Generación Controlable de Imágenes Médicas con ControlNets
Controllable Generation of Medical Images with ControlNets
Guía sobre el uso de ControlNets para controlar el proceso de generación de modelos de difusión latente
En esta publicación, presentaremos una guía sobre cómo entrenar un ControlNet para brindar a los usuarios un control preciso sobre el proceso de generación de un modelo de difusión latente (como Stable Diffusion!). Nuestro objetivo es mostrar las notables capacidades de estos modelos en la traducción de imágenes cerebrales en diferentes contrastes. Para lograr esto, aprovecharemos el poder de la extensión de código abierto para MONAI, MONAI Generative Models !

Nuestro código de proyecto está disponible en este repositorio público https://github.com/Warvito/generative_brain_controlnet
Introducción
En los últimos años, los modelos de difusión de texto a imagen han experimentado avances notables, lo que permite la generación de imágenes altamente realistas en función de descripciones de texto de dominio abierto. Estas imágenes generadas tienen detalles ricos, contornos bien definidos, estructuras coherentes y representación contextual significativa. Sin embargo, a pesar de los logros significativos de los modelos de difusión, sigue existiendo el desafío de lograr un control preciso sobre el proceso generativo. Incluso con descripciones de texto complejas y detalladas, capturar con precisión las ideas deseadas del usuario puede ser difícil.
La introducción de ControlNets, propuestos por Lvmin Zhang y Maneesh Agrawala en su innovador artículo “Agregando control condicional a los modelos de difusión de texto a imagen” (2023), ha mejorado significativamente la capacidad de control y personalización de los modelos de difusión. Estas redes neuronales actúan como adaptadores livianos, lo que permite un control preciso y una personalización mientras se preserva la capacidad de generación original de los modelos de difusión. Ajustando finamente estos adaptadores y manteniendo congelado el modelo de difusión original, los modelos de texto a imagen se pueden mejorar de manera eficiente para una amplia gama de aplicaciones de imagen a imagen.
- ¡Está vivo! Construye tus primeros robots con Python y algunos componentes baratos y básicos.
- AWS Inferentia2 se basa en AWS Inferentia1 ofreciendo un rendimiento 4 veces mayor y una latencia 10 veces menor.
- Generador de subtítulos de inteligencia artificial (para contenido de formato corto)
Lo que distingue a ControlNet es su solución al desafío de la consistencia espacial. En contraste con los métodos anteriores, ControlNet permite un control explícito sobre los aspectos espaciales, estructurales y geométricos de las estructuras generadas, al tiempo que conserva el control semántico derivado de las leyendas de texto. El estudio original introdujo varios modelos que permiten la generación condicional basada en bordes, pose, máscaras semánticas y mapas de profundidad, allanando el camino para avances emocionantes en el campo de la visión por computadora.
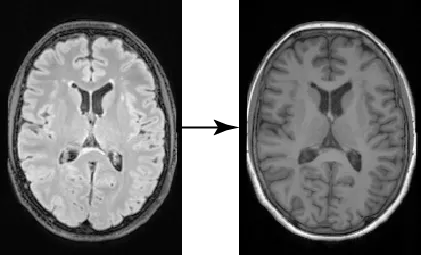
En el campo de la imagen médica, numerosas aplicaciones de imagen a imagen son de gran importancia. Entre estas aplicaciones, una tarea notable implica la traducción de imágenes entre diferentes dominios, como la conversión de imágenes de tomografía computarizada (TC) a imágenes de resonancia magnética (MRI) o la transformación de imágenes entre contrastes distintos, por ejemplo, de imágenes de resonancia magnética ponderadas en T1 a T2. En esta publicación, nos centraremos en un caso específico: utilizar cortes 2D de imágenes cerebrales obtenidas a partir de una imagen FLAIR para generar la imagen correspondiente ponderada en T1. Nuestro objetivo es demostrar cómo nuestra nueva extensión para MONAI (MONAI Generative Models) y ControlNets pueden utilizarse de manera efectiva para entrenar y evaluar modelos generativos en datos médicos. Al adentrarnos en este ejemplo, buscamos brindar información sobre la aplicación práctica de estas tecnologías en el dominio de la imagen médica.
Entrenamiento del modelo de difusión latente
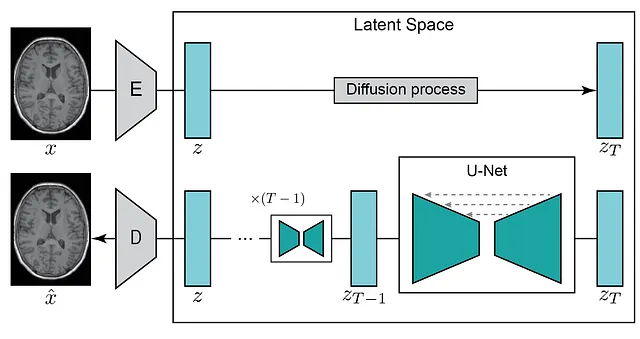
Para generar imágenes ponderadas en T1 (T1w) a partir de imágenes FLAIR, el primer paso es entrenar un modelo de difusión capaz de generar imágenes ponderadas en T1w. En nuestro ejemplo, utilizamos cortes 2D extraídos de imágenes de resonancia magnética cerebral obtenidas del conjunto de datos de UK Biobank (disponible bajo este acuerdo de datos). Después de registrar los cerebros originales en un espacio MNI utilizando su método favorito (por ejemplo, ANTs o UniRes), extraemos cinco cortes 2D de la parte central del cerebro. Elegimos esta región ya que presenta varios tejidos, lo que facilita la evaluación de la traducción de imágenes que estamos realizando. Utilizando este script, obtuvimos alrededor de 190,000 cortes con una dimensión espacial de 224 × 160 píxeles. A continuación, dividimos nuestra imagen en los conjuntos de entrenamiento (~180,000 cortes), validación (~5,000 cortes) y prueba (~5,000 cortes) utilizando este script. ¡Con nuestro conjunto de datos preparado, podemos comenzar a entrenar nuestro modelo de difusión latente!
Para optimizar los recursos computacionales, el modelo de difusión latente emplea un codificador para transformar la imagen de entrada x en un espacio latente de menor dimensión z, que luego puede ser reconstruido por un descodificador. Este enfoque permite entrenar modelos de difusión incluso con una capacidad computacional limitada, manteniendo al mismo tiempo su calidad y flexibilidad originales. Similar a lo que hicimos en nuestro post anterior (Generando imágenes médicas con MONAI), utilizamos el modelo de autoencoder con regularización KL de los modelos generativos de MONAI para crear nuestro modelo de compresión. Al utilizar esta configuración y la pérdida L1 junto con la regularización KL, la pérdida perceptual y la pérdida adversarial, hemos creado un autoencoder capaz de codificar y decodificar imágenes cerebrales con alta fidelidad (con este script). La calidad de la reconstrucción del autoencoder es crucial para el rendimiento del modelo de difusión latente, ya que define el límite de la calidad de nuestras imágenes generadas. Si el descodificