Cómo crear un sistema de clasificación Elo basado en datos para juegos 2v2
Crear un sistema Elo 2v2.
Poniendo la matemática sobre la mesa: de algoritmos a la locura del futbolín, la búsqueda del campeón de oficina definitivo.
¡Hola y bienvenido/a!
Me llamo Lazare y acabo de terminar mi segundo título de licenciatura en Análisis de Datos Empresariales. Este artículo se basa en el trabajo que hice para mi tesis de licenciatura.
Desde partidos amistosos hasta competiciones intensas, el futbolín ha encontrado su nicho en la cultura corporativa, proporcionando una forma única para que los equipos se conecten y compitan.
Este artículo explora las matemáticas detrás de un sistema de puntuación basado en Elo para partidos de 2 contra 2, que se puede aplicar al futbolín u cualquier otro juego de 2 contra 2. También examina la arquitectura que respalda el procesamiento de datos y presenta la creación de una aplicación web que proporciona clasificación en tiempo real y análisis de datos utilizando Python.
- Una introducción a los conceptos fundamentales que necesitas para comenzar a realizar pruebas estadísticas
- Investigadores de Microsoft presentan Hydra-RLHF Una solución eficiente en memoria para el aprendizaje por refuerzo con retroalimentación humana
- Investigadores del MIT proponen AskIt un lenguaje específico de dominio para agilizar la integración de modelos de lenguaje grandes en el desarrollo de software.
La Clasificación Elo
El sistema de puntuación Elo es un método utilizado para determinar el nivel de habilidad relativa de un jugador en juegos de suma cero. Fue desarrollado por primera vez para el ajedrez, pero ahora se está aplicando como sistema de clasificación en una variedad de otros deportes como béisbol, baloncesto, varios juegos de mesa y deportes electrónicos.
Un ejemplo bien conocido de este sistema es en el ajedrez, donde se utiliza el sistema de puntuación Elo para clasificar a los jugadores a nivel mundial. Magnus Carlsen, también conocido como el “Mozart del Ajedrez”, tiene la puntuación Elo más alta del mundo con una puntuación de 2,853 en 2023, demostrando sus habilidades extraordinarias en el juego.
La fórmula de puntuación Elo consta de dos partes: primero, calcula el resultado esperado para un grupo determinado de jugadores, y luego determina el ajuste de puntuación basado en el resultado del partido y el resultado esperado.
Cálculo del Resultado Esperado
Considera el siguiente ejemplo en el ajedrez con el Jugador A y el Jugador B con las puntuaciones R𝖠 y R𝖡 respectivamente. La ecuación para la puntuación esperada de Jugador A contra Jugador B es la siguiente:
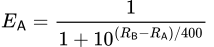
El algoritmo Elo utiliza una variable que se puede ajustar para controlar cómo la probabilidad de ganar es influenciada por las puntuaciones de los jugadores. En este ejemplo, se establece en 400, que es típico para la mayoría de los deportes, incluido el ajedrez.
Ahora veamos un ejemplo más realista, donde el jugador A tiene una puntuación de 1,500 y el Jugador B, 1,200.
La misma ecuación vista anteriormente puede calcular la puntuación esperada de Jugador A contra Jugador B:
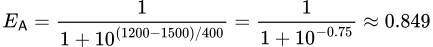
Con este cálculo, sabemos que Jugador A tiene un 84.9% de probabilidad de ganar contra Jugador B.
Para encontrar la probabilidad estimada de que Jugador B gane contra Jugador A, se utiliza la misma fórmula, pero se invierte el orden de las puntuaciones:
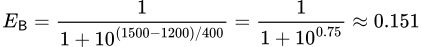
La suma de las probabilidades de que Jugador A gane y Jugador B gane es igual a 1 (0.849 + 0.151 = 1). En este escenario, Jugador A tiene un 84.9% de probabilidad de ganar, dejando a Jugador B con solo un 15.1% de probabilidad.
Cálculo de Puntuación
La diferencia de puntuación entre el ganador y el perdedor determina el número total de puntos ganados o perdidos después de cada partido.
- Si un jugador con una puntuación Elo mucho más alta gana, recibirá menos puntos por su victoria y su oponente perderá solo unos pocos puntos por su derrota.
- Por el contrario, si el jugador de menor clasificación gana, este logro se considera mucho más significativo, por lo tanto, la recompensa es mayor y el oponente de mayor clasificación es penalizado en consecuencia.
La fórmula para calcular la nueva puntuación del Jugador A jugando contra el Jugador B es la siguiente:
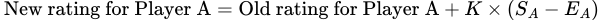
En esta fórmula, ( S𝖠 — E𝖠 ) representa la diferencia entre la puntuación real del Jugador A y la puntuación esperada. La variable adicional K determina aproximadamente cuánto puede cambiar la puntuación de un jugador después de un solo partido. En el ajedrez, esta variable se establece en 32.
Si el Jugador A gana, la puntuación real, que es 1 en este caso, será mayor que la puntuación esperada de 0.849, creando una variación positiva.
