De papel a píxel Evaluando las mejores técnicas para digitalizar textos escritos a mano
De papel a píxel Evaluación de técnicas para digitalizar textos manuscritos
Un Buceo Comparativo en OCR, Modelos de Transformadores y Técnicas de Ensamble Basadas en Ingeniería de Indicaciones
Por: Sohrab Sani y Diego Capozzi
Las organizaciones han lidiado durante mucho tiempo con la tediosa y costosa tarea de digitalizar documentos históricos escritos a mano. Anteriormente, las técnicas de Reconocimiento Óptico de Caracteres (OCR, por sus siglas en inglés), como AWS Textract (TT) [1] y Azure Form Recognizer (FR) [2], han sido las líderes en esto. Aunque estas opciones pueden estar ampliamente disponibles, tienen muchas desventajas: son costosas, requieren un largo procesamiento/limpieza de datos y pueden dar lugar a precisión subóptima. Los avances recientes en Aprendizaje Profundo en segmentación de imágenes y Procesamiento de Lenguaje Natural que utilizan arquitecturas basadas en transformadores han permitido el desarrollo de técnicas sin OCR, como el modelo Document Understanding Transformer (Donut)[3].
En este estudio, compararemos las técnicas de OCR y basadas en transformadores para este proceso de digitalización con nuestro conjunto de datos personalizado, que se creó a partir de una serie de formularios escritos a mano. La evaluación de esta tarea relativamente simple tiene como objetivo avanzar hacia aplicaciones más complejas en documentos escritos a mano más largos. Para aumentar la precisión, también exploramos el uso de un enfoque de ensamble utilizando ingeniería de indicaciones con el modelo de Lenguaje de Gran Tamaño gpt-3.5-turbo (LLM) para combinar las salidas de TT y el modelo Donut afinado.
El código de este trabajo se puede ver en este repositorio de GitHub. El conjunto de datos está disponible en nuestro repositorio de Hugging Face aquí.
- Cómo guiar a ChatGPT para que escriba textos técnicos de calidad para tu sitio web
- GraphReduce Utilizando Grafos para Abstracciones de Ingeniería de Características
- Simplifica el acceso a la información interna utilizando la Generación Mejorada de Recuperación y los Agentes de LangChain
Tabla de Contenidos:
· Creación del conjunto de datos· Métodos ∘ Azure Form Recognizer (FR) ∘ AWS Textract (TT) ∘ Donut ∘ Método de Ensamble: TT, Donut, GPT· Medición del Rendimiento del Modelo ∘ FLA ∘ CBA ∘ Cobertura ∘ Costo· Resultados· Consideraciones Adicionales ∘ Entrenamiento del modelo Donut ∘ Variabilidad en la ingeniería de indicaciones· Conclusión· Próximos Pasos· Referencias· Agradecimientos
Creación del conjunto de datos
Este estudio creó un conjunto de datos personalizado a partir de 2100 imágenes de formularios escritos a mano del conjunto de datos NIST Special Database 19 [4]. La Figura 1 muestra una imagen de muestra de uno de estos formularios. La colección final incluye 2099 formularios. Para curar este conjunto de datos, recortamos la sección superior de cada formulario de NIST, enfocándonos en las claves de FECHA, CIUDAD, ESTADO y CÓDIGO POSTAL (ahora denominado “ZIP”) resaltadas en el recuadro rojo [Figura 1]. Este enfoque inició el proceso de evaluación con una tarea de extracción de texto relativamente simple, lo que nos permitió seleccionar y etiquetar rápidamente el conjunto de datos de forma manual. Hasta la fecha de escritura, no conocemos ningún conjunto de datos disponible públicamente con imágenes etiquetadas de formularios escritos a mano que se puedan utilizar para extracciones de texto de campos clave en formato JSON.
Extraímos manualmente los valores de cada clave de los documentos y los verificamos para asegurar su precisión. En total, se descartaron 68 formularios que contenían al menos un carácter ilegible. Los caracteres de los formularios se registraron tal como aparecían, sin importar los errores ortográficos o las inconsistencias de formato.
Para ajustar finamente el modelo Donut en los datos faltantes, agregamos 67 formularios vacíos que permitirían el entrenamiento para estos campos vacíos. Los valores faltantes dentro de los formularios se representan como una cadena “None” en la salida JSON.
