Conoce DenseDiffusion una técnica de IA sin entrenamiento para abordar subtítulos densos y manipulación de diseño en la generación de texto a imagen
DenseDiffusion una técnica de IA sin entrenamiento para abordar subtítulos densos y manipulación de diseño en la generación de texto a imagen.


Los avances recientes en los modelos de texto a imagen han llevado a sistemas sofisticados capaces de generar imágenes de alta calidad basadas en descripciones breves de escenas. Sin embargo, estos modelos encuentran dificultades cuando se enfrentan a subtítulos complicados, lo que a menudo resulta en la omisión o mezcla de atributos visuales relacionados con diferentes objetos. El término “densa” en este contexto se basa en el concepto de densidad de subtítulos, donde se utilizan frases individuales para describir regiones específicas dentro de una imagen. Además, los usuarios enfrentan desafíos para dictar con precisión la disposición de los elementos dentro de las imágenes generadas utilizando solo indicaciones textuales.
Varios estudios recientes han propuesto soluciones que otorgan a los usuarios un control espacial mediante el entrenamiento o refinamiento de modelos de texto a imagen condicionados a diseños. Mientras que enfoques específicos como “Make-aScene” y “Modelos de Difusión Latente” construyen modelos desde cero con condiciones tanto de texto como de diseño, otros métodos concurrentes como “SpaText” y “ControlNet” introducen controles espaciales complementarios a modelos de texto a imagen existentes mediante el ajuste fino. Desafortunadamente, el entrenamiento o ajuste fino de un modelo puede ser computacionalmente intensivo. Además, el modelo requiere volver a entrenar para cada condición de usuario novedosa, dominio o modelo de texto a imagen base.
Basado en los problemas mencionados anteriormente, se propone una nueva técnica sin entrenamiento llamada DenseDiffusion para acomodar subtítulos densos y proporcionar manipulación de diseño.
- Innovaciones autónomas en un mundo incierto
- Llevando la inteligencia artificial generativa en la búsqueda a más personas en todo el mundo
- Despliega un servicio de autorespuesta de preguntas con la solución QnABot en AWS, impulsado por Amazon Lex con Amazon Kendra y modelos de lenguaje amplios
Antes de presentar la idea principal, permítanme resumir brevemente cómo funcionan los modelos de difusión. Los modelos de difusión generan imágenes a través de pasos secuenciales de eliminación de ruido, comenzando desde ruido aleatorio. Las redes de predicción de ruido estiman el ruido agregado e intentan renderizar una imagen más nítida en cada paso. Los modelos recientes reducen el número de pasos de eliminación de ruido para obtener resultados más rápidos sin comprometer significativamente la imagen generada.
Dos bloques esenciales en los modelos de difusión de última generación son las capas de autoatención y de atención cruzada.
Dentro de una capa de autoatención, las características intermedias funcionan adicionalmente como características contextuales. Esto permite la creación de estructuras globalmente consistentes estableciendo conexiones entre los tokens de imagen que abarcan diversas áreas. Al mismo tiempo, una capa de atención cruzada se adapta en función de las características textuales obtenidas del título de texto de entrada, empleando un codificador de texto CLIP para la codificación.
Volviendo atrás, la idea principal detrás de DenseDiffusion es el proceso de modulación de atención revisado, que se presenta en la figura a continuación.