Esto indica que el Jugador A tuvo un mejor desempeño de lo esperado inicialmente. Como resultado, el sistema de clasificación Elo recalibra las puntuaciones para ambos jugadores:
- La puntuación del Jugador A aumentará debido a la victoria
- La puntuación del Jugador B disminuirá debido a la derrota
Una vez más, esta misma ecuación puede calcular la nueva puntuación del Jugador A y el Jugador B:
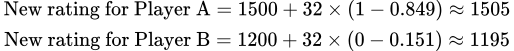
En resumen, el sistema de clasificación Elo ofrece un método sólido y eficiente para evaluar y comparar las habilidades de los jugadores de manera dinámica y justa. Actualiza continuamente la puntuación de un jugador después de cada partido, teniendo en cuenta la diferencia de habilidad entre los dos oponentes.
Este enfoque recompensa la toma de riesgos, ya que ganar contra un jugador con una puntuación más alta resulta en un aumento más significativo en la puntuación de un jugador, como se muestra en la tabla a continuación:
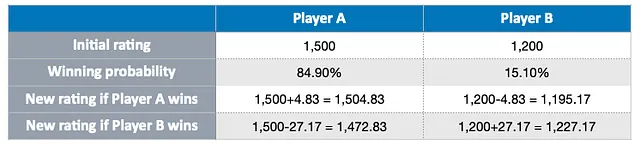
Por otro lado, si un jugador con una puntuación más alta va en contra de su probabilidad de ganar y pierde contra un jugador con una puntuación más baja, su puntuación se verá significativamente afectada: perderán más puntos y su oponente ganará más puntos.
En resumen, cuando un jugador gana un partido, cuanto menor sea su probabilidad de ganar, mayor será la cantidad de puntos que pueden ganar.
En su estado actual, esta fórmula de puntuación, originalmente diseñada para el ajedrez, no se adapta completamente al futbolín.
De hecho, el futbolín tiene más variables que el ajedrez, como:
- Es un juego de cuatro jugadores con equipos de dos (2v2)
- Cada miembro del equipo puede influir positiva o negativamente en su compañero
- A diferencia del resultado binario en el ajedrez, la escala de victoria o derrota en el futbolín puede variar considerablemente según las puntuaciones de los equipos
Exploración del Algoritmo de Puntuación
El enfoque aquí es adaptar el sistema de clasificación Elo a los requisitos únicos de los juegos de futbolín, que involucran a cuatro jugadores divididos en dos equipos.
Probabilidad de Ganar
Para comenzar a calcular las nuevas puntuaciones de los jugadores, es necesario establecer una fórmula refinada para determinar el resultado esperado de un juego que involucra a cuatro jugadores en dos equipos.
Para demostrar esto, consideremos un escenario hipotético de un juego de futbolín con cuatro jugadores: Jugador 1, Jugador 2, Jugador 3 y Jugador 4, cada uno con una puntuación diferente que representa su nivel de habilidad.

Para calcular la puntuación esperada del Equipo 1 contra el Equipo 2 en el sistema de clasificación Elo revisado, es necesario determinar la puntuación esperada de cada jugador involucrado en el juego.
La puntuación esperada del Jugador 1, denotada por E𝖯𝟣, se puede calcular promediando la suma de la puntuación de cada oponente utilizando la fórmula de clasificación Elo de la siguiente manera:
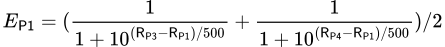
Después de extensas pruebas, se decidió que sería apropiado para la fórmula de puntuación esperada establecer la variable utilizada para dividir la diferencia de puntuación en 500, en lugar del valor tradicional de 400 utilizado en el ajedrez. Este valor aumentado significa que la puntuación de un jugador tendrá un impacto menor en su puntuación esperada.
Una razón principal para este ajuste es que, a diferencia del ajedrez, hay un ligero elemento de azar en el futbolín. Al utilizar un valor de 500, los resultados del juego pueden predecirse de manera más precisa y se puede desarrollar un sistema de puntuación confiable.
Para calcular la puntuación esperada del Jugador 2, denotada por E𝖯𝟤, contra el Jugador 3 y el Jugador 4, se puede utilizar el mismo método utilizado para el Jugador 1.
La puntuación esperada del Equipo, denotada por E𝖳𝟣, puede calcularse tomando el promedio de E𝖯𝟣 y E𝖯𝟤:

Una vez calculadas las puntuaciones esperadas para cada jugador, se pueden utilizar para calcular el resultado del partido. El equipo con la puntuación esperada más alta tiene más probabilidades de ganar. Al promediar las puntuaciones esperadas para cada miembro del equipo, ¡se puede resolver el problema de las diferencias de habilidad dentro del equipo!
La tabla a continuación muestra las puntuaciones esperadas del Jugador 1 y 2 contra los Jugadores 3 y 4.
- Las puntuaciones esperadas de P1 contra P3 y P4 son 0.091 y 0.201, lo que corresponde a una probabilidad de ganar del 14.6%
- Las puntuaciones esperadas de P2 contra P3 y P4 son 0.201 y 0.387, lo que da una probabilidad combinada de ganar del 29.4%
- Para P1, asociarse con un jugador más fuerte como P2 puede aumentar sus posibilidades generales de ganar, como se demuestra en el 22%
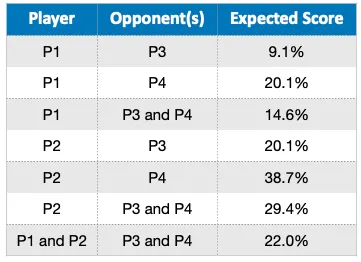
Si el equipo de P1 y P2 gana, P1 obtiene menos puntos de los que sugeriría su puntuación esperada individual, ya que P2, que tiene un rango más alto, también contribuye a la victoria y reduce su probabilidad general de ganar.
Por otro lado, P2 obtiene más puntos debido a tener un compañero de equipo de rango más bajo. En caso de victoria, se recompensa a P2 por correr un riesgo, mientras que P1 obtiene menos puntos, ya que se asume que P2 contribuyó de manera más significativa a la victoria, y viceversa si pierden.
Parámetros de puntuación
Ahora que se ha determinado el resultado esperado de un partido de cuatro jugadores, esta información se puede incorporar en una nueva fórmula que considere múltiples variables que afectan el partido y las puntuaciones de los jugadores.
Como se discutió anteriormente, el valor K puede modificarse para adaptarse mejor a las necesidades del sistema de puntuación. Esta nueva fórmula considera la cantidad de partidos jugados por cada jugador, reflejando su antigüedad, así como el resultado del partido.
Por ejemplo, en la semifinal de la Copa del Mundo de 2014, Alemania derrotó a Brasil con un marcador de 7-1. Este fue uno de los resultados más impactantes y humillantes en la historia de la Copa del Mundo, ya que Brasil era el país anfitrión y nunca había perdido un partido competitivo en casa desde 1975.
Si aplicáramos el sistema de puntuación a este partido, esperaríamos que Alemania ganara una cantidad significativa de puntos, mientras que Brasil perdería una gran cantidad de puntos, reflejando la diferencia en su rendimiento y nivel de habilidad.
Valor K El valor K, denotado como K𝟣 para el Jugador 1 en este caso, determina cuánto cambiará la puntuación de un jugador después de un partido. Este valor K revisado tiene en cuenta la cantidad de partidos que el jugador ha jugado para equilibrar el efecto de cada partido en su puntuación. Después de realizar numerosas pruebas, se desarrolló una fórmula para calcular el valor K para cada jugador.
Para el Jugador 1, esto se expresa como:
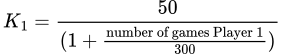
Esta fórmula para el valor K está diseñada para tener un mayor impacto en la calificación de los nuevos jugadores, al tiempo que proporciona estabilidad y menos fluctuación en la calificación para los jugadores experimentados. Específicamente, después de jugar 300 partidas, la calificación de un jugador se vuelve más representativa de su nivel de habilidad.
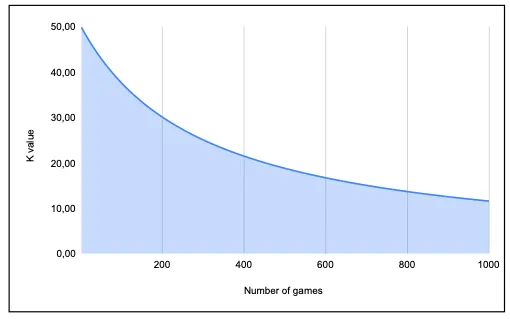
La Figura IV muestra el efecto del número de partidas jugadas en el valor K. Comenzando en 50, este gráfico muestra que el valor K disminuye a medida que aumenta el número de partidas jugadas, alcanzando un valor reducido a la mitad de 25 después de 300 partidas. Esto asegura que el impacto de cada partida en la calificación de un jugador disminuya a medida que aumenta la experiencia.
Factor de PuntosPara considerar los puntos anotados por cada equipo, se introdujo una nueva variable llamada “factor de puntos” en la ecuación. Este factor multiplica el parámetro K de cada jugador y se basa en la diferencia absoluta de puntos entre los dos equipos. El impacto de un partido debe ser mayor cuando un equipo gana por un margen amplio, es decir, una victoria abrumadora.
Para calcular el factor de puntos, se utilizó la siguiente fórmula:
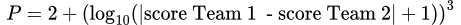
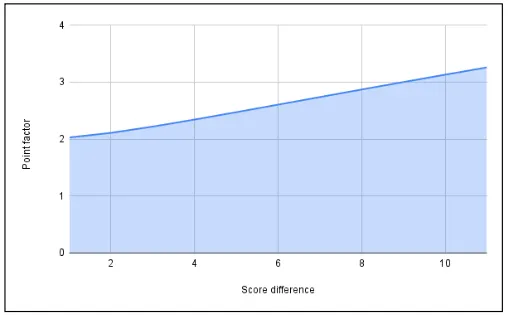
Esta fórmula toma la diferencia absoluta entre las puntuaciones de los dos equipos, le suma 1 y calcula el logaritmo en base 10 del resultado. Luego se eleva al cubo y se le suma 2 al resultado para obtener el valor final del factor de puntos.
Cálculo de la Calificación Final
Después de ajustar todas las variables necesarias, se desarrolló una fórmula mejorada para calcular la nueva clasificación de cada jugador involucrado en un juego.
