Aprendizaje Profundo con R
Deep Learning with R.
En este tutorial, aprende cómo realizar una tarea de aprendizaje profundo en R.
Introducción
¿Quién no se ha sorprendido por los avances tecnológicos, especialmente en inteligencia artificial, desde Alexa hasta los coches autónomos de Tesla y una miríada de otras innovaciones? Me maravillo de los avances cada dos días, pero lo que es aún más interesante es cuando se tiene una idea de lo que subyace a esas innovaciones. Bienvenido al mundo de la inteligencia artificial y a las infinitas posibilidades del aprendizaje profundo. Si te has estado preguntando qué es, entonces estás en el lugar correcto.
En este tutorial, descompondré la terminología y te guiaré sobre cómo realizar una tarea de aprendizaje profundo en R. Cabe destacar que este artículo asumirá que tienes un conocimiento básico de los conceptos de aprendizaje automático, como la regresión, la clasificación y el clustering.
- Proyecto RedPajama Una iniciativa de código abierto para democratizar los modelos de lenguaje de aprendizaje automático (LLM)
- Técnicas avanzadas de selección de características para modelos de aprendizaje automático
- AI Modelos de Lenguaje y Visión de Gran Escala
Comencemos con las definiciones de algunos términos que rodean el concepto de aprendizaje profundo:
El aprendizaje profundo es una rama del aprendizaje automático que enseña a las computadoras a imitar las funciones cognitivas del cerebro humano. Esto se logra mediante el uso de redes neuronales artificiales que ayudan a descomponer patrones complejos en conjuntos de datos. Con el aprendizaje profundo, una computadora puede clasificar sonidos, imágenes o incluso textos.
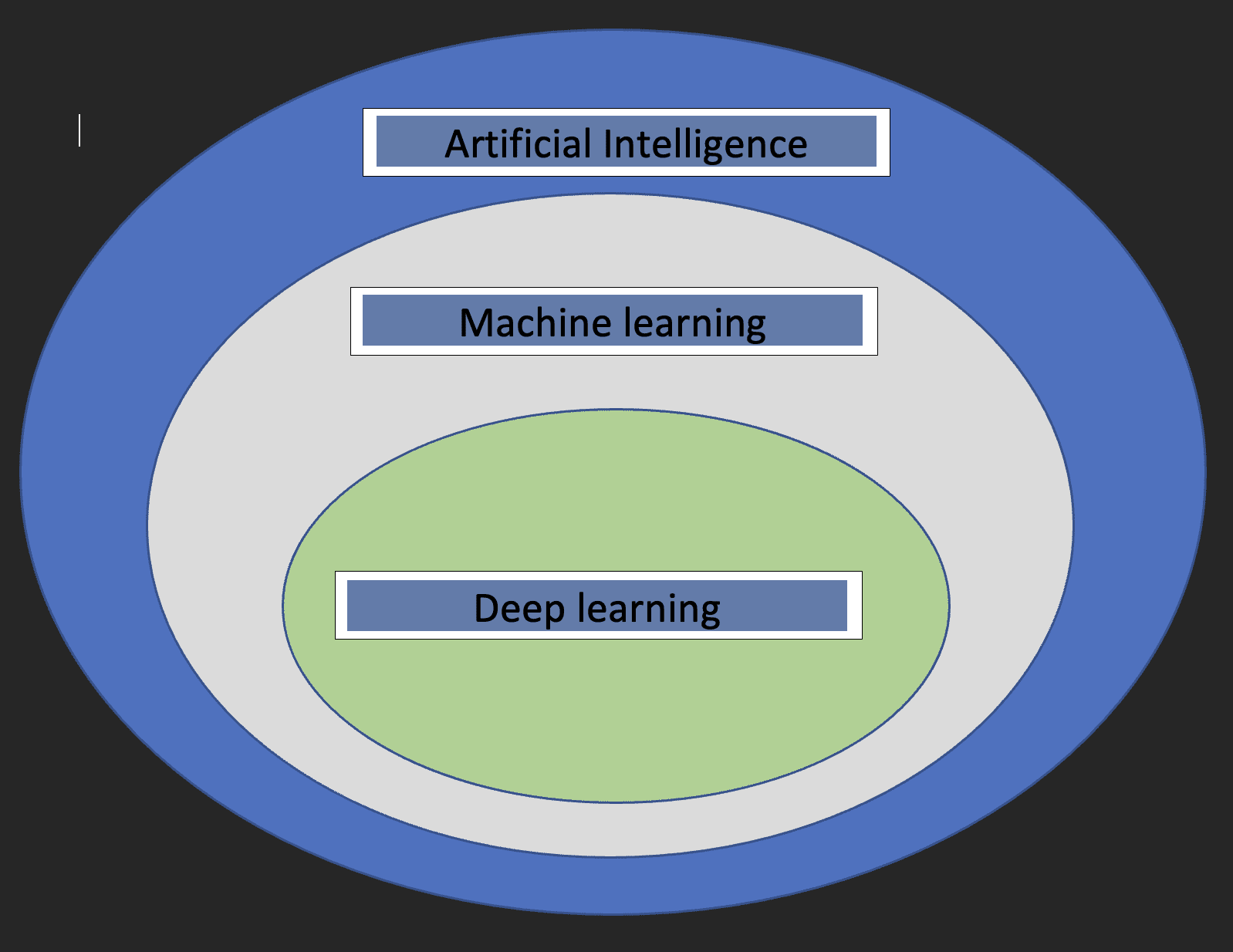
Antes de sumergirnos en los detalles del aprendizaje profundo, sería bueno entender qué son el aprendizaje automático y la inteligencia artificial, y cómo se relacionan los tres conceptos entre sí.
Inteligencia artificial: esta es una rama de la informática que se ocupa del desarrollo de máquinas cuyo funcionamiento imita al cerebro humano.
Aprendizaje automático: este es un subconjunto de la inteligencia artificial que permite a las computadoras aprender de los datos.
Con las definiciones anteriores, ahora tenemos una idea de cómo se relaciona el aprendizaje profundo con la inteligencia artificial y el aprendizaje automático.
El siguiente diagrama ayudará a mostrar la relación.
Dos cosas cruciales a tener en cuenta sobre el aprendizaje profundo son:
- Requiere grandes volúmenes de datos
- Requiere una alta capacidad de procesamiento informático
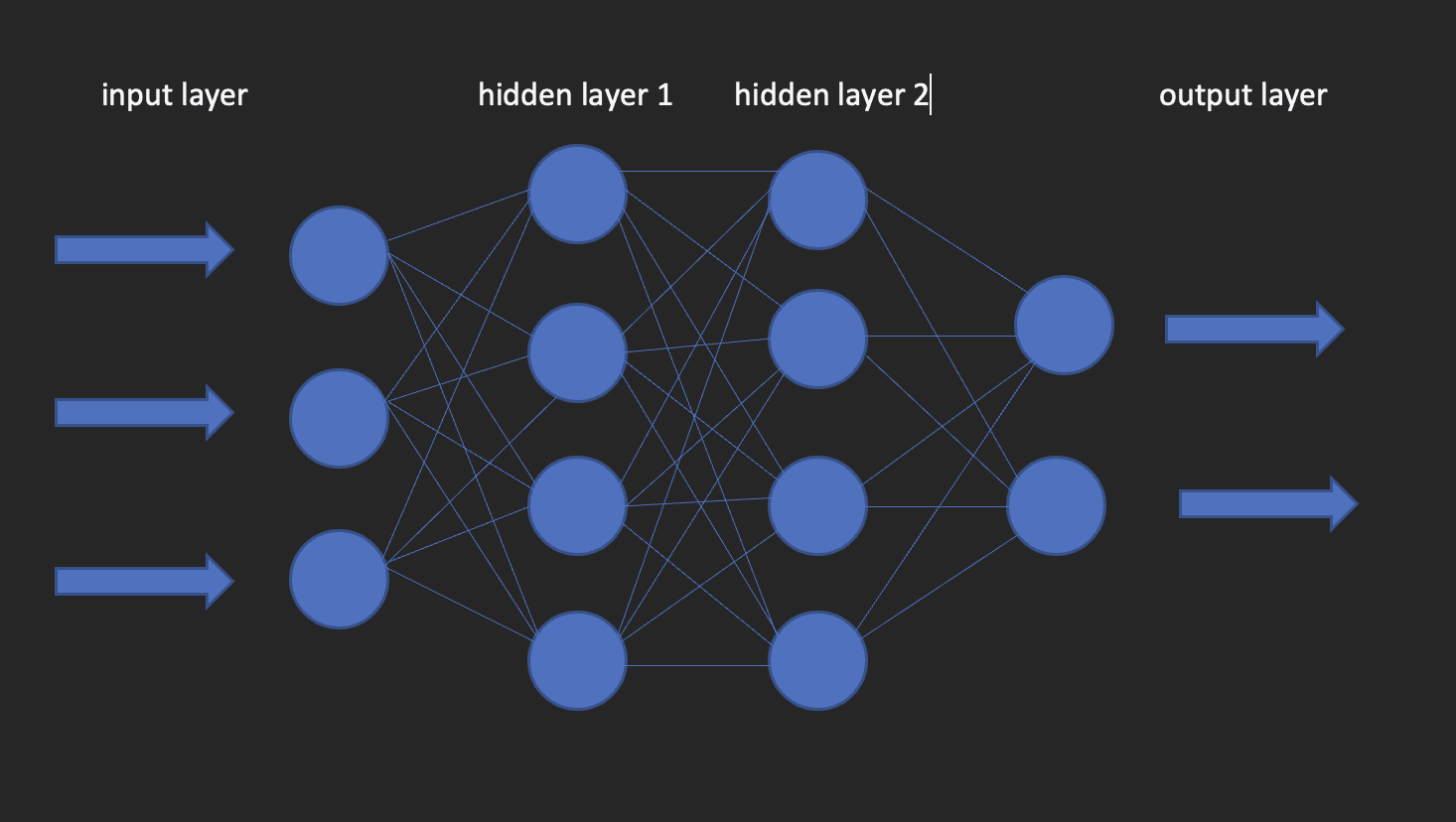
Redes Neuronales
Estos son los bloques de construcción de los modelos de aprendizaje profundo. Como sugiere el nombre, la palabra “neuronal” proviene de las neuronas, al igual que las neuronas del cerebro humano. De hecho, la arquitectura de las redes neuronales profundas se inspira en la estructura del cerebro humano.
