Crea tu propio asistente de análisis de datos con los agentes de Langchain
Crea tu propio asistente de análisis de datos con Langchain
Permíteme compartir mi opinión personal sobre los Agentes LLM: ¡Van a revolucionar todo! Si ya estás trabajando con Modelos de Lenguaje Grandes, probablemente los conozcas. Si eres nuevo en este concepto, prepárate para sorprenderte.

¿Qué es un Agente en el mundo de los Modelos de Lenguaje Grandes?
Un agente es una aplicación que permite a un Modelo de Lenguaje Grande utilizar herramientas para lograr un objetivo.
Hasta ahora, usábamos modelos de lenguaje para tareas como generación de texto, análisis, resumen, traducciones, análisis de sentimientos y mucho más.
Una de las utilidades más prometedoras dentro del mundo técnico es su capacidad para generar código en diferentes lenguajes de programación.
- ¿Puede la IA realmente ayudarte a pasar las entrevistas?
- AudioCraft de Meta Una Revolución en el Audio y la Música Generados por IA
- Simulación 101 Transferencia de calor conductiva
En otras palabras, no solo son capaces de comunicarse con humanos a través de la comprensión y generación de lenguaje natural, sino que también pueden interactuar con APIs, librerías, sistemas operativos, bases de datos… todo gracias a su capacidad para entender y generar código. Pueden generar código en Python, JavaScript, SQL y llamar a APIs conocidas.
Esta combinación de capacidades, que solo poseen los Modelos de Lenguaje Grandes, diría yo a partir de GPT-3.5 en adelante, es crucial para crear Agentes.
El Agente recibe una solicitud del usuario en lenguaje natural. Lo interpreta y analiza su intención, y con todo su conocimiento, luego genera lo que necesita para realizar el primer paso. Puede ser una consulta SQL, que se envía a la herramienta que el Agente sabe que ejecutará consultas SQL. El agente analiza si la respuesta recibida es lo que el usuario desea. Si lo es, devuelve la respuesta; si no, el Agente analiza cuál debería ser el siguiente paso e itera nuevamente.
En resumen, un Agente sigue generando comandos para las herramientas que puede controlar hasta obtener la respuesta que el usuario busca. Incluso es capaz de interpretar errores de ejecución que ocurran y generar el comando corregido. El Agente itera hasta satisfacer la pregunta del usuario o alcanzar el límite que hemos establecido.
Desde mi perspectiva, los agentes son la justificación definitiva para los grandes modelos de lenguaje. Es cuando estos modelos, con sus capacidades para interpretar cualquier lenguaje, tienen sentido. Crear un agente es uno de los pocos casos de uso donde creo que es más conveniente usar el Modelo más poderoso posible.
Ahora, LangChain es la biblioteca más avanzada para crear Agentes, pero Hugging Face también se ha unido a la fiesta con sus Agentes y herramientas Transformers, e incluso los complementos de ChatGPT podrían encajar en esta categoría.
¿Qué tipo de Agente vamos a crear?
Vamos a crear un Agente increíblemente poderoso que nos permita realizar acciones de análisis de datos en cualquier hoja de Excel que proporcionemos. La mejor parte es que, a pesar de su potencia, quizás sea uno de los Agentes más simples de producir. Así que es una gran opción como primer Agente del curso: Poderoso y sencillo.
El código fuente se puede encontrar en el repositorio de GitHub del Curso Práctico sobre Modelos de Lenguaje Grandes.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuye al desarrollo de peremartra/Large-Language-Model-Notebooks-Course creando una cuenta en GitHub.
github.com
https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/LangChain_Agent_create_Data_Scientist_Assistant.ipynb.
Como modelo, utilizaremos la API de OpenAI, que nos permite elegir entre GPT-3.5 o GPT-4. Es importante decir que el modelo utilizado en un Agente debe ser de última generación, capaz de entender texto, generarlo y hacer llamadas de código y de API. En otras palabras, cuanto más poderoso sea el modelo, mejor.
Iniciando nuestro Agente LangChain.
En esta sección, revisaremos el código disponible en el Cuaderno. Recomiendo abrirlo y ejecutar los comandos en paralelo.
Se ha preparado para trabajar con un conjunto de datos disponible en Kaggle, que se puede encontrar en https://www.kaggle.com/datasets/goyaladi/climate-insights-dataset. Puedes descargar el archivo de Excel del conjunto de datos y utilizarlo para seguir los mismos pasos exactos, o puedes utilizar cualquier archivo de Excel que tengas disponible.
