Decodificando la Sinfonía del Sonido Procesamiento de Señales de Audio para la Ingeniería Musical
Decoding the Symphony of Sound Audio Signal Processing for Music Engineering
La Guía Definitiva para la Extracción de Características de Audio en el Dominio del Tiempo y la Frecuencia utilizando Python
Imagen de OpenClipart-Vectors en Pixabay
Contenidos
Introducción
Extracción de Características en el Dominio del Tiempo 2.1 Fundamentos del Procesamiento de Señales de Audio: Tamaño de Trama y Longitud de Salto 2.2 Característica 1: Envolvente de Amplitud 2.3 Característica 2: Energía de la Media Cuadrática 2.4 Característica 3: Factor de Cresta 2.5 Característica 4: Tasa de Cruce por Cero
Extracción de Características en el Dominio de la Frecuencia 3.1 Característica 5: Relación de Energía en las Bandas 3.2 Característica 6: Centroide Espectral 3.3 Característica 7: Ancho de Banda Espectral 3.4 Característica 8: Planicidad Espectral
Conclusión
Referencias
Introducción
La capacidad de procesar y analizar datos de diferentes tipos para obtener ideas prácticas es una de las habilidades más importantes de la era de la información. Los datos nos rodean: desde los libros que leemos hasta las películas que vemos, desde las publicaciones de Instagram que nos gustan hasta la música que escuchamos. En este artículo, intentaremos comprender los fundamentos del Procesamiento de Señales de Audio:
¿Cómo lee una computadora una señal de audio?
¿Qué son las características en el dominio del tiempo y de la frecuencia?
¿Cómo se extraen estas características?
¿Por qué es necesario extraer estas características?
En particular, cubriremos en detalle las siguientes características:
Características en el Dominio del Tiempo: Envolvente de amplitud, energía de la media cuadrática, factor de cresta (y relación de potencia pico-promedio), tasa de cruce por cero.
Características en el Dominio de la Frecuencia: Relación de energía en las bandas, centroide espectral, ancho de banda espectral (distribución), planicidad espectral.
Describiremos la teoría y escribiremos códigos en Python desde cero para extraer cada una de estas características para señales de audio de 3 instrumentos musicales diferentes: Guitarra acústica, Metal y Batería. Los archivos de datos de audio de muestra utilizados se pueden descargar aquí: https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction
El archivo de código completo también está disponible en el repositorio mencionado anteriormente o se puede acceder a través de este enlace: https://github.com/namanlab/Audio-Signal-Processing-Feature-Extraction/blob/main/Audio_Signal_Extraction.ipynb
Extracción de Características en el Dominio del Tiempo
Comencemos recordando qué es el sonido y cómo lo percibimos. Como algunos de ustedes recordarán de sus lecciones de secundaria, el sonido es la propagación de vibraciones a través de un medio. La producción de sonido hace que las moléculas de aire circundantes se vibren, lo que se manifiesta en regiones alternantes de compresión (alta presión) y rarefacción (baja presión). Estas compresiones y rarefacciones viajan a través del medio y llegan a nuestros oídos, lo que nos permite percibir el sonido tal como es. Por lo tanto, la propagación del sonido implica la transmisión de estas variaciones de presión a lo largo del tiempo. La representación en el dominio del tiempo del sonido implica capturar y analizar estas variaciones de presión en diferentes intervalos de tiempo mediante el muestreo de la onda de sonido en puntos discretos en el tiempo (normalmente utilizando una técnica de grabación de audio digital). Cada muestra representa el nivel de presión sonora en un momento específico. Al trazar estas muestras, obtenemos una forma de onda que muestra cómo el nivel de presión sonora cambia a lo largo del tiempo. El eje horizontal representa el tiempo, mientras que el eje vertical representa la amplitud o intensidad del sonido, generalmente escalado para ajustarse entre -1 y 1, donde los valores positivos indican compresión y los valores negativos indican rarefacción. Esto nos ayuda a obtener una representación visual de las características de la onda de sonido, como su amplitud, frecuencia y duración.
Fundamentos de la Propagación del Sonido [Imagen de Autor]
Para extraer la forma de onda de un audio dado utilizando Python, comenzamos cargando los paquetes necesarios:
import numpy as npimport matplotlib.pyplot as pltimport librosaimport librosa.displayimport IPython.display as ipdimport scipy as spp
NumPy es un paquete popular de Python para procesar y trabajar con matrices y matrices. ¡Contiene una amplia gama de herramientas, desde álgebra lineal hasta simplificar muchas tareas!
librosa es el paquete de Python para el procesamiento y análisis de audio y contiene varias funciones y herramientas para facilitar el uso de diferentes tipos de características de audio. Como se mencionó anteriormente, analizaremos las formas de onda de 3 instrumentos musicales diferentes: guitarra acústica, latón y batería. Puede descargar los archivos de audio desde el enlace compartido anteriormente y cargarlos en su repositorio local. Para escuchar los archivos de audio, usamos IPython.display. A continuación se muestra el código:
# Escuchar los archivos de audio# Asegúrese de tener la ruta relativa / absoluta correcta de los archivos de sonido.acoustic_guitar_path = "acoustic_guitar.wav"ipd.Audio(acoustic_guitar_path)brass_path = "brass.wav"ipd.Audio(brass_path)# ¡Mantenga el volumen bajo!drum_set_path = "drum_set.wav"ipd.Audio(drum_set_path)
A continuación, cargamos los archivos de música en librosa utilizando la función librosa.load(). Esta función nos permite analizar el archivo de audio y devolver dos objetos:
y (Matriz NumPy): Contiene los valores de amplitud para diferentes intervalos de tiempo. ¡Intente imprimir la matriz para verla usted mismo!
sr (número > 0): Tasa de muestreo
La tasa de muestreo se refiere al número de muestras tomadas por unidad de tiempo al convertir una señal analógica en su representación digital. Como se discutió anteriormente, la variación de presión en el VoAGI constituye una señal analógica, una que tiene una forma de onda que varía continuamente en el tiempo. Teóricamente, almacenar datos continuos requeriría una cantidad infinita de espacio. Por lo tanto, para procesar y almacenar estas señales analógicas digitalmente, deben convertirse en una representación discreta. Aquí es donde entra el muestreo para capturar capturas de pantalla de la onda de sonido en intervalos de tiempo discretos (uniformemente espaciados). El espaciado entre estos intervalos se captura mediante el inverso de la tasa de muestreo.
La tasa de muestreo determina con qué frecuencia se toman muestras de la señal analógica y, por lo tanto, se mide en muestras por segundo o hertzios (Hz). Una tasa de muestreo más alta significa que se toman más muestras cada segundo, lo que resulta en una representación más precisa de la señal analógica original, pero requiere más recursos de memoria. Por el contrario, una tasa de muestreo más baja significa que se toman menos muestras cada segundo, lo que resulta en una representación menos precisa de la señal analógica original, pero requiere menos recursos de memoria.
La tasa de muestreo habitual predeterminada es 22050. Sin embargo, según la aplicación/memoria, el usuario puede elegir una tasa de muestreo más baja o más alta, que se puede especificar mediante el argumento sr de librosa.load(). Al elegir una tasa de muestreo adecuada para la conversión analógica a digital, puede ser importante conocer el teorema de muestreo de Nyquist-Shannon, que establece que para capturar y reconstruir con precisión una señal analógica, la tasa de muestreo debe ser al menos el doble de la componente de frecuencia más alta presente en la señal de audio (llamada frecuencia/tasa de Nyquist).
Al muestrear a una frecuencia superior a la frecuencia de Nyquist, podemos evitar un fenómeno llamado aliasing, que puede distorsionar la señal original. La discusión sobre el aliasing no es particularmente relevante para el propósito de este artículo. Si está interesado en leer más al respecto, aquí hay una excelente fuente: https://thewolfsound.com/what-is-aliasing-what-causes-it-how-to-avoid-it/
A continuación se muestra el código para leer las señales de audio:
# Cargar música en librosasr = 22050acoustic_guitar, sr = librosa.load(acoustic_guitar_path, sr = sr)brass, sr = librosa.load(brass_path, sr = sr)drum_set, sr = librosa.load(drum_set_path, sr = sr)
En el ejemplo anterior, se dice que la tasa de muestreo es 22050 (que también es la tasa predeterminada). La ejecución del código anterior devuelve 3 matrices, cada una de las cuales almacena los valores de amplitud en intervalos de tiempo discretos (especificados por la tasa de muestreo). A continuación, visualizamos las formas de onda de cada una de las 3 muestras de audio utilizando librosa.display.waveshow(). Se ha agregado cierta transparencia (configurando alpha = 0.5) para una visualización más clara de la densidad de amplitud a lo largo del tiempo.
def show_waveform(signal, name=""): # Crear una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Mostrar la forma de onda de la señal usando librosa librosa.display.waveshow(signal, alpha=0.5) # Establecer el título del gráfico plt.title("Forma de onda para " + name) # Mostrar el gráfico plt.show()show_waveform(acoustic_guitar, "Guitarra Acústica")show_waveform(brass, "Latón")show_waveform(drum_set, "Batería")
Forma de onda para Guitarra Acústica [Imagen del autor]Forma de onda para Brass [Imagen del autor]Forma de onda para Batería [Imagen del autor]
Tómese un momento para revisar los gráficos anteriores. Piense en los patrones que ve. En la forma de onda de la guitarra acústica, podemos identificar un patrón periódico caracterizado por oscilaciones regulares en la amplitud, lo cual refleja la naturaleza armónicamente rica del sonido de la guitarra. Las oscilaciones corresponden a las vibraciones producidas por las cuerdas pulsadas que generan una forma de onda compleja que consta de múltiples armónicos que contribuyen al tono y timbre característicos de la guitarra.
De manera similar, la forma de onda del brass también muestra un patrón periódico que resulta en un tono y timbre consistentes. Los instrumentos de brass producen sonido a través del zumbido de los labios del músico en una boquilla. Esta acción de zumbido genera una forma de onda con armónicos distintos y un patrón regular de variaciones de amplitud.
En cambio, la forma de onda de una batería no muestra un patrón periódico claro ya que los tambores producen sonido mediante el impacto de una baqueta o mano en un parche de tambor u otras superficies de percusión, creando formas de onda complejas e irregulares, con amplitudes y duraciones variables. La ausencia de un patrón periódico discernible refleja la naturaleza percusiva y no tonal de los sonidos de la batería.
Conceptos básicos del procesamiento de señales de audio: Tamaño de marco y longitud de salto
Antes de discutir las características vitales del dominio temporal del audio, es imprescindible hablar sobre dos parámetros importantes de extracción de características: el tamaño de marco y la longitud de salto. Usualmente, una vez que una señal ha sido procesada digitalmente, se divide en marcos (un conjunto de intervalos de tiempo discretos que pueden o no superponerse). La longitud del marco describe el tamaño de estos marcos, mientras que la longitud de salto encapsula información sobre cuánto se superponen los marcos. Pero, ¿por qué es importante el enmarcado?
El propósito del enmarcado es capturar la variación temporal en diferentes características de la señal. Los métodos usuales de extracción de características proporcionan un resumen de un solo número de la señal de entrada (por ejemplo, la media, el mínimo o el máximo). El problema de utilizar estos métodos de extracción de características directamente es que esto aniquila completamente cualquier información asociada con el tiempo. Por ejemplo, si está interesado en calcular la amplitud media de su señal, obtendrá un resumen de un solo número, digamos x. Sin embargo, naturalmente, hay intervalos en los que la media es más baja y otros en los que la media es más alta. Tomar un resumen de un solo número elimina cualquier información sobre la variación temporal de la media. La solución, a su vez, es dividir las señales en marcos, por ejemplo, [0 ms, 10 ms), [10 ms, 20 ms), … Posteriormente se calcula la media para la porción de la señal en cada uno de estos marcos de tiempo y este conjunto colectivo de características proporciona el vector de características extraído final, un resumen de características dependiente del tiempo, ¡eso sí que es genial!
Ahora, hablemos sobre los dos parámetros en detalle:
Tamaño de marco: Describe el tamaño de cada marco. Por ejemplo, si el tamaño de marco es 1024, se incluyen 1024 muestras en cada marco y se calculan las características necesarias para cada uno de estos conjuntos de 1024 muestras. En general, se recomienda que el tamaño de marco sea una potencia de 2. La razón detrás de esto no es importante para el propósito de este artículo. Pero si tienes curiosidad, es porque la Transformada Rápida de Fourier (un algoritmo muy eficiente para transformar una señal del dominio del tiempo al dominio de la frecuencia) requiere que los marcos tengan un tamaño que sea una potencia de 2. Hablaremos más sobre las transformaciones de Fourier en las secciones posteriores.
Longitud de salto: Se refiere al número de muestras por las cuales se avanza un marco en cada paso a través de la secuencia de datos, es decir, el número de muestras que desplazamos hacia la derecha antes de generar un nuevo marco. Puede ser útil pensar en el marco como una ventana deslizante que se mueve a lo largo de la señal en pasos definidos por la longitud de salto. En cada paso, la ventana se aplica a una nueva sección de la señal o secuencia, y se realiza la extracción de características en ese segmento. La longitud de salto, por lo tanto, determina la superposición entre marcos de audio consecutivos. Una longitud de salto igual al tamaño de marco significa que no hay superposición, ya que cada marco comienza exactamente donde termina el anterior. Sin embargo, para mitigar el impacto de un fenómeno llamado filtrado espectral (que ocurre al convertir una señal de su dominio temporal al dominio de la frecuencia), se aplica una función de ventana, lo que resulta en la pérdida de datos alrededor de los bordes de cada marco (la explicación técnica va más allá del propósito de este artículo, pero si tienes curiosidad, no dudes en consultar este enlace: https://dspillustrations.com/pages/posts/misc/spectral-leakage-zero-padding-and-frequency-resolution.html). Por lo tanto, a menudo se eligen longitudes de salto intermedias para preservar las muestras de los bordes, lo que resulta en grados variables de superposición entre marcos.
En general, un tamaño de salto más pequeño proporciona una mayor resolución temporal, lo que nos permite capturar más detalles y cambios rápidos en la señal. Sin embargo, también aumenta los requisitos de memoria. Por otro lado, un tamaño de salto más grande reduce la resolución temporal pero también ayuda a reducir la complejidad espacial.
Tamaño de cuadro y tamaño de salto [Imagen por el autor]
Nota: Para una visualización más clara, el tamaño del cuadro se muestra bastante grande en la imagen anterior. Para fines prácticos, el tamaño del cuadro elegido es mucho más pequeño (quizás unas pocas 1000 muestras, alrededor de 20-40 ms).
Antes de continuar con los diferentes métodos de extracción de características en el dominio del tiempo, aclaremos algunas notaciones matemáticas. Utilizaremos las siguientes notaciones a lo largo de este artículo:
xᵢ: la amplitud de la muestra i
K: Tamaño de cuadro
H: Tamaño de salto
Característica 1: Envoltura de amplitud
Primero, hablemos sobre la envoltura de amplitud. Esta es una de las características más fáciles de calcular (aunque bastante útil) en el análisis del dominio del tiempo. La envoltura de amplitud para un cuadro de una señal de audio es simplemente el valor máximo de su amplitud en ese cuadro. Matemáticamente, la envoltura de amplitud (para cuadros no superpuestos) del cuadro k está dada por:
En general, para cualquier cuadro k que contenga muestras xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, la envoltura de amplitud es:
El código Python para calcular la envoltura de amplitud de una señal dada se muestra a continuación:
TAMAÑO_CUADRO = 1024TAMAÑO_SALTO = 512def envoltura_amplitud(señal, tamaño_cuadro=1024, tamaño_salto=512): """ Calcula la envoltura de amplitud de una señal utilizando una ventana deslizante. Args: señal (array): La señal de entrada. tamaño_cuadro (int): El tamaño de cada cuadro en muestras. tamaño_salto (int): El número de muestras entre cuadros consecutivos. Returns: np.array: Un array de valores de envoltura de amplitud. """ res = [] for i in range(0, len(señal), tamaño_salto): # Obtener una porción de la señal porción_actual = señal[i:i + tamaño_cuadro] # Calcular el valor máximo en la porción valor_envoltura = max(porción_actual) # Almacenar el valor de envoltura de amplitud res.append(valor_envoltura) # Convertir el resultado en un array NumPy return np.array(res)def trazar_envoltura_amplitud(señal, nombre, tamaño_cuadro=1024, tamaño_salto=512): """ Traza la forma de onda de una señal con la superposición de valores de envoltura de amplitud. Args: señal (array): La señal de entrada. nombre (str): El nombre de la señal para el título de la gráfica. tamaño_cuadro (int): El tamaño de cada cuadro en muestras. tamaño_salto (int): El número de muestras entre cuadros consecutivos. """ # Calcular la envoltura de amplitud envoltura = envoltura_amplitud(señal, tamaño_cuadro, tamaño_salto) # Generar los índices de los cuadros cuadros = range(0, len(envoltura)) # Convertir los cuadros a tiempo tiempo = librosa.frames_to_time(cuadros, hop_length=tamaño_salto) # Crear una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Mostrar la forma de onda de la señal librosa.display.waveshow(señal, alpha=0.5) # Graficar la envoltura de amplitud a lo largo del tiempo plt.plot(tiempo, envoltura, color="r") # Establecer el título de la gráfica plt.title("Forma de onda para " + nombre + " (Envoltura de Amplitud)") # Mostrar la gráfica plt.show() trazar_envoltura_amplitud(guitarra_acústica, "Guitarra acústica")trazar_envoltura_amplitud(metales, "Metales")trazar_envoltura_amplitud(batería, "Batería")
En el código anterior, hemos definido una función llamada “amplitude_envelope” que toma como entrada una matriz de señal de entrada (generada usando librosa.load()), el tamaño de la trama (K) y la longitud del salto (H), y devuelve una matriz del mismo tamaño que el número de tramas. El valor k-ésimo en la matriz corresponde al valor del envolvente de amplitud para la k-ésima trama. El cálculo se realiza utilizando un simple bucle for que itera a través de toda la señal con pasos determinados por la longitud del salto. Se define una lista (res) para almacenar estos valores y finalmente se convierte en una matriz de NumPy antes de devolverla. También se define otra función llamada “plot_amplitude_envelope” que toma los mismos conjuntos de entradas (junto con un argumento de nombre) y superpone la trama del envolvente de amplitud sobre la trama original. Para trazar la forma de onda, se ha utilizado la función tradicional “librosa.display.waveform()”, como se explica en la sección anterior.
Para trazar el envolvente de amplitud, necesitamos el tiempo y los valores correspondientes del envolvente de amplitud. Los valores de tiempo se obtienen utilizando la función muy útil “librosa.frames_to_times()”, que toma dos entradas: un iterable correspondiente al número de tramas (que se define utilizando la función de rango) y la longitud del salto) para generar el tiempo medio para cada trama. Posteriormente, se utiliza “matplotlib.pyplot” para superponer la trama en rojo. El proceso descrito anteriormente se utilizará de manera consistente para todos los métodos de extracción de características en el dominio del tiempo.
Las siguientes figuras muestran el envolvente de amplitud calculado para cada uno de los instrumentos musicales. Se han añadido como una línea roja sobre la forma de onda original y tienden a aproximar el límite superior de la forma de onda. El envolvente de amplitud no solo conserva el patrón periódico, sino que también indica la diferencia general en las amplitudes de audio, como se refleja en las intensidades más bajas de los instrumentos de viento metal en comparación con la guitarra acústica y los tambores.
Envolvente de Amplitud para Guitarra Acústica [Imagen del Autor]Envolvente de Amplitud para Instrumento de Viento Metal [Imagen del Autor]Envolvente de Amplitud para Batería [Imagen del Autor]
Característica 2: Energía de la Raíz Cuadrada Media (RMSE)
A continuación, hablemos sobre la energía de la raíz cuadrada media (RMSE), otra característica vital en el análisis en el dominio del tiempo. La energía de la raíz cuadrada media para una trama de una señal de audio se obtiene tomando la raíz cuadrada de la media del cuadrado de todos los valores de amplitud en una trama. Matemáticamente, la energía de la raíz cuadrada media (para tramas no superpuestas) de la k-ésima trama está dada por:
En general, para cualquier trama k que contenga las muestras xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, el RMS es:
La energía RMS proporciona una representación de la intensidad o fuerza general de una señal de sonido teniendo en cuenta tanto las excursionas positivas como negativas de la forma de onda, lo que proporciona una medida más precisa de la potencia de la señal en comparación con otras medidas como la amplitud máxima. El código Python para calcular el RMS de una señal dada se muestra a continuación. La estructura del código es la misma que la utilizada para generar el envolvente de amplitud. El único cambio está en la función utilizada para extraer la característica. En lugar del máximo, el valor RMS se calcula tomando la media de los valores al cuadrado en la porción actual de la señal seguido de una raíz cuadrada.
def RMS_energy(signal, frame_size=1024, hop_length=512): """ Calcula la energía RMS (Root Mean Square) de una señal utilizando una ventana deslizante. Args: signal (array): La señal de entrada. frame_size (int): El tamaño de cada trama en muestras. hop_length (int): El número de muestras entre tramas consecutivas. Returns: np.array: Un array de valores de energía RMS. """ res = [] for i in range(0, len(signal), hop_length): # Extraer una porción de la señal cur_portion = signal[i:i + frame_size] # Calcular la energía RMS para la porción rmse_val = np.sqrt(1 / len(cur_portion) * sum(i**2 for i in cur_portion)) res.append(rmse_val) # Convertir el resultado en un array de NumPy return np.array(res)def plot_RMS_energy(signal, name, frame_size=1024, hop_length=512): """ Grafica la forma de onda de una señal con la superposición de valores de energía RMS. Args: signal (array): La señal de entrada. name (str): El nombre de la señal para el título de la gráfica. frame_size (int): El tamaño de cada trama en muestras. hop_length (int): El número de muestras entre tramas consecutivas. """ # Calcular la energía RMS rmse = RMS_energy(signal, frame_size, hop_length) # Generar los índices de las tramas frames = range(0, len(rmse)) # Convertir las tramas a tiempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crear una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Mostrar la forma de onda como una gráfica similar a un espectrograma librosa.display.waveshow(signal, alpha=0.5) # Graficar los valores de energía RMS plt.plot(time, rmse, color="r") # Establecer el título de la gráfica plt.title("Forma de Onda para " + name + " (Energía RMS)") plt.show()plot_RMS_energy(acoustic_guitar, "Guitarra Acústica")plot_RMS_energy(brass, "Instrumento de Viento Metal")plot_RMS_energy(drum_set, "Batería")
Las siguientes figuras muestran la Energía RMS calculada para cada uno de los instrumentos musicales. Se han agregado como una línea roja sobre la forma de onda original y tienden a aproximar el centro de masa de la forma de onda. Al igual que antes, esta medida no solo preserva el patrón periódico sino que también aproxima el nivel de intensidad general de la onda de sonido.
RMSE para Guitarra Acústica [Imagen del Autor]RMSE para Metales [Imagen del Autor]RMSE para Batería [Imagen del Autor]
Característica 3: Factor de Cresta
Ahora, hablemos del factor de cresta, una medida de la extremidad de los picos en la forma de onda. El factor de cresta para un marco de una señal de audio se obtiene dividiendo la amplitud máxima (el valor absoluto más grande de la amplitud) por la Energía RMS. Matemáticamente, el factor de cresta (para marcos no superpuestos) del k-ésimo marco está dado por:
En general, para cualquier marco k que contenga muestras xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, el factor de cresta es:
El factor de cresta indica la relación entre el nivel de pico más alto y el nivel de intensidad promedio de una forma de onda. El código de Python para calcular el factor de cresta de una señal dada se muestra a continuación. La estructura sigue como antes, involucrando el cálculo del valor de RMSE (el denominador) y el valor de pico más alto (el numerador), que luego se utiliza para obtener la fracción deseada (¡el factor de cresta!).
