Aprendizaje por Refuerzo Profundo mejora algoritmos de ordenamiento
Deep Reinforcement Learning improves sorting algorithms.
Cómo Google DeepMind creó un algoritmo de ordenamiento más eficiente
La semana pasada, Google DeepMind publicó un artículo en la revista Nature en el que afirmaba haber encontrado un algoritmo de ordenamiento más eficiente utilizando el aprendizaje profundo por refuerzo (DLR). DeepMind es conocido por empujar los límites en el aprendizaje por refuerzo (RL). Hace algunos años, vencieron al mejor jugador en el juego de Go con su agente AlphaGo, después de usar un programa similar para aplastar a los motores de ajedrez existentes. En 2022, DeepMind presentó AlphaTensor, un programa que encontró un algoritmo de multiplicación de matrices más eficiente con DLR. Las técnicas utilizadas son similares al último logro de DeepMind: mejorar un algoritmo de ordenamiento estándar. En este artículo, discutiré cómo lograron esto introduciendo el aprendizaje por refuerzo, la búsqueda de árboles de Monte Carlo y los detalles del enfoque de DeepMind y el agente AlphaDev.
Ordenamiento
Escribir un algoritmo de ordenamiento es simple: comparar todos los valores uno por uno para encontrar el valor más bajo (o alto), guardar este valor en el primer elemento de la lista de retorno y continuar con el siguiente valor hasta que no quede ningún valor más. Aunque este algoritmo funcionará, está muy lejos de ser eficiente. Debido a que el ordenamiento es muy común en los programas de computadora, los algoritmos de ordenamiento eficientes son objeto de intensa investigación. DeepMind se centró en dos variantes de ordenamiento: Ordenamiento fijo y ordenamiento variable. El ordenamiento fijo implica ordenar una secuencia de valores con una longitud fija y predefinida. En el ordenamiento variable, el tamaño de la lista de valores no está definido de antemano. Solo se proporciona el tamaño máximo de la lista. Ambas variantes de ordenamiento se utilizan extensamente en los algoritmos de ordenamiento de última generación. A menudo, una lista grande se ordena ordenando repetidamente pequeñas secciones de la lista.
Los algoritmos de última generación utilizan redes de ordenamiento, llamadas redes de ordenamiento en ambos ordenamientos fijos y variables. En este artículo, no discutiré los detalles de las redes de ordenamiento. Puede encontrar más información aquí .
Aprendizaje por refuerzo
En esta sección, presentaré los conceptos principales del aprendizaje por refuerzo. El aprendizaje por refuerzo es una rama del aprendizaje automático, en el que se encarga a un agente encontrar las mejores acciones en un entorno, dada la situación actual. La situación de un entorno contiene todos los aspectos relevantes de un entorno que pueden o deben influir en la acción a tomar. La mejor acción se define como la acción que maximiza la recompensa acumulada (descontada). Las acciones se toman secuencialmente, y después de cada acción, se registran la recompensa obtenida y la nueva situación. Por lo general, un entorno tiene algún criterio de terminación después del cual comienza el siguiente episodio. Las primeras versiones de RL usaban tablas para llevar un registro del valor de ciertas situaciones y acciones con la idea de siempre tomar la acción con el valor más alto. A menudo, estas tablas son reemplazadas por redes neuronales profundas porque pueden generalizar mejor y enumerar todas las situaciones es a menudo imposible. Cuando se usan redes neuronales profundas para el aprendizaje por refuerzo, se usa el término aprendizaje profundo por refuerzo.
- Más allá de NeRFs (Parte Dos)
- Microsoft AI presenta Orca un modelo de 13 mil millones de parámetros que aprende a imitar el proceso de razonamiento de los LFM (modelos de fundación grandes).