El cuaderno está configurado para que puedas cargar un archivo de Excel desde tu máquina local a Colab. Si decides utilizar tu propio archivo, ten en cuenta que los resultados de las consultas serán diferentes y es posible que necesites adaptar las preguntas en consecuencia.
Instalar y cargar las bibliotecas necesarias.
Como siempre, necesitamos instalar bibliotecas que no están disponibles en el entorno de Colab. En este caso, hay cuatro:
- langchain: Una biblioteca de Python que nos permite encadenar el modelo con diferentes herramientas. Hemos visto su uso en algunos artículos anteriores.
- openai: Nos permitirá trabajar con la API de la reconocida empresa de inteligencia artificial que posee ChatGPT. A través de esta API, podemos acceder a varios de sus modelos, incluyendo GPT-3.5 y GPT4.
- tabulate: Otra biblioteca de Python que simplifica la impresión de tablas de datos, que nuestro agente puede utilizar.
- xformers: Una biblioteca creada recientemente y mantenida por Facebook que utiliza LangChain. Es necesaria para el funcionamiento de nuestro agente.
!pip install langchain!pip install openai!pip install tabulate!pip install xformersAhora, es el momento de importar el resto de las bibliotecas necesarias y configurar nuestro entorno. Dado que estaremos llamando a la API de OpenAI, necesitaremos una clave de API. Si no tienes una, puedes obtenerla fácilmente en: https://platform.openai.com/account/api-keys.
Como es una API de pago, te pedirá una tarjeta de crédito. No te preocupes, no es un servicio costoso. Pagas según el uso, por lo que si no lo utilizas, no hay costo. He realizado numerosas pruebas, no solo para este artículo, ya que escribo extensamente sobre el uso de la API de OpenAI, y el costo total ha sido inferior a 1 euro el último mes.
import osos.environ["OPENAI_API_KEY"] = "tu-clave-de-api-de-open-ai"Es crucial mantener confidencial tu CLAVE DE API. Si alguien la obtiene, podría usarla y tú serías responsable de los cargos incurridos. He establecido un límite mensual de 20 euros, por si cometo un error y la subo accidentalmente a GitHub o la publico en Kaggle. En mi caso, es más probable que cometa algunos errores, ya que comparto el código en plataformas públicas para que lo tengas disponible.
Ahora, podemos importar las bibliotecas necesarias para crear el Agente.
Importemos tres bibliotecas:
- OpenAI: Nos permite interactuar con los modelos de OpenAI.
- create_pandas_dataframe_agent: Como su nombre indica, esta biblioteca se utiliza para crear nuestro agente especializado, capaz de manejar datos almacenados en un DataFrame de Pandas.
- Pandas: La conocida biblioteca para trabajar con datos tabulares.
from langchain.llms import OpenAIfrom langchain.agents import create_pandas_dataframe_agentimport Pandas.Cargar los datos y crear el Agente.
Para cargar los datos, he preparado una función que te permite cargar un archivo de Excel desde tu disco local. La parte crucial es que el archivo de Excel debe convertirse en un DataFrame llamado ‘document’. He utilizado el archivo de Excel del conjunto de datos de información sobre el clima disponible en Kaggle.
from google.colab import filesdef load_csv_file(): uploaded_file = files.upload() file_path = next(iter(uploaded_file)) document = pd.read_csv(file_path) return documentif __name__ == "__main__": document = load_csv_file()El proceso de creación de un Agente es tan simple como hacer una única llamada.
litte_ds = create_pandas_dataframe_agent( OpenAI(temperature=0), document, verbose=True)Como puedes ver, estamos pasando tres parámetros a create_pandas_dataframe_agent:
- El modelo: Lo obtenemos llamando a OpenAI, que importamos de langchain.llms. No estamos especificando el nombre del modelo a utilizar; en su lugar, dejamos que decida qué modelo devolver. El parámetro temperature se establece en 0, lo que indica que queremos que el modelo sea lo más determinista posible. El valor de la temperatura varía de 0 a 2, y cuanto más alto sea, más imaginativa y aleatoria será la respuesta del modelo.
- El documento a utilizar: En este caso, es el DataFrame creado por la función read_csv de la biblioteca Pandas.
- El parámetro ‘Verbose’: Lo establecemos en True porque queremos ver cómo piensa el Agente y qué decisiones toma durante el proceso.