Ahora la calificación de cada jugador tiene en cuenta su calificación anterior, la calificación de sus oponentes, el impacto de sus compañeros de equipo, su historial de juego y la puntuación del juego. Esta fórmula garantiza que cada jugador sea recompensado según su verdadero rendimiento, teniendo en cuenta la equidad de cada partido.
Basándonos en el ejemplo anterior, la nueva fórmula para la clasificación del jugador A es la siguiente:
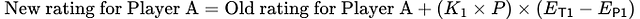
Esta fórmula mejorada recompensa a los jugadores en función de su rendimiento real, fomenta la toma de riesgos y proporciona un sistema de clasificación más equilibrado tanto para jugadores nuevos como experimentados.
Ahora que tenemos un algoritmo Elo, podemos pasar al modelado de bases de datos.
Diseño y Modelado de la Base de Datos
El modelo de base de datos propuesto adopta un enfoque relacional, organizando los datos en tablas interconectadas mediante el uso de Claves Primarias (PKs) y Claves Foráneas (FKs). Esta organización estructurada facilita la gestión y análisis de datos, por lo que PostgreSQL es una elección adecuada como sistema de gestión de bases de datos. Las PKs y FKs ayudan a mantener la consistencia de los datos y minimizar la redundancia dentro de la base de datos.
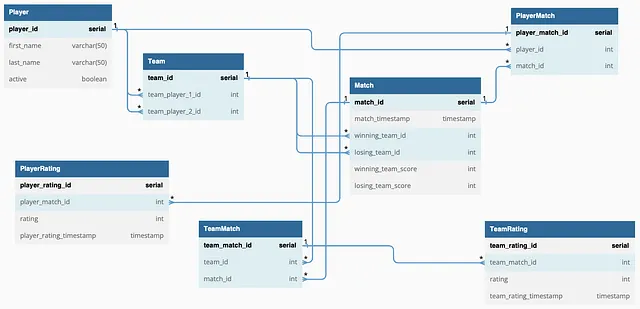
Existen dos tipos de relaciones entre tablas en este modelo de base de datos: uno a muchos y muchos a muchos.
La relación entre la tabla ‘Jugador’ y la tabla ‘Partido’ es de muchos a muchos, ya que un jugador puede participar en numerosos partidos y varios jugadores pueden estar involucrados en un solo partido. Una tabla de unión llamada ‘JugadorPartido’ establece esta relación, y contiene dos claves foráneas: ‘player_id’ (que hace referencia al jugador participante) y ‘match_id’ (que hace referencia al partido correspondiente).
Esta estructura asegura la asociación precisa de jugadores y partidos, como se muestra en el código a continuación:
CREATE TABLE PlayerMatch (player_match_id serial PRIMARY KEY,player_id INT NOT NULL REFERENCES Player(player_id),match_id INT NOT NULL REFERENCES Match(match_id));Una lógica similar se aplica a la tabla ‘TeamMatch’, que sirve como una conexión entre las tablas ‘Match’ y ‘Team’, permitiendo que varios equipos jueguen un partido y que un partido involucre a varios equipos.
Se han diseñado tablas separadas para ‘PlayerRating’ y ‘TeamRating’ para facilitar el análisis de clasificación a lo largo del tiempo. Estas tablas se conectan a las tablas ‘PlayerMatch’ y ‘TeamMatch’, respectivamente, a través de ‘player_match_id’ y ‘team_match_id’.
Integridad de los Datos
Además del uso de PKs y FKs, este modelo de base de datos también utiliza tipos de datos adecuados y restricciones de verificación para garantizar la integridad de los datos:
- Las columnas ‘winning_team_score’ y ‘losing_team_score’ en la tabla ‘Match’ son enteros, lo que impide la entrada de valores no numéricos
- Las restricciones de verificación aseguran que ‘winning_team_score’ sea exactamente 11
- Las restricciones de verificación aseguran que ‘losing_team_score’ esté entre 0 y 10, siguiendo las reglas del juego
Como se puede ver en el fragmento de código a continuación, se ha implementado el uso de secuencias para cada clave primaria en la creación de la base de datos para facilitar la entrada de datos. Esta automatización simplifica el procedimiento general al utilizar posteriormente el bucle de Python para el proceso de entrada de datos.
CREATE SEQUENCE player_id_seq START 1;CREATE SEQUENCE team_id_seq START 1;CREATE SEQUENCE match_id_seq START 1;CREATE SEQUENCE player_match_id_seq START 1;CREATE SEQUENCE player_rating_id_seq START 1;CREATE SEQUENCE team_match_id_seq START 1;CREATE SEQUENCE team_rating_id_seq START 1;Procesamiento de Datos
El desafío principal fue encontrar una manera de procesar los datos del partido en una secuencia que permitiera recuperar las IDs de los datos iniciales que se estaban procesando e insertando en la base de datos.
Estas IDs particulares podrían luego servir como claves externas para administrar los datos restantes, creando las relaciones necesarias en el proceso. En otras palabras, el primer paso fue identificar y almacenar datos específicos (IDs) de los datos sin procesar, y luego utilizar estas IDs como puente para vincular y procesar el resto de los datos.
