistazo más cercano a los métodos de limpieza de texto previo a la incrustación
Desbloqueo del potencial del texto Métodos de limpieza previa a la incrustación
Este artículo discutirá diferentes técnicas de limpieza que son esenciales para obtener un rendimiento máximo de los datos textuales.
Para la demostración de los métodos de limpieza de texto, utilizaremos el conjunto de datos de texto llamado ‘metamorphosis’ de Kaggle.
Comencemos importando las bibliotecas de Python necesarias para el proceso de limpieza.
import nltk, re, stringfrom nltk.corpus import stopwordsfrom nltk.stem.porter import PorterStemmerAhora carguemos el conjunto de datos.
file_directory = 'enlace-al-directorio-local-del-conjunto-de-datos'file = open(file_directory, 'rt', encoding='utf-8')text = file.read()file.close()ten en cuenta que para que el código anterior funcione, debes colocar la ruta del directorio local del archivo de datos.
- Conoce a los razonadores RAP y LLM Dos marcos basados en conceptos similares para el razonamiento avanzado con LLMs
- Keras 3.0 Todo lo que necesitas saber
- La IA y los implantes cerebrales restauran el movimiento y la sensación para un hombre paralizado
Dividiendo los datos de texto en palabras según los espacios en blanco
words = text.split()print(words[:120])
Aquí vemos que se conserva la puntuación (por ejemplo, armour-like y wasn’t), lo cual es bueno. También podemos ver que la puntuación al final de una oración se mantiene con la última palabra (por ejemplo, thought.), lo cual no es ideal.
Entonces, esta vez intentemos dividir los datos utilizando caracteres que no sean palabras.
words = re.split(r'\W+', text)print(words[:120])
Aquí vemos que palabras como ‘thought.’ se han convertido en ‘thought’. Pero el problema es que palabras como ‘wasn’t’ se convierten en dos palabras como ‘wasn’ y ‘t’. Necesitamos solucionarlo.
En Python, podemos usar string.punctuation para obtener un conjunto de puntuaciones de una vez. Usaremos eso para eliminar la puntuación de nuestro texto.
print(string.punctuation)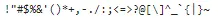
Entonces, ahora dividiremos las palabras según los espacios en blanco y luego eliminaremos toda la puntuación que se haya registrado en los datos.
words = text.split()re_punc = re.compile('[%s]' % re.escape(string.punctuation))stripped = [re_punc.sub('', word) for word in words]print(stripped[:120])
Aquí podemos ver que no tenemos palabras como ‘thought.’ pero también tenemos palabras como ‘wasn’t’, lo cual es correcto.
A veces, el texto también contiene caracteres que no son imprimibles. También debemos filtrarlos. Para hacer esto, podemos usar ‘string.printable’ de Python, que nos da un conjunto de caracteres que se pueden imprimir. Entonces, eliminaremos los caracteres que no estén presentes en esta lista.
re_print = re.compile('[^%s]' % re.escape(string.printable))result = [re_print.sub('', word) for word in stripped]print(result[:120])
Ahora convirtamos todas las palabras en minúsculas. Esto reducirá nuestro vocabulario. Pero también tiene algunas desventajas. Después de hacer esto, dos palabras como ‘Apple’, en referencia a la compañía, y ‘apple’, como una fruta, se considerarán la misma entidad.
resultado = [palabra.lower() for palabra in resultado]print(resultado[:120])
Además, las palabras de un solo carácter no contribuirán a la mayoría de las tareas de PNL. Por lo tanto, también las eliminaremos.
resultado = [palabra for palabra in resultado if len(palabra) > 1]print(resultado[:120])
En PNL, palabras frecuentes como ‘is’, ‘as’, ‘the’ no contribuyen mucho al entrenamiento del modelo. Por lo tanto, a estas palabras se les conoce como palabras de parada y se sugiere eliminarlas en el proceso de limpieza de texto.
import nltkfrom nltk.corpus import stopwordsstop_words = stopwords.words('english')print(stop_words)
resultado = [palabra for palabra in resultado if palabra not in set(stop_words)]print(words[:110])
Ahora, en este punto, reduciremos las palabras con la misma intención a una sola palabra. Por ejemplo, reduciremos las palabras ‘running’, ‘run’ y ‘runs’ a la palabra ‘run’ solamente, ya que las tres palabras dan el mismo significado al modelo durante el entrenamiento. Esto se puede realizar utilizando la clase PorterStemmer en la biblioteca nltk.
from nltk.stem.porter import PorterStemmerps = PorterStemmer()resultado = [ps.stem(palabra) for palabra in resultado]print(words[:110])
Las palabras reducidas pueden tener o no un significado. Si desea que sus palabras tengan un significado, en lugar de utilizar la técnica de reducción, puede utilizar una técnica de lematización que garantice que las palabras tendrán significado después de la transformación.
Ahora eliminemos las palabras que no están compuestas solo por letras del alfabeto
resultado = [palabra for palabra in resultado if palabra.isalpha()]print(resultado[:110])
En esta etapa, los datos textuales parecen lo suficientemente buenos como para ser utilizados en las técnicas de embedding de palabras. Pero también ten en cuenta que puede haber algunos pasos adicionales en este proceso para algunos tipos especiales de datos (por ejemplo, código HTML).
Espero que te haya gustado el artículo. Si tienes algún pensamiento sobre el artículo, por favor házmelo saber. Cualquier comentario constructivo es muy apreciado.
Conéctate conmigo en LinkedIn.
Envíame un correo a [email protected]
¡Que tengas un gran día!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aceptando la IA para el Desarrollo de Software Estrategias de Solución e Implementación
- Top 40 Herramientas de IA Generativa 2023
- Investigadores de UC Berkeley presentan Nerfstudio un marco de trabajo en Python para el desarrollo de Neural Radiance Field (NeRF)
- Adopción empresarial de la IA generativa
- Nueva herramienta de imagen basada en HADAR te permite ver claramente en la oscuridad
- Este artículo de IA de China propone HQTrack un marco de IA para rastrear cualquier cosa de alta calidad en videos
- Ingeniería de Comandos Prácticos