La Figura 2a muestra un formulario de muestra de nuestro conjunto de datos, mientras que la Figura 2b muestra el JSON correspondiente que luego se vincula a ese formulario.
La Tabla 1 proporciona un desglose de la variabilidad dentro del conjunto de datos para cada clave. De mayor a menor variabilidad, el orden es ZIP, CIUDAD, FECHA y ESTADO. Todas las fechas estaban dentro del año 1989, lo que puede haber reducido la variabilidad general de las FECHAS. Además, aunque solo hay 50 estados en los Estados Unidos, la variabilidad de los ESTADOS se incrementó debido a los diferentes acrónimos o deletreos sensibles a mayúsculas y minúsculas que se utilizaron para las entradas de estados individuales.
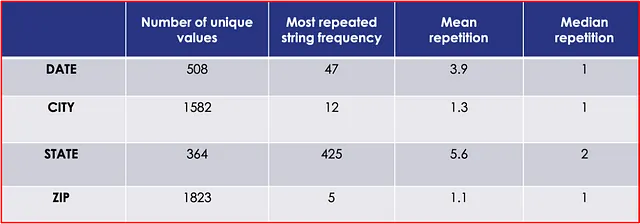
La Tabla 2 resume las longitudes de caracteres para varios atributos de nuestro conjunto de datos.
Los datos anteriores muestran que las entradas de CIUDAD tenían la longitud de caracteres más larga, mientras que las entradas de ESTADO tenían la más corta. Los valores medianos para cada entrada siguen de cerca sus respectivas medias, lo que indica una distribución relativamente uniforme de las longitudes de caracteres alrededor del promedio para cada categoría.
Después de anotar los datos, los dividimos en tres subconjuntos: entrenamiento, validación y prueba, con tamaños de muestra respectivos de 1400, 199 y 500. Aquí hay un enlace al cuaderno que usamos para esto.
Métodos
Ahora ampliaremos cada método que probamos y enlazaremos estos con códigos de Python relevantes que contienen más detalles. La aplicación de los métodos se describe primero individualmente, es decir, FR, TT y Donut, y luego secundariamente, con el enfoque de ensamblaje TT+GPT+Donut.
Azure Form Recognizer (FR)
La Figura 3 muestra el flujo de trabajo para extraer texto manuscrito de nuestras imágenes de formulario utilizando Azure FR:
- Almacenar las imágenes: Esto podría ser en una unidad local u otra solución, como un cubo S3 o Azure Blob Storage.
- Azure SDK: Script de Python para cargar cada imagen desde el almacenamiento y transferir estas al API de FR a través de Azure SDK.
- Post-procesamiento: El uso de un método predefinido significa que la salida final a menudo necesita refinamiento. Aquí están las 21 claves extraídas que requieren un procesamiento adicional: [‘FECHA’, ‘CIUDAD’, ‘ESTADO’, ‘FECHA’, ‘CÓDIGO POSTAL’, ‘NOMBRE’, ‘E CÓDIGO POSTAL’, ‘·FECHA’, ‘.FECHA’, ‘NAMR’, ‘FECHA®’, ‘NAMA’, ‘_CÓDIGO POSTAL’, ‘.CÓDIGO POSTAL’, ‘imprimir las siguientes tiendas en aca i’, ‘-FECHA’, ‘FECHA.’, ‘No.’, ‘NAMN’, ‘ESTADO\nCÓDIGO POSTAL’] Algunas claves tienen puntos o guiones bajos adicionales que necesitan ser eliminados. Debido a la posición cercana del texto dentro de los formularios, hay numerosas instancias en las que los valores extraídos se asocian erróneamente con claves incorrectas. Estos problemas se abordan en cierta medida.
- Guardar el resultado: Guardar el resultado en un espacio de almacenamiento en formato pickle.
AWS Textract (TT)
La Figura 4 muestra el flujo de trabajo para extraer texto manuscrito de nuestras imágenes de formulario utilizando AWS TT:
- Almacenar las imágenes: Las imágenes se almacenan en un cubo S3.
- SageMaker Notebook: Una instancia de Notebook facilita la interacción con el API de TT, ejecuta la limpieza posterior del script y guarda los resultados.
