Desplegando Falcon-7B en Producción
Deploying Falcon-7B in Production.
Un tutorial paso a paso
Ejecutando Falcon-7B en la nube como un microservicio

Antecedentes
Hasta ahora, hemos visto las capacidades de ChatGPT y lo que ofrece. Sin embargo, para uso empresarial, modelos cerrados como ChatGPT pueden representar un riesgo ya que las empresas no tienen control sobre sus datos. OpenAI afirma que los datos de los usuarios no se almacenan ni se utilizan para entrenar modelos, pero no hay garantía de que los datos no se filtren de alguna manera.
Para combatir algunos de los problemas relacionados con los modelos cerrados, los investigadores se apresuran a construir LLM de código abierto que rivalicen con modelos como ChatGPT. Con modelos de código abierto, las empresas pueden alojar los modelos ellos mismos en un entorno de nube seguro, mitigando el riesgo de filtración de datos. Además, se obtiene total transparencia en el funcionamiento interno del modelo, lo que ayuda a generar más confianza en la IA en general.
Con los avances recientes en LLM de código abierto, es tentador probar nuevos modelos y ver cómo se comparan con modelos cerrados como ChatGPT.
Sin embargo, ejecutar modelos de código abierto hoy en día presenta barreras significativas. Es mucho más fácil llamar a la API de ChatGPT que descubrir cómo ejecutar un LLM de código abierto.
- Aprendizaje de operadores a través de DeepONet informado por física Vamos a implementarlo desde cero
- Lo que me han enseñado más de 50 entrevistas de Machine Learning (como entrevistador)
- Fundamentos de la detección de anomalías con distribución gaussiana multivariante
En este artículo, mi objetivo es romper estas barreras mostrando cómo se pueden ejecutar modelos de código abierto como el modelo Falcon-7B en la nube en un entorno similar al de producción. Podremos acceder a estos modelos a través de un punto final de API similar a ChatGPT.
Desafíos
Uno de los desafíos importantes para ejecutar modelos de código abierto es la falta de recursos informáticos. Incluso un modelo “pequeño” como Falcon 7B requiere una GPU para ejecutarse.
Para resolver este problema, podemos aprovechar las GPUs en la nube. Pero esto plantea otro desafío. ¿Cómo contenerizamos nuestro LLM? ¿Cómo habilitamos el soporte de GPU? Habilitar el soporte de GPU puede ser complicado porque requiere conocimientos de CUDA. Trabajar con CUDA puede ser una molestia porque hay que averiguar cómo instalar las dependencias de CUDA adecuadas y qué versiones son compatibles.
Entonces, para evitar la trampa mortal de CUDA, muchas empresas han creado soluciones para contenerizar modelos fácilmente al tiempo que habilitan el soporte de GPU. Para esta publicación de blog, utilizaremos una herramienta de código abierto llamada Truss para ayudarnos a contenerizar fácilmente nuestro LLM sin mucho problema.
Truss permite a los desarrolladores contenerizar fácilmente modelos construidos con cualquier marco de trabajo.
¿Por qué usar Truss?
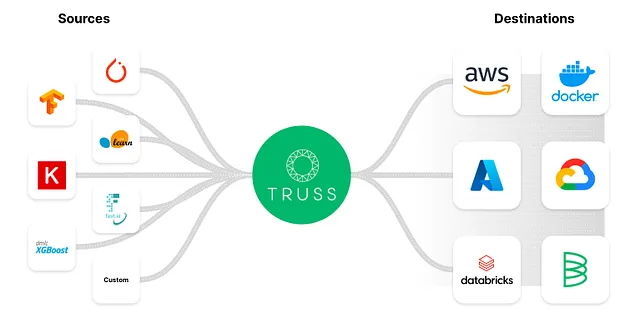
Truss tiene muchas características útiles listas para usar, como:
- Convertir tu modelo de Python en un microservicio con un punto final de API listo para producción
- Congelar dependencias mediante Docker
- Compatibilidad con inferencia en GPUs
- Preprocesamiento y posprocesamiento sencillos para el modelo
- Gestión fácil y segura de secretos
He utilizado Truss antes para implementar modelos de aprendizaje automático y el proceso es bastante fluido y sencillo. Truss crea automáticamente tu archivo Docker y gestiona las dependencias de Python. Todo lo que tenemos que hacer es proporcionar el código de nuestro modelo.
