Datos faltantes desmitificados la guía definitiva para científicos de datos
Datos faltantes desmitificados guía definitiva para científicos de datos
Crónicas de Calidad de Datos
Datos faltantes, mecanismos faltantes y perfilado de datos faltantes
A principios de este año, comencé un artículo sobre varios problemas (o características) de calidad de datos que comprometen en gran medida nuestros modelos de aprendizaje automático.
Uno de ellos fue, como era de esperar, los Datos Faltantes.
He estado estudiando este tema durante muchos años (¡lo sé, ¿verdad?!) pero a lo largo de algunos proyectos en los que contribuyo en la Comunidad Centrada en los Datos, me di cuenta de que muchos científicos de datos aún no han comprendido completamente la complejidad del problema, lo que me inspiró a crear este tutorial completo.
Hoy, profundizaremos en las complejidades del problema de los datos faltantes, descubriremos los diferentes tipos de datos faltantes que podemos encontrar en la vida real y exploraremos cómo podemos identificar y marcar los valores faltantes en conjuntos de datos del mundo real.
- Cómo las empresas están aprovechando la IA, IoT, AR/VR para alcanzar sus objetivos de sostenibilidad corporativa.
- Conferencia de Ciencia de Datos de la Universidad de San Francisco 2023 Datathon en colaboración con AWS y Amazon SageMaker Studio Lab
- Todo lo que debes saber sobre la evaluación de modelos de lenguaje grandes
El Problema de los Datos Faltantes
Los Datos Faltantes son una imperfección interesante en los datos, ya que pueden surgir naturalmente debido a la naturaleza del dominio, o crearse inadvertidamente durante la recolección, transmisión o procesamiento de datos.
En esencia, los datos faltantes se caracterizan por la aparición de valores ausentes en los datos, es decir, valores faltantes en algunos registros u observaciones en el conjunto de datos, y pueden ser univariados (una característica tiene valores faltantes) o multivariados (varias características tienen valores faltantes):
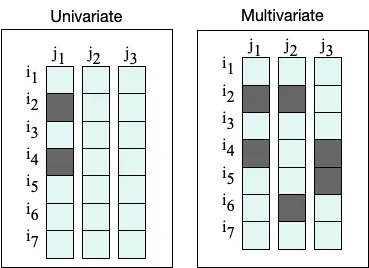
Consideremos un ejemplo. Digamos que estamos realizando un estudio sobre una cohorte de pacientes con diabetes, por ejemplo.
Los datos médicos son un gran ejemplo de esto, porque a menudo están altamente sujetos a valores faltantes: los valores de los pacientes se obtienen tanto de encuestas como de resultados de laboratorio, se pueden medir varias veces a lo largo del curso del diagnóstico o tratamiento, se almacenan en diferentes formatos (a veces distribuidos en diferentes instituciones) y son manejados por diferentes personas. ¡Puede (y seguramente lo hará) volverse confuso!
En nuestro estudio de diabetes, la presencia de valores faltantes puede estar relacionada con el estudio que se está realizando o con los datos que se están recopilando.
Por ejemplo, los datos faltantes pueden surgir debido a un sensor defectuoso que se apaga para valores altos de presión arterial. Otra posibilidad es que los valores faltantes en la característica “peso” sean más probables de faltar en mujeres mayores, que son menos propensas a revelar esta información. O los pacientes obesos pueden ser menos propensos a compartir su peso.
Por otro lado, los datos también pueden faltar por razones que no están relacionadas de ninguna manera con el estudio.
Un paciente puede tener parte de su información faltante porque un pinchazo de llanta de su vehículo causó que se perdiera una cita médica. Los datos también pueden faltar debido a errores humanos: por ejemplo, si la persona que realiza el análisis extravía o lee incorrectamente algunos documentos.
Independientemente de la razón por la cual faltan los datos, es importante investigar si los conjuntos de datos contienen datos faltantes antes de construir un modelo, ya que este problema puede tener consecuencias graves para los clasificadores:
- Algunos clasificadores no pueden manejar valores faltantes internamente: Esto los hace inaplicables cuando se manejan conjuntos de datos con datos faltantes. En algunos escenarios, estos valores se codifican con un valor predefinido, por ejemplo, “0”, para que los algoritmos de aprendizaje automático puedan manejarlos, aunque esta no es la mejor práctica, especialmente para porcentajes más altos de datos faltantes (o mecanismos faltantes más complejos);
- Las predicciones basadas en datos faltantes pueden ser sesgadas e poco confiables: Aunque algunos clasificadores pueden manejar datos faltantes internamente, sus predicciones podrían verse comprometidas, ya que una pieza importante de información podría faltar en los datos de entrenamiento.
