Creando animación para mostrar 4 algoritmos de agrupamiento basados en centroides usando Python y Sklearn
Creando animación de 4 algoritmos de agrupamiento basados en centroides con Python y Sklearn
Usando visualización de datos y animaciones para entender el proceso de 4 algoritmos de clustering basados en centroides.
Análisis de clustering
El análisis de clustering es una técnica efectiva de aprendizaje automático que agrupa datos según sus similitudes y diferencias. Los grupos de datos obtenidos pueden ser utilizados para diversos propósitos, como segmentación, estructuración y toma de decisiones.
Para realizar el análisis de clustering, existen muchos métodos basados en diferentes algoritmos. Este artículo se centrará principalmente en el clustering basado en centroides, que es una técnica común y útil.
Clustering basado en centroides
Básicamente, la técnica basada en centroides funciona calculando repetidamente para obtener centroides óptimos (centros de agrupación) y luego asignando puntos de datos a los más cercanos.
Debido a tener muchas iteraciones, la visualización de datos se puede utilizar para expresar lo que sucede durante el proceso. Por lo tanto, el propósito de este artículo es crear animaciones para mostrar el proceso basado en centroides con Python y Sklearn.
- Kris Nagel, CEO de Sift – Serie de Entrevistas
- Esta investigación de IA propone Strip-Cutmix un método de aumento de datos más adecuado para la reidentificación de personas
- El Proceso de IA
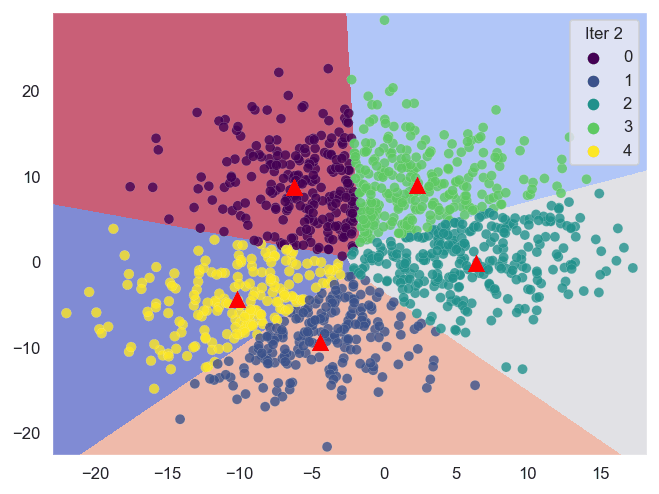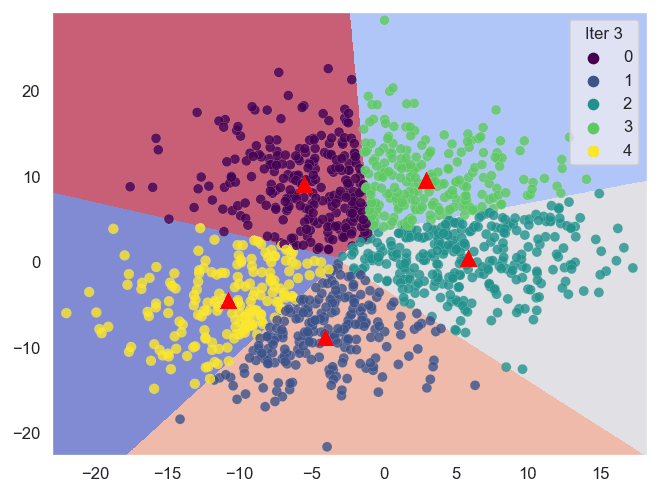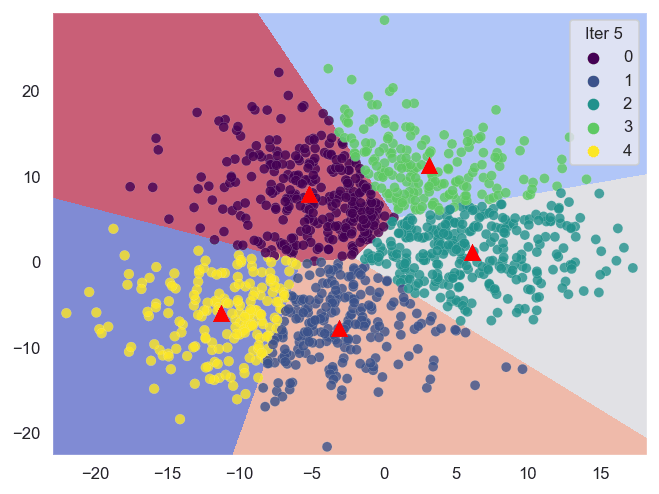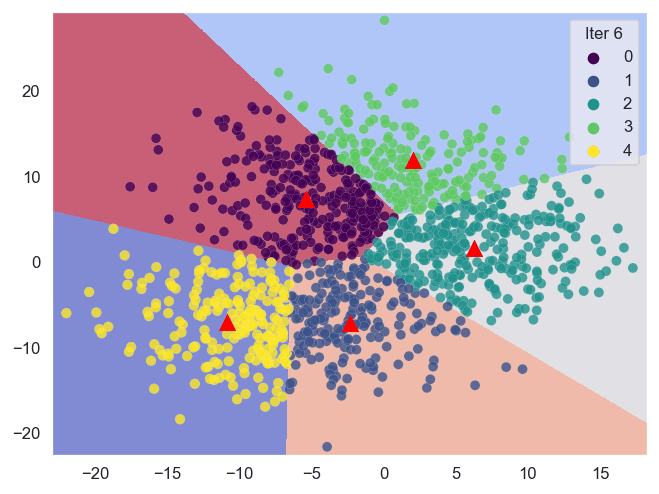
Sklearn (Scikit-learn) es una biblioteca poderosa que nos ayuda a realizar análisis de clustering de manera eficiente. A continuación, se presentan las técnicas de clustering basadas en centroides con las que trabajaremos.
- Clustering K-means
- Clustering K-means en mini lotes
- Clustering K-means bisectante
- Clustering Mean-Shift
Empecemos
Obteniendo los datos
Comienza importando las bibliotecas.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsComo ejemplo, este artículo utilizará un conjunto de datos generado, que se puede crear fácilmente utilizando make_blobs() de sklearn. Si tienes tu propio conjunto de datos, este paso se puede omitir.
from sklearn.datasets import make_blobsX, y…We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 5 Formas en las que puedes utilizar el intérprete de código de ChatGPT para Ciencia de Datos
- Por qué la API de OpenAI es más cara para los idiomas que no son inglés
- Desenmascarando Deepfakes Aprovechando los patrones de estimación de la posición de la cabeza para mejorar la precisión de detección
- Este boletín de inteligencia artificial es todo lo que necesitas #60
- Qué saber sobre StableCode el generador de código de IA de Stability AI
- Los modelos de IA son poderosos, pero ¿son biológicamente plausibles?
- Aprende mientras buscas (y navegas) utilizando la IA generativa