def crest_factor(signal, frame_size=1024, hop_length=512): """ Calcula el factor de cresta de una señal utilizando una ventana deslizante. Args: signal (array): La señal de entrada. frame_size (int): El tamaño de cada marco en muestras. hop_length (int): El número de muestras entre marcos consecutivos. Returns: np.array: Un array de valores de factor de cresta. """ res = [] for i in range(0, len(signal), hop_length): # Obtener una porción de la señal cur_portion = signal[i:i + frame_size] # Calcular la energía RMS para la porción rmse_val = np.sqrt(1 / len(cur_portion) * sum(i ** 2 for i in cur_portion)) # Calcular el factor de cresta crest_val = max(np.abs(cur_portion)) / rmse_val # Almacenar el valor del factor de cresta res.append(crest_val) # Convertir el resultado a un array de NumPy return np.array(res) def plot_crest_factor(signal, name, frame_size=1024, hop_length=512): """ Grafica el factor de cresta de una señal a lo largo del tiempo. Args: signal (array): La señal de entrada. name (str): El nombre de la señal para el título del gráfico. frame_size (int): El tamaño de cada marco en muestras. hop_length (int): El número de muestras entre marcos consecutivos. """ # Calcular el factor de cresta crest = crest_factor(signal, frame_size, hop_length) # Generar los índices de los marcos frames = range(0, len(crest)) # Convertir los marcos a tiempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crear una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Graficar el factor de cresta a lo largo del tiempo plt.plot(time, crest, color="r") # Establecer el título del gráfico plt.title(name + " (Factor de Cresta)") # Mostrar el gráfico plt.show() plot_crest_factor(acoustic_guitar, "Guitarra Acústica")plot_crest_factor(brass, "Metales")plot_crest_factor(drum_set, "Batería")
Las siguientes figuras muestran el factor de cresta calculado para cada uno de los instrumentos musicales:
Factor de Cresta para Guitarra Acústica [Imagen por Autor]Factor de Cresta para Metales [Imagen por Autor]Factor de Cresta para Conjunto de Metales [Imagen por Autor]
Un factor de cresta más alto, como se ve en la guitarra acústica y los metales, indica una mayor diferencia entre los niveles de pico y los niveles promedio, lo que sugiere una señal más dinámica o puntiaguda con mayores variaciones en la amplitud. Un factor de cresta más bajo, como se ve en un conjunto de tambores, sugiere una señal más uniforme o comprimida con variaciones más pequeñas en la amplitud. El factor de cresta es particularmente relevante en casos donde es imperativo considerar la capacidad de manejo o rango dinámico disponible del sistema. Por ejemplo, un factor de cresta alto en una grabación de música puede requerir una consideración cuidadosa para evitar distorsiones o recortes al reproducirse en equipos con capacidad de manejo limitada.
De hecho, existe otra característica llamada relación de potencia pico a promedio (PAPR), estrechamente relacionada con el factor de cresta. PAPR es simplemente el valor al cuadrado del factor de cresta, generalmente convertido a una relación de potencia en decibelios. En general, para cualquier marco k que contenga muestras xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, la relación de potencia pico a promedio es:
Como un desafío divertido, intenta modificar el código anterior para generar un gráfico de PAPR para cada uno de los 3 instrumentos musicales y analiza tus hallazgos.
Característica 4: Tasa de Cruce por Cero
Finalmente, hablaremos sobre la Tasa de Cruce por Cero (ZCR, por sus siglas en inglés). La tasa de cruce por cero de un marco de una señal de audio es simplemente el número de veces que la señal cruza el cero (el eje x/tiempo). Matemáticamente, la ZCR (para marcos no superpuestos) del k-ésimo marco está dada por:
Si los valores consecutivos tienen el mismo signo, la expresión dentro del valor absoluto se cancela, dando 0. Si tienen signos opuestos (lo que indica que la señal ha cruzado el eje de tiempo), los valores se suman, dando como resultado 2 (después de tomar el valor absoluto). Dado que cada cruce por cero da un valor de 2, multiplicamos el resultado por un factor de medio para obtener el recuento requerido. En general, para cualquier marco k que contenga muestras xⱼ₁ , xⱼ₂ , · · · , xⱼₖ, la ZCR es:
Observa que, en la expresión anterior, la tasa de cruce por cero se calcula simplemente sumando el número de veces que la señal cruza el eje. Sin embargo, según la aplicación, también se pueden normalizar los valores (dividiendo por la longitud del marco). El código Python para calcular el factor de cresta de una señal dada se muestra a continuación. La estructura sigue la anterior, con la definición de otra función llamada “num sign changes” que determina el número de veces que cambia el signo en la señal dada.
def ZCR(signal, frame_size=1024, hop_length=512): """ Calcula la Tasa de Cruce por Cero (ZCR) de una señal utilizando una ventana deslizante. Args: signal (array): La señal de entrada. frame_size (int): El tamaño de cada marco en muestras. hop_length (int): El número de muestras entre marcos consecutivos. Returns: np.array: Un arreglo de valores de ZCR. """ res = [] for i in range(0, len(signal), hop_length): # Obtén una porción de la señal cur_portion = signal[i:i + frame_size] # Calcula el número de cambios de signo en la porción zcr_val = num_sign_changes(cur_portion) # Almacena el valor de ZCR res.append(zcr_val) # Convierte el resultado a un arreglo NumPy return np.array(res) def num_sign_changes(signal): """ Calcula el número de cambios de signo en una señal. Args: signal (array): La señal de entrada. Returns: int: El número de cambios de signo. """ res = 0 for i in range(0, len(signal) - 1): # Verifica si hay un cambio de signo entre muestras consecutivas if (signal[i] * signal[i + 1] < 0): res += 1 return resdef plot_ZCR(signal, name, frame_size=1024, hop_length=512): """ Grafica la Tasa de Cruce por Cero (ZCR) de una señal a lo largo del tiempo. Args: signal (array): La señal de entrada. name (str): El nombre de la señal para el título del gráfico. frame_size (int): El tamaño de cada marco en muestras. hop_length (int): El número de muestras entre marcos consecutivos. """ # Calcula la ZCR zcr = ZCR(signal, frame_size, hop_length) # Genera los índices de los marcos frames = range(0, len(zcr)) # Convierte los marcos a tiempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Grafica la ZCR a lo largo del tiempo plt.plot(time, zcr, color="r") # Establece el título del gráfico plt.title(name + " (Tasa de Cruce por Cero)") # Muestra el gráfico plt.show() plot_ZCR(acoustic_guitar, "Guitarra Acústica")plot_ZCR(brass, "Metales")plot_ZCR(drum_set, "Conjunto de Tambores")
Las siguientes figuras muestran la tasa de cruce por cero calculada para cada uno de los instrumentos musicales.
Tasa de cruce por cero para la guitarra acústica [Imagen del autor]Tasa de cruce por cero para el latón [Imagen del autor]Tasa de cruce por cero para el set de batería [Imagen del autor]
Una tasa de cruce por cero más alta muestra que la señal cambia de dirección con frecuencia, lo que sugiere la presencia de componentes de alta frecuencia o una forma de onda más dinámica. Por el contrario, una tasa de cruce por cero más baja indica una forma de onda relativamente más suave o constante.
La tasa de cruce por cero es particularmente útil en aplicaciones de análisis de voz y música debido a su capacidad para proporcionar información sobre propiedades como el timbre y los patrones rítmicos. Por ejemplo, en el análisis del habla, la tasa de cruce por cero ayuda a distinguir entre sonidos sonoros y no sonoros, ya que los sonidos sonoros tienden a tener una tasa de cruce por cero más alta debido a la vibración de las cuerdas vocales. Es importante tener en cuenta que, aunque la tasa de cruce por cero es una característica simple y computacionalmente eficiente, puede que no capture todos los aspectos de la complejidad de una señal (como se puede ver en las figuras anteriores, la periodicidad se pierde por completo). Por lo tanto, a menudo se utiliza en conjunto con otras características para un análisis más completo de las señales de audio.
Extracción de características en el dominio de frecuencia
El dominio de frecuencia ofrece una representación alternativa de una onda de audio. A diferencia del dominio de tiempo, donde la señal se representa como una función del tiempo, en el dominio de frecuencia, la señal se descompone en sus frecuencias constituyentes, revelando la información de amplitud y fase asociada con cada frecuencia, es decir, la señal se representa como una función de la frecuencia. En lugar de mirar la amplitud de la señal en varios puntos en el tiempo, examinamos las amplitudes de los diferentes componentes de frecuencia que constituyen la señal. Cada componente de frecuencia representa una onda sinusoidal de una frecuencia particular y al combinar estos componentes podemos reconstruir la señal original en el dominio del tiempo.
La herramienta matemática (más común) utilizada para convertir una señal del dominio de tiempo al dominio de frecuencia es la transformación de Fourier. La transformación de Fourier toma la señal como entrada y la descompone en una suma de ondas seno y coseno de diversas frecuencias que tienen su propia amplitud y fase. La representación resultante es lo que constituye el espectro de frecuencia. Matemáticamente, la transformada de Fourier de una señal continua en su dominio de tiempo g(t) se define de la siguiente manera:
donde i = √−1 es el número imaginario. ¡Sí, la transformación de Fourier produce una salida compleja, con la fase y la magnitud correspondientes a las de la onda seno constituyente! Sin embargo, para la mayoría de las aplicaciones, solo nos importa la magnitud de la transformación y simplemente ignoramos la fase asociada. Dado que el sonido procesado digitalmente es discreto, podemos definir la transformada de Fourier discreta (DFT) análoga:
donde T es la duración de una muestra. En términos de la frecuencia de muestreo:
Dado que las representaciones de frecuencia también son continuas, evaluamos la transformada de Fourier en intervalos de frecuencia discretizados para obtener una representación de dominio de frecuencia discreta de la onda de audio. Esto se llama transformada de Fourier a corto plazo. Matemáticamente,
¡No te pongas ansioso! Vamos a revisarlo cuidadosamente. La función del sombrero-h(k) es la que asigna un entero k ∈ {0, 1, · · · , N – 1} a la magnitud de la frecuencia k · Sᵣ/N. Observa que consideramos solo los intervalos de frecuencia discretos que son múltiplos enteros de Sᵣ/N, donde N es el número de muestras en la señal. Si aún no estás seguro de cómo funciona esto, aquí tienes una excelente explicación de las transformadas de Fourier: https://www.youtube.com/watch?v=spUNpyF58BY&t=393s
La transformada de Fourier es una de las innovaciones matemáticas más hermosas, por lo que vale la pena conocerla, aunque la discusión no sea específicamente relevante para el propósito de este artículo. En Python, puedes obtener fácilmente la transformada de Fourier de corto plazo utilizando librosa.stft().
Nota: Para datos de audio grandes, hay una forma más eficiente de calcular la transformada de Fourier, llamada Transformación Rápida de Fourier (FFT), si te interesa, ¡no dudes en echarle un vistazo!
Como antes, no solo nos interesa saber qué frecuencias son más dominantes: también queremos mostrar cuándo estas frecuencias son dominantes. Por lo tanto, buscamos una representación simultánea de frecuencia-tiempo que muestre qué frecuencias dominan en qué punto en el tiempo. Aquí es donde entra el enmarcado: dividimos la señal en segmentos de tiempo y obtenemos la magnitud de la transformada de Fourier resultante en cada segmento. Esto nos da una matriz de valores, donde el número de filas está dado por el número de intervalos de frecuencia (Φ, normalmente igual a K/2 + 1, donde K es el tamaño del segmento), y el número de columnas está dado por el número de segmentos. Dado que la transformada de Fourier da como resultado valores complejos, la matriz generada es de valores complejos. En Python, el tamaño del segmento y los parámetros de longitud de salto se pueden especificar fácilmente como argumentos y la matriz resultante se puede calcular simplemente usando librosa.stft(signal, n_fft=tamaño del segmento, hop_length=longitud de salto). Dado que solo nos importa la magnitud, podemos usar numpy.abs() para convertir la matriz de valores complejos en una de valores reales. Es bastante conveniente trazar la matriz obtenida para tener una representación visualmente cautivadora de la señal que proporciona información valiosa sobre el contenido de frecuencia y las características temporales del sonido dado. Se llama a esta representación un espectrograma.
Los espectrogramas se obtienen trazando los segmentos de tiempo en el eje x y los intervalos de frecuencia en el eje y. Luego, se utilizan colores para indicar la intensidad o la magnitud de la frecuencia para el segmento de tiempo dado. Por lo general, el eje de frecuencia se convierte a una escala logarítmica (ya que se sabe que los humanos los perciben mejor bajo una transformación logarítmica) y la magnitud se expresa en decibeles.
A continuación se muestra el código de Python para generar un espectrograma:
FRAME_SIZE = 1024HOP_LENGTH = 512def plot_spectrogram(signal, sample_rate, frame_size=1024, hop_length=512): """ Traza el espectrograma de una señal de audio. Args: signal (array-like): La señal de audio de entrada. sample_rate (int): La frecuencia de muestreo de la señal de audio. frame_size (int): El tamaño de cada segmento en muestras. hop_length (int): El número de muestras entre segmentos consecutivos. """ # Calcula la STFT espectrograma = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Convierte la STFT a escala dB espectrograma_db = librosa.amplitude_to_db(np.abs(espectrograma)) # Crea una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Muestra el espectrograma librosa.display.specshow(espectrograma_db, sr=sample_rate, hop_length=hop_length, x_axis='time', y_axis='log') # Agrega una barra de color para mostrar la escala de magnitud plt.colorbar(format='%+2.0f dB') # Establece el título de la gráfica plt.title('Espectrograma') # Establece la etiqueta para el eje x plt.xlabel('Tiempo') # Establece la etiqueta para el eje y plt.ylabel('Frecuencia (Hz)') # Ajusta el diseño de la gráfica plt.tight_layout() # Muestra la gráfica plt.show() plot_spectrogram(acoustic_guitar, sr)plot_spectrogram(brass, sr)plot_spectrogram(drum_set, sr)
En el código anterior, hemos definido una función llamada plot_spectrogram que recibe 4 argumentos: el array de la señal de entrada, la frecuencia de muestreo, el tamaño del segmento y la longitud de salto. Primero, se utiliza librosa.stft() para obtener la matriz del espectrograma. Posteriormente, se utiliza np.abs() para extraer la magnitud seguida de una conversión de los valores de amplitud a decibeles utilizando la función librosa.amplitude_to_db(). Finalmente, se utiliza la función librosa.display.specshow() para trazar el espectrograma. Esta función recibe la matriz del espectrograma transformado, la frecuencia de muestreo, la longitud de salto y las especificaciones para los ejes x e y. Se puede especificar un eje y transformado logarítmicamente utilizando el argumento y_axis = ‘log’. Se puede agregar una barra de color opcional utilizando plt.colorbar(). Los espectrogramas resultantes para los 3 instrumentos musicales se muestran a continuación:
Espectrograma para Guitarra Acústica [Imagen por el Autor]Espectrograma para Brass [Imagen por el Autor]Espectrograma para Batería [Imagen por el Autor]
Los espectrogramas ofrecen una forma única de visualizar el equilibrio tiempo-frecuencia. El dominio del tiempo nos brinda una representación precisa de cómo evoluciona una señal a lo largo del tiempo, mientras que el dominio de la frecuencia nos permite ver la distribución de energía en diferentes frecuencias. Esto nos permite identificar no solo la presencia de frecuencias específicas, sino también comprender su duración y variaciones temporales. Los espectrogramas son una de las formas más útiles de representar el sonido y se utilizan con frecuencia en aplicaciones de aprendizaje automático de señales de audio (por ejemplo, alimentar el espectrograma de una onda de sonido a una red neuronal convolucional profunda para hacer predicciones).
Antes de pasar a los diferentes métodos de extracción de características en el dominio de la frecuencia, aclaremos algunas notaciones matemáticas. Utilizaremos las siguientes notaciones para las secciones posteriores:
mₖ(i): la amplitud de la frecuencia i-ésima del k-ésimo marco.
