Escalado de datos con Python
Data scaling with Python
Cómo escalar tus datos para hacerlos adecuados para la construcción de modelos.

En el proceso de aprendizaje automático, la escalación de datos se encuentra en el preprocesamiento de datos, o ingeniería de características. Escalar sus datos antes de utilizarlos para la construcción del modelo puede lograr lo siguiente:
- La escalación garantiza que las características tengan valores en el mismo rango.
- La escalación garantiza que las características utilizadas en la construcción del modelo sean adimensionales.
- La escalación se puede utilizar para detectar valores atípicos.
Existen varios métodos para escalar datos. Las dos técnicas de escalación más importantes son la Normalización y la Estandarización.
- El 70% de los desarrolladores adoptan la IA hoy en día adentrándose en el surgimiento de los grandes modelos de lenguaje, LangChain y las bases de datos vectoriales en el panorama tecnológico actual.
- Investigadores de Microsoft proponen un nuevo marco de trabajo para la calibración de LLM utilizando auto-supervisión óptima de Pareto sin utilizar datos de entrenamiento etiquetados.
- AI, Gemelos Digitales para Desatar la Próxima Ola de Innovación en la Investigación del Clima
Escalado de datos utilizando Normalización
Cuando los datos se escalan utilizando la normalización, los datos transformados se pueden calcular utilizando la siguiente ecuación:
donde
Implementación de la Normalización en Python
La escalación utilizando la normalización se puede implementar en Python utilizando el siguiente código:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)Sea X un conjunto de datos dado con
El X normalizado se muestra en la figura siguiente:
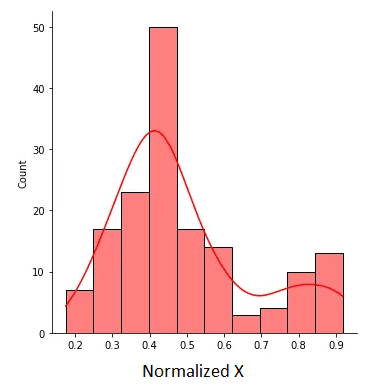 Figura 2. X normalizado con valores entre 0 y 1. Imagen del autor.
Figura 2. X normalizado con valores entre 0 y 1. Imagen del autor.
Escalado de datos utilizando Estandarización
Idealmente, la estandarización se debe utilizar cuando los datos se distribuyen de acuerdo a la distribución normal o Gaussiana. Los datos estandarizados se pueden calcular de la siguiente manera:
Aquí, es la media de los datos y
es la desviación estándar. Los valores estandarizados deberían estar típicamente en el rango [-2, 2], lo cual representa el intervalo de confianza del 95%. Los valores estandarizados inferiores a -2 o mayores a 2 se pueden considerar como valores atípicos. Por lo tanto, la estandarización se puede utilizar para la detección de valores atípicos.
Implementación de la Estandarización en Python
La escalación utilizando la estandarización se puede implementar en Python utilizando el siguiente código:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)Utilizando los datos descritos anteriormente, los datos estandarizados se muestran a continuación:
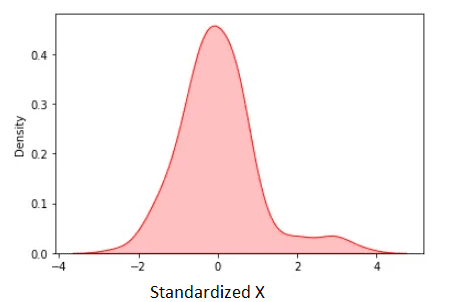 Figura 3. X estandarizado. Imagen del autor.
Figura 3. X estandarizado. Imagen del autor.
La media estandarizada es cero. Observamos en la figura anterior que excepto por algunos valores atípicos, la mayoría de los datos estandarizados se encuentran en el rango [-2, 2].
Conclusión
En resumen, hemos discutido dos de los métodos más populares para la escala de características, a saber: estandarización y normalización. Los datos normalizados se encuentran en el rango [0, 1], mientras que los datos estandarizados suelen encontrarse en el rango [-2, 2]. La ventaja de la estandarización es que se puede utilizar para la detección de valores atípicos. Benjamin O. Tayo es un físico, educador de ciencia de datos y escritor, además de ser el propietario de DataScienceHub. Anteriormente, Benjamin enseñaba ingeniería y física en la U. de Central Oklahoma, la U. Grand Canyon y la U. Pittsburgh State.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Resumen del artículo Un enfoque híbrido con GAN y DP para la preservación de la privacidad de los datos de IIoT.
- Análisis en base de datos aprovechando las funciones analíticas de SQL
- Deja de usar PowerPoint para tus presentaciones de ML y prueba esto en su lugar
- ¿Por qué el aprendizaje profundo siempre se realiza en datos de matriz? Nueva investigación de IA introduce ‘Spatial Functa’, donde desde los datos hasta la Functa se tratan como uno solo.
- La guía de campo de datos sintéticos
- Un nuevo estudio de investigación en IA presenta AttrPrompt un generador de datos de entrenamiento LLM para un nuevo paradigma en el aprendizaje de cero disparos.
- 4 Ideas Estadísticas Importantes que Deberías Comprender en un Mundo Impulsado por los Datos