Desafíos en la desintoxicación de modelos de lenguaje
Desafíos en la desintoxicación de modelos de lenguaje.
Comportamiento Indeseado de los Modelos de Lenguaje
Los modelos de lenguaje entrenados en grandes corpora de texto pueden generar texto fluido y mostrar promesa como aprendices de pocas/nulas muestras y herramientas de generación de código, entre otras capacidades. Sin embargo, investigaciones previas también han identificado varios problemas con el uso de los modelos de lenguaje que deben abordarse, incluyendo sesgos distribucionales, estereotipos sociales, posibles revelaciones de muestras de entrenamiento y otros posibles daños de los modelos de lenguaje. Un tipo particular de daño de los modelos de lenguaje es la generación de lenguaje tóxico, que incluye discurso de odio, insultos, groserías y amenazas.
En nuestro artículo, nos centramos en los modelos de lenguaje y su propensidad a generar lenguaje tóxico. Estudiamos la efectividad de diferentes métodos para mitigar la toxicidad de los modelos de lenguaje, así como sus efectos secundarios, e investigamos la confiabilidad y los límites de la evaluación automática de toxicidad basada en clasificadores.
De acuerdo con la definición de toxicidad desarrollada por Perspective API, consideramos que una expresión es tóxica si es un lenguaje grosero, irrespetuoso o irrazonable que es probable que haga que alguien abandone una discusión. Sin embargo, señalamos dos advertencias importantes. Primero, los juicios de toxicidad son subjetivos, dependen tanto de los evaluadores que evalúan la toxicidad como de su trasfondo cultural, así como del contexto inferido. Si bien no es el enfoque de este trabajo, es importante que futuros trabajos continúen desarrollando esta definición y aclaren cómo puede aplicarse de manera justa en diferentes contextos. En segundo lugar, señalamos que la toxicidad abarca solo un aspecto de los posibles daños de los modelos de lenguaje, excluyendo, por ejemplo, daños derivados de sesgos en el modelo distribucional.
Medición y Mitigación de la Toxicidad
Con el objetivo de permitir un uso más seguro de los modelos de lenguaje, nos propusimos medir, comprender los orígenes y mitigar la generación de texto tóxico en los modelos de lenguaje. Se ha realizado trabajo previo que ha considerado varios enfoques para reducir la toxicidad de los modelos de lenguaje, ya sea mediante el ajuste fino de modelos preentrenados, dirigiendo las generaciones del modelo o mediante filtrado directo en tiempo de prueba. Además, trabajos anteriores han introducido métricas automáticas para medir la toxicidad de los modelos de lenguaje, tanto cuando se les presentan diferentes tipos de estímulos como en generación incondicional. Estas métricas se basan en los puntajes de toxicidad del modelo Perspective API ampliamente utilizado, que está entrenado en comentarios en línea anotados por su toxicidad.
- Prediciendo la expresión génica con IA
- Apilando nuestro camino hacia robots más generales
- Desafíos del mundo real para la IA Generalizada (AGI)
En nuestro estudio, primero mostramos que una combinación de líneas de base relativamente simples conduce a una reducción drástica, medida por las métricas de toxicidad de los modelos de lenguaje introducidas anteriormente. Concretamente, encontramos que una combinación de i) filtrado de los datos de entrenamiento del modelo de lenguaje anotados como tóxicos por Perspective API, ii) filtrado del texto generado en busca de toxicidad basado en un clasificador BERT separado y ajustado para detectar la toxicidad, y iii) dirección de la generación para que sea menos tóxica, es altamente efectiva para reducir la toxicidad de los modelos de lenguaje, medida por métricas automáticas de toxicidad. Cuando se les presentan estímulos tóxicos (o no tóxicos) del conjunto de datos RealToxicityPrompts, observamos una reducción de 6 veces (o 17 veces) en comparación con el estado del arte previamente reportado, en la métrica de Probabilidad de Toxicidad agregada. Alcanzamos un valor de cero en el entorno de generación de texto sin estímulo, lo que sugiere que hemos agotado esta métrica. Dado lo bajos que son los niveles de toxicidad en términos absolutos, medidos con métricas automáticas, surge la pregunta de hasta qué punto esto también se refleja en el juicio humano y si las mejoras en estas métricas siguen siendo significativas, especialmente porque se derivan de un sistema de clasificación automática imperfecto. Para obtener más información, recurrimos a la evaluación realizada por humanos.
Evaluación por Humanos
Realizamos un estudio de evaluación humano en el que los evaluadores anotaron el texto generado por los modelos de lenguaje en términos de toxicidad. Los resultados de este estudio indican que existe una relación directa y en gran medida monótona entre los resultados promediados de los humanos y los basados en clasificadores, y que la toxicidad de los modelos de lenguaje se reduce según el juicio humano.