Una red neuronal tiene una capa de entrada, una capa oculta y una capa de salida. Esta red se llama red neuronal superficial. Cuando tenemos más de una capa oculta, se convierte en una red neuronal profunda, donde las capas podrían ser tantas como cientos.
La imagen a continuación muestra cómo es una red neuronal.
Esto nos lleva a la pregunta de cómo construir modelos de aprendizaje profundo en R. ¡Entremos en kera!
Keras es una biblioteca de aprendizaje profundo de código abierto que facilita el uso de redes neuronales en el aprendizaje automático. Esta biblioteca es un envoltorio que utiliza TensorFlow como motor de backend. Sin embargo, existen otras opciones para el backend, como Theano o CNTK.
Ahora, instalemos tanto TensorFlow como Keras.
Comencemos con la creación de un entorno virtual usando reticulate
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3")
install.packages(“tensorflow”) #¡Esto se hace solo una vez!
library(tensorflow)
install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu")
install.packages(“keras”) #¡Haz esto una vez!
library(keras)
install_keras(envname = "/path/to/your/virtualenv")
# confirma que la instalación fue exitosa
tf$constant("¡Hola TensorFlow!")Ahora que nuestras configuraciones están listas, podemos pasar a cómo podemos usar el aprendizaje profundo para resolver un problema de clasificación.