K: Tamaño del Marco
H: Longitud de Salto
Φ: Número de bins de frecuencia (= K/2 + 1)
Característica 5: Relación de Energía de Banda
Primero, hablemos sobre la relación de energía de banda. La relación de energía de banda es una métrica utilizada para cuantificar la relación entre las energías de las frecuencias bajas y las frecuencias altas en un marco de tiempo dado. Matemáticamente, para cualquier marco k, la relación de energía de banda es:
donde σբ denota el bin de frecuencia de división: un parámetro para distinguir las frecuencias bajas de las frecuencias altas. Al calcular la relación de energía de banda, todas las frecuencias que tienen un valor menor que la frecuencia correspondiente a σբ (llamada frecuencia de división) se tratan como frecuencias bajas. La suma de las energías al cuadrado de estas frecuencias determina el numerador. De manera similar, todas las frecuencias que tienen un valor mayor que la frecuencia de división se tratan como frecuencias altas y la suma de las energías al cuadrado de estas frecuencias determina el denominador. El código Python para calcular la relación de energía de banda de una señal se muestra a continuación:
def find_split_freq_bin(spec, split_freq, sample_rate, frame_size=1024, hop_length=512): """ Calcula el índice de bin correspondiente a una frecuencia de división dada. Args: spec (array): El espectrograma. split_freq (float): La frecuencia de división en Hz. sample_rate (int): La frecuencia de muestreo del audio. frame_size (int, opcional): El tamaño de cada marco en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre marcos consecutivos. El valor predeterminado es 512. Returns: int: El índice de bin correspondiente a la frecuencia de división. """ # Calcula el rango de frecuencias range_of_freq = sample_rate / 2 # Calcula el cambio de frecuencia por bin change_per_bin = range_of_freq / spec.shape[0] # Calcula el bin correspondiente a la frecuencia de división split_freq_bin = split_freq / change_per_bin return int(np.floor(split_freq_bin))def band_energy_ratio(signal, split_freq, sample_rate, frame_size=1024, hop_length=512): """ Calcula la relación de energía de banda (BER) de una señal. Args: signal (array): La señal de entrada. split_freq (float): La frecuencia de división en Hz. sample_rate (int): La frecuencia de muestreo del audio. frame_size (int, opcional): El tamaño de cada marco en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre marcos consecutivos. El valor predeterminado es 512. Returns: ndarray: Las relaciones de energía de banda para cada marco de la señal. """ # Calcula el espectrograma de la señal spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Encuentra el bin correspondiente a la frecuencia de división split_freq_bin = find_split_freq_bin(spec, split_freq, sample_rate, frame_size, hop_length) # Extrae la magnitud y la transpone modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcula la energía en el rango de frecuencias bajas low_freq_density = sum(i ** 2 for i in sub_arr[:split_freq_bin]) # Calcula la energía en el rango de frecuencias altas high_freq_density = sum(i ** 2 for i in sub_arr[split_freq_bin:]) # Calcula la relación de energía de banda ber_val = low_freq_density / high_freq_density res.append(ber_val) return np.array(res)def plot_band_energy_ratio(signal, split_freq, sample_rate, name, frame_size=1024, hop_length=512): """ Grafica la relación de energía de banda (BER) de una señal a lo largo del tiempo. Args: signal (ndarray): La señal de entrada. split_freq (float): La frecuencia de división en Hz. sample_rate (int): La frecuencia de muestreo del audio. name (str): El nombre de la señal para el título del gráfico. frame_size (int, opcional): El tamaño de cada marco en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre marcos consecutivos. El valor predeterminado es 512. """ # Calcula la relación de energía de banda (BER) ber = band_energy_ratio(signal, split_freq, sample_rate, frame_size, hop_length) # Genera los índices de los marcos frames = range(0, len(ber)) # Convierte los marcos a tiempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Grafica la BER a lo largo del tiempo plt.plot(time, ber) # Establece el título del gráfico plt.title(name + " (Relación de Energía de Banda)") # Muestra el gráfico plt.show() plot_band_energy_ratio(acoustic_guitar, 2048, sr, "Guitarra Acústica")plot_band_energy_ratio(brass, 2048, sr, "Brass")plot_band_energy_ratio(drum_set, 2048, sr, "Batería")
La estructura del código anterior es bastante similar a la extracción en el dominio del tiempo. El primer paso es definir una función llamada find_split_freq_bin() que toma el espectrograma, el valor de la frecuencia de división y la tasa de muestreo para determinar el bin de frecuencia de división (σբ) correspondiente a la frecuencia de división. El proceso es bastante simple. Implica encontrar el rango de frecuencias (que, como se explicó anteriormente, es la frecuencia de Nyquist, Sᵣ/2). El número de bins de frecuencia se calcula a partir del número de filas de los espectrogramas, que se extrae como spec.shape[0]. Dividir el rango total de frecuencias por el número de bins de frecuencia nos permite calcular el cambio en frecuencia por bin, que se puede dividir por la frecuencia de división dada para determinar el bin de frecuencia de división.
A continuación, usamos esta función para calcular el vector de relación de energía de banda. La función band_energy_ratio() toma la señal de entrada, la frecuencia de división, la tasa de muestreo, el tamaño de trama y la longitud de salto. Primero, utiliza librosa.stft() para extraer el espectrograma, seguido de un cálculo del bin de frecuencia de división. A continuación, se calcula la magnitud del espectrograma utilizando np.abs(), seguido de la transposición para facilitar la iteración en cada trama. Durante la iteración, se calcula la relación de energía de banda para cada trama utilizando la fórmula definida y el bin de frecuencia de división encontrado. Los valores se almacenan en una lista, res, que finalmente se devuelve como un array de NumPy. Finalmente, los valores se representan gráficamente utilizando la función plot_band_energy_ratio().
A continuación se muestran los gráficos de la relación de energía de banda para los 3 instrumentos musicales. Para estos gráficos, la frecuencia de división se elige como 2048 Hz, es decir, las frecuencias por debajo de 2048 Hz se consideran frecuencias de menor energía, y las que están por encima se consideran frecuencias de mayor energía.
Relación de energía de banda para guitarra acústica [Imagen por el autor]Relación de energía de banda para instrumentos de viento metal [Imagen por el autor]Relación de energía de banda para batería [Imagen por el autor]
Una relación de energía de banda alta (para instrumentos de viento metal) indica una mayor presencia de componentes de baja frecuencia en relación con los componentes de alta frecuencia. Por lo tanto, observamos que los instrumentos de viento metal producen una cantidad significativa de energía en las bandas de frecuencia más bajas en comparación con las bandas de frecuencia más altas. La guitarra acústica tiene una BER más baja en comparación con los instrumentos de viento metal, lo que indica una contribución de energía relativamente menor en las bandas de frecuencia más bajas en comparación con las bandas de frecuencia más altas. En general, las guitarras acústicas tienden a tener una distribución de energía más equilibrada en todo el espectro de frecuencias, con un énfasis relativamente menor en las frecuencias más bajas en comparación con otros instrumentos. Por último, la batería tiene la BER más baja de los tres, lo que sugiere una contribución de energía comparativamente menor en las bandas de frecuencia más bajas en relación con otros instrumentos.
Característica 6: Centroide espectral
A continuación, hablaremos sobre el centroide espectral, una medida que cuantifica información sobre el centro de masa o la frecuencia promedio del espectro de una señal en un marco de tiempo dado. Matemáticamente, para cualquier marco k, el centroide espectral es:
Imagínalo como una suma ponderada de los índices de los bins de frecuencia, donde el peso está determinado por la contribución de energía del bin en el marco de tiempo dado. También se realiza una normalización dividiendo la suma ponderada por la suma de todos los pesos para facilitar la comparación uniforme entre diferentes señales. El código Python para calcular el centroide espectral de una señal se muestra a continuación:
def spectral_centroid(signal, sample_rate, frame_size=1024, hop_length=512): """ Calcula el centroide espectral de una señal. Args: signal (array): La señal de entrada. sample_rate (int): La tasa de muestreo del audio. frame_size (int, opcional): El tamaño de cada trama en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre tramas consecutivas. El valor predeterminado es 512. Returns: ndarray: Los centroides espectrales para cada trama de la señal. """ # Calcula el espectrograma de la señal spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Extrae la magnitud y la transpone modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcula el centroide espectral sc_val = sc(sub_arr) # Almacena el valor del centroide espectral para la trama actual res.append(sc_val) return np.array(res)def sc(arr): """ Calcula el centroide espectral en una señal. Args: arr (array): Array de dominio de frecuencia para la trama actual. Returns: float: El valor del centroide espectral para la trama actual. """ res = 0 for i in range(0, len(arr)): # Calcula la suma ponderada res += i*arr[i] return res/sum(arr)def bin_to_freq(spec, bin_val, sample_rate, frame_size=1024, hop_length=512): """ Calcula la frecuencia correspondiente a un valor de bin dado Args: spec (array): El espectrograma. bin_val (): El valor de bin. sample_rate (int): La tasa de muestreo del audio. frame_size (int, opcional): El tamaño de cada trama en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre tramas consecutivas. El valor predeterminado es 512. Returns: int: El índice de bin correspondiente a la frecuencia de división. """ # Calcula el rango de frecuencias rango_de_frecuencias = sample_rate / 2 # Calcula el cambio de frecuencia por bin cambio_por_bin = rango_de_frecuencias / spec.shape[0] # Calcula la frecuencia correspondiente al bin frecuencia_division = bin_val*cambio_por_bin return frecuencia_divisiondef plot_spectral_centroid(signal, sample_rate, name, frame_size=1024, hop_length=512, col = "black"): """ Grafica el centroide espectral de una señal a lo largo del tiempo. Args: signal (ndarray): La señal de entrada. sample_rate (int): La tasa de muestreo del audio. name (str): El nombre de la señal para el título de la gráfica. frame_size (int, opcional): El tamaño de cada trama en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre tramas consecutivas. El valor predeterminado es 512. """ # Calcula la STFT espectrograma = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length
En el código anterior, se define la función del centroide espectral para producir la matriz de centroides espectrales para todos los intervalos de tiempo. Posteriormente, se define la función sc() para calcular el centroide espectral de un intervalo a través de un proceso iterativo simple que multiplica los valores de índice con la magnitud, seguido de una normalización para obtener el promedio de la frecuencia binaria. Antes de trazar los valores del centroide espectral devueltos por spectral_centroid(), se define una función adicional llamada bin_to_freq como una función auxiliar para trazar. Esta función convierte los valores promedio de bin a los valores de frecuencia correspondientes que se pueden trazar sobre el espectrograma original para tener una idea consistente sobre la variación del centroide espectral a lo largo del tiempo. A continuación se muestran las gráficas de salida (con la superposición de la variación del centroide sobre el espectrograma original):
Centroide Espectral para Guitarra Acústica [Imagen por el Autor]Centroide Espectral para Latón [Imagen por el Autor]Centroide Espectral para Batería [Imagen por el Autor]
El centroide espectral es bastante análogo a la métrica RMSE para el análisis en dominio del tiempo y se usa comúnmente como un descriptor para el timbre y el brillo del sonido. Los sonidos con centroides espectrales más altos tienden a tener una calidad más brillante o orientada a los agudos, mientras que los valores de centroide más bajos están asociados con un carácter más oscuro o orientado a los graves. El centroide espectral es una de las características más importantes para el aprendizaje automático de audio, a menudo utilizado en aplicaciones que involucran la clasificación de géneros de audio/música.
Característica 7: Ancho de Banda Espectral
Ahora, hablaremos sobre el ancho de banda/esparcimiento espectral, una medida que cuantifica la información sobre la distribución de energías en las frecuencias componentes del espectro de una señal en un intervalo de tiempo dado. Piénsalo de esta manera: Si el centroide espectral es el valor promedio, el ancho de banda espectral es una medida de su dispersión/varianza alrededor del centroide. Matemáticamente, para cualquier intervalo k, el ancho de banda espectral es:
donde SCₖ denota el centroide espectral del k-ésimo intervalo. Como antes, la normalización se realiza dividiendo la suma ponderada por la suma de todos los pesos para facilitar la comparación uniforme entre diferentes señales. El código en Python para calcular el ancho de banda espectral de una señal se muestra a continuación:
def spectral_bandwidth(signal, sample_rate, frame_size=1024, hop_length=512): """ Calcula el Ancho de Banda Espectral de una señal. Args: signal (array): La señal de entrada. sample_rate (int): La frecuencia de muestreo del audio. frame_size (int, opcional): El tamaño de cada intervalo en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre intervalos consecutivos. El valor predeterminado es 512. Returns: ndarray: Los anchos de banda espectrales para cada intervalo de la señal. """ # Calcula el espectrograma de la señal spec = librosa.stft(signal, n_fft=frame_size, hop_length=hop_length) # Extrae la magnitud y transpónela modified_spec = np.abs(spec).T res = [] for sub_arr in modified_spec: # Calcula el ancho de banda espectral sb_val = sb(sub_arr) # Almacena el valor de ancho de banda espectral para el intervalo actual res.append(sb_val) return np.array(res)def sb(arr): """ Calcula el ancho de banda espectral en una señal. Args: arr (array): Array de dominio de frecuencia para el intervalo actual. Returns: float: El valor de ancho de banda espectral para el intervalo actual. """ res = 0 sc_val = sc(arr) for i in range(0, len(arr)): # Calcula la suma ponderada res += (abs(i - sc_val))*arr[i] return res/sum(arr)def plot_spectral_bandwidth(signal, sample_rate, name, frame_size=1024, hop_length=512): """ Grafica el ancho de banda espectral de una señal a lo largo del tiempo. Args: signal (ndarray): La señal de entrada. sample_rate (int): La frecuencia de muestreo del audio. name (str): El nombre de la señal para el título de la gráfica. frame_size (int, opcional): El tamaño de cada intervalo en muestras. El valor predeterminado es 1024. hop_length (int, opcional): El número de muestras entre intervalos consecutivos. El valor predeterminado es 512. """ # Calcula el ancho de banda espectral sb_arr = spectral_bandwidth(signal, sample_rate, frame_size, hop_length) # Genera los índices de intervalos frames = range(0, len(sb_arr)) # Convierte los intervalos a tiempo time = librosa.frames_to_time(frames, hop_length=hop_length) # Crea una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Grafica el Ancho de Banda Espectral a lo largo del tiempo plt.plot(time, sb_arr) # Establece el título de la gráfica plt.title(name + " (Ancho de Banda Espectral)") # Muestra la gráfica plt.show() plot_spectral_bandwidth(acoustic_guitar, sr, "Guitarra Acústica")plot_spectral_bandwidth(brass, sr, "Latón")plot_spectral_bandwidth(drum_set, sr, "Batería")
Como antes, en el código anterior, la función de ancho de banda espectral está definida para producir la matriz de dispersión espectral para todos los fotogramas de tiempo utilizando la función auxiliar sb, que calcula de forma iterativa el ancho de banda de un fotograma. Finalmente, se utiliza la función de trazado de ancho de banda espectral para trazar estos valores de ancho de banda. Las gráficas de salida se muestran a continuación:
Ancho de Banda Espectral para Guitarra Acústica [Imagen por el Autor]Ancho de Banda Espectral para Metales [Imagen por el Autor]Ancho de Banda Espectral para Batería [Imagen por el Autor]
El ancho de banda espectral se puede utilizar en diversas tareas de análisis/clasificación de audio debido a su capacidad para proporcionar información sobre la dispersión o amplitud de las frecuencias presentes en una señal. Un ancho de banda espectral más alto (como se ve en los metales y baterías) indica un rango más amplio de frecuencias, lo que sugiere una señal más diversa o compleja. Por otro lado, un ancho de banda más bajo sugiere un rango más estrecho de frecuencias, lo que indica una señal más focalizada o tonalmente pura.
Característica 8: Planitud Espectral
Finalmente, hablaremos sobre la planitud espectral (también conocida como entropía de Weiner), una medida que informa sobre la planitud o uniformidad del espectro de potencia de una señal de audio. Nos ayuda a saber qué tan cerca está la señal de audio de un tono puro (en contraposición a un sonido similar al ruido) y por eso también se le llama coeficiente de tonalidad. Para cualquier fotograma k, la planitud espectral es la relación entre su media geométrica y su media aritmética. Matemáticamente,
El código Python para calcular la planitud espectral de una señal se muestra a continuación:
def planitud_espectral(señal, tasa_muestreo, tamaño_fotograma=1024, longitud_salto=512): """ Calcula la Planitud Espectral de una señal. Args: señal (arreglo): La señal de entrada. tasa_muestreo (int): La tasa de muestreo del audio. tamaño_fotograma (int, opcional): El tamaño de cada fotograma en muestras. El valor predeterminado es 1024. longitud_salto (int, opcional): El número de muestras entre fotogramas consecutivos. El valor predeterminado es 512. Returns: ndarray: La planitud espectral para cada fotograma de la señal. """ # Calcula el espectrograma de la señal espec = librosa.stft(señal, n_fft=tamaño_fotograma, hop_length=longitud_salto) # Extrae la magnitud y la transpone espec_modificado = np.abs(espec).T res = [] for sub_arr in espec_modificado: # Calcula la media geométrica media_geom = np.exp(np.log(sub_arr).mean()) # Calcula la media aritmética media_arit = np.mean(sub_arr) # Calcula la planitud espectral val_plan = media_geom/media_arit # Almacena el valor de planitud espectral para el fotograma actual res.append(val_plan) return np.array(res)def trazar_planitud_espectral(señal, tasa_muestreo, nombre, tamaño_fotograma=1024, longitud_salto=512): """ Trazar la planitud espectral de una señal a lo largo del tiempo. Args: señal (ndarray): La señal de entrada. tasa_muestreo (int): La tasa de muestreo del audio. nombre (str): El nombre de la señal para el título del gráfico. tamaño_fotograma (int, opcional): El tamaño de cada fotograma en muestras. El valor predeterminado es 1024. longitud_salto (int, opcional): El número de muestras entre fotogramas consecutivos. El valor predeterminado es 512. """ # Calcula la Planitud Espectral plan_arr = planitud_espectral(señal, tasa_muestreo, tamaño_fotograma, longitud_salto) # Genera los índices de los fotogramas fotogramas = range(0, len(plan_arr)) # Convierte los fotogramas a tiempo tiempo = librosa.frames_to_time(fotogramas, hop_length=longitud_salto) # Crea una nueva figura con un tamaño específico plt.figure(figsize=(15, 7)) # Trama la Planitud Espectral a lo largo del tiempo plt.plot(tiempo, plan_arr) # Establece el título del gráfico plt.title(nombre + " (Planitud Espectral)") # Muestra el gráfico plt.show() trazar_planitud_espectral(guitarra_acústica, sr, "Guitarra Acústica")trazar_planitud_espectral(metales, sr, "Metales")trazar_planitud_espectral(batería, sr, "Batería")
La estructura del código anterior es la misma que la de otros métodos de extracción en el dominio de frecuencia. La única diferencia radica en la función de extracción de características dentro del bucle for, que calcula la media aritmética y geométrica utilizando funciones de NumPy y calcula su proporción para producir los valores de planitud espectral para cada segmento de tiempo. Las gráficas de salida se muestran a continuación:
Planitud Espectral para Guitarra Acústica [Imagen por el Autor]Planitud Espectral para Brass [Imagen por el Autor]Planitud Espectral para Batería [Imagen por el Autor]
Un valor alto de planitud espectral (uno que esté más cerca de 1) indica una distribución de energía más uniforme o equilibrada en diferentes frecuencias de la señal. Esto se observa consistentemente en la batería, lo que sugiere un sonido más "similar al ruido" o de banda ancha, sin picos prominentes o énfasis en frecuencias específicas (como se observó anteriormente por la falta de periodicidad).