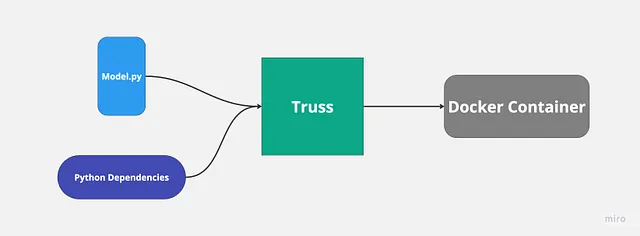
La razón principal por la que queremos usar una herramienta como Truss es que se vuelve mucho más fácil implementar nuestro modelo con soporte de GPU.
Nota: No he recibido ningún patrocinio de Baseten para promocionar su contenido ni estoy asociado con ellos de ninguna manera. No tengo ninguna influencia de Baseten o Truss para escribir este artículo. Simplemente encontré su proyecto de código abierto interesante y útil.
El plan
Esto es lo que cubriré en esta publicación del blog:
- Configurar Falcon 7B localmente usando Truss
- Ejecutar el modelo localmente si tienes una GPU (tengo una RTX 3080)
- Contenerizar el modelo y ejecutarlo usando Docker
- Crear un clúster de Kubernetes habilitado para GPU en Google Cloud para ejecutar nuestro modelo
No te preocupes si no tienes una GPU para el paso 2, aún podrás ejecutar el modelo en la nube.
Aquí está el repositorio de Github que contiene el código si quieres seguirlo:
GitHub – htrivedi99/falcon-7b-truss
Contribuye al desarrollo de htrivedi99/falcon-7b-truss creando una cuenta en GitHub.
github.com
¡Empecemos!
Paso 1: Configuración local de Falcon 7B usando Truss
Primero, necesitaremos crear un proyecto con una versión de Python ≥ 3.8
Descargaremos el modelo de Hugging Face y lo empaquetaremos usando Truss. Aquí están las dependencias que necesitaremos instalar:
pip install trussDentro de tu proyecto de Python, crea un script llamado main.py. Este es un script temporal que usaremos para trabajar con Truss.
A continuación, configuraremos nuestro paquete Truss ejecutando el siguiente comando en la terminal:
truss init falcon_7b_trussSi se te solicita crear un nuevo Truss, presiona ‘y’. Una vez que esté completo, deberías ver un nuevo directorio llamado falcon_7b_truss. Dentro de ese directorio, habrá algunos archivos y carpetas generados automáticamente. Hay un par de cosas que debemos completar: model.py que está anidado bajo el paquete model y config.yaml.
├── falcon_7b_truss│ ├── config.yaml│ ├── data│ ├── examples.yaml│ ├── model│ │ ├── __init__.py│ │ └── model.py│ └── packages└── main.pyComo mencioné anteriormente, Truss solo necesita el código de nuestro modelo, se encarga de todo lo demás automáticamente. Escribiremos el código dentro de model.py, pero debe estar escrito en un formato específico.
Truss espera que cada modelo admita al menos tres funciones: __init__, load y predict.
