Creando Operaciones de Aprendizaje Automático para Empresas
Creating Machine Learning Operations for Businesses
Un plano para MLOps efectivo para apoyar tu estrategia de IA

Antecedentes — Navegando MLOps
En mi carrera, he notado que la clave para estrategias de IA exitosas radica en la habilidad para implementar modelos de aprendizaje automático en producción, desbloqueando así su potencial comercial a gran escala. No obstante, esto no es tarea fácil — involucra la integración de diversas tecnologías, equipos y a menudo requiere un cambio cultural dentro de las organizaciones, un sistema referido como MLOps.
Sin embargo, no existe una estrategia MLOps universal. En este artículo, ofrezco un plano flexible de MLOps que puede ser un punto de partida o un medio para ajustar tu flujo de trabajo actual. Aunque el camino de MLOps puede ser complejo, recomiendo enfáticamente verlo como un paso inicial indispensable en la integración de la IA en tu negocio, en vez de una consideración secundaria.
MLOps va más allá de la tecnología
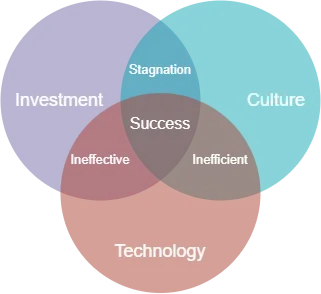
Antes de sumergirnos en las técnicas, me gustaría compartir percepciones (no técnicas) de mi experiencia observando diversas estrategias MLOps. MLOps es más que tecnología — depende de tres componentes clave: Inversión, Cultura y Tecnología. Empresas que han considerado los tres desde el principio tienden a tener más éxito con sus estrategias. Un error común que he visto es que las empresas priorizan la inversión en soluciones sin considerar cambios culturales necesarios. Este descuido podría socavar críticamente tu estrategia, posiblemente desperdiciando fondos y disminuyendo la confianza de tus ejecutivos o inversores.
Cultura
Introducir una cultura nueva a cualquier negocio no es tarea fácil y requiere apoyo total de su gente. Un error común que he visto es cuando las empresas reemplazan abruptamente herramientas antiguas con nuevas y brillantes sin considerar cambios culturales. Este enfoque puede generar resentimiento y resultar en que estas herramientas sean ignoradas o mal utilizadas.
- La Guía Esencial de Análisis Exploratorio de Datos para un Científico de Datos.
- Predicción del éxito de un programa de recompensas en Starbucks.
- Regresión Lineal y Descenso del Gradiente
Por el contrario, las empresas que manejan cambios culturales de forma efectiva han involucrado a los usuarios finales en la elaboración de la estrategia MLOps y les han asignado responsabilidades para promover la propiedad. Además, han proporcionado apoyo y capacitación esenciales para mejorar las habilidades de los usuarios y recompensar su compromiso en estas iniciativas.
Una solución puede ser técnicamente superior, pero sin impulsar un cambio cultural, corre el riesgo de ser ineficaz. Después de todo, son las personas las que operan las tecnologías, no al revés.
Tecnología
Por brevedad, he definido la tecnología como una combinación de infraestructura técnica y servicios de gestión de datos.
Una estrategia de MLOps efectiva se construye sobre un ecosistema de datos maduro. Al aprovechar las herramientas de gestión de datos, los científicos de datos deberían estar facultados para acceder a los datos para el desarrollo de modelos de manera segura y cumpliendo normas regulatorias.
Desde el punto de vista de la infraestructura técnica, debemos facultar a los científicos de datos e ingenieros de ML para acceder a los componentes hardware y software necesarios para facilitar el desarrollo y entrega de productos de IA. Para muchas empresas, aprovechar la infraestructura en la nube es esencial para habilitar esto.
Inversión
No hay atajos en MLOps, especialmente cuando se trata de inversión. Una estrategia de MLOps eficiente debería priorizar inversiones tanto en personas como en tecnología. Un problema recurrente que encuentro con los clientes es la tendencia a construir una estrategia de MLOps centrada en un único científico de datos debido a limitaciones presupuestarias. En tales casos, generalmente recomiendo una reevaluación o al menos moderar las expectativas.
Desde el inicio, es imperativo establecer el alcance de tu inversión en innovación y su duración. En verdad, la inversión continua es vital si deseas que la IA se convierta en algo fundamental para tus operaciones y obtener los beneficios asociados.
Para una visión sobre el desarrollo de estrategias de IA, quizá desees leer mi artículo sobre la creación de estrategias de IA con mapas de Wardley:
Creando Estrategias de IA para Negocios
El arte de crear una estrategia de inteligencia artificial a través de mapas de Wardley
towardsdatascience.com
Un diseño de alto nivel para MLOps
Ahora que hemos establecido las bases, nos adentraremos en algunos de los componentes técnicos de MLOps. Para ayudar en la visualización, he diseñado un diagrama de flujo que ilustra las relaciones entre los procesos. Donde hay líneas discontinuas, fluye la información. Donde existe una línea sólida, hay una transición de una actividad a otra.
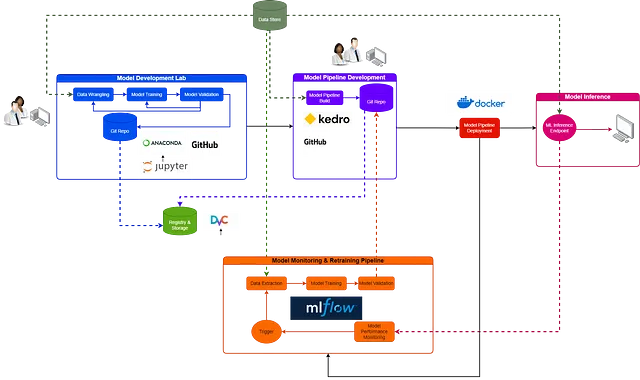
Laboratorio de desarrollo de modelos
El proceso de desarrollo de modelos es inherentemente impredecible e iterativo. Las empresas que no reconocen esto tendrán dificultades para construir estrategias de inteligencia artificial efectivas. En realidad, el desarrollo de modelos tiende a ser el aspecto más caótico del flujo de trabajo, lleno de experimentación, repetición y fallas frecuentes. Todos estos elementos son esenciales para explorar nuevas soluciones; es aquí donde nace la innovación. Entonces, ¿qué necesitan los científicos de datos? La libertad de experimentar, innovar y colaborar.
Existe una creencia generalizada de que los científicos de datos deben adherirse a las mejores prácticas de ingeniería de software en la escritura de su código. Si bien no estoy en desacuerdo con este sentimiento, hay un momento y un lugar para todo. No creo que los laboratorios de desarrollo de modelos sean necesariamente la arena para esto. En lugar de intentar calmar este caos, debemos abrazarlo como una parte necesaria del flujo de trabajo y buscar utilizar herramientas que nos ayuden a gestionarlo: un laboratorio de desarrollo de modelos efectivo debería proporcionar esto. Examinemos algunos componentes potenciales.
Experimentación y prototipado – Jupyter Labs
Jupyter Labs ofrece un entorno de desarrollo integrado (IDE) versátil adecuado para la creación de modelos preliminares y pruebas de concepto. Proporciona acceso a notebooks, scripts e interfaces de línea de comandos, todas características que son a menudo conocidas por los científicos de datos.
Como herramienta de código abierto, Jupyter Labs cuenta con una integración perfecta con Python y R, abarcando la mayoría de las tareas contemporáneas de desarrollo de modelos de ciencia de datos. La mayoría de las cargas de trabajo de ciencia de datos se pueden realizar en el IDE del laboratorio.