Breve sobre los Datos
Los datos que utilizaré para este tutorial provienen de una encuesta salarial en curso realizada por https://www.askamanager.org .
La pregunta principal que se hace en el formulario es cuánto dinero ganas, además de algunos detalles más como la industria, la edad, los años de experiencia, etc. Los detalles se recopilan en una hoja de Google de la cual obtuve los datos.
El problema que queremos resolver con los datos es poder crear un modelo de aprendizaje profundo que prediga cuánto dinero podría ganar alguien dado información como la edad, el género, los años de experiencia y el nivel más alto de educación.
Cargamos las librerías que necesitaremos.
library(dplyr)
library(keras)
library(caTools)Importamos los datos
url <- “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv”
salary_data <- read.csv(url)Seleccionamos las columnas que necesitamos
salary_data <- salary_data %>% select(edad,años_de_experiencia_profesional,género,nivel_más_alto_de_educación,salario_anual)Limpieza de datos
¿Recuerdas el concepto informático GIGO? (Basura entra, basura sale). Bueno, este concepto es perfectamente aplicable aquí como lo es en otros campos. Los resultados de nuestro entrenamiento dependerán en gran medida de la calidad de los datos que usemos. Es por eso que la limpieza y transformación de datos son pasos críticos en cualquier proyecto de Ciencia de Datos.
Algunos de los problemas clave que la limpieza de datos busca abordar son: consistencia, valores faltantes, problemas de ortografía, valores atípicos y tipos de datos. No entraré en detalles sobre cómo se abordan esos problemas y esto se debe a la simple razón de no querer desviarme del tema de este artículo. Por lo tanto, usaré la versión limpia de los datos, pero si estás interesado en saber cómo se manejó la limpieza, consulta este artículo.
Transformaciones de datos
Las redes neuronales artificiales aceptan solo variables numéricas y dado que algunas de nuestras variables son de naturaleza categórica, deberemos codificarlas en números. Esto forma parte del paso de preprocesamiento de datos, que es necesario porque con frecuencia no obtendrás datos listos para el modelado.
# creamos una función de codificación
encode_ordinal <- function(x, order = unique(x)) {
x <- as.numeric(factor(x, levels = order, exclude = NULL))
}
salary_data <- salary_data %>% mutate(
nivel_más_alto_de_educación = encode_ordinal(nivel_más_alto_de_educación, order = c("Escuela secundaria","Licenciatura","Maestría","Título profesional (MD, JD, etc.)","PhD")),
años_de_experiencia_profesional = encode_ordinal(años_de_experiencia_profesional,
order = c("1 año o menos", "2-4 años","5-7 años", "8-10 años", "11-20 años", "21-30 años", "31-40 años", "41 años o más")),
edad = encode_ordinal(edad, order = c("menor de 18 años", "18-24 años","25-34 años", "35-44 años", "45-54 años", "55-64 años","65 años o más")),
género = case_when(género == "Mujer" ~ 0,
género == "Hombre" ~ 1))Dado que queremos resolver una clasificación, necesitamos categorizar el salario anual en dos clases para que lo usemos como variable de respuesta.
salary_data <- salary_data %>%
mutate(categorias = case_when(
salario_anual <= 100000 ~ 0,
salario_anual > 100000 ~ 1))
salary_data <- salary_data %>% select(-salario_anual)Dividir los datos
Al igual que en los enfoques básicos de aprendizaje automático; regresión, clasificación y agrupación, deberemos dividir nuestros datos en conjuntos de entrenamiento y prueba. Hacemos esto utilizando la regla 80-20, que es el 80% del conjunto de datos para entrenamiento y el 20% para prueba. Esto no es una regla estricta, ya que puedes decidir usar cualquier relación de separación que consideres adecuada, pero ten en cuenta que el conjunto de entrenamiento debe tener una buena proporción de los porcentajes.