__init__se utiliza principalmente para crear variables de claseloades donde descargaremos el modelo de Hugging Facepredictes donde llamaremos a nuestro modelo
Aquí está el código completo para model.py:
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, pipelinefrom typing import DictMODEL_NAME = "tiiuae/falcon-7b-instruct"DEFAULT_MAX_LENGTH = 128class Model: def __init__(self, data_dir: str, config: Dict, **kwargs) -> None: self._data_dir = data_dir self._config = config self.device = "cuda" if torch.cuda.is_available() else "cpu" print("EL DISPOSITIVO EN EL QUE SE EJECUTA LA INFERENCIA ES: ", self.device) self.tokenizer = None self.pipeline = None def load(self): self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) model_8bit = AutoModelForCausalLM.from_pretrained( MODEL_NAME, device_map="auto", load_in_8bit=True, trust_remote_code=True) self.pipeline = pipeline( "text-generation", model=model_8bit, tokenizer=self.tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", ) def predict(self, request: Dict) -> Dict: with torch.no_grad(): try: prompt = request.pop("prompt") data = self.pipeline( prompt, eos_token_id=self.tokenizer.eos_token_id, max_length=DEFAULT_MAX_LENGTH, **request )[0] return {"data": data} except Exception as exc: return {"status": "error", "data": None, "message": str(exc)}Qué está sucediendo aquí:
MODEL_NAMEes el modelo que utilizaremos, que en nuestro caso es el modelofalcon-7b-instruct- Dentro de
load, descargamos el modelo de Hugging Face en 8 bits. La razón por la que queremos 8 bits es que el modelo utiliza significativamente menos memoria en nuestra GPU cuando está cuantizado. - También, cargar el modelo en 8 bits es necesario si quieres ejecutar el modelo localmente en una GPU con menos de 13 GB de VRAM.
- La función
predictacepta una solicitud JSON como parámetro y llama al modelo usandoself.pipeline. Eltorch.no_gradle indica a Pytorch que estamos en modo de inferencia, no en modo de entrenamiento.
¡Genial! Eso es todo lo que necesitamos para configurar nuestro modelo.
Paso 2: Ejecutar el modelo localmente (Opcional)
Si tienes una GPU Nvidia con más de 8 GB de VRAM, podrás ejecutar este modelo localmente.
Si no es así, siéntete libre de pasar al siguiente paso.
Necesitaremos descargar algunas dependencias adicionales para ejecutar el modelo localmente. Antes de descargar las dependencias, asegúrate de tener CUDA y los controladores de CUDA correctos instalados.
Como estamos tratando de ejecutar el modelo localmente, Truss no podrá ayudarnos a manejar la locura de CUDA.
pip install transformerspip install torchpip install peftpip install bitsandbytespip install einopspip install scipy A continuación, dentro de main.py, el script que creamos fuera del directorio falcon_7b_truss, necesitamos cargar nuestro truss.
Aquí está el código para main.py:
import trussfrom pathlib import Pathimport requeststr = truss.load("./falcon_7b_truss")output = tr.predict({"prompt": "Hola, ¿cómo estás?"})print(output)Qué está sucediendo aquí:
- Si recuerdas, el directorio
falcon_7b_trussfue creado por Truss. Podemos cargar todo ese paquete, incluido el modelo y las dependencias, utilizandotruss.load - Una vez que hayamos cargado nuestro paquete, simplemente podemos llamar al método
predictpara obtener la salida del modelo
Ejecuta main.py para obtener la salida del modelo.
Estos archivos de modelo tienen un tamaño de ~15 GB, por lo que puede llevar de 5 a 10 minutos descargar el modelo. Después de ejecutar el script, deberías ver una salida como esta:
{'data': {'generated_text': "Hola, ¿cómo estás?\nEstoy bien. Estoy en medio de una mudanza, así que estoy un poco cansado. También estoy un poco abrumado. No estoy seguro de cómo empezar. No estoy seguro de lo que estoy haciendo. No estoy seguro de si lo estoy haciendo bien. No estoy seguro de si lo estoy haciendo mal. No estoy seguro de si lo estoy haciendo en absoluto.\nNo estoy seguro de si lo estoy haciendo bien. No estoy seguro de si lo estoy haciendo mal. No lo estoy."}}Paso 3: Contenerizar el modelo usando Docker
Por lo general, cuando las personas contenerizan un modelo, toman el binario del modelo y las dependencias de Python y lo envuelven todo en un servidor Flask o Fast API.
Gran parte de esto es código de relleno y no queremos hacerlo nosotros mismos. Truss se encargará de ello. Ya hemos proporcionado el modelo, Truss creará el servidor, así que lo único que queda por hacer es proporcionar las dependencias de Python.