- 10 Cursos Cortos Gratuitos Para Dominar la Inteligencia Artificial Generativa
Búsqueda de árboles de Monte Carlo
AlphaDev se entrena utilizando el aprendizaje profundo por refuerzo y la búsqueda de árboles de Monte Carlo, que es un algoritmo de búsqueda para encontrar la mejor acción dada alguna situación inicial. A menudo se combina con DRL, por ejemplo, en AlphaZero y AlphaGo. Merece su propio artículo, pero se proporciona un resumen aquí.
La búsqueda de árboles de Monte Carlo (MCTS) construye un árbol de posibles situaciones de resultado donde la situación actual es el nodo raíz. Para un número dado de simulaciones, se explorará este árbol para encontrar las consecuencias de tomar ciertas acciones. En cada simulación, se utiliza una simulación de juego (a veces llamada juego completo) para expandir un nodo en nodos secundarios si el juego no se termina en ese punto. La probabilidad de seleccionar una acción se basa en criterios de selección. En nuestro caso, la probabilidad de seleccionar una acción se da por la red de política que se discutirá a continuación. El valor de un nodo es una medida de cuán buena es la situación de ese nodo. Se determina mediante la red de valor, que también se discute en una sección futura. Si se alcanza un estado terminal, el valor se reemplaza por el valor de recompensa verdadero del entorno.
Los valores se propagan hacia arriba por el árbol de búsqueda. De esta manera, el valor de la situación actual depende del valor de las situaciones a las que se puede llegar desde la situación actual.
Enfoque de DeepMind
El agente DRL de DeepMind que está entrenado para mejorar la implementación del algoritmo de ordenamiento se llama AlphaDev. La tarea de AlphaDev es escribir un algoritmo de ordenamiento más eficiente en Assembly. Assembly es el puente entre los lenguajes de alto nivel como C++, Java y Python y el código de máquina. Si usas sort en C++, el compilador compila tu programa en código de ensamblador. Luego, el ensamblador convierte este código en código de máquina. AlphaDev tiene la tarea de seleccionar una serie de instrucciones de ensamblador para crear un algoritmo de ordenamiento que sea correcto y rápido. Esta es una tarea difícil porque agregar una instrucción puede hacer que el programa esté completamente equivocado, incluso si era correcto antes.
AlphaDev encuentra un algoritmo de ordenamiento eficiente creando y resolviendo el AssemblyGame. En cada turno, debe seleccionar una acción correspondiente a una instrucción de CPU. Al formular este problema como un juego, se puede ajustar fácilmente al marco de aprendizaje por refuerzo estándar.
Formulación de aprendizaje por refuerzo
Una formulación estándar de RL contiene estados, acciones, recompensas y un criterio de terminación.
Estado
El estado del AssemblyGame consta de dos partes. Primero, una representación del programa actual. AlphaDev utiliza la salida de un Transformer, una arquitectura de red neuronal, para representar el algoritmo actual. Los Transformers han tenido mucho éxito recientemente con grandes modelos de lenguaje y son una opción adecuada para codificar el algoritmo actual porque está basado en texto. La segunda parte del estado es una representación del estado de la memoria y los registros después de ejecutar el algoritmo actual. Esto se hace mediante una red neuronal profunda convencional.
Acción
Las acciones del AssemblyGame son agregar una instrucción de ensamblador legal al programa. AlphaDev puede elegir agregar cualquier instrucción siempre que sea legal. DeepMind creó las siguientes seis reglas para acciones legales:
- Las ubicaciones de memoria siempre se leen en orden incremental
- Los registros se asignan en orden incremental
- Leer y escribir en cada ubicación de memoria una vez
- No hay instrucciones de comparación consecutivas
- No hay comparación o movimientos condicionales a la memoria
- No se pueden utilizar registros no inicializados
Las dos últimas acciones son ilegales desde el punto de vista de la programación, las demás se cumplen porque no cambiarán el programa. Al eliminar estas acciones, el espacio de búsqueda se limita sin afectar el algoritmo.