Además, aunque los valores faltantes pueden “parecer todos iguales”, la verdad es que sus mecanismos subyacentes (la razón por la cual faltan) pueden seguir 3 patrones principales: Faltantes Completamente al Azar (MCAR), Faltantes No al Azar (MNAR) y Faltantes No al Azar (MNAR).
Mantener en mente estos diferentes tipos de mecanismos de faltantes es importante porque determinan la elección de métodos apropiados para manejar datos faltantes de manera eficiente y la validez de las inferencias derivadas de ellos.
¡Repasemos cada mecanismo rápidamente!
Mecanismos de Datos Faltantes
Si eres una persona matemática, te sugiero que leas este documento (cof cof), especialmente las secciones II y III, que contienen toda la notación y formulación matemática que estás buscando (de hecho, me inspiré en este libro, que también es una introducción muy interesante, revisa la Sección 2.2.3. y 2.2.4.).
Si también eres un aprendiz visual como yo, ¡te gustaría “verlo”, ¿verdad?
Para eso, echaremos un vistazo al ejemplo del estudio de tabaco en adolescentes, utilizado en el documento. Consideraremos datos ficticios para mostrar cada mecanismo de faltantes:
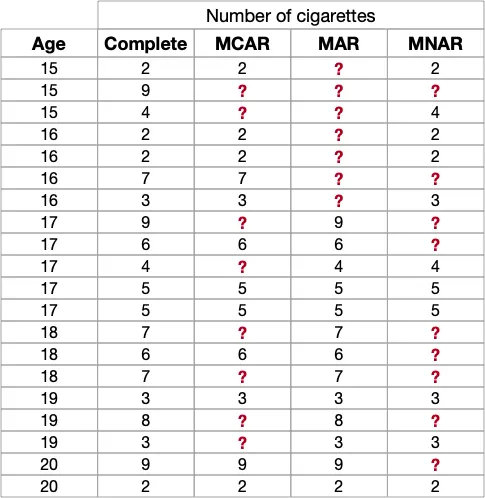
Una cosa que debes tener en cuenta es: los mecanismos de faltantes describen si y cómo el patrón de faltantes puede explicarse por los datos observados y/o los datos faltantes. Es complicado, lo sé. ¡Pero se aclarará más con el ejemplo!
En nuestro estudio de tabaco, nos estamos enfocando en el uso de tabaco en adolescentes. Hay 20 observaciones, correspondientes a 20 participantes, y la característica Edad está completamente observada, mientras que el Número de Cigarrillos (fumados por día) estará ausente según diferentes mecanismos.
Faltantes Completamente al Azar (MCAR): ¡Sin problemas!
En el mecanismo de Faltantes Completamente al Azar (MCAR), el proceso de faltantes no está relacionado en absoluto ni con los datos observados ni con los datos faltantes. Eso significa que la probabilidad de que una característica tenga valores faltantes es completamente aleatoria.
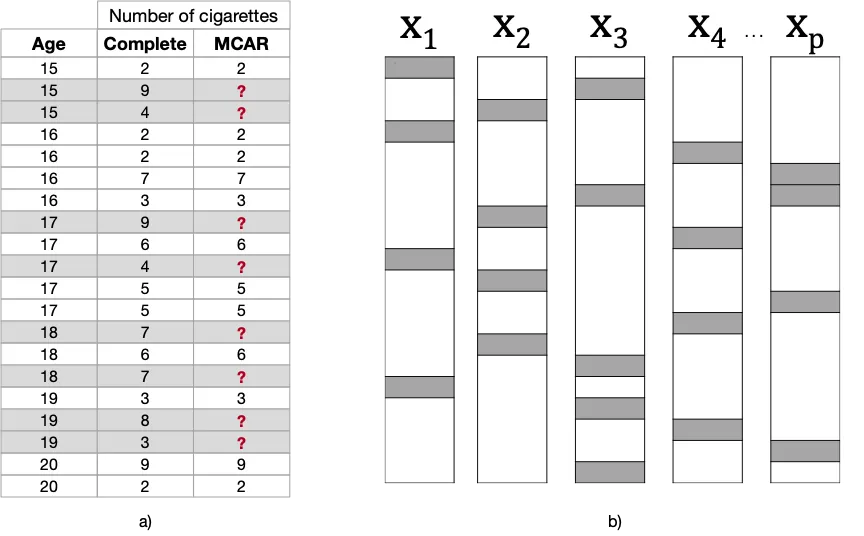
En nuestro ejemplo, simplemente eliminé algunos valores al azar. Observa cómo los valores faltantes no se encuentran en un rango particular de valores de Edad o Número de Cigarrillos. Este mecanismo puede ocurrir debido a eventos inesperados que suceden durante el estudio: por ejemplo, la persona encargada de registrar las respuestas de los participantes omitió accidentalmente una pregunta de la encuesta.