- API de TT: Este es el API de extracción de texto basado en OCR predefinido proporcionado por AWS.
- Post-procesamiento: El uso de un método predefinido significa que la salida final a menudo necesita refinamiento. TT produjo un conjunto de datos con 68 columnas, que es más que las 21 columnas del enfoque FR. Esto se debe principalmente a la detección de texto adicional en las imágenes que se considera campos. Estos problemas se abordan durante el post-procesamiento basado en reglas.
- Guardar el resultado: Los datos refinados se almacenan en un cubo S3 utilizando el formato pickle.
Donut
En contraste con los enfoques basados en OCR listos para usar, que no pueden adaptarse a datos de entrada específicos a través de campos personalizados y/o reentrenamiento de modelos, esta sección se adentra en la mejora del enfoque sin OCR utilizando el modelo Donut, que se basa en la arquitectura del modelo transformer.
Primero, ajustamos el modelo Donut con nuestros datos antes de aplicar el modelo a nuestras imágenes de prueba para extraer el texto manuscrito en formato JSON. Con el fin de volver a entrenar el modelo de manera eficiente y evitar el posible sobreajuste, utilizamos el módulo EarlyStopping de PyTorch Lightning. Con un tamaño de lote de 2, el entrenamiento finalizó después de 14 épocas. Estos son más detalles sobre el proceso de ajuste fino del modelo Donut:
- Asignamos 1,400 imágenes para el entrenamiento, 199 para la validación y las 500 restantes para las pruebas.
- Utilizamos un modelo base naver-clova-ix/donut-base como nuestro modelo de base, el cual se encuentra disponible en Hugging Face.
- Este modelo luego fue ajustado fino utilizando una GPU Quadro P6000 con 24GB de memoria.
- El tiempo total de entrenamiento fue de aproximadamente 3.5 horas.
- Para obtener más detalles de configuración intrincados, consulte el archivo
train_nist.yamlen el repositorio.
Este modelo también se puede descargar desde nuestro repositorio en Hugging Face.
Método de Ensamble: TT, Donut, GPT
Se exploraron varios métodos de ensamblaje y la combinación de TT, Donut y GPT fue la que mejor funcionó, como se explica a continuación.
Una vez que se obtuvieron las salidas JSON mediante la aplicación individual de TT y Donut, se utilizaron como entradas a una consulta que luego se pasó a GPT. El objetivo era utilizar GPT para tomar la información dentro de estas entradas JSON, combinarla con información contextual de GPT y crear una salida JSON nueva/más limpia con mayor confiabilidad y precisión de contenido [Tabla 3]. La Figura 5 proporciona una descripción visual de este enfoque de ensamblaje.
La creación de la consulta GPT adecuada para esta tarea fue iterativa y requirió la introducción de reglas ad hoc. La adaptación de la consulta GPT a esta tarea, y posiblemente al conjunto de datos, es un aspecto de este estudio que requiere exploración, como se menciona en la sección Consideraciones Adicionales.
Medición del Rendimiento del Modelo
Este estudio midió el rendimiento del modelo principalmente mediante el uso de dos medidas de precisión distintas:
- Precisión a Nivel de Campo (FLA, por sus siglas en inglés)
- Precisión Basada en Caracteres (CBA, por sus siglas en inglés)
También se midieron cantidades adicionales, como Cobertura y Costo, para proporcionar información contextual relevante. Todas las métricas se describen a continuación.
FLA
Esta es una medida binaria: si todos los caracteres de las claves dentro del JSON predicho coinciden con los del JSON de referencia, entonces el FLA es 1; sin embargo, si al menos un carácter no coincide, el FLA es 0.
Consideremos los ejemplos:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42071'}Comparar JSON1 y JSON2 utilizando FLA resulta en una puntuación de 0 debido a la discrepancia en ZIP. Sin embargo, al comparar JSON1 consigo mismo, se obtiene una puntuación de FLA de 1.
CBA
Esta medida de precisión se calcula de la siguiente manera:
- Determinando la distancia de edición de Levenshtein para cada par de valores correspondientes.
- Obteniendo una puntuación normalizada sumando todas las distancias y dividiendo por la longitud total combinada de cada valor.
- Convirtiendo esta puntuación en un porcentaje.