El archivo config.yaml contiene la configuración de nuestro modelo. Aquí es donde podemos agregar las dependencias para nuestro modelo. El archivo de configuración ya viene con la mayoría de las cosas que necesitamos, pero necesitaremos agregar algunas cosas.
Esto es lo que debes agregar a config.yaml:
apply_library_patches: truebundled_packages_dir: packagesdata_dir: datadescription: nullenvironment_variables: {}examples_filename: examples.yamlexternal_package_dirs: []input_type: Anylive_reload: falsemodel_class_filename: model.pymodel_class_name: Modelmodel_framework: custommodel_metadata: {}model_module_dir: modelmodel_name: Falcon-7Bmodel_type: custompython_version: py39requirements:- torch- peft- sentencepiece- accelerate- bitsandbytes- einops- scipy- git+https://github.com/huggingface/transformers.gitresources: use_gpu: true cpu: "3" memory: 14Gisecrets: {}spec_version: '2.0'system_packages: []Lo principal que hemos agregado es el requirements. Todas las dependencias listadas son necesarias para descargar y ejecutar el modelo.
Otra cosa importante que hemos agregado es el resources. El use_gpu: true es esencial, porque esto le dice a Truss que cree un Dockerfile para nosotros con soporte para GPU habilitado.
Eso es todo para la configuración.
A continuación, containerizaremos nuestro modelo. Si no sabes cómo containerizar un modelo usando Docker, no te preocupes, Truss te cubre.
Dentro del archivo main.py, le diremos a Truss que empacaremos todo junto. Aquí está el código que necesitas:
import truss
from pathlib import Path
import requests
str = truss.load("./falcon_7b_truss")
command = tr.docker_build_setup(build_dir=Path("./falcon_7b_truss"))
print(command)Qué está sucediendo:
- Primero, cargamos nuestro
falcon_7b_truss - A continuación, la función
docker_build_setupse encarga de todas las cosas complicadas, como crear el Dockerfile y configurar el servidor Fast API. - Si echas un vistazo a tu directorio
falcon_7b_truss, verás que se generaron muchos más archivos. No necesitamos preocuparnos por cómo funcionan estos archivos porque todo se gestionará detrás de escena. - Al final de la ejecución, obtenemos un comando docker para construir nuestra imagen docker:
docker build falcon_7b_truss -t falcon-7b-model:latest
Si deseas construir la imagen docker, adelante y ejecuta el comando de construcción. La imagen tiene un tamaño de ~9 GB, por lo que puede llevar un tiempo construirla. Si no quieres construirla pero quieres seguir adelante, puedes usar mi imagen: htrivedi05/truss-falcon-7b:latest.
Si estás construyendo la imagen tú mismo, deberás etiquetarla y subirla a Docker Hub para que nuestros contenedores en la nube puedan descargar la imagen. Aquí están los comandos que deberás ejecutar una vez que la imagen esté construida:
docker tag falcon-7b-model <docker_user_id>/falcon-7b-model
docker push <docker_user_id>/falcon-7b-model¡Genial! ¡Estamos listos para ejecutar nuestro modelo en la nube!
(Pasos opcionales a continuación para ejecutar la imagen localmente con GPU)
Si tienes una GPU Nvidia y quieres ejecutar tu modelo containerizado localmente con soporte para GPU, debes asegurarte de que Docker esté configurado para usar tu GPU.
Abre una terminal y ejecuta los siguientes comandos:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get update
apt-get install -y nvidia-docker2
sudo systemctl restart dockerAhora que tu Docker ha sido configurado para acceder a tu GPU, aquí te mostramos cómo ejecutar tu contenedor:
docker run --gpus all -d -p 8080:8080 falcon-7b-modelNuevamente, llevará un tiempo descargar el modelo. Para asegurarte de que todo funcione correctamente, puedes verificar los registros del contenedor y deberías ver “THE DEVICE INFERENCE IS RUNNING ON IS: cuda”.