set.seed(123)
sample_split <- sample.split(Y = salary_data$categorias, SplitRatio = 0.7)
train_set <- subset(x=salary_data, sample_split == TRUE)
test_set <- subset(x = salary_data, sample_split == FALSE)
y_train <- train_set$categorias
y_test <- test_set$categorias
x_train <- train_set %>% select(-categorias)
x_test <- test_set %>% select(-categorias)Keras toma entradas en forma de matrices o arreglos. Usamos la función as.matrix para la conversión. Además, necesitamos escalar las variables predictoras y luego convertir la variable de respuesta en un tipo de datos categórico.
x <- as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x))))
y <- to_categorical(y_train, num_classes = 2)Instanciar el modelo
Crear un modelo secuencial en el que agregaremos capas usando el operador pipe.
model = keras_model_sequential()Configurar las capas
La input_shape especifica la forma de los datos de entrada. En nuestro caso, lo hemos obtenido usando la función ncol. activation : Aquí especificamos la función de activación; una función matemática que transforma la salida en un formato no lineal deseado antes de pasarla a la siguiente capa.
units : el número de neuronas en cada capa de la red neuronal.
model %>%
layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>%
layer_dense(units = 10, activation = "relu") %>%
layer_dense(units = 2, activation = "sigmoid")Configurar el proceso de aprendizaje del modelo
Usamos el método compile para hacer esto. La función toma tres argumentos;
optimizer : Este objeto especifica el procedimiento de entrenamiento. loss : Esta es la función a minimizar durante la optimización. Las opciones disponibles son mse (error cuadrático medio), binary_crossentropy y categorical_crossentropy.
metrics : Lo que usamos para monitorear el entrenamiento. Precisión para problemas de clasificación.
model %>%
compile(
loss = "binary_crossentropy",
optimizer = "adagrad",
metrics = "accuracy"
)Ajuste del modelo
Ahora podemos ajustar el modelo usando el método fit de Keras. Algunos de los argumentos que toma fit son:
epochs : Una época es una iteración sobre el conjunto de datos de entrenamiento.
batch_size : El modelo divide la matriz / array pasada en lotes más pequeños sobre los que itera durante el entrenamiento.
validation_split : Keras necesitará dividir una porción de los datos de entrenamiento para obtener un conjunto de validación que se utilizará para evaluar el rendimiento del modelo para cada época.
shuffle : Aquí indicas si deseas o no mezclar tus datos de entrenamiento antes de cada época.
fit = model %>%
fit(
x = x,
y = y,
shuffle = T,
validation_split = 0.2,
epochs = 100,
batch_size = 5
)Evaluar el modelo
Para obtener el valor de precisión del modelo, use la función evaluate como se muestra a continuación.
y_test <- to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)Predicción
Para predecir en nuevos datos, use la función predict_classes de la biblioteca Keras como se muestra a continuación.
model %>% predict(as.matrix(x_test))Conclusión
Este artículo te ha llevado a través de los conceptos básicos del aprendizaje profundo con Keras en R. Eres bienvenido a profundizar para una mejor comprensión, jugar con los parámetros, ensuciarte las manos con la preparación de datos y quizás escalar los cálculos aprovechando el poder de la computación en la nube. Clinton Oyogo, escritor de Saturn Cloud, cree que analizar datos para obtener información accionable es una parte crucial de su trabajo diario. Con sus habilidades en visualización de datos, manipulación de datos y aprendizaje automático, se enorgullece de su trabajo como científico de datos.
Original. Publicado con permiso.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Escala tus cargas de trabajo de aprendizaje automático en Amazon ECS impulsado por instancias AWS Trainium.
- Entrena un Modelo de Lenguaje Grande en una sola GPU de Amazon SageMaker con Hugging Face y LoRA.
- Subtítulos visuales Usando modelos de lenguaje grandes para mejorar las videoconferencias con visuales dinámicos.
- Evaluando la síntesis del habla en varios idiomas con SQuId