La distancia de edición de Levenshtein entre dos cadenas es el número de cambios necesarios para transformar una cadena en otra. Esto implica contar sustituciones, inserciones o eliminaciones. Por ejemplo, transformar “marry” en “Murray” requeriría dos sustituciones y una inserción, lo que resulta en un total de tres cambios. Estas modificaciones se pueden realizar en varias secuencias, pero al menos se necesitan tres acciones. Para este cálculo, utilizamos la función edit_distance de la biblioteca NLTK.
A continuación se muestra un fragmento de código que ilustra la implementación del algoritmo descrito. Esta función acepta dos entradas JSON y devuelve un porcentaje de precisión.
def dict_distance (dict1:dict, dict2:dict) -> float: distance_list = [] character_length = [] for key, value in dict1.items(): distance_list.append(edit_distance(dict1[key].strip(), dict2[key].strip())) if len(dict1[key]) > len(dict2[key]): character_length.append((len(dict1[key]))) else: character_length.append((len(dict2[key]))) accuracy = 100 - sum(distance_list)/(sum(character_length))*100 return accuracyPara comprender mejor la función, veamos cómo se desempeña en los siguientes ejemplos:
JSON1 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'KY', 'ZIP': '42171'}JSON2 = {'DATE': 'None', 'CITY': 'None', 'STATE': 'None', 'ZIP': 'None'}JSON3 = {'DATE': '8/28/89', 'CITY': 'Murray', 'STATE': 'None', 'ZIP': 'None'}dict_distance(JSON1, JSON1): 100% No hay diferencia entre JSON1 y JSON1, por lo que obtenemos una puntuación perfecta del 100%dict_distance(JSON1, JSON2): 0% Cada carácter en JSON2 necesitaría ser alterado para que coincida con JSON1, lo que resulta en una puntuación del 0%.dict_distance(JSON1, JSON3): 59% Cada carácter en los campos STATE y ZIP de JSON3 debe cambiarse para que coincida con JSON1, lo que resulta en una puntuación de precisión del 59%.
Ahora nos centraremos en el valor promedio de CBA sobre la muestra de imágenes analizadas. Ambas medidas de precisión son muy estrictas, ya que miden si todos los caracteres y casos de caracteres de las cadenas examinadas coinciden. FLA es particularmente conservador debido a su naturaleza binaria, lo que lo ciega hacia casos parcialmente correctos. Aunque CBA es menos conservador que FLA, todavía se considera algo conservador. Además, CBA tiene la capacidad de identificar casos parcialmente correctos, pero también considera el caso del texto (mayúsculas vs. minúsculas), lo cual puede tener niveles de importancia diferentes dependiendo de si el enfoque es recuperar el contenido apropiado del texto o preservar la forma exacta del contenido escrito. En general, decidimos utilizar estas medidas estrictas para un enfoque más conservador, ya que priorizamos la corrección de la extracción de texto sobre la semántica del texto.
Cobertura
Esta cantidad se define como la fracción de imágenes de formularios cuyos campos han sido extraídos en el JSON de salida. Es útil para monitorizar la capacidad general de extraer todos los campos de los formularios, independientemente de su corrección. Si la Cobertura es muy baja, indica que ciertos campos se están dejando sistemáticamente fuera del proceso de extracción.
Costo
Esta es una estimación simple del costo incurrido al aplicar cada método al conjunto de datos de prueba completo. No hemos capturado el costo de GPU para afinar el modelo Donut.
Resultados
Evaluamos el rendimiento de todos los métodos en el conjunto de datos de prueba, que incluía 500 muestras. Los resultados de este proceso se resumen en la Tabla 3.
Cuando se utiliza FLA, observamos que los métodos más tradicionales basados en OCR, FR y TT, tienen un rendimiento similar con precisión relativamente baja (FLA~37%). Si bien no es ideal, esto puede deberse a los requisitos estrictos de FLA. Alternativamente, al utilizar el CBA Total, que es el valor promedio de CBA al tener en cuenta todas las claves JSON juntas, los rendimientos tanto de TT como de FR son mucho más aceptables, con valores superiores al 77%. En particular, TT (CBA Total = 89.34%) supera a FR en ~15%. Este comportamiento se mantiene al centrarse en los valores de CBA medidos para los campos individuales del formulario, especialmente en las categorías DATE y CITY [Tabla 3], y al medir los valores de FLA y CBA Totals en toda la muestra de 2099 imágenes (TT: FLA = 40.06%; CBA Total = 86.64%; FR: FLA = 35,64%; CBA Total = 78.57%). Si bien el valor de Costo para aplicar estos dos modelos es el mismo, TT está mejor posicionado para extraer todos los campos del formulario con valores de Cobertura aproximadamente un 9% más altos que los de FR.