Puedes llamar al modelo a través de un punto de acceso de API de la siguiente manera:
import requestsdata = {"prompt": "Hola, ¿cómo va todo?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)
print(res.json())Paso 4: Desplegando el modelo en producción
Estoy usando la palabra “producción” de manera bastante amplia aquí. Vamos a ejecutar nuestro modelo en Kubernetes, donde puede escalar fácilmente y manejar cantidades variables de tráfico.
Dicho esto, Kubernetes tiene una TONELADA de configuraciones, como políticas de red, almacenamiento, mapas de configuración, equilibrio de carga, gestión de secretos, etc.
Aunque Kubernetes está diseñado para “escalar” y ejecutar cargas de trabajo de “producción”, muchas de las configuraciones de nivel de producción que necesitas no vienen de serie. Cubrir esos temas avanzados de Kubernetes está fuera del alcance de este artículo y se aleja de lo que estamos tratando de lograr aquí. Por lo tanto, en esta publicación de blog, crearemos un clúster mínimo sin todas las características adicionales.
Sin más preámbulos, ¡creemos nuestro clúster!
Requisitos previos:
- Tener una cuenta de Google Cloud con un proyecto
- Tener instalada la CLI de gcloud en tu máquina
- Asegúrate de tener suficiente cuota para ejecutar una máquina habilitada para GPU. Puedes verificar tus cuotas en IAM y administración.
Creando nuestro clúster GKE
Usaremos el motor de Kubernetes de Google para crear y gestionar nuestro clúster. Ok, es hora de obtener información IMPORTANTE:
El motor de Kubernetes de Google NO es gratuito. Google no nos permitirá usar una poderosa GPU de forma gratuita. Dicho esto, estamos creando un clúster de un solo nodo con una GPU menos potente. No debería costarte más de $1-$2 para este experimento.
Aquí está la configuración para el clúster de Kubernetes que vamos a ejecutar:
- 1 nodo, clúster de Kubernetes estándar (no autopilot)
- 1 GPU Nvidia T4
- máquina n1-standard-4 (4 vCPU, 15 GB de memoria)
- Todo esto se ejecutará en una instancia spot
Nota: Si te encuentras en otra región y no tienes acceso a los mismos recursos exactos, siéntete libre de hacer modificaciones.
Pasos para crear el clúster:
- Dirígete a la consola de Google Cloud y busca el servicio llamado Kubernetes Engine
2. Haz clic en el botón CREAR
- Asegúrate de crear un clúster estándar, no un clúster autopilot. Debería decir Crear un clúster de Kubernetes en la parte superior.
3. Información básica del clúster
- Dentro de la pestaña de información básica del clúster, no queremos cambiar mucho. Simplemente dale un nombre a tu clúster. No es necesario cambiar la zona o el plano de control.
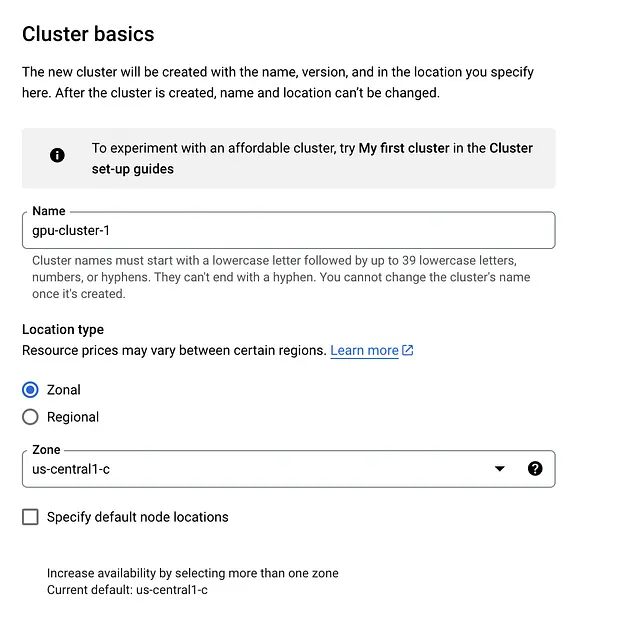
4. Haz clic en la pestaña default-pool y cambia el número de nodos a 1
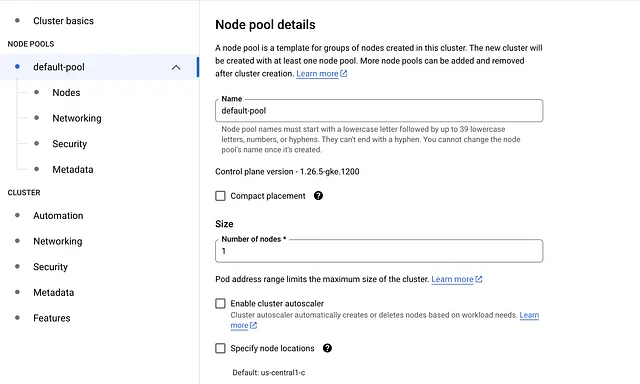
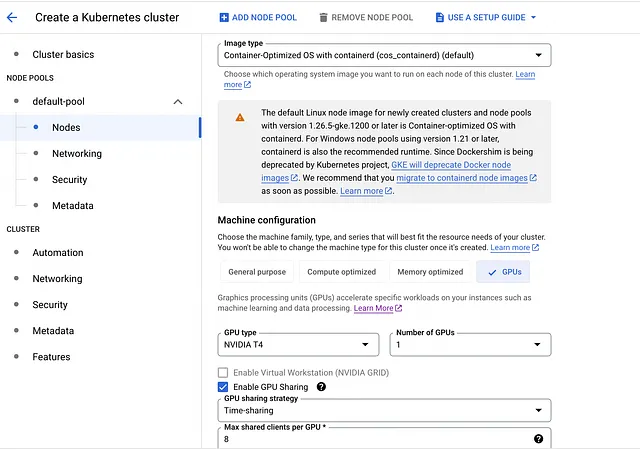
5. Bajo default-pool, haz clic en la pestaña Nodos en la barra lateral izquierda
- Cambia la Configuración de la máquina de <strong propósito general a GPU
- Selecciona la GPU Nvidia T4 como tipo de GPU y establece 1 para la cantidad
- Habilita el uso compartido de GPU (aunque no utilizaremos esta función)
- Establece el Máximo de clientes compartidos por GPU en 8
- Para el Tipo de máquina, selecciona n1-standard-4 (4 vCPU, 15 GB de memoria)
- Cambia el Tamaño del disco de arranque a 50
- Desplázate hasta la parte inferior y marca la casilla que dice: Habilitar nodos en máquinas virtuales spot
![]()
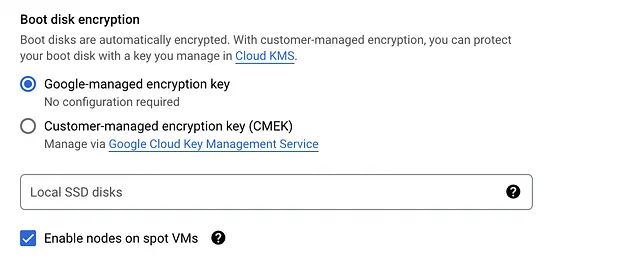
Aquí hay una captura de pantalla del precio estimado que obtuve para este clúster:
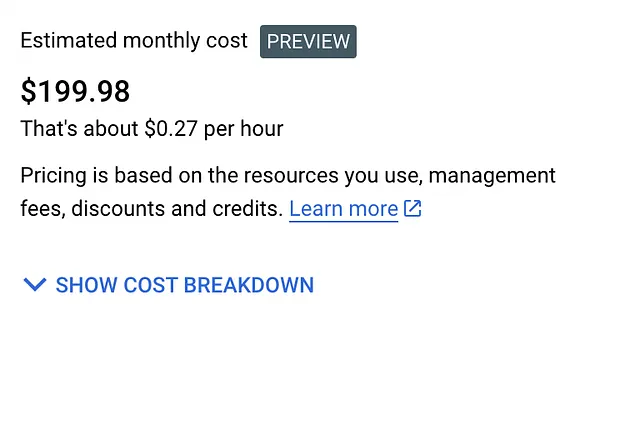
Una vez que hayas configurado el clúster, continúa y créalo.
Tomará unos minutos para que Google configure todo. Después de que tu clúster esté en funcionamiento, necesitamos conectarnos a él. Abre tu terminal y ejecuta los siguientes comandos:
gcloud config set compute/zone us-central1-c
gcloud container clusters get-credentials gpu-cluster-1Si usaste una zona de clúster o un nombre diferente, actualízalos en consecuencia. Para verificar que estamos conectados, ejecuta el siguiente comando:
kubectl get nodesDeberías ver 1 nodo aparecer en tu terminal. Aunque nuestro clúster tiene una GPU, le faltan algunos controladores de Nvidia que tendremos que instalar. Afortunadamente, instalarlos es fácil. Ejecuta el siguiente comando para instalar los controladores:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml¡Genial! Finalmente estamos listos para implementar nuestro modelo.
Implementando el modelo
Para implementar nuestro modelo en nuestro clúster, necesitamos crear una implementación de Kubernetes. Una implementación de Kubernetes nos permite administrar instancias de nuestro modelo en contenedores. No entraré en detalles sobre Kubernetes o cómo escribir archivos YAML, ya que está fuera de nuestro alcance.
Necesitas crear un archivo llamado truss-falcon-deployment.yaml. Abre ese archivo y pega el siguiente contenido:
apiVersion: apps/v1kind: Deploymentmetadata: name: truss-falcon-7b namespace: defaultspec: replicas: 1 selector: matchLabels: component: truss-falcon-7b-layer template: metadata: labels: component: truss-falcon-7b-layer spec: containers: - name: truss-falcon-7b-container image: <tu_id_de_docker>/falcon-7b-model:latest ports: - containerPort: 8080 resources: limits: nvidia.com/gpu: 1---apiVersion: v1kind: Servicemetadata: name: truss-falcon-7b-service namespace: defaultspec: type: ClusterIP selector: component: truss-falcon-7b-layer ports: - port: 8080 protocol: TCP targetPort: 8080Lo que está sucediendo:
- Le estamos diciendo a Kubernetes que queremos crear pods con nuestra imagen
falcon-7b-model. Asegúrate de reemplazar<tu_id_de_docker>con tu id actual. Si no creaste tu propia imagen de Docker y quieres usar la mía en su lugar, reemplázala con lo siguiente:htrivedi05/truss-falcon-7b:latest - Estamos habilitando el acceso a la GPU para nuestro contenedor estableciendo un límite de recursos
nvidia.com/gpu: 1. Esto le indica a Kubernetes que solicite solo una GPU para nuestro contenedor - Para interactuar con nuestro modelo, necesitamos crear un servicio de Kubernetes que se ejecutará en el puerto 8080
Crea la implementación ejecutando el siguiente comando en tu terminal:
kubectl create -f truss-falcon-deployment.yamlSi ejecutas el comando:
kubectl get deploymentsDeberías ver algo como esto:
NOMBRE LISTA ACTUALIZADO DISPONIBLE EDADtruss-falcon-7b 0/1 1 0 8sTomará unos minutos para que la implementación cambie al estado listo. Recuerde que el modelo debe descargarse de Hugging Face cada vez que se reinicia el contenedor. Puede verificar el progreso de su contenedor ejecutando el siguiente comando:
kubectl get pods
kubectl logs truss-falcon-7b-8fbb476f4-bggtsCambie el nombre del pod en consecuencia.
Hay algunas cosas que debe buscar en los registros:
- Busque la declaración de impresión EL DISPOSITIVO DE INFERENCIA EN EL QUE SE ESTÁ EJECUTANDO ES: cuda. Esto confirma que nuestro contenedor está correctamente conectado a la GPU.
- A continuación, debería ver algunas declaraciones de impresión sobre la descarga de los archivos del modelo
Descargando (…)model.bin.index.json: 100%|██████████| 16.9k/16.9k [00:00<00:00, 1.92MB/s]Descargando (…)l-00001-of-00002.bin: 100%|██████████| 9.95G/9.95G [02:37<00:00, 63.1MB/s]Descargando (…)l-00002-of-00002.bin: 100%|██████████| 4.48G/4.48G [01:04<00:00, 69.2MB/s]Descargando fragmentos: 100%|██████████| 2/2 [03:42<00:00, 111.31s/it][01:04<00:00, 71.3MB/s]- Una vez que el modelo se haya descargado y Truss haya creado el microservicio, debería ver la siguiente salida al final de sus registros:
{"asctime": "2023-06-29 21:40:40,646", "levelname": "INFO", "message": "La ejecución de model.load() se completó en 330588 ms"}A partir de este mensaje, podemos confirmar que el modelo está cargado y listo para la inferencia.
Inferencia del modelo
No podemos llamar directamente al modelo, en cambio, tenemos que llamar al servicio del modelo
Ejecute el siguiente comando para obtener el nombre de su servicio:
kubectl get svcResultado:
NOMBRE TIPO CLUSTER-IP EXTERNAL-IP PUERTO(S) EDADkubernetes ClusterIP 10.80.0.1 <none> 443/TCP 46mtruss-falcon-7b-service ClusterIP 10.80.1.96 <none> 8080/TCP 6m19sEl truss-falcon-7b-service es el que queremos llamar. Para hacer que el servicio sea accesible, necesitamos reenviar el puerto usando el siguiente comando:
kubectl port-forward svc/truss-falcon-7b-service 8080Resultado:
Reenviando desde 127.0.0.1:8080 -> 8080Reenviando desde [::1]:8080 -> 8080¡Genial, nuestro modelo está disponible como un punto de conexión de API REST en 127.0.0.1:8080! Abra cualquier script de Python, como main.py, y ejecute el siguiente código:
import requestsdata = {"prompt": "¿Cuál es la cosa más interesante de un halcón?"}res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)print(res.json())Resultado:
{'data': {'generated_text': '¿Cuál es la cosa más interesante de un halcón?\nLos halcones son conocidos por su increíble velocidad y agilidad en el aire, así como por sus impresionantes habilidades de caza. También son conocidos por su distintivo plumaje, que puede variar mucho dependiendo de la especie.'}}¡Hurra! ¡Hemos contenerizado con éxito nuestro modelo Falcon 7B y lo hemos implementado como un microservicio en producción!
Siéntete libre de jugar con diferentes comandos para ver qué devuelve el modelo.
Desactivando el clúster
Una vez que te hayas divertido jugando con Falcon 7B, puedes eliminar tu implementación ejecutando este comando:
kubectl delete -f truss-falcon-deployment.yamlA continuación, dirígete al motor de Kubernetes en Google Cloud y elimina el clúster de Kubernetes.
Nota: Todas las imágenes, a menos que se indique lo contrario, son del autor
Conclusión
Ejecutar y gestionar un modelo de calidad de producción como ChatGPT no es fácil. Sin embargo, con el tiempo, las herramientas mejorarán para que los desarrolladores puedan implementar sus propios modelos en la nube.
En esta publicación del blog, hemos abordado todo lo necesario para implementar un LLM en producción a un nivel básico. Empaquetamos el modelo con Truss, lo containerizamos con Docker y lo implementamos en la nube con Kubernetes. Sé que hay mucho que desempaquetar y no fue lo más fácil de hacer en el mundo, pero de todos modos lo logramos.
Espero que hayas aprendido algo interesante de esta publicación del blog. ¡Gracias por leer!
Paz.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprendizaje automático de efectos mixtos para variables categóricas de alta cardinalidad – Parte I una comparación empírica de diferentes métodos.
- Aprendiendo el lenguaje de las moléculas para predecir sus propiedades
- Anunciando el primer Desafío de Desaprendizaje Automático
- ‘Mi aplicación 3D favorita’ Fanático de Blender comparte su escena inspirada en Japón esta semana ‘En el NVIDIA Studio’
- 10 millones se registran en la aplicación rival de Twitter de Meta, Threads.
- Las ventas de automóviles nuevos despegan a medida que se alivia la escasez de chips.
- AI Sesgo Desafíos y Soluciones