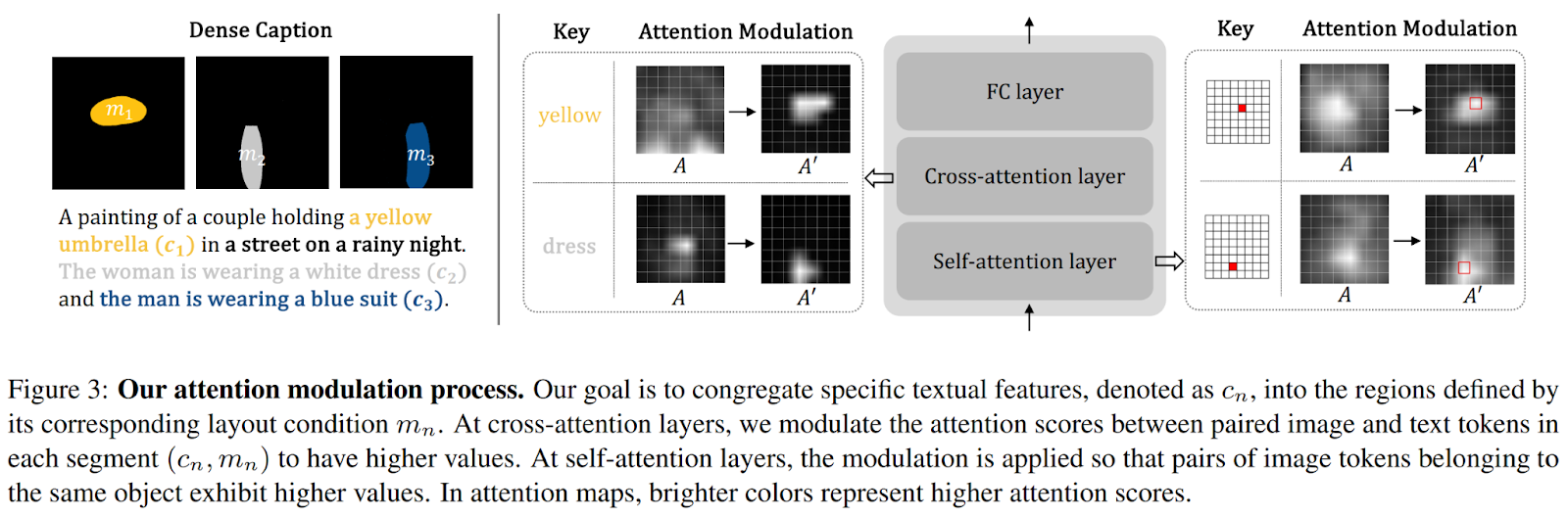
Inicialmente, se examinan las características intermedias de un modelo de difusión de texto a imagen pre-entrenado para revelar la correlación sustancial entre el diseño de la imagen generada y los mapas de autoatención y atención cruzada. Basándose en esta idea, los mapas de atención intermedia se ajustan dinámicamente en función de las condiciones de diseño. Además, el enfoque implica tener en cuenta el rango original de puntuación de atención y ajustar fino la extensión de modulación en función del área de cada segmento. En el trabajo presentado, los autores demuestran la capacidad de DenseDiffusion para mejorar el rendimiento del modelo “Stable Diffusion” y superar a múltiples modelos de difusión composicionales en términos de subtítulos densos, condiciones de texto y diseño, y calidad de imagen.
Se muestran a continuación los resultados de muestra seleccionados del estudio en la imagen a continuación. Estas imágenes proporcionan una visión comparativa entre DenseDiffusion y enfoques de última generación.

Esto fue un resumen de DenseDiffusion, una nueva técnica de entrenamiento de IA sin entrenamiento para acomodar subtítulos densos y proporcionar manipulación de diseño en la síntesis de texto a imagen.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Los camareros robots chinos alimentan la ansiedad coreana sobre la escasez de mano de obra
- Un nuevo protocolo para demostrar de manera confiable la ventaja computacional cuántica
- 5 Pequeños Negocios Lucrativos Que Sobrevivirán a la Oleada de IA
- Aquí están 7 trabajos pioneros en IA para tener en cuenta para el 2030
- Generar automáticamente impresiones a partir de hallazgos en informes de radiología utilizando IA generativa en AWS
- Por qué los científicos se adentran en el mundo virtual
- Doce naciones instan a los gigantes de las redes sociales a abordar el raspado ilegal de datos