Los datos se procesaron paso a paso, utilizando bucles de Python cada vez más complejos. Cada nueva entrada se le asignó una clave primaria única generada a partir de la secuencia de la tabla.
- El primer paso fue manejar a los jugadores individuales y obtener sus IDs.
- A continuación, se procesaron los equipos utilizando las IDs de los jugadores. Para cada par único de jugadores en un partido, se creó una entrada en la tabla ‘Team’ (FK jugadores)
- Después de esto, se manejaron los partidos utilizando las IDs de los equipos ganadores y perdedores. Después de procesar los partidos, se abordaron las tablas ‘PlayerMatch’ y ‘TeamMatch’ recuperando los IDs correspondientes de los jugadores, equipos y partidos respectivos
- Una vez que se habían procesado todos los datos necesarios, las IDs de ‘PlayerMatch’ y ‘TeamMatch’, junto con las marcas de tiempo de ‘match’, se utilizaron en las tablas ‘PlayerRating’ y ‘TeamRating’ para rastrear la evolución de las clasificaciones a lo largo del tiempo.
Desarrollo de la Aplicación Web
El objetivo de la aplicación web es permitir a los usuarios ingresar resultados de juegos, verificar datos e interactuar directamente con la base de datos. Esto asegura que los datos estén actualizados y se ofrezcan en tiempo real para que los usuarios siempre puedan acceder a las clasificaciones o visualizar sus métricas.
Además, quería que la aplicación web sea compatible con dispositivos móviles, porque ¿quién querría arrastrar una computadora portátil para jugar futbolín? Eso no sería muy práctico ni divertido.
Pila de Tecnología
BackendDespués de comparar Django y Flask, dos populares frameworks web para construir aplicaciones web en Python, se eligió Flask por su enfoque amigable para principiantes. El framework web Flask se utiliza para manejar las solicitudes de los usuarios, procesar datos e interactuar con la base de datos PostgreSQL.
FrontendEl frontend consiste en archivos HTML y CSS estáticos, que definen la estructura y el estilo de la aplicación web. JavaScript se utiliza para la validación de formularios y el manejo de interacciones del usuario. Esto asegura que los datos enviados por los usuarios sean consistentes y precisos antes de ser enviados al backend.
Visualización de DatosCuando se trata de visualización de datos, el mayor desafío es tener datos actualizados. Para superar esta limitación, la capa de visualización de datos utiliza Plotly, una biblioteca de Python, para generar gráficos interactivos que visualizan las calificaciones de los jugadores a lo largo del tiempo. Este componente recibe datos del backend, los procesa y los presenta a los usuarios en un formato fácil de usar.
Base de DatosSe utilizó PostgreSQL tanto en el entorno de desarrollo local como en el entorno de producción en AWS, a través de Heroku. Heroku facilita las copias de seguridad automáticas de la base de datos, lo que garantiza que los datos estén protegidos y se puedan restaurar fácilmente si es necesario.
Investigación de UI/UX
Para el diseño de UI/UX, se tomó inspiración de los diseños web modernos de Spotify y el nuevo motor de búsqueda de Bing. El objetivo era crear una experiencia de usuario familiar e intuitiva.
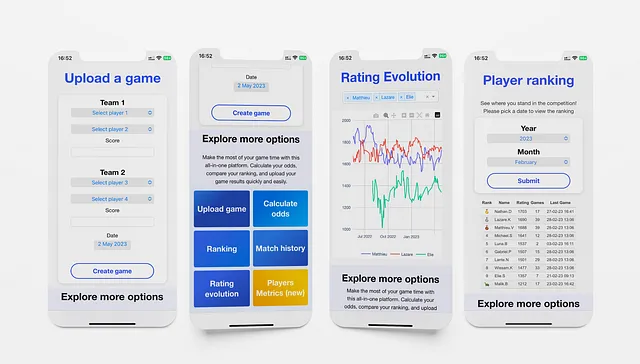
Funcionalidades de la Aplicación
Sumergámonos en las funcionalidades de la aplicación con un escenario concreto. El equipo 1 (Matthieu y Gabriel) quiere jugar contra el equipo 2 (Wissam y Malik). Todos los jugadores tienen una calificación diferente que representa su nivel de habilidad, que se muestra a continuación.

Calcular Probabilidades
Lo primero que los jugadores desean hacer antes de cualquier partido es calcular su probabilidad de ganar.
Para hacerlo, la vista “Calcular Probabilidades” permite a los usuarios seleccionar cuatro jugadores utilizando el menú desplegable y generar la probabilidad de ganar para los equipos seleccionados.