Faltantes Aleatorios (MAR): ¡Busca las señales!
El nombre es en realidad confuso, ya que los Faltantes Aleatorios (MAR) ocurren cuando el proceso de faltantes puede estar relacionado con la información observada en los datos (aunque no con la información faltante en sí).
Considera el siguiente ejemplo, donde eliminé los valores de Número de Cigarrillos solo para los participantes más jóvenes (entre 15 y 16 años). Observa que, a pesar de que el proceso de faltantes está claramente relacionado con los valores observados en Edad, no tiene relación alguna con el número de cigarrillos fumados por estos adolescentes, en caso de que se hubiera informado (observa la columna “Complete”, donde se encontrarían valores bajos y altos de cigarrillos entre los valores faltantes, si se hubieran observado).
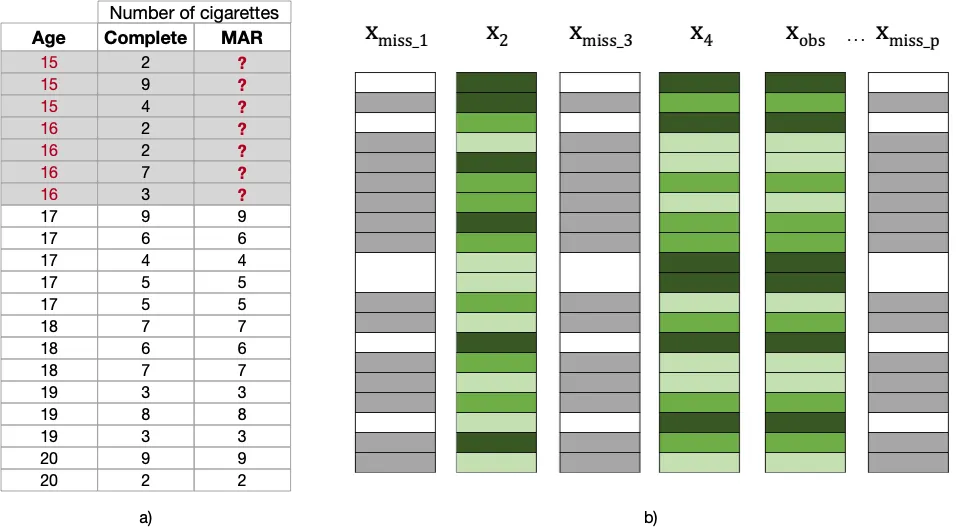
Este sería el caso si los niños más jóvenes fueran menos propensos a revelar la cantidad de cigarrillos que fuman al día, evitando admitir que son fumadores regulares (independientemente de la cantidad que fumen).
Falta de aleatoriedad (MNAR): ¡Ese momento ah-ha!
Como era de esperar, el mecanismo de falta de aleatoriedad (MNAR) es el más complicado de todos, ya que el proceso de falta de valores puede depender tanto de la información observada como de la información faltante en los datos. Esto significa que la probabilidad de que ocurran valores perdidos en una característica puede estar relacionada con los valores observados de otra característica en los datos, así como con los valores perdidos de esa misma característica.
Eche un vistazo al siguiente ejemplo: los valores están perdidos para cantidades más altas de Número de Cigarrillos, lo que significa que la probabilidad de valores perdidos en Número de Cigarrillos está relacionada con los valores perdidos en sí mismos, si hubieran sido observados (observe la columna “Completo”).