Gestión de entornos – Anaconda
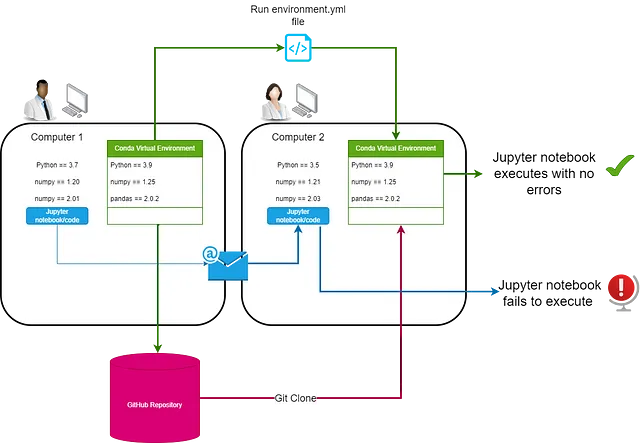
La gestión efectiva de entornos puede simplificar los pasos posteriores del flujo de trabajo de MLOps, centrándose en el acceso seguro a bibliotecas de código abierto y en la reproducción del entorno de desarrollo. Anaconda, un gestor de paquetes, permite a los científicos de datos crear entornos virtuales e instalar las bibliotecas y paquetes necesarios para el desarrollo de modelos con su sencilla interfaz de línea de comandos (CLI).
Anaconda también ofrece el reflejo de repositorios, que evalúa los paquetes de código abierto para su uso comercial seguro, aunque se deben considerar los riesgos asociados con la gestión de terceros. El uso de entornos virtuales es crucial para gestionar la fase experimental, proporcionando esencialmente un espacio contenido para todos los paquetes y dependencias de un experimento dado.
Control de versiones y colaboración – GitHub Desktop
La colaboración es una parte crucial de un laboratorio de desarrollo de modelos exitoso, y aprovechar GitHub Desktop es una forma efectiva de facilitar esto. Los científicos de datos, a través de GitHub Desktop, pueden crear un repositorio para cada laboratorio. Cada repositorio almacena el notebook o script de desarrollo del modelo, junto con un archivo environment.yml que indica a Anaconda cómo reproducir el entorno en el que se desarrolló el notebook en otra máquina.
La combinación de los tres componentes del laboratorio: Jupyter Labs, Anaconda y GitHub, proporciona a los científicos de datos un espacio seguro para experimentar, innovar y colaborar.
#Un ejemplo de archivo environment.yml que replica un entorno conda
name: myenv
channels:
- conda-forge
dependencies:
- python=3.9
- pandas
- scikit-learn
- seabornDesarrollo de la tubería de modelos
En mis discusiones con clientes que se encuentran en las primeras etapas de su madurez de MLOps, parece haber esta idea de que los científicos de datos desarrollan modelos y luego los “entregan” a ingenieros de aprendizaje automático para “ponerlos en producción”. Este enfoque no funciona y probablemente sea la forma más rápida de perder a tus ingenieros de aprendizaje automático. Nadie quiere lidiar con el código desordenado de otra persona, y francamente, es injusto esperar esto de tus ingenieros.
En cambio, las organizaciones deben fomentar una cultura en la que los científicos de datos sean responsables de desarrollar modelos dentro de los laboratorios de datos y luego formalizarlos como tuberías de modelos de extremo a extremo. Aquí está el por qué:
- Los científicos de datos comprenden mejor sus modelos que cualquier otra persona. Hacerlos responsables de crear la tubería del modelo mejorará la eficiencia.
- Se establece una cultura de las mejores prácticas de ingeniería de software en cada etapa del desarrollo.
- Los ingenieros de aprendizaje automático pueden centrarse en aspectos de su trabajo que agregan valor, como la aprovisionamiento de recursos, escalabilidad, automatización, en lugar de refactorizar el cuaderno de otra persona.
Construir tuberías de extremo a extremo puede parecer desalentador al principio, pero afortunadamente existen herramientas dirigidas a los científicos de datos para ayudarlos a lograr esto.
Construcción de Tuberías de Modelos – Kedro
Kedro es un marco de código abierto de Python de McKinsey Quantum Black para ayudar a los científicos de datos a construir tuberías de modelos.
# Plantilla estándar para proyectos Kedro{{ cookiecutter.repo_name }} # Directorio principal de la plantilla├── conf # Archivos de configuración del proyecto├── data # Datos locales del proyecto├── docs # Documentación del proyecto├── notebooks # Cuadernos relacionados con el proyecto├── README.md # README del proyecto├── setup.cfg # Opciones de configuración para herramientas └── src # Código fuente del proyecto └── {{ cookiecutter.python_package }} ├── __init.py__ ├── pipelines ├── pipeline_registry.py ├── __main__.py └── settings.py ├── requirements.txt ├── setup.py └── testsKedro proporciona una plantilla estándar para construir tuberías de modelos de extremo a extremo con las mejores prácticas de ingeniería de software. El concepto detrás de ello es fomentar que los científicos de datos construyan código modular, reproducible y mantenible. Una vez que un científico de datos completa el flujo de trabajo de Kedro, básicamente ha construido algo que se puede implementar más fácilmente en un entorno de producción. Aquí están los conceptos principales:
- Plantilla de Proyecto : Kedro proporciona una plantilla de proyecto estándar y fácil de usar, mejorando la estructura, la colaboración y la eficiencia.
- Catálogo de Datos : El Catálogo de Datos en Kedro es el registro de todas las fuentes de datos que el proyecto puede utilizar. Proporciona una forma sencilla de definir cómo y dónde se almacenan los datos.
Catálogo de ingeniería de datos definido por el proyecto Kedro tomado de https://docs.kedro.org/en/0.18.1/faq/faq.html
- Tuberías : Kedro estructura el procesamiento de tus datos como una tubería de tareas dependientes, imponiendo una estructura de código clara y visualizando el flujo y las dependencias de los datos.
- Nodos : En Kedro, un Node es un contenedor para una función de Python que nombra las entradas y salidas de esa función, sirviendo como los bloques de construcción de una tubería de Kedro.
- Configuración : Kedro gestiona diferentes configuraciones para varios entornos (desarrollo, producción, etc.) sin codificar ninguna configuración en tu código.
- Entrada y Salida : En Kedro, las operaciones de entrada y salida se abstraen del cálculo real, lo que aumenta la testabilidad y modularidad del código y facilita el cambio entre diferentes fuentes de datos.
- Modularidad y Reutilización : Kedro promueve un estilo de codificación modular que produce código reutilizable, mantenible y testeable.
- Pruebas : Kedro se integra con PyTest, un marco de pruebas en Python, lo que facilita escribir pruebas para tu tubería.
- Versionado : Kedro admite versionado para datos y código, permitiendo la reproducción de cualquier estado anterior de tu tubería.
- Registro de Eventos : Kedro ofrece un sistema de registro estandarizado para el seguimiento de eventos y cambios.
- Ganchos y complementos : Kedro admite ganchos y complementos, extendiendo las capacidades del marco según los requisitos del proyecto.
- Integración con otras herramientas : Kedro se puede integrar con varias herramientas como Jupyter Notebook, Dask, Apache Spark y otros para facilitar diferentes aspectos de un flujo de trabajo de ciencia de datos.
Todos los proyectos de Kedro siguen esta plantilla básica. La aplicación de este estándar en los equipos de ciencia de datos permitirá la reproducibilidad y la mantenibilidad de manera efectiva.