Recompensa
La recompensa del AssemblyGame es una combinación de dos partes. El primer elemento de la recompensa es una puntuación de corrección. Basado en una serie de secuencias de prueba, se evalúa el algoritmo proporcionado. Cuanto más cerca esté el algoritmo de ordenar correctamente la secuencia de prueba, mayor será la recompensa por corrección. El segundo elemento de la recompensa es la velocidad o latencia del programa. Se mide por el número de líneas del programa, si no hay ramas condicionales. En la práctica, esto significa que la longitud del programa se usa para ordenamiento fijo porque no se requieren condiciones para ese programa. Para el ordenamiento variable, el algoritmo debe condicionar en la longitud real de la secuencia. Debido a que no todas las partes del algoritmo se utilizan durante el ordenamiento, se mide la latencia real del programa en lugar del número de líneas.
Terminación y objetivo
Según el documento publicado por DeepMind, terminan el AssemblyGame después de “un número limitado de pasos”. Lo que esto significa exactamente no está claro, pero supongo que limitan el número de pasos en función del punto de referencia humano actual. El objetivo del juego es encontrar un algoritmo correcto y rápido. Si AlphaDev proporciona un algoritmo incorrecto o lento, se pierde el juego.
Redes de política y valor
Para usar la búsqueda de árbol de Monte Carlo, se requiere una política y una red de valor. La red de política establece la probabilidad para cada acción y la red de valor se entrena para evaluar un estado. La red de política se actualiza en función del número de visitas de un estado determinado. Esto crea un procedimiento iterativo, donde la política se usa para realizar MCTS y la red de política se actualiza con el número de visitas de un estado en MCTS.
La red de valor produce dos valores, uno para la corrección del algoritmo y otro para la latencia del algoritmo. Según DeepMind, esto produce mejores resultados que combinar estos valores en una puntuación por la red. La red de valor se actualiza en función de las recompensas obtenidas.
Resultados
Después de entrenar a AlphaDev, encontró algoritmos más cortos para el ordenamiento fijo con longitudes de secuencia de 3 y 5. Para el ordenamiento fijo con longitud 4, encontró la implementación actual, por lo que no se hizo ninguna mejora allí. AlphaDev logró estos resultados para el ordenamiento fijo aplicando dos nuevas ideas. Estas nuevas ideas, llamadas movimiento de intercambio y de copia, resultan en menos comparaciones entre valores y, por lo tanto, en un algoritmo más rápido. Para el ordenamiento fijo con longitud 3, DeepMind demostró que no existe un programa más corto mediante la fuerza bruta a través de todas las opciones con una longitud de programa más corta. Para programas más largos, este enfoque es inviable, ya que el espacio de búsqueda crece exponencialmente.
Para la clasificación de variables, AlphaDev ideó un nuevo diseño del algoritmo. Por ejemplo, para la clasificación de variables en una secuencia con una longitud de hasta 4, AlphaDev sugirió primero ordenar 3 valores y luego realizar una versión simplificada de ordenamiento para el último elemento restante. La figura a continuación muestra el diseño del algoritmo para Varsort (4) proporcionado por AlphaDev.
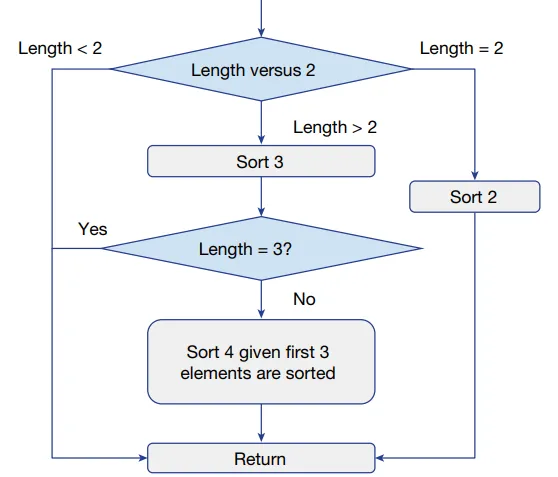
En general, se encontraron algoritmos más rápidos para clasificación fija y variable, demostrando que DRL se puede utilizar para implementar algoritmos eficientes. La implementación de clasificación en C++ se ha actualizado para utilizar estos nuevos algoritmos. Los detalles sobre las mejoras de rendimiento logradas por AlphaDev se pueden encontrar en la tabla a continuación.