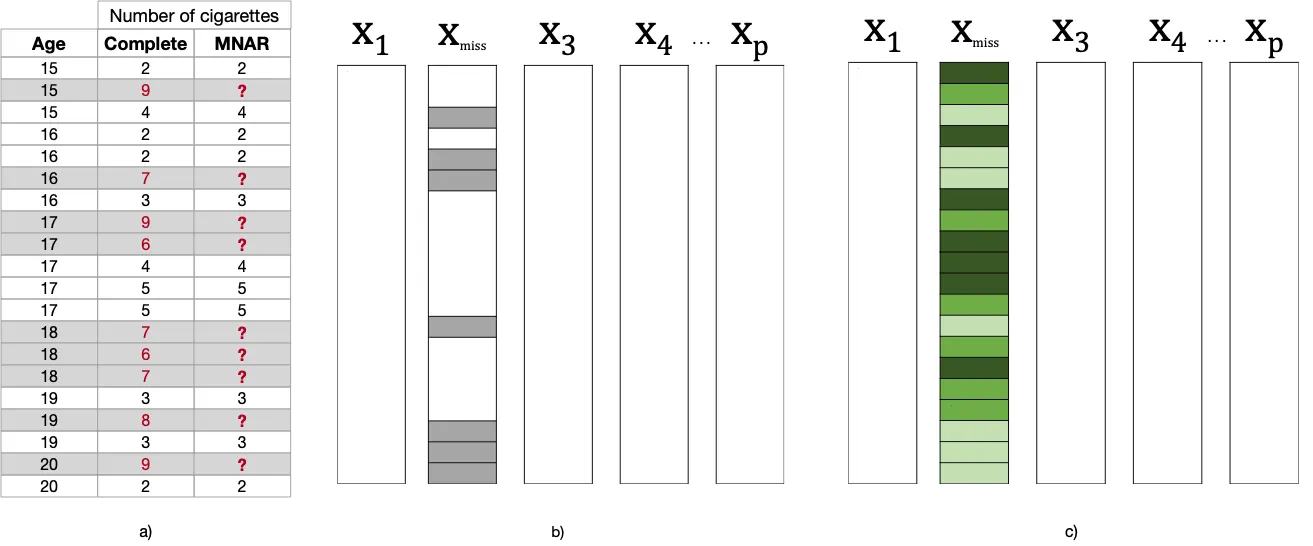
Este sería el caso de los adolescentes que se negaron a informar la cantidad de cigarrillos que fuman al día, ya que fumaban una cantidad muy grande.
El impacto de los mecanismos de datos faltantes
A lo largo de nuestro ejemplo simple, hemos visto cómo MCAR es el mecanismo más simple de los datos faltantes. En este escenario, podemos ignorar muchas de las complejidades que surgen debido a la aparición de valores perdidos y algunas soluciones simples como la eliminación de casos o imputaciones estadísticas más simples pueden funcionar.
Sin embargo, aunque conveniente, la verdad es que en dominios del mundo real, MCAR a menudo es irrealista y la mayoría de los investigadores generalmente asumen al menos MAR en sus estudios, que es más general y realista que MCAR. En este escenario, podemos considerar estrategias más robustas que pueden inferir la información faltante de los datos observados. En este sentido, las estrategias de imputación de datos basadas en aprendizaje automático son generalmente las más populares.
Finalmente, MNAR es, con mucho, el caso más complejo, ya que es muy difícil inferir las causas de la falta de valores. Los enfoques actuales se centran en mapear las causas de los valores perdidos utilizando factores de corrección definidos por expertos en el dominio, inferir datos faltantes de sistemas distribuidos, ampliar modelos de vanguardia (por ejemplo, modelos generativos) para incorporar múltiples imputaciones o realizar análisis de sensibilidad para determinar cómo cambian los resultados en diferentes circunstancias.
Además, en cuanto a la identificabilidad, el problema no se vuelve más fácil.
Aunque existen algunas pruebas para distinguir MCAR de MAR, no son ampliamente populares y tienen suposiciones restrictivas que no se cumplen en conjuntos de datos complejos del mundo real. También es imposible distinguir MNAR de MAR ya que falta la información necesaria.
Para diagnosticar y distinguir mecanismos faltantes en la práctica, podemos enfocarnos en pruebas de hipótesis, análisis de sensibilidad, obtener ideas de expertos en el dominio e investigar técnicas de visualización que puedan proporcionar una comprensión de los dominios.
Naturalmente, hay otras complejidades a tener en cuenta que condicionan la aplicación de estrategias de tratamiento para datos faltantes, como el porcentaje de datos que faltan, el número de características que afecta y el objetivo final de la técnica (por ejemplo, alimentar un modelo de entrenamiento para clasificación o regresión, reconstruir los valores originales de la manera más auténtica posible?).
En resumen, no es un trabajo fácil.
Identificar y marcar datos faltantes
Veámoslo poco a poco. Acabamos de aprender una sobrecarga de información sobre datos faltantes y sus complejas complicaciones.
En este ejemplo, cubriremos los conceptos básicos de cómo marcar y visualizar datos faltantes en un conjunto de datos del mundo real, y confirmaremos los problemas que los datos faltantes introducen en los proyectos de ciencia de datos.
Con ese fin, utilizaremos el conjunto de datos de diabetes de los indios Pima, disponible en Kaggle (Licencia: CC0: Dominio público). Si desea seguir el tutorial, siéntase libre de descargar el cuaderno desde el repositorio de GitHub de Data-Centric AI Community.
Para hacer un perfil rápido de sus datos, también utilizaremos ydata-profiling, que nos proporciona una descripción completa de nuestro conjunto de datos en solo unas pocas líneas de código. Comencemos por instalarlo:
Instalando la última versión de ydata-profiling. Fragmento por el autor.
Ahora, podemos cargar los datos y hacer un perfil rápido:
Cargando los datos y creando el informe de perfil. Fragmento por el autor.
Al observar los datos, podemos determinar que este conjunto de datos está compuesto por 768 registros/filas/observaciones (768 pacientes) y 9 atributos o características. De hecho, Outcome es la clase objetivo (1/0), por lo que tenemos 8 predictores (8 características numéricas y 1 categórica).
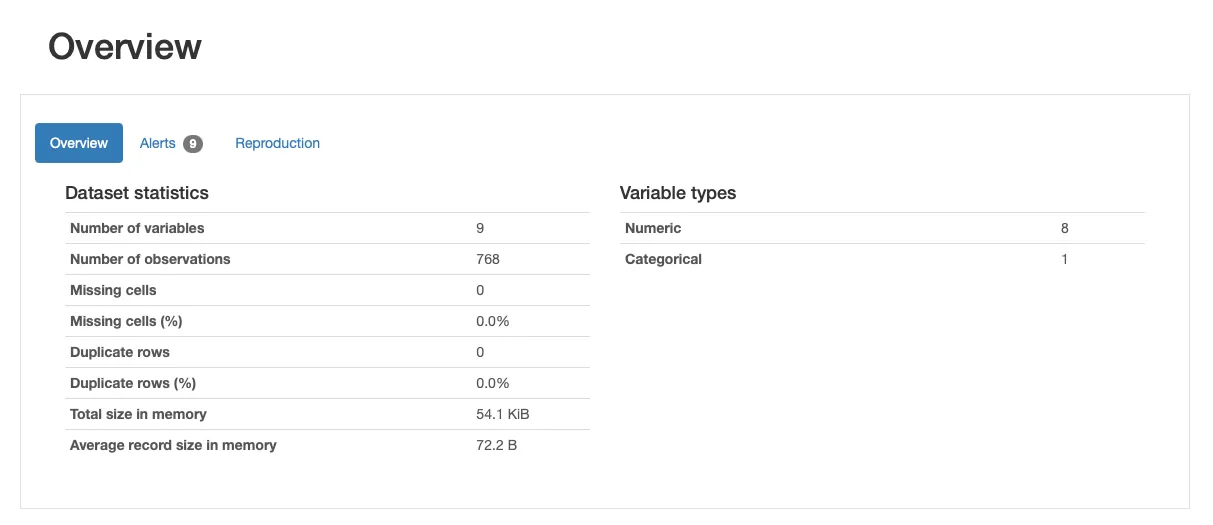
A primera vista, el conjunto de datos no parece tener datos faltantes. ¡Sin embargo, se sabe que este conjunto de datos está afectado por datos faltantes! ¿Cómo podemos confirmarlo?
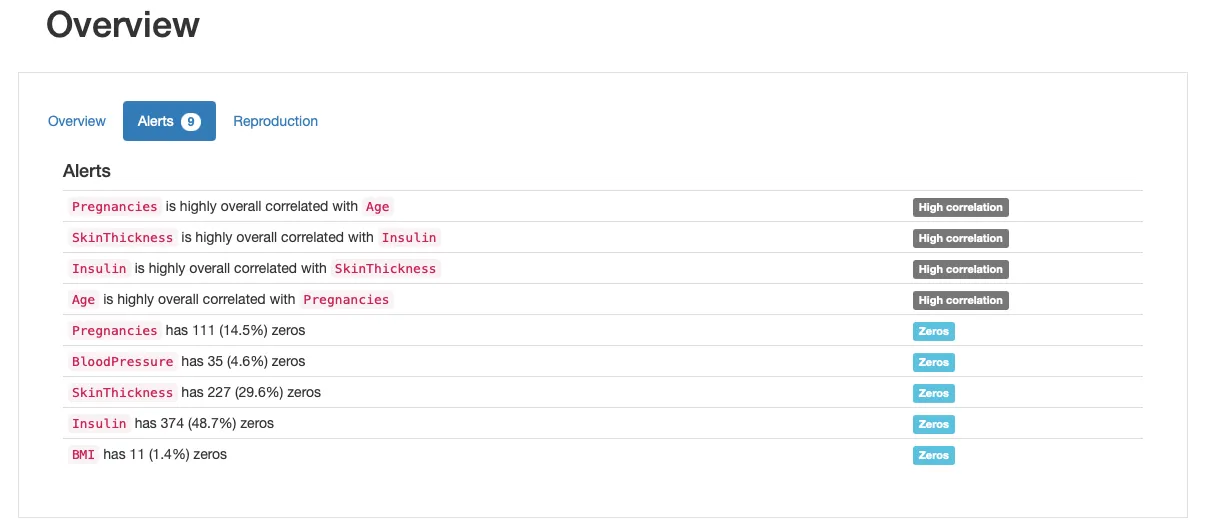
Al observar la sección “Alertas”, podemos ver varias alertas de “Ceros” que nos indican que hay varias características para las cuales los valores cero no tienen sentido o son biológicamente imposibles: por ejemplo, ¡un valor cero para el índice de masa corporal o la presión arterial es inválido!