Por otro lado, un valor bajo de planitud espectral (especialmente para la guitarra acústica y en cierta medida para el brass) implica un espectro de potencia más desigual, con la energía concentrada alrededor de unas cuantas frecuencias específicas. Esto muestra la presencia de componentes tonales o armónicos en el sonido (como se refleja en su estructura periódica en el dominio del tiempo). En general, la música con tonos/frecuencias distintas tiende a tener valores de planitud espectral más bajos, mientras que los sonidos más ruidosos (y no tonales) exhiben valores de planitud espectral más altos.
Conclusión
En este artículo, nos sumergimos en las diferentes estrategias y técnicas para la extracción de características, que constituyen una parte integral del procesamiento de señales de audio en la ingeniería musical. Comenzamos aprendiendo sobre los conceptos básicos de la producción y propagación del sonido, que se pueden traducir de manera efectiva en variaciones de presión a lo largo del tiempo, dando lugar a su representación en el dominio del tiempo. Discutimos la representación digital del sonido y sus parámetros vitales, incluyendo la tasa de muestreo, el tamaño del marco y la longitud de salto. Se discutieron características en el dominio del tiempo, como la envolvente de amplitud, la energía de la raíz media cuadrada, el factor de cresta, la relación entre el pico y la potencia, y la tasa de cruce por cero, tanto teóricamente como evaluadas computacionalmente en 3 instrumentos musicales: la guitarra acústica, el brass y la batería. A continuación, se presentó y analizó la representación en el dominio de la frecuencia del sonido a través de diversas discusiones teóricas sobre la transformada de Fourier y los espectrogramas. Esto abrió el camino para una amplia variedad de características en el dominio de la frecuencia, incluyendo la relación de energía en bandas, el centroide espectral, las anchuras y el coeficiente de tonalidad, cada uno de los cuales se puede utilizar eficientemente para evaluar una característica particular del audio de entrada. Hay mucho más en las aplicaciones de procesamiento de señales, incluyendo los mel-espectrogramas, los coeficientes cepstrales, el control de ruido, la síntesis de audio, etc. Espero que esta explicación sirva como base para una mayor exploración de conceptos avanzados en el campo.
¡Espero que hayas disfrutado leyendo este artículo! En caso de tener alguna duda o sugerencia, por favor responde en el cuadro de comentarios.
No dudes en contactarme por correo electrónico.
Si te gustó mi artículo y quieres leer más, por favor sígueme.
Nota: Todas las imágenes (excepto la imagen de portada) han sido creadas por el autor.
Referencias
Crest factor. (2023). En Wikipedia. https://en.wikipedia.org/w/index.php?title=Crest_factor&oldid=1158501578
librosa — Documentación de Librosa 0.10.1dev. (s.f.). Recuperado el 5 de junio de 2023, de https://librosa.org/doc/main/index.html
Planitud espectral. (2022). En Wikipedia. https://en.wikipedia.org/w/index.php?title=Spectral_flatness&oldid=1073105086
The Sound of AI. (1 de agosto de 2020). Valerio Velardo. https://valeriovelardo.com/the-sound-of-ai/
We will continue to update Zepes; if you have any questions or suggestions, please contact us!

![Fundamentos de la Propagación del Sonido [Imagen de Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*73LlzPPzLmX6DsLrFVheeA.jpeg)

![Forma de onda para Guitarra Acústica [Imagen del autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Kf0MmP8_mqIZUyBRxgjHAA.png)
![Forma de onda para Brass [Imagen del autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*AY_urpb3jkZyrs7DwIEwRg.png)
![Forma de onda para Batería [Imagen del autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*1VDVlwQ_W_FKFgr1HPMoCA.png)
![Tamaño de cuadro y tamaño de salto [Imagen por el autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6jeBOA2R3sXcNADsXfEjuQ.png)

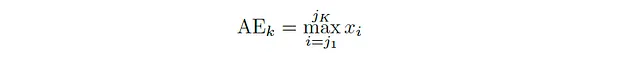
![Envolvente de Amplitud para Guitarra Acústica [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*-ruXOgSVNITu35WV0yuAtw.png)
![Envolvente de Amplitud para Instrumento de Viento Metal [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NhwUexulu7bWENkWEbr5XQ.png)
![Envolvente de Amplitud para Batería [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yi2fVD67-CZ_b2kL6VfLmg.png)
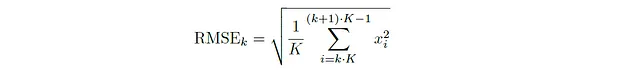

![RMSE para Guitarra Acústica [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*mKwBIq_5NMQ-QW-xd6T72Q.png)
![RMSE para Metales [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*eZWBylUC8FxqTS3jQnI9tw.png)
![RMSE para Batería [Imagen del Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WRDjgDkjMjTGC9ha87fWZw.png)


![Factor de Cresta para Guitarra Acústica [Imagen por Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OXJqmGmFU2pq1yaYrG3mHQ.png)
![Factor de Cresta para Metales [Imagen por Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*ic8zGIUhRa-nz3pOssyUFA.png)
![Factor de Cresta para Conjunto de Metales [Imagen por Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*uo2ACou50jdvkmETLVS7Iw.png)



![Tasa de cruce por cero para la guitarra acústica [Imagen del autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*jIW9ZcSzwnANrDp9tWL7bw.png)
![Tasa de cruce por cero para el latón [Imagen del autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8rUxSjDDA95_GSZ_oQRL9Q.png)




![Espectrograma para Guitarra Acústica [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*cs5iAD0d6SIAjt4TxYrTfA.png)
![Espectrograma para Brass [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*GUnA6RZXx8RA1T2dlnKhVw.png)
![Espectrograma para Batería [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*JjFO1kDacts055p-u241GQ.png)
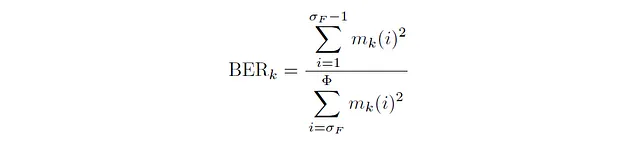
![Relación de energía de banda para guitarra acústica [Imagen por el autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Fk1Y0M9l7nYkX3wzHEbluA.png)
![Relación de energía de banda para instrumentos de viento metal [Imagen por el autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*dgHIkYXnmbp9fs02Kwr8JQ.png)
![Relación de energía de banda para batería [Imagen por el autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*IHpTCLmDdEPOKXlmpJ6GOw.png)

![Centroide Espectral para Guitarra Acústica [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*CpQGq2geei3hJdl4sQvrKg.png)
![Centroide Espectral para Latón [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*NOkciC8-vrK58ZY1W5-SsQ.png)
![Centroide Espectral para Batería [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*q4RWqeUuo9hPhNRpHiyZOA.png)

![Ancho de Banda Espectral para Guitarra Acústica [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Td--j-QnYI7aBd3jWwXf6g.png)
![Ancho de Banda Espectral para Metales [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*nl_g33qWsFmwxErGksZB1g.png)
![Ancho de Banda Espectral para Batería [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*LWAAj53HTRpmBC-wOqfDDQ.png)

![Planitud Espectral para Guitarra Acústica [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6LvWubMfSszLjZBSairoAg.png)
![Planitud Espectral para Brass [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*OzhJvcyF8ZZ7tmovy1bxIA.png)
![Planitud Espectral para Batería [Imagen por el Autor]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*gnekroUcZKW_QFQuyEg3PQ.png)