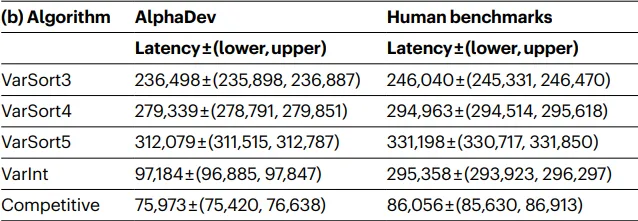
Para probar si este enfoque se generaliza a otras implementaciones de programación, DeepMind también probó AlphaDev en un desafío de codificación competitiva y un protocolo de búfer utilizado por Google. En ambos casos, AlphaDev pudo idear implementaciones más eficientes, lo que demuestra que DLR con la búsqueda de árbol de Monte Carlo es un enfoque válido para encontrar implementaciones eficientes para algoritmos comunes.
Conclusión
El aprendizaje por refuerzo profundo ha demostrado ser exitoso en muchos entornos diferentes, desde juegos como Go y Ajedrez hasta la implementación de algoritmos como se ve aquí. Aunque el dominio es desafiante, a menudo dependiente de detalles de implementación de bajo nivel y elecciones de hiperparámetros, estos éxitos muestran los resultados que se pueden lograr con este concepto poderoso.
Espero que este artículo le haya dado una idea de los últimos logros en RL. Si desea una explicación más detallada de la búsqueda de árboles de Monte Carlo u otros algoritmos que discutí, ¡hágamelo saber!
Fuentes
[1] K. Batcher, Redes de clasificación y sus aplicaciones (1968), Actas de la conferencia conjunta de computación de primavera del 30 de abril al 2 de mayo de 1968 (pp. 307-314)
[2] D. Mankowitz et al., Algoritmos de clasificación más rápidos descubiertos mediante aprendizaje por refuerzo profundo (2023), Nature 618.7964: 257-263
[3] D. Silver et al., Dominando el ajedrez y el shogi mediante la autojugada con un algoritmo general de aprendizaje por refuerzo (2017), preimpresión arXiv arXiv:1712.01815
[4] D. Silver et al., Dominando el juego del Go con redes neuronales profundas y búsqueda de árbol (2016), Nature 529.7587: 484-489
[5] A. Fawzi et al., Descubrimiento de algoritmos de multiplicación de matrices más rápidos con aprendizaje por refuerzo (2022), Nature 610.7930: 47-53
[6] C. Browne et al., Una encuesta de métodos de búsqueda de árbol de Monte Carlo (2012), IEEE Transactions on Computational Intelligence and AI en juegos 4.1: 1-43.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- FastAPI y Streamlit El dúo de Python que debes conocer.
- AVFormer Inyectando visión en modelos de habla congelados para la conversión automática de voz a texto sin entrenamiento previo (AV-ASR).
- Rendimiento sobrehumano en la prueba Atari 100K El poder de BBF – Un nuevo agente de RL basado en valores de Google DeepMind, Mila y la Universidad de Montreal.
- Ejecutando Falcon en una CPU con Hugging Face Pipelines.
- La huella digital de ChatGPT DNA-GPT es un método de detección de texto generado por GPT que utiliza un análisis divergente de N-gramos.
- Acelerando el Acelerador Científico Acelera la Computación de Alto Rendimiento de CERN con GPUs y IA.
- 3 preguntas Jacob Andreas sobre modelos de lenguaje grandes