Al recorrer todas las características, podemos determinar que los embarazos parecen estar bien (tener cero embarazos es razonable), pero para las características restantes, los valores cero son sospechosos:
En la mayoría de los conjuntos de datos del mundo real, los datos faltantes se codifican mediante valores centinela:
- Entradas fuera de rango, como
999; - Números negativos cuando la característica solo tiene valores positivos, por ejemplo,
-1; - Valores cero en una característica que nunca podría ser 0.
En nuestro caso, Glucose, BloodPressure, SkinThickness, Insulin y BMI tienen datos faltantes. Contemos la cantidad de ceros que tienen estas características:
Contando la cantidad de valores cero. Fragmento por el autor.
Podemos ver que Glucose, BloodPressure y BMI tienen solo unos pocos valores cero, mientras que SkinThickness y Insulin tienen muchos más, cubriendo casi la mitad de las observaciones existentes. Esto significa que podríamos considerar diferentes estrategias para manejar estas características: por ejemplo, algunas podrían requerir técnicas de imputación más complejas que otras.
Para que nuestro conjunto de datos sea consistente con las convenciones específicas de los datos, debemos convertir estos valores faltantes en NaN valores.
Esta es la forma estándar de tratar los datos faltantes en Python y la convención seguida por paquetes populares como pandas y scikit-learn. Estos valores se ignoran en ciertos cálculos como sum o count, y son reconocidos por algunas funciones para realizar otras operaciones (por ejemplo, eliminar los valores faltantes, imputarlos, reemplazarlos por un valor fijo, etc).