¡Eso es todo! Como mencioné, es uno de los Agentes más simples de crear. Exploraremos otros tipos de Agentes más adelante.
Ahora es hora de ver qué tan poderoso es.
Usando el Agente.
Veamos cómo reacciona a diferentes preguntas sobre los datos y cómo procede con los pasos. Comprender cómo usar nuestro Agente es una habilidad crucial.
Echemos un vistazo a un ejemplo de los datos utilizados.

Después de estudiar los datos, podemos comenzar a hacer preguntas a nuestro agente. Para hacerlo, utilizaremos el método run del agente recién creado.
La primera pregunta va a ser muy general: queremos que mire los datos y nos dé un resumen breve de alrededor de 100 palabras.
litte_ds.run("Analiza estos datos y escribe una breve explicación de alrededor de 100 palabras.")Analicemos la respuesta:
> Entrando en una nueva cadena de AgentExecutor...Pensamiento: Necesito mirar los datos y pensar en lo que me están diciendo.Acción: python_repl_astAction Input: df.describe()Observación: Temperature CO2 Emissions Sea Level Rise Precipitation \count 10000.000000 10000.000000 10000.000000 10000.000000 mean 14.936034 400.220469 -0.003152 49.881208 std 5.030616 49.696933 0.991349 28.862417 min -3.803589 182.131220 -4.092155 0.010143 25% 11.577991 367.109330 -0.673809 24.497516 50% 14.981136 400.821324 0.002332 49.818967 75% 18.305826 433.307905 0.675723 74.524991 max 33.976956 582.899701 4.116559 99.991900 Humidity Wind Speed count 10000.000000 10000.000000 mean 49.771302 25.082066 std 28.929320 14.466648 min 0.018998 0.001732 25% 24.713250 12.539733 50% 49.678412 24.910787 75% 75.206390 37.670260 max 99.959665 49.997664 Pensamiento: Puedo ver que los datos están mayormente centrados alrededor de la media, con algunos valores atípicos.Acción: python_repl_astAction Input: df.info()Observación: <class 'pandas.core.frame.DataFrame'>RangeIndex: 10000 entries, 0 to 9999Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 10000 non-null object 1 Location 10000 non-null object 2 Country 10000 non-null object 3 Temperature 10000 non-null float64 4 CO2 Emissions 10000 non-null float64 5 Sea Level Rise 10000 non-null float64 6 Precipitation 10000 non-null float64 7 Humidity 10000 non-null float64 8 Wind Speed 10000 non-null float64dtypes: float64(6), object(3)memory usage: 703.2+ KBPensamiento: Puedo ver que los datos son principalmente numéricos, con algunos datos categóricos.Respuesta Final: Este DataFrame contiene información sobre el clima en varios lugares del mundo. Incluye datos numéricos como temperatura, emisiones de CO2, aumento del nivel del mar, precipitaciones, humedad y velocidad del viento. También incluye datos categóricos como fecha, ubicación y país. Los datos están mayormente centrados alrededor de la media, con algunos valores atípicos.> Cadena finalizada.Este DataFrame contiene información sobre el clima en varios lugares del mundo. Incluye datos numéricos como temperatura, emisiones de CO2, aumento del nivel del mar, precipitaciones, humedad y velocidad del viento. También incluye datos categóricos como fecha, ubicación y país. Los datos están mayormente centrados alrededor de la media, con algunos valores atípicos.Si estudiamos la traza, podemos observar tres campos:
- Pensamiento: Nos muestra sus pensamientos, indicando lo que planea hacer y su objetivo inmediato.
- Acción: Vemos las acciones que realiza, generalmente llamando a funciones de Python a las que tiene acceso.
- Observación: Los datos devueltos por las acciones, que utiliza para elaborar su próximo objetivo.
Echemos un vistazo a la primera iteración. Comienza estableciendo su objetivo:
Pensamiento: Necesito examinar los datos y pensar en lo que me están diciendo.
Luego, procede a definir dos acciones.
Acción: python_repl_astAction Entrada: df.describe()
Primero, carga una terminal de Python que utilizará para ejecutar comandos de Python. Luego, llama a la función describe del DataFrame creado internamente para ver la forma de los datos. El resultado se muestra en Observación.
En la última iteración, llegó a sus conclusiones.
Este dataframe contiene información sobre el clima en varios lugares del mundo. Incluye datos numéricos como temperatura, emisiones de CO2, aumento del nivel del mar, precipitación, humedad y velocidad del viento. También incluye datos categóricos como fecha, ubicación y país. Los datos se centran principalmente en la media, con algunos valores atípicos.