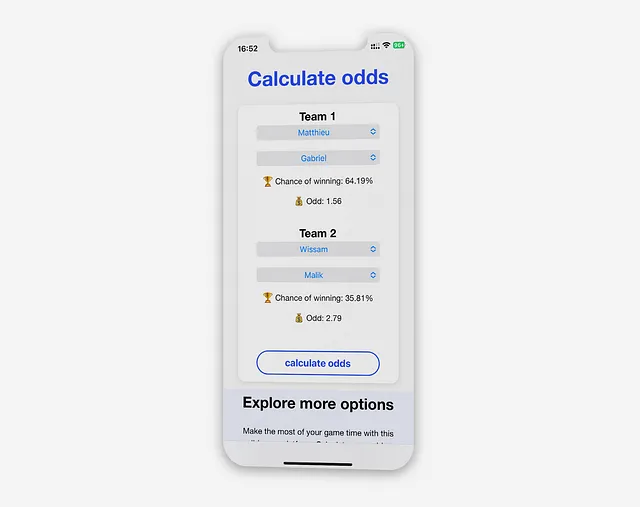
Esta funcionalidad se utiliza principalmente antes de un juego para verificar que el partido esté equilibrado e informar a los jugadores sobre su probabilidad de ganar. Por ejemplo, el equipo 1 tiene una mayor probabilidad de ganar (64.19%) que el equipo 2, que tiene una probabilidad de ganar del 35.81%. Esta vista informa a cada jugador sobre los riesgos y el riesgo asumido.
Una vez que se envía el formulario, la aplicación calcula solo la primera parte del algoritmo, que consiste en calcular el resultado esperado de un juego dado los cuatro jugadores seleccionados.
Cargar un Juego
La vista “Cargar un Juego” sirve como página de inicio de la aplicación. Está diseñada para la comodidad del usuario, permitiéndoles cargar un juego inmediatamente al abrir la aplicación.
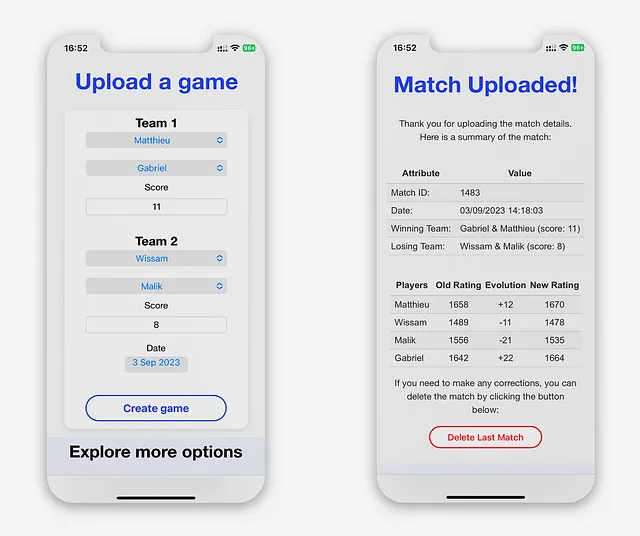
Antes de enviar el formulario, la aplicación realiza validación de datos utilizando JavaScript para asegurarse de que:
- Se seleccionen cuatro jugadores diferentes
- Las puntuaciones sean enteros no negativos
- Solo haya un equipo ganador con una puntuación exacta de 11, sin empates permitidos
Cuando la validación es exitosa, la aplicación procesa los datos utilizando el algoritmo completo, actualiza las tablas correspondientes en la base de datos y brinda a los usuarios una confirmación de su carga.
La vista “Partida cargada” está diseñada para mostrar a los usuarios el efecto de cada partida en sus puntuaciones individuales. Calcula la diferencia entre las puntuaciones de los jugadores antes y después de que se cargue la partida.
Como se muestra arriba, el juego no tiene el mismo efecto en la puntuación de cada jugador. Esto se debe a los parámetros individuales del algoritmo en cada jugador: su puntuación esperada, su número de partidas, su compañero de equipo y el equipo contrario.
Clasificación Elo
La vista “Clasificación de jugadores” permite a los usuarios acceder a la clasificación mensual en tiempo real y compararse con otros jugadores. Los usuarios pueden ver su puntuación, el número de partidas que jugaron durante el mes y la última partida que jugaron mostrando su última puntuación.
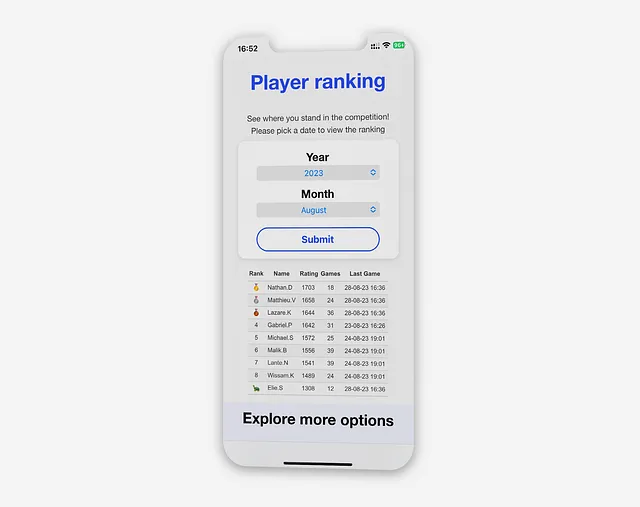
Una vez que se accede a la vista “Clasificación de jugadores” o se envía un nuevo período, la aplicación consulta la base de datos utilizando un enfoque de CTE.
Esto implica unir todas las tablas necesarias y mostrar la actualización de clasificación más reciente, utilizando el selector de período para filtrar la consulta:
def obtener_ultimas_puntuaciones_jugador(mes=None, año=None): ahora = datetime.now() mes_predeterminado = ahora.month año_predeterminado = ahora.year año_seleccionado = int(año) si año else año_predeterminado mes_seleccionado = int(mes) si mes else mes_predeterminado fecha_inicio = f'{año_seleccionado}-{mes_seleccionado:02d}-01 00:00:00' fecha_fin = f'{año_seleccionado}-{mes_seleccionado:02d}-{get_last_day_of_month(mes_seleccionado, año_seleccionado):02d} 23:59:59' consulta = ''' CON maxima_fecha_puntuacion_jugador AS ( SELECT pm.id_jugador, MAX(pr.fecha_puntuacion_jugador) as max_fecha FROM PartidaJugador pm JOIN PuntuacionJugador pr ON pm.id_partida_jugador = pr.id_partida_jugador WHERE pr.fecha_puntuacion_jugador BETWEEN %s AND %s GROUP BY pm.id_jugador ), partida_jugador_filtrada AS ( SELECT pm.id_jugador, pm.id_partida FROM PartidaJugador pm JOIN maxima_fecha_puntuacion_jugador mfpj ON pm.id_jugador = mfpj.id_jugador ), partidas_filtradas AS ( SELECT id_partida FROM Partida WHERE fecha_partida BETWEEN %s AND %s ) SELECT CONCAT(p.nombre, '.', SUBSTRING(p.apellido FROM 1 FOR 1)) as nombre_jugador, pr.puntuacion, COUNT(DISTINCT pjp.id_partida) as num_partidas, pr.fecha_puntuacion_jugador FROM Jugador p JOIN maxima_fecha_puntuacion_jugador mfpj ON p.id_jugador = mfpj.id_jugador JOIN PartidaJugador pj ON p.id_jugador = pj.id_jugador JOIN PuntuacionJugador pr ON pj.id_partida_jugador = pr.id_partida_jugador AND pr.fecha_puntuacion_jugador = mfpj.max_fecha JOIN partida_jugador_filtrada pjp ON p.id_jugador = pjp.id_jugador JOIN partidas_filtradas pf ON pjp.id_partida = pf.id_partida GROUP BY p.id_jugador, pr.puntuacion, pr.fecha_puntuacion_jugador ORDER BY pr.puntuacion DESC; '''Visualización de datos
El objetivo principal al desarrollar esta solución integral fue proporcionar a los usuarios un sistema de clasificación en tiempo real que sirva como representación visual del rendimiento de cada jugador.
Aunque existen herramientas poderosas como PowerBI y Qlik para la visualización de datos, se eligió una solución totalmente compatible con dispositivos móviles, lo que permite a los usuarios obtener información en tiempo real en sus dispositivos sin incurrir en tarifas de licencia.
Se utilizaron dos métodos para lograr esto:
- Primero, se utilizó Dash Plotly, un marco de Python que permite a los desarrolladores crear aplicaciones interactivas basadas en datos sobre aplicaciones Flask.
- Segundo, se emplearon varias consultas SQL y páginas HTML estáticas para extraer información de la base de datos y mostrarla, asegurando que los usuarios siempre tengan acceso a datos en tiempo real.
Evolución de la puntuación
Esta visualización permite a los jugadores observar el impacto de cada partida en su clasificación e identificar tendencias más amplias. Por ejemplo, pueden ver exactamente cuándo alguien los supera o ver el impacto de victorias o derrotas consecutivas.
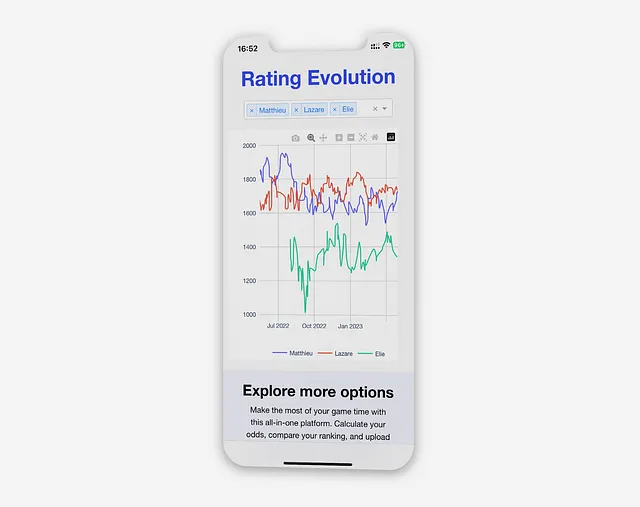
Cuando se accede a la vista “Evolución de clasificación”, la aplicación realiza una consulta en la base de datos para cada jugador seleccionado, recuperando la actualización de clasificación más reciente para cada día en el que se jugó una partida:
SELECT DISTINCT ON (DATE_TRUNC('day', m.match_timestamp)) DATE_TRUNC('day', m.match_timestamp) AS day_start, CASE WHEN p.first_name = '{player}' THEN pr.rating ELSE NULL END AS ratingFROM PlayerMatch pmJOIN Player p ON pm.player_id = p.player_idJOIN PlayerRating pr ON pm.player_match_id = pr.player_match_idJOIN Match m ON pm.match_id = m.match_idWHERE p.first_name = '{player}'ORDER BY DATE_TRUNC('day', m.match_timestamp) DESC, m.match_timestamp DESCA continuación, la tabla de datos recuperada se transforma en un gráfico de líneas, con las columnas convertidas en ejes utilizando Dash.
