Decodificando emociones Revelando sentimientos y estados mentales con EmoTX, un novedoso marco de inteligencia artificial impulsado por Transformer
Decoding emotions and revealing feelings and mental states with EmoTX, a novel AI framework powered by Transformer.


Las películas son una de las expresiones artísticas más importantes de historias y sentimientos. Por ejemplo, en “En busca de la felicidad”, el protagonista pasa por una serie de emociones, experimentando momentos difíciles como una ruptura y la falta de hogar, y momentos felices como lograr un trabajo codiciado. Estos intensos sentimientos involucran al público, que puede relacionarse con el viaje del personaje. Para comprender estas narrativas en el campo de la inteligencia artificial (IA), es crucial que las máquinas monitoreen el desarrollo de las emociones y estados mentales de los personajes a lo largo de la historia. Este objetivo se persigue utilizando anotaciones de MovieGraphs y entrenando modelos para observar escenas, analizar diálogos y hacer predicciones sobre las emociones y estados mentales de los personajes.
El tema de las emociones ha sido ampliamente explorado a lo largo de la historia; desde la clasificación de cuatro vías de Cicerón en la Antigua Roma hasta la investigación cerebral contemporánea, el concepto de las emociones ha cautivado constantemente el interés de la humanidad. Los psicólogos han contribuido a este campo introduciendo estructuras como la rueda de Plutchik o la propuesta de expresiones faciales universales de Ekman, ofreciendo diversos marcos teóricos. Las emociones afectivas también se categorizan en estados mentales que abarcan aspectos afectivos, conductuales y cognitivos, así como estados corporales.
En un estudio reciente, un proyecto conocido como Emotic introdujo 26 grupos distintos de etiquetas de emociones al procesar contenido visual. Este proyecto sugirió un marco de trabajo de multi-etiquetas, permitiendo la posibilidad de que una imagen pueda transmitir varias emociones al mismo tiempo, como la paz y la participación. Como alternativa al enfoque categórico convencional, el estudio también incorporó tres dimensiones continuas: valencia, activación y dominancia.
- Deprecación de la autenticación de Git utilizando contraseña
- Comenzando con la IA
- Puntuación F1 Una guía visual – Y por qué no te salvará de los datos desequilibrados
El análisis debe abarcar diversas modalidades contextuales para predecir de manera precisa una amplia gama de emociones. Los caminos prominentes en el reconocimiento multimodal de emociones incluyen el Reconocimiento de Emociones en Conversaciones (ERC), que implica categorizar emociones para cada instancia de intercambio de diálogo. Otro enfoque es predecir un puntaje de valencia-actividad singular para segmentos cortos de clips de películas.
Operar a nivel de una escena de película implica trabajar con una colección de tomas que cuentan colectivamente una subhistoria dentro de una ubicación específica, involucrando un elenco definido y ocurriendo en un marco de tiempo breve de 30 a 60 segundos. Estas escenas ofrecen una duración significativamente mayor que los diálogos individuales o los clips de películas. El objetivo es predecir las emociones y estados mentales de cada personaje en la escena, incluyendo la acumulación de etiquetas a nivel de escena. Dado el período de tiempo extendido, esta estimación conduce naturalmente a un enfoque de clasificación de múltiples etiquetas, ya que los personajes pueden transmitir múltiples emociones al mismo tiempo (como la curiosidad y la confusión) o experimentar transiciones debido a las interacciones con otros (por ejemplo, pasar de la preocupación a la calma).
Además, aunque las emociones pueden ser ampliamente categorizadas como parte de los estados mentales, este estudio distingue entre emociones expresadas, que son visiblemente evidentes en la actitud de un personaje (por ejemplo, sorpresa, tristeza, enojo), y estados mentales latentes, que solo son discernibles a través de interacciones o diálogos (por ejemplo, cortesía, determinación, confianza, ayuda). Los autores argumentan que clasificar de manera efectiva dentro de un amplio espacio de etiquetas emocionales requiere considerar el contexto multimodal. Como solución, proponen EmoTx, un modelo que incorpora simultáneamente frames de video, enunciados de diálogo y apariencias de personajes.
Se presenta una descripción general de este enfoque en la siguiente figura.

EmoTx utiliza un enfoque basado en Transformers para identificar emociones a nivel de personaje y escena de película. El proceso comienza con una canalización inicial de preprocesamiento de video y extracción de características, que extrae representaciones relevantes de los datos. Estas características incluyen datos de video, rostros de personajes y características de texto. En este contexto, se introducen embeddings adecuados a los tokens para diferenciación basada en modalidades, enumeración de personajes y contexto temporal. Además, se generan tokens que funcionan como clasificadores para emociones individuales y se vinculan a la escena o personajes específicos. Una vez incrustados, estos tokens se combinan mediante capas lineales y se alimentan a un codificador Transformer, lo que permite la integración de información en diferentes modalidades. El componente de clasificación del método se inspira en estudios previos sobre clasificación de múltiples etiquetas utilizando Transformers.