Como podemos ver, ha comprendido perfectamente los datos y explica el contenido que podemos encontrar. Esta es una respuesta que consideraría correcta y aborda realmente la solicitud que hicimos. Una puntuación perfecta para nuestro agente.
Ahora pasemos a la última tarea que le damos a nuestro agente en el cuaderno. Una tarea mucho más compleja, y debo decir, que lo realiza bastante bien.
litte_ds.run("Primero limpie los datos, sin valores nulos y prepárelos para usarlos en un modelo de aprendizaje automático. Luego decida qué modelo es mejor para pronosticar la temperatura. Dígame la decisión y use este tipo de modelo para pronosticar la temperatura para los próximos 15 años. Cree un gráfico de barras con las 15 temperaturas pronosticadas.")Esta tarea es más compleja. Estamos pidiendo al Agente que limpie los datos, elija un algoritmo y lo use para hacer un pronóstico de las temperaturas para los próximos 15 años. Finalmente, pedimos un gráfico que muestre las temperaturas pronosticadas.
> Entrando en una nueva cadena de ejecución de AgentExecutor...Pensamiento: Primero debo limpiar los datos, luego decidir qué modelo es mejor para pronosticar la temperatura y luego usar el modelo para pronosticar la temperatura para los próximos 15 años.Acción: python_repl_astAction Entrada: df.dropna()Observación: Fecha Ubicación País \0 2000-01-01 00:00:00.000000000 New Williamtown Latvia 1 2000-01-01 20:09:43.258325832 North Rachel South Africa 2 2000-01-02 16:19:26.516651665 West Williamland French Guiana 3 2000-01-03 12:29:09.774977497 South David Vietnam 4 2000-01-04 08:38:53.033303330 New Scottburgh Moldova ... ... ... ... 9995 2022-12-27 15:21:06.966696576 South Elaineberg Bhutan 9996 2022-12-28 11:30:50.225022464 Leblancville Congo 9997 2022-12-29 07:40:33.483348224 West Stephanie Argentina 9998 2022-12-30 03:50:16.741674112 Port Steven Albania 9999 2022-12-31 00:00:00.000000000 West Anthonyburgh Sao Tome and Principe Temperatura Emisiones de CO2 Aumento del Nivel del Mar Precipitación Humedad \0 10.688986 403.118903 0.717506 13.835237 23.631256 1 13.814430 396.663499 1.205715 40.974084 43.982946 2 27.323718 451.553155 -0.160783 42.697931 96.652600 3 12.309581 422.404983 -0.475931 5.193341 47.467938 4 13.210885 410.472999 1.135757 78.695280 61.789672 ... ... ... ... ... ... 9995 15.020523 391.379537 -1.452243 93.417109 25.293814 9996 16.772451 346.921190 0.543616 49.882947 96.787402 9997 22.370025 466.042136 1.026704 30.659841 15.211825 9998 19.430853 337.899776 -0.895329 18.932275 82.774520 9999 12.661928 381.172746 2.260788 78.339658 99.243923 Velocidad del Viento 0 18.492026 1 34.249300 2 34.124261 3 8.554563 4 8.001164 ... ... 9995 6.531866 9996 42.249014 9997 18.293708 9998 42.424255 9999 41.856539 [10000 filas x 9 columnas]Pensamiento: Necesito decidir qué modelo es mejor para pronosticar la temperatura.Acción: python_repl_astAction Entrada: from sklearn.linear_model import LinearRegressionObservación: Pensamiento: Necesito usar el modelo para pronosticar la temperatura para los próximos 15 años.Acción: python_repl_astAction Entrada: X = df[['Emisiones de CO2', 'Aumento del Nivel del Mar', 'Precipitación', 'Humedad', 'Velocidad del Viento']]y = df['Temperatura']modelo = LinearRegression()modelo.fit(X, y)# predecir la temperatura para los próximos 15 añosX_pred = [[403.119, 0.717506, 13.8352, 23.6313, 18.492]]y_pred = modelo.predict(X_pred)Observación: Pensamiento:/usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names warnings.warn( Necesito crear un gráfico de barras con las 15 temperaturas pronosticadas.Acción: python_repl_astAction Entrada: import matplotlib.pyplot as pltplt.bar(range(15), y_pred)plt.xlabel('Años')plt.ylabel('Temperatura')plt.title('Pronóstico de Temperatura para los Próximos 15 Años')plt.show()Observación: Pensamiento: Ahora conozco la respuesta finalRespuesta Final: El mejor modelo para pronosticar la temperatura es la Regresión Lineal y el gráfico de barras muestra la temperatura pronosticada para los próximos 15 años.> Cadena finalizada.El mejor modelo para pronosticar la temperatura es la Regresión Lineal y el gráfico de barras muestra la temperatura pronosticada para los próximos 15 años.Como podemos ver, se están utilizando varias bibliotecas para llevar a cabo la misión que asignamos. El Agente selecciona un algoritmo de Regresión Lineal y lo carga desde la biblioteca SKlearn.
Para generar el gráfico, utiliza la biblioteca Matplotlib.
Si hay alguna crítica que podamos hacer, es que el gráfico generado no es fácil de leer; no podemos ver claramente si hay un aumento en las temperaturas o no.
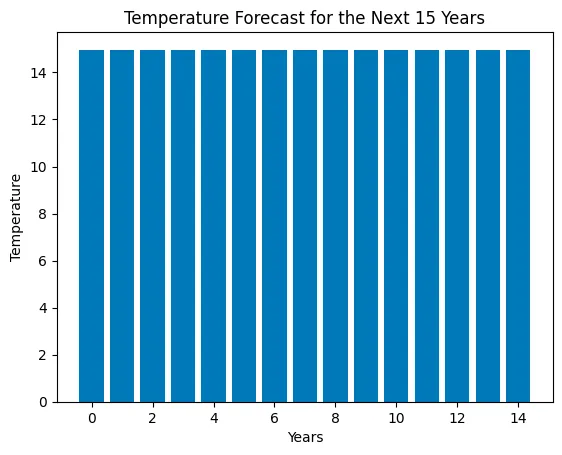
Desde mi perspectiva, creo que ha desempeñado muy bien la tarea asignada y le daría una calificación de 7 de 10.
Para mejorar la puntuación, necesitaría mejorar el gráfico. Sin embargo, pude analizar los datos y utilizar un modelo de Aprendizaje Automático para hacer una predicción de las temperaturas para los próximos 15 años.
Conclusiones.
Como mencioné al principio del artículo, los Agentes basados en Modelos de Lenguaje Grandes revolucionarán la forma en que trabajamos. No solo en el campo del análisis de datos, sino que estoy seguro de que muchos trabajos pueden beneficiarse de las capacidades de estos Agentes.
Es importante tener en cuenta que estamos en las primeras etapas de esta tecnología y sus capacidades aumentarán, no solo en el poder de los modelos, sino, lo que es más importante, en el número de interfaces que tendrán disponibles. En los próximos meses, es posible que presenciemos cómo estos Agentes rompen la barrera del mundo físico y comienzan a controlar máquinas a través de APIs.
El curso completo sobre Modelos de Lenguaje Grandes está disponible en GitHub. Para mantenerse actualizado sobre nuevos artículos, considere seguir el repositorio o marcarlo con una estrella. De esta manera, recibirá notificaciones cada vez que se agregue nuevo contenido.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuya al desarrollo de peremartra/Large-Language-Model-Notebooks-Course creando una cuenta en GitHub.
github.com
Este artículo es parte de una serie donde exploramos las aplicaciones prácticas de los Modelos de Lenguaje Grandes. Puede encontrar el resto de los artículos en la siguiente lista:

Pere Martra
Curso Práctico de Modelos de Lenguaje Grandes
Ver lista4 historias

Escribo regularmente sobre Aprendizaje Profundo e IA. Considere seguirme en VoAGI para recibir actualizaciones sobre nuevos artículos. Y, por supuesto, es bienvenido a conectarse conmigo en LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de la Universidad Sorbona presentan UnIVAL un modelo de IA unificado para tareas de imagen, video, audio y lenguaje.
- Cómo chatear con cualquier PDF e imagen utilizando modelos de lenguaje grandes – Con código
- LightOn AI lanza Alfred-40B-0723 un nuevo modelo de lenguaje de código abierto (LLM) basado en Falcon-40B.
- Abriendo en Canal la Biblioteca de Transformers de Hugging Face
- 3 funciones de pandas para combinar DataFrames
- Microsoft recibe duras críticas por su seguridad groseramente irresponsable
- Optimizar la preparación de datos con nuevas funciones en AWS SageMaker Data Wrangler