Cuantificar el rendimiento de estos modelos basados en OCR más tradicionales nos proporcionó un punto de referencia que luego utilizamos para evaluar las ventajas de utilizar un enfoque puramente Donut versus utilizar uno en combinación con TT y GPT. Comenzamos esto utilizando TT como nuestro punto de referencia.
Los beneficios de utilizar este enfoque se muestran a través de métricas mejoradas del modelo Donut que se ajustó en un tamaño de muestra de 1400 imágenes y sus JSON correspondientes. En comparación con los resultados de TT, el FLA global de este modelo del 54% y el CBA Total del 95.23% constituyen una mejora del 38% y del 6%, respectivamente. El aumento más significativo se observó en el FLA, lo que demuestra que el modelo puede recuperar con precisión todos los campos del formulario para más de la mitad de la muestra de prueba.
El aumento en el CBA es notable, dado el número limitado de imágenes utilizadas para ajustar el modelo. El modelo Donut muestra beneficios, como se evidencia por los valores globales mejorados en la cobertura y las métricas de CBA basadas en claves, que aumentaron entre un 2% y un 24%. La cobertura alcanzó el 100%, lo que indica que el modelo puede extraer texto de todos los campos del formulario, lo que reduce el trabajo de postprocesamiento involucrado en la producción de dicho modelo.
Basándonos en esta tarea y conjunto de datos, estos resultados ilustran que el uso de un modelo Donut ajustado produce resultados superiores a los producidos por un modelo OCR. Por último, se exploraron métodos de agrupamiento para evaluar si se pueden seguir realizando mejoras adicionales.
El rendimiento del conjunto de TT y el modelo Donut ajustado, impulsado por gpt-3.5-turbo, revela que se pueden lograr mejoras si se eligen métricas específicas, como FLA. Todas las métricas para este modelo (excluyendo CBA Estado y Cobertura) muestran un aumento, que oscila entre ~0.2% y ~10%, en comparación con las de nuestro modelo Donut ajustado. La única degradación del rendimiento se observa en el CBA Estado, que disminuye en ~3% en comparación con el valor medido para nuestro modelo Donut ajustado. Esto puede deberse a la indicación de GPT que se utilizó y que se puede ajustar aún más para mejorar esta métrica. Finalmente, el valor de la Cobertura permanece sin cambios en 100%.
En comparación con los otros campos individuales, la extracción de la Fecha (ver CBA Fecha) produjo una mayor eficiencia. Esto se debió probablemente a la limitada variabilidad en el campo de la Fecha, ya que todas las fechas se originaron en 1989.
Si los requisitos de rendimiento son considerablemente conservadores, entonces el aumento del 10% en el FLA es significativo y puede justificar el mayor costo de construcción y mantenimiento de una infraestructura más compleja. Esto también debe considerar la fuente de variabilidad introducida por la modificación de la indicación LLM, que se menciona en la sección Otras Consideraciones. Sin embargo, si los requisitos de rendimiento son menos estrictos, entonces las mejoras en las métricas de CBA generadas por este método de agrupamiento pueden no justificar el costo y el esfuerzo adicional.
En resumen, nuestro estudio muestra que si bien los métodos basados en OCR individuales, como FR y TT, tienen sus fortalezas, el modelo Donut, ajustado en solo 1400 muestras, supera fácilmente su punto de referencia de precisión. Además, el conjunto de TT y un modelo Donut ajustado mediante una indicación gpt-3.5-turbo aumenta aún más la precisión cuando se mide mediante la métrica FLA. También se deben tener en cuenta Otras Consideraciones sobre el proceso de ajuste fino del modelo Donut y la indicación GPT, que se exploran a continuación.