Para obtener una descripción más extensa del marco de trabajo de Kedro, visite los siguientes recursos:
- Documentación de Kedro: enlace
- La importancia del pensamiento en capas en la ingeniería de datos: enlace
Registro y almacenamiento — Control de versión de datos (DVC)
El registro y almacenamiento son fundamentales para la reproducibilidad en el aprendizaje automático, algo que cualquier empresa que busque incorporar el aprendizaje automático debe tener en cuenta. Los modelos de aprendizaje automático están compuestos esencialmente por código, datos, artefactos de modelo y entorno, todos los cuales deben ser trazables para garantizar la reproducibilidad.
DVC es una herramienta que proporciona control de versiones y seguimiento para modelos y datos. Si bien GitHub podría ser una alternativa, está limitado en su capacidad para almacenar objetos grandes, lo que plantea problemas para conjuntos de datos o modelos extensos. DVC extiende esencialmente Git, ofreciendo las mismas capacidades de control de versiones mientras permite el almacenamiento de conjuntos de datos y modelos más grandes en un repositorio DVC, que puede ser local o en la nube.
En entornos comerciales, existen beneficios de seguridad obvios al versionar su código en un repositorio Git, mientras se almacenan los artefactos de modelo y los datos en un entorno controlado.
Recuerde, la reproducibilidad del modelo será cada vez más importante a medida que se endurezcan las regulaciones en torno al uso de la inteligencia artificial comercialmente. La reproducibilidad facilita la auditabilidad.
Implementación de la canalización de modelos — Docker
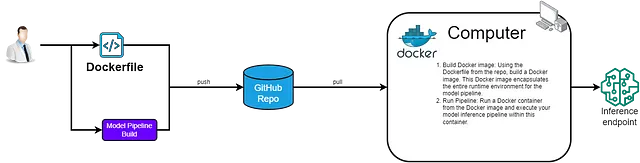
La implementación no es simplemente una tarea única, sino más bien una fusión meticulosamente elaborada de herramientas, actividades y procesos; Docker une todo esto para la implementación del modelo. Es crucial para aplicaciones de aprendizaje automático intrincadas con numerosas dependencias, que Docker asegura la consistencia en cualquier máquina encapsulando la aplicación con su entorno.
El proceso comienza con un archivo Dockerfile; Docker luego usa sus comandos para construir una imagen, una canalización de modelo envasada y lista para cualquier máquina habilitada para Docker. En colaboración con la funcionalidad de canalización de Kedro, Docker puede implementar de manera eficiente tanto la retrabajo como las canalizaciones de inferencia del modelo, garantizando la reproducibilidad en todas las etapas del flujo de trabajo de aprendizaje automático.
Monitoreo y retrabajo del modelo — MLflow
Con el tiempo, los modelos de aprendizaje automático sufren un deterioro del rendimiento, que puede ser debido al cambio de concepto o al cambio de datos. Queremos poder monitorear cuándo comienza a fallar el rendimiento de nuestros modelos y volver a entrenarlos cuando sea necesario. MLflow nos proporciona la capacidad de hacer esto a través de su API de seguimiento. La API de seguimiento debe incorporarse en la formación de modelos y las canalizaciones de inferencia construidas por los científicos de datos. Aunque he especificado MLflow para el seguimiento en la canalización de monitoreo y retrabajo del modelo, el seguimiento también se puede hacer en el laboratorio de desarrollo del modelo, especialmente para el seguimiento de experimentos.
El punto final de inferencia
Dado que la canalización de inferencia se ha encapsulado en un archivo Dockerfile, podemos crear una imagen de Docker de la canalización en cualquier lugar para usarla como punto final de API para cualquier aplicación. Dependiendo del caso de uso, tendremos que decidir dónde implementar la imagen de Docker. Sin embargo, esto está más allá del alcance de este artículo.