Un ejemplo del comportamiento de EmoTx publicado por los autores y relacionado con una escena de “Forrest Gump” se muestra en la siguiente imagen.
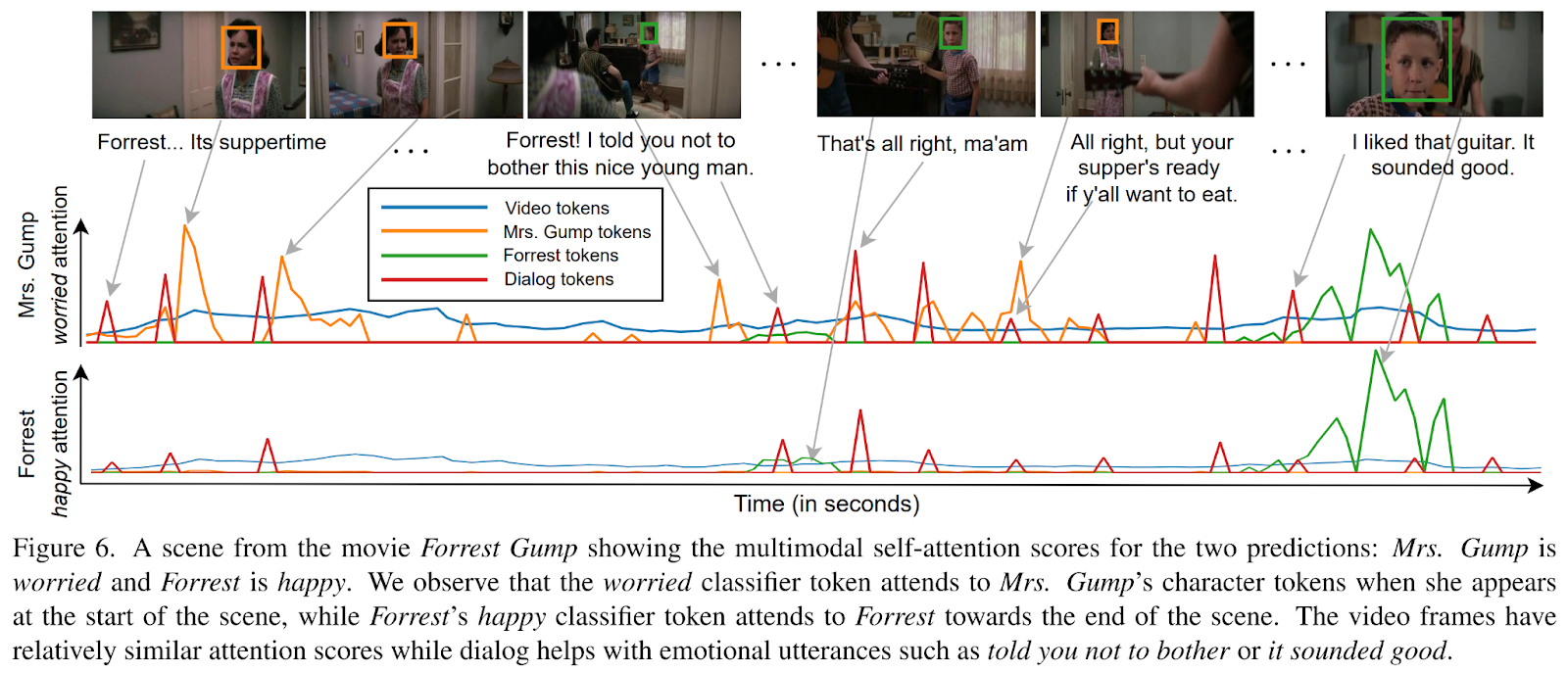
Este fue el resumen de EmoTx, una novedosa arquitectura basada en Transformer de IA llamada EmoTx que predice las emociones de los sujetos que aparecen en un videoclip a partir de datos multimodales adecuados. Si estás interesado y quieres aprender más al respecto, no dudes en consultar los enlaces citados a continuación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce Cursive Un Marco de Inteligencia Artificial Universal e Intuitivo para Interactuar con LLMs
- Deci presenta DeciCoder un modelo de lenguaje grande de código abierto con 1 billón de parámetros para generación de código.
- Cómo interpretar los coeficientes de regresión logística
- Organizando la IA generativa 5 lecciones aprendidas de los equipos de ciencia de datos
- Apoyando la sostenibilidad, la salud digital y el futuro del trabajo
- Cómo ayudar a los estudiantes de secundaria a prepararse para el auge de la inteligencia artificial
- Increíble nueva función de Inpainting a mitad de camino (Región variable)