Otras Consideraciones
Entrenamiento del modelo Donut
Para mejorar la precisión del modelo Donut, experimentamos con tres enfoques de entrenamiento, cada uno destinado a mejorar la precisión de inferencia y evitar el sobreajuste a los datos de entrenamiento. La Tabla 4 muestra un resumen de nuestros resultados.
1. El entrenamiento de 30 épocas: Entrenamos el modelo Donut durante 30 épocas utilizando una configuración proporcionada en el repositorio de Donut en GitHub. Esta sesión de entrenamiento duró aproximadamente 7 horas y dio como resultado un FLA del 50,0%. Los valores de CBA para diferentes categorías variaron, con CITY alcanzando un valor del 90,55% y ZIP alcanzando el 98,01%. Sin embargo, notamos que el modelo comenzó a sobreajustarse después de la 19ª época cuando examinamos la métrica de validación.
2. El entrenamiento de 19 épocas: Basándonos en los conocimientos adquiridos durante el entrenamiento inicial, ajustamos el modelo durante solo 19 épocas. Nuestros resultados mostraron una mejora significativa en el FLA, que alcanzó el 55,8%. El CBA general, así como los CBA basados en claves, mostraron valores de precisión mejorados. A pesar de estas métricas prometedoras, detectamos un indicio de sobreajuste, como se indica en la métrica de validación.
3. El entrenamiento de 14 épocas: Para refinar aún más nuestro modelo y controlar el posible sobreajuste, utilizamos el módulo EarlyStopping de PyTorch Lightning. Este enfoque terminó el entrenamiento después de 14 épocas. Esto resultó en un FLA del 54,0%, y los CBA fueron comparables, si no mejores, que el entrenamiento de 19 épocas.
Al comparar las salidas de estas tres sesiones de entrenamiento, aunque el entrenamiento de 19 épocas produjo un FLA ligeramente mejor, las métricas de CBA en el entrenamiento de 14 épocas fueron en general superiores. Además, la métrica de validación reforzó nuestra preocupación con respecto al entrenamiento de 19 épocas, indicando una ligera inclinación hacia el sobreajuste.
En conclusión, dedujimos que el modelo que se ajustó durante 14 épocas utilizando EarlyStopping fue tanto el más sólido como el más rentable.
Variabilidad en la ingeniería de indicaciones
Trabajamos en dos enfoques de ingeniería de indicaciones (ver1 y ver2) para mejorar la eficiencia de extracción de datos mediante la combinación de un modelo Donut ajustado y nuestros resultados de TT. Después de entrenar el modelo durante 14 épocas, Prompt ver1 produjo resultados superiores con un FLA del 59,6% y métricas de CBA más altas para todas las claves [Tabla 5]. En contraste, Prompt ver2 experimentó un descenso, con su FLA disminuyendo al 54,4%. Un análisis detallado de las métricas de CBA indicó que las puntuaciones de precisión para cada categoría en ver2 eran ligeramente más bajas en comparación con las de ver1, resaltando la diferencia significativa que este cambio hizo.
Durante nuestro proceso de etiquetado manual del conjunto de datos, utilizamos los resultados de TT y FR, y desarrollamos Prompt ver1 mientras anotábamos el texto de los formularios. A pesar de ser intrínsecamente idéntico a su predecesor, Prompt ver2 fue ligeramente modificado. Nuestro objetivo principal era refinar la indicación eliminando líneas vacías y espacios redundantes que estaban presentes en Prompt ver1.
En resumen, nuestra experimentación destacó el impacto matizado de ajustes aparentemente menores. Mientras que Prompt ver1 mostró una mayor precisión, el proceso de refinar y simplificarlo en Prompt ver2, paradójicamente, llevó a una reducción en el rendimiento en todas las métricas. Esto resalta la naturaleza intrincada de la ingeniería de indicaciones y la necesidad de pruebas meticulosas antes de finalizar una indicación para su uso.
Prompt ver1 está disponible en este cuaderno, y se puede ver el código de Prompt ver2 aquí.
Conclusión
Creemos un conjunto de datos de referencia para la extracción de texto de imágenes de formularios manuscritos que contienen cuatro campos (FECHA, CIUDAD, ESTADO y CÓDIGO POSTAL). Estos formularios fueron anotados manualmente en formato JSON. Utilizamos este conjunto de datos para evaluar el rendimiento de modelos basados en OCR (FR y TT) y un modelo Donut, que luego se ajustó utilizando nuestro conjunto de datos. Por último, empleamos un modelo en conjunto que construimos mediante la ingeniería de indicaciones utilizando un LLM (gpt-3.5-turbo) con TT y los resultados de nuestro modelo Donut ajustado.