Marcaremos nuestros valores faltantes usando la función replace(), y luego llamaremos a isnan() para verificar si se codificaron correctamente:
Marcar los valores cero como valores NaN. Fragmento de autor.
¡El recuento de valores NaN es el mismo que los valores 0, lo que significa que hemos marcado correctamente nuestros valores faltantes! Luego podríamos usar el informe de perfil nuevamente para verificar que ahora los datos faltantes sean reconocidos. Así es como se ve nuestro “nuevo” conjunto de datos:
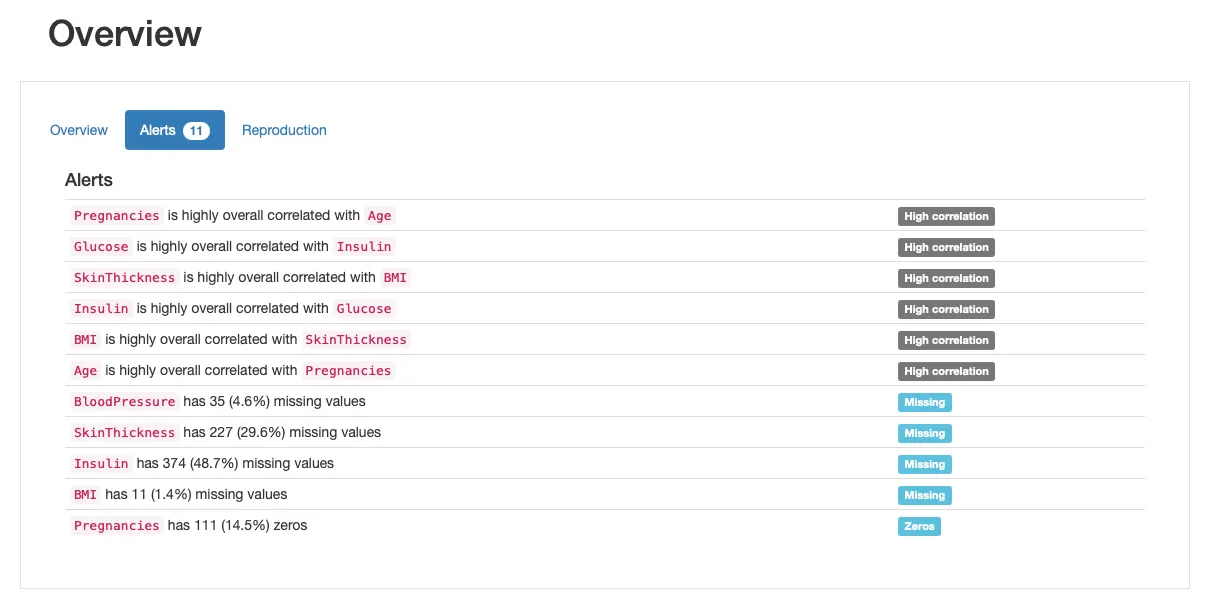
También podemos verificar algunas características del proceso de faltantes, revisando la sección “Valores faltantes” del informe:
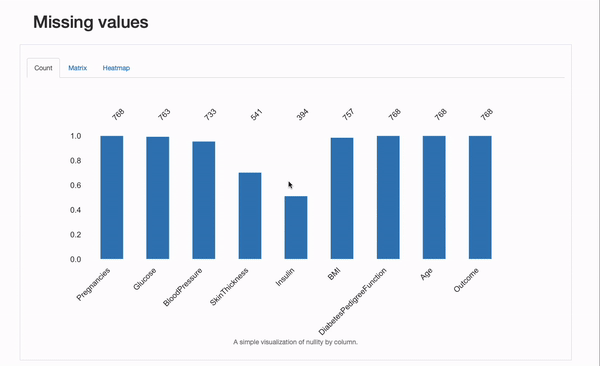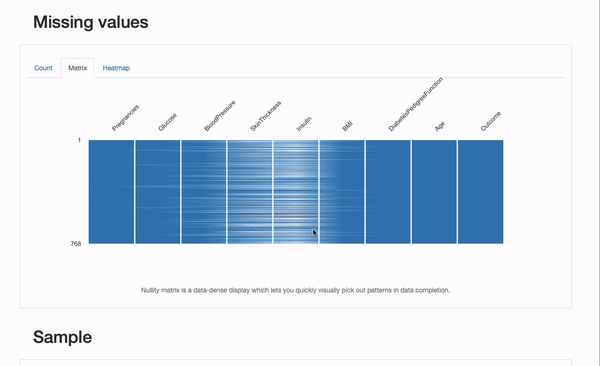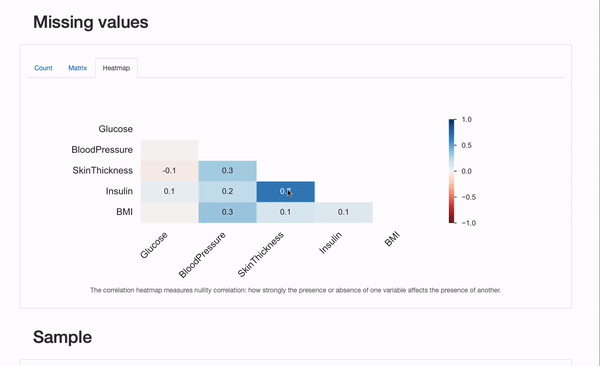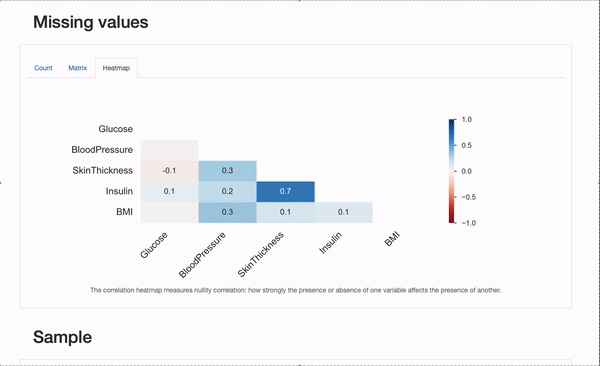
Además del gráfico de “Recuento”, que nos da una visión general de todos los valores faltantes por característica, podemos explorar los gráficos de “Matriz” y “Mapa de calor” en más detalle para plantear hipótesis sobre los mecanismos de faltantes subyacentes que los datos pueden sufrir. En particular, la correlación entre las características faltantes puede ser informativa. En este caso, parece haber una correlación significativa entre Insulin y SkinThicknes: ambos valores parecen faltar simultáneamente para algunos pacientes. Si esto es una coincidencia (improbable), o el proceso de faltantes puede explicarse por factores conocidos, como representar mecanismos MAR o MNAR, ¡sería algo en lo que podríamos profundizar!