Roles y responsabilidades
Asignar roles y responsabilidades distintos dentro de MLOps es fundamental para su éxito. La naturaleza multifacética de MLOps, que abarca disciplinas, requiere una clara demarcación de roles. Esto asegura que cada tarea se realice de manera eficiente. Además, fomenta la responsabilidad, facilitando una resolución más rápida de problemas. Por último, la delegación clara reduce la confusión y la superposición, lo que hace que el equipo sea más eficiente y ayuda a mantener un entorno de trabajo armonioso. Es como una máquina bien engrasada, con cada engranaje desempeñando su papel a la perfección.
Científicos de datos
- Rol: La función principal de los científicos de datos dentro de las estrategias de MLOps es concentrarse en el desarrollo del modelo. Esto incluye experimentos iniciales, prototipos y configuración de canalizaciones de modelado para modelos validados.
- Responsabilidades: Los científicos de datos garantizan que los modelos se adhieran a las mejores prácticas de aprendizaje automático y se alineen con los casos empresariales. Más allá de las tareas de laboratorio, interactúan con los interesados en el negocio para identificar soluciones impactantes. Se hacen responsables de los laboratorios de datos, un científico de datos líder debe establecer el ritmo operativo y las mejores prácticas para la configuración de los laboratorios.
Ingenieros de Aprendizaje Automático
- Rol: Los ingenieros de ML supervisan la infraestructura técnica de MLOps, exploran soluciones innovadoras, diseñan estrategias junto a científicos de datos y mejoran la eficiencia de los procesos.
- Responsabilidades: Aseguran la funcionalidad de la infraestructura técnica, supervisan el rendimiento de los componentes para controlar los costos y confirman que los modelos de producción cumplan con la demanda requerida a escala.
Profesionales de Gobernanza de Datos
- Rol: Los profesionales de gobernanza de datos mantienen políticas de seguridad y privacidad de datos, desempeñando un papel fundamental en la transferencia segura de datos dentro del marco de MLOps.
- Responsabilidades: Aunque la gobernanza de datos es responsabilidad de todos, estos profesionales crean políticas y garantizan el cumplimiento a través de controles y auditorías regulares. Se mantienen al día con las regulaciones y garantizan el cumplimiento de todos los consumidores de datos.
Conclusión
Navegar por el mundo de MLOps es una tarea que requiere una planificación deliberada, la combinación adecuada de tecnología y talento, y una cultura organizacional que respalde el cambio y el aprendizaje.
El viaje puede parecer complejo, pero al emplear un diseño bien pensado y al abordar MLOps como un proceso holístico e iterativo en lugar de un proyecto único, se puede obtener un valor inmenso de las estrategias de IA. Sin embargo, recuerda que no hay un enfoque único que se adapte a todas las situaciones. Es crucial adaptar tu estrategia a tus necesidades específicas y permanecer ágil ante circunstancias cambiantes.
Sígueme en LinkedIn
Suscríbete a Zepes para obtener más información de mi parte:
Únete a Zepes con mi enlace de referencia — John Adeojo
Comparto proyectos, experiencias y conocimientos de ciencia de datos para ayudarte en tu camino. Puedes registrarte en Zepes a través de…
johnadeojo.medium.com
Si estás interesado en integrar IA o ciencia de datos en tus operaciones comerciales, te invitamos a programar una consulta inicial gratuita con nosotros:
Reserva en línea | Soluciones Centradas en Datos
Descubre nuestra experiencia en ayudar a las empresas a alcanzar metas ambiciosas con una consulta gratuita. Nuestros científicos de datos y…
www.data-centric-solutions.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Boto3 vs AWS Wrangler Simplificando Operaciones en S3 con Python
- Samsung adopta la IA y los grandes datos, revoluciona el proceso de fabricación de chips.
- Modelo SARIMA para la predicción de tasas de cambio de divisas.
- Consejos de Matplotlib para mejorar instantáneamente tus visualizaciones de datos – Según Storytelling with Data
- Usando RAPIDS cuDF para aprovechar la GPU en la ingeniería de características.
- Desarrollar y probar reglas RLS en Power BI.
- Power BI vs Tableau Similitudes y Diferencias