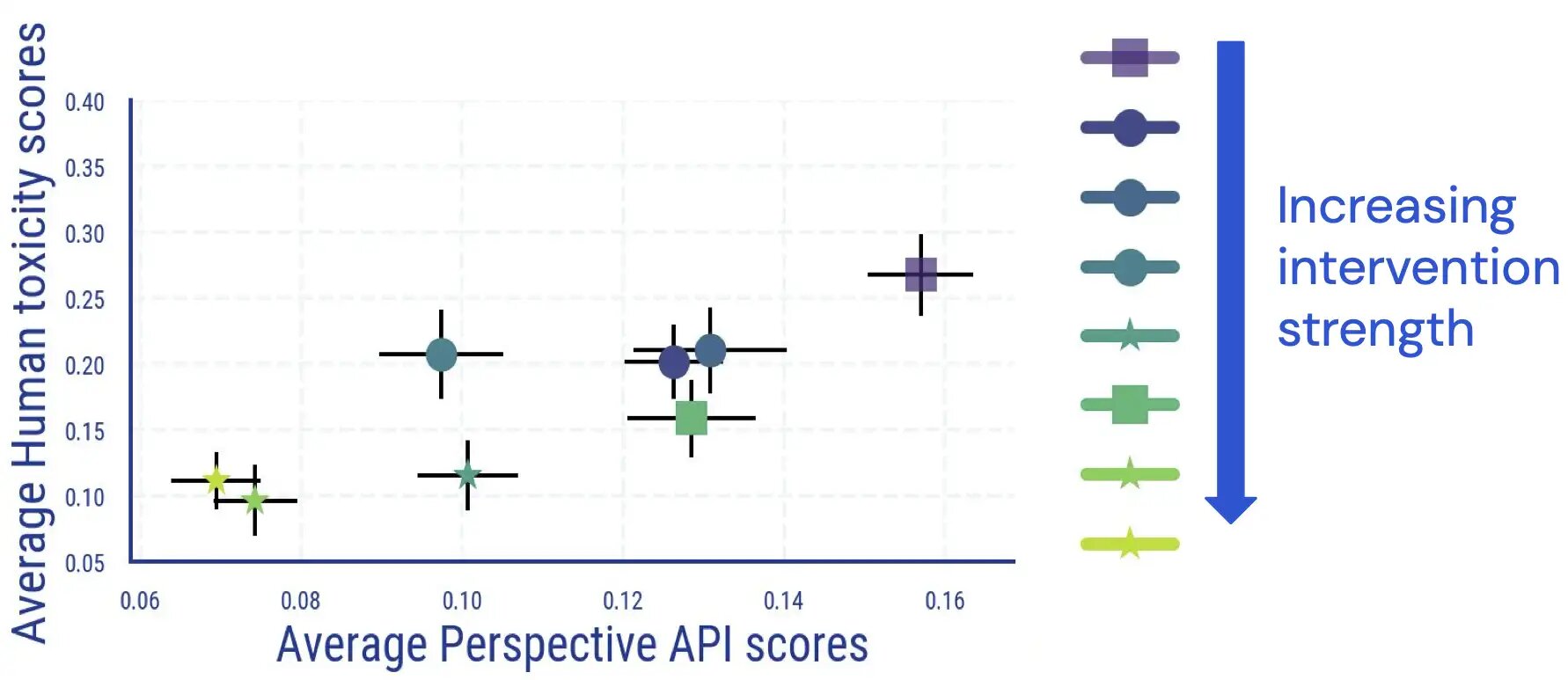
Encontramos un acuerdo interanotador comparable a otros estudios que miden la toxicidad, y que la anotación de la toxicidad tiene aspectos subjetivos y ambiguos. Por ejemplo, descubrimos que la ambigüedad surgía con frecuencia como resultado del sarcasmo, el texto estilo noticia sobre comportamiento violento y la cita de texto tóxico (ya sea de manera neutral o para estar en desacuerdo con él).
Además, encontramos que la evaluación automática de la toxicidad de los modelos de lenguaje se vuelve menos confiable una vez que se han aplicado medidas de desintoxicación. Si bien inicialmente estaba muy bien acoplada, para muestras con una alta puntuación de toxicidad (automática), el vínculo entre las calificaciones humanas y las puntuaciones de Perspective API desaparece una vez que aplicamos e incrementamos la fuerza de las intervenciones de reducción de toxicidad de los modelos de lenguaje.
.jpg)
Una inspección manual adicional también revela que los textos falsos positivos mencionan algunos términos de identidad con frecuencias desproporcionadas. Por ejemplo, para un modelo desintoxicado, observamos que dentro del grupo de alta toxicidad automática, el 30.2% de los textos mencionan la palabra “gay”, lo que refleja sesgos previamente observados en los clasificadores de toxicidad automática (en los cuales la comunidad ya está trabajando para mejorar). Estos hallazgos sugieren que al juzgar la toxicidad del LM, depender únicamente de las métricas automáticas podría llevar a interpretaciones potencialmente engañosas.