Descubrimos que TT tuvo un mejor rendimiento que FR y lo utilizamos como punto de referencia para evaluar las mejoras potenciales que podría generar un modelo Donut en forma aislada o en combinación con TT y GPT, que es el enfoque de conjunto. Como se muestra en las métricas de rendimiento del modelo, este modelo Donut ajustado mostró mejoras claras de precisión que justifican su adopción sobre los modelos basados en OCR. El modelo en conjunto mostró una mejora significativa del FLA, pero tiene un costo más alto y, por lo tanto, se puede considerar para su uso en casos con requisitos de rendimiento más estrictos. A pesar de emplear el mismo modelo subyacente, gpt-3.5-turbo, observamos diferencias notables en el formulario JSON de salida cuando se realizaron cambios menores en la indicación. Esta imprevisibilidad es una desventaja significativa al utilizar LLM predefinidos en producción. Actualmente estamos desarrollando un proceso de limpieza más compacto basado en un LLM de código abierto para abordar este problema.
Próximos Pasos
- La columna de precios en la Tabla 2 muestra que la llamada a la API de OpenAI fue el servicio cognitivo más costoso utilizado en este trabajo. Por lo tanto, para minimizar los costos, estamos trabajando en ajustar finamente un LLM para una tarea de seq2seq utilizando métodos como el ajuste fino completo, la sintonización de instrucciones[5] y QLORA[6].
- Por razones de privacidad, el recuadro del nombre en las imágenes del conjunto de datos está cubierto por un rectángulo negro. Estamos trabajando en actualizar esto agregando nombres y apellidos aleatorios al conjunto de datos, lo que aumentaría los campos de extracción de datos de cuatro a cinco.
- En el futuro, planeamos aumentar la complejidad de la tarea de extracción de texto al ampliar este estudio para incluir la extracción de texto de formularios completos u otros documentos más extensos.
- Investigar la optimización de hiperparámetros del modelo Donut.
Referencias
- Amazon Textract, AWS Textract
- Form Recognizer, Form Recognizer (ahora Document Intelligence)
- Kim, Geewook y Hong, Teakgyu y Yim, Moonbin y Nam, JeongYeon y Park, Jinyoung y Yim, Jinyeong y Hwang, Wonseok y Yun, Sangdoo y Han, Dongyoon y Park, Seunghyun, OCR-free Document Understanding Transformer (2022), Conferencia Europea sobre Visión por Computadora (ECCV)
- Grother, P. y Hanaoka, K. (2016) Base de Datos de Formularios y Caracteres Manuscritos del NIST (NIST Special Database 19). DOI: http://doi.org/10.18434/T4H01C
- Brian Lester, Rami Al-Rfou, Noah Constant, El poder de la escala para la sintonización eficiente de instrucciones (2021), arXiv:2104.08691
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer, QLoRA: Ajuste eficiente de LLM cuantificados (2023), https://arxiv.org/abs/2305.14314
Agradecimientos
Queremos agradecer a nuestro colega, Dr. David Rodrigues, por su continuo apoyo y las discusiones en torno a este proyecto. También queremos agradecer a Kainos por su apoyo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una revisión exhaustiva de la Blockchain en la Inteligencia Artificial
- Cómo construir un sistema Multi-GPU para Deep Learning en 2023
- Nuevo estudio sugiere la ecología como modelo para la innovación en IA
- Investigadores de China presentan ImageBind-LLM un método de ajuste de instrucciones de múltiples modalidades de modelos de lenguaje grandes (LLMs) a través de ImageBind.
- Comprendiendo el Aprendizaje Supervisado Teoría y Visión General
- Investigadores de Stanford introducen Protpardelle un modelo de difusión de todos los átomos revolucionario para el co-diseño de la estructura y secuencia de proteínas
- ¿Cómo deberíamos ver los datos clínicos sesgados en el aprendizaje automático médico? Un llamado a una perspectiva arqueológica