Para reducir la carga de la base de datos y simplificar la presentación de datos en el gráfico, solo se muestra la actualización de clasificación más reciente para cada día.
Métricas del jugador
Inspirado en Spotify Wrapped, la idea es proporcionar información derivada de la recopilación constante de datos. Si bien existe un inmenso potencial para visualizar información sobre los jugadores, el enfoque se centra en métricas que resalten el rendimiento individual y las conexiones entre los jugadores.
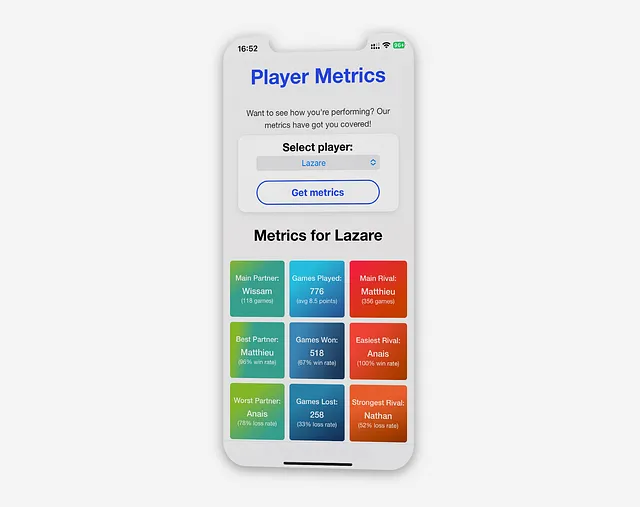
Estas métricas se organizan en tres categorías codificadas por colores: compañero, partidas y rivales, y cada métrica se acompaña de un título, un valor y una submedida para obtener más detalles.
Métricas de partidasEstas métricas se centran en la pantalla y se muestran en azul para mantener la neutralidad. Incluyen el número total de partidas jugadas desde el inicio de la recopilación de datos.
Métricas de compañeroLas métricas de compañero aparecen en el lado izquierdo de la pantalla. Se muestran en verde debido a su connotación positiva.
- El primer recuadro destaca al compañero principal con quien el jugador seleccionado ha jugado la mayoría de las partidas.
- La segunda métrica identifica al mejor compañero del jugador. Esto se define por el porcentaje más alto de victorias.
- La tercera métrica en esta categoría es el peor compañero del jugador seleccionado. Esto se calcula en función del porcentaje más bajo de victorias (o el porcentaje más alto de derrotas).
Métricas de rivalLas métricas de rival se muestran en rojo para indicar oposición. Las métricas de rival representan la relación competitiva entre los jugadores.
- El primer recuadro muestra al oponente más común, con una submétrica que indica el número de partidas jugadas juntos, similar a las métricas de compañero.
- La segunda métrica, “Rival más fácil”, representa al oponente contra quien el jugador tiene el mayor porcentaje de victorias. Esto indica un oponente más débil.
- La última métrica es el jugador contra quien el jugador seleccionado tiene el menor porcentaje de victorias. Esta métrica indica el oponente más difícil.
Conclusión
A medida que escribo esto, la aplicación lleva 6 meses en uso y estos son los resultados hasta ahora:
- Este sistema de clasificación basado en el sistema Elo predice los resultados de las partidas y clasifica con precisión a los jugadores según su rendimiento real.
- Los jugadores se han vuelto más competitivos, ya que ahora son cada vez más conscientes de su rendimiento debido a la visualización de datos.
- Los jugadores se han vuelto más inclusivos gracias a una fórmula mejorada que recompensa a los jugadores que asumen riesgos. Los jugadores que normalmente no jugarían juntos ahora tienen incentivos para formar pareja.
Al adoptar una estrategia basada en datos, este proyecto ha destacado la profunda influencia e importancia de los datos.
Yendo más allá del simple análisis del rendimiento de los jugadores, este proyecto ha iniciado una transformación en la forma en que los jugadores abordan los juegos de futbolín y cómo interactúan con otros jugadores, así como con los recién llegados. El poder de los datos ha cultivado verdaderamente un entorno más inclusivo y competitivo.
¡Gracias por leer hasta aquí! Espero que hayas encontrado útil este artículo. Si estás interesado en leer el artículo completo, está disponible aquí. Además, todo el código está disponible en Github.
No dudes en compartir tus pensamientos en los comentarios 🙂
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Khan Academy lanza Khanmigo, un tutor de aprendizaje de IA generativa
- Word Embeddings Dando contexto a tu ChatBot para obtener mejores respuestas
- Investigadores de Apple proponen un nuevo modelo de descomposición de tensores para el filtrado colaborativo con retroalimentación implícita
- Clasificación con el Perceptrón de Rosenblatt
- Temas por Clase Utilizando BERTopic
- Esta investigación de IA presenta Point-Bind un modelo de multimodalidad 3D que alinea nubes de puntos con imágenes 2D, lenguaje, audio y video
- Los programas piloto de IA buscan reducir el consumo de energía y las emisiones en el campus del MIT