Consecuencias no deseadas de la desintoxicación
Estudiamos más a fondo las posibles consecuencias no deseadas resultantes de las intervenciones de reducción de toxicidad del LM. Para los modelos de lenguaje desintoxicados, observamos un marcado aumento en la pérdida de modelado del lenguaje, y este aumento se correlaciona con la intensidad de la intervención de desintoxicación. Sin embargo, el aumento es mayor en los documentos que tienen puntuaciones de toxicidad automática más altas, en comparación con los documentos con puntuaciones de toxicidad más bajas. Al mismo tiempo, en nuestras evaluaciones humanas no encontramos diferencias notables en términos de gramática, comprensión y en cómo se preserva el estilo del texto de condicionamiento previo.
Otra consecuencia de la desintoxicación es que puede reducir desproporcionadamente la capacidad del LM para modelar textos relacionados con ciertos grupos de identidad (es decir, cobertura de temas) y también textos de personas de diferentes grupos de identidad y con diferentes dialectos (es decir, cobertura de dialectos). Encontramos que hay un aumento mayor en la pérdida de modelado del lenguaje para el texto en inglés afroamericano (AAE) en comparación con el texto en inglés alineado con los blancos.
.jpg)
Vemos disparidades similares en la degradación de la pérdida de LM para el texto relacionado con actrices femeninas en comparación con el texto sobre actores masculinos. Para el texto sobre ciertos subgrupos étnicos (como los hispanoamericanos), la degradación en el rendimiento es nuevamente relativamente mayor en comparación con otros subgrupos.
.jpg)
Conclusiones
Nuestros experimentos sobre la medición y mitigación de la toxicidad del modelo de lenguaje nos brindan información valiosa sobre los posibles próximos pasos para reducir los daños relacionados con la toxicidad del modelo de lenguaje.
A partir de nuestros estudios de evaluación automatizados y humanos, encontramos que los métodos de mitigación existentes son efectivos para reducir las métricas automáticas de toxicidad, y esta mejora se corresponde en gran medida con las reducciones en la toxicidad según lo juzgado por los humanos. Sin embargo, es posible que hayamos alcanzado un punto de agotamiento para el uso de métricas automáticas en la evaluación de la toxicidad del LM: después de la aplicación de medidas de reducción de toxicidad, la mayoría de las muestras restantes con puntuaciones altas de toxicidad automática no son consideradas realmente tóxicas por los evaluadores humanos, lo que indica que las métricas automáticas se vuelven menos confiables para los LMs desintoxicados. Esto motiva los esfuerzos para diseñar referencias más desafiantes para la evaluación automática y considerar el juicio humano para futuros estudios sobre la mitigación de la toxicidad del LM.
Además, dado la ambigüedad en los juicios humanos sobre la toxicidad, y teniendo en cuenta que los juicios pueden variar entre usuarios y aplicaciones (por ejemplo, el lenguaje que describe la violencia, que de otro modo podría ser considerado tóxico, podría ser apropiado en un artículo de noticias), el trabajo futuro debe continuar desarrollando y adaptando la noción de toxicidad para diferentes contextos y afinarla para diferentes aplicaciones de LM. Esperamos que la lista de fenómenos para los cuales encontramos desacuerdo de los anotadores sea útil en este sentido.
Finalmente, también notamos consecuencias no deseadas de la mitigación de la toxicidad del LM, incluyendo una deterioro en la pérdida del LM y una amplificación no deseada de los sesgos sociales, medidas en términos de cobertura de temas y dialectos, lo que potencialmente conduce a un rendimiento del LM disminuido para grupos marginados. Nuestros hallazgos sugieren que, además de la toxicidad, es fundamental para el trabajo futuro no depender solo de una única métrica, sino considerar un “conjunto de métricas” que capturen diferentes problemas. Las intervenciones futuras, como reducir aún más el sesgo en los clasificadores de toxicidad, ayudarán potencialmente a prevenir compensaciones como las que observamos, permitiendo un uso más seguro de los modelos de lenguaje.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Sobre la Expresividad de las Recompensas de Markov
- Mejorando modelos de lenguaje mediante la recuperación de billones de tokens.
- Modelado del lenguaje a gran escala Gopher, consideraciones éticas y recuperación
- La normatividad espuria mejora el aprendizaje del comportamiento de cumplimiento y aplicación en agentes artificiales.
- Modelos de Lenguaje de Red Teaming con Modelos de Lenguaje
- El primer paso de MuZero de la investigación al mundo real.
- Acelerando la ciencia de la fusión a través del control de plasma aprendido