De cualquier manera, ¡ahora tenemos nuestros datos listos para el análisis! Desafortunadamente, el proceso de manejo de datos faltantes está lejos de terminar. Muchos algoritmos clásicos de aprendizaje automático no pueden manejar datos faltantes, y necesitamos encontrar formas expertas de mitigar el problema. Intentemos evaluar el algoritmo de Análisis Discriminante Lineal (LDA) en este conjunto de datos:
Evaluando el algoritmo de Análisis Discriminante Lineal (LDA) con valores faltantes. Fragmento de autor.
Si intentas ejecutar este código, arrojará inmediatamente un error:

La forma más sencilla de solucionar esto (¡y la más ingenua!) sería eliminar todos los registros que contienen valores faltantes. Podemos hacer esto creando un nuevo marco de datos con las filas que contienen valores faltantes eliminados, usando la función dropna()…
Eliminar todas las filas/observaciones con valores faltantes. Fragmento de autor.
… y luego intentar de nuevo:
Evaluando el algoritmo LDA sin valores faltantes. Fragmento de autor.
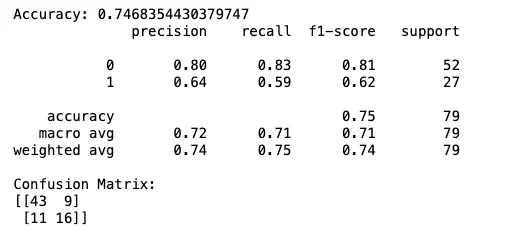
¡Y ahí lo tienes! Al eliminar los valores faltantes, el algoritmo LDA ahora puede funcionar normalmente.
Sin embargo, el tamaño del conjunto de datos se redujo sustancialmente a solo 392 observaciones, lo que significa que estamos perdiendo casi la mitad de la información disponible.
Por esa razón, en lugar de simplemente eliminar observaciones, deberíamos buscar estrategias de imputación, ya sea estadísticas o basadas en aprendizaje automático. También podríamos usar datos sintéticos para reemplazar los valores faltantes, dependiendo de nuestra aplicación final.
Y para eso, podríamos tratar de obtener una idea de los mecanismos subyacentes de falta de datos en los datos. ¿Algo para esperar en futuros artículos?
Reflexiones finales
En este artículo, hemos cubierto todos los conceptos básicos que los científicos de datos necesitan dominar al comenzar a trabajar con datos faltantes.
Desde el problema en sí, hasta los mecanismos de falta de datos, hemos descubierto el impacto que la falta de información puede tener en nuestros proyectos de ciencia de datos, y que, a pesar de que todos los NaNs pueden parecer iguales, pueden contar historias muy diferentes.
En mis siguientes artículos, abordaré específicamente cada mecanismo de falta de datos, centrándome en estrategias de generación, imputación y visualización para cada uno, así que mantente atento a las nuevas publicaciones en el blog y no olvides marcar el Repositorio de AI Centrado en Datos para no perderte ninguna actualización de código.
Como siempre, los comentarios, preguntas y sugerencias son muy bienvenidos. Puedes dejarme un comentario, contribuir al repositorio e incluso encontrarme en la Comunidad de AI Centrado en Datos para discutir otros temas relacionados con los datos. ¿Nos vemos allí?
Sobre mí
Ph.D., Investigador de Aprendizaje Automático, Educador, Defensor de Datos y en general un “todoterreno”. Aquí en VoAGI, escribo sobre AI Centrado en Datos y Calidad de Datos, educando a las comunidades de Ciencia de Datos y Aprendizaje Automático sobre cómo pasar de datos imperfectos a datos inteligentes.
Relaciones con Desarrolladores @ YData | Comunidad de AI Centrado en Datos | GitHub | Instagram | Google Scholar | LinkedIn
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo implementar el clustering jerárquico para campañas de marketing directo – con código Python
- Top 40+ Herramientas de IA Generativa (Septiembre 2023)
- Investigadores de la Universidad de Washington y AI2 presentan TIFA una métrica de evaluación automática que mide la fidelidad de una imagen generada por IA a través de VQA.
- Abriendo la caja negra
- Las 10 habilidades de IA más importantes para conseguir un trabajo en 2023
- Base de datos de vectores ¡Una guía para principiantes!
- 9 Mejores sitios web de IA (Tienes que probar antes de morir)





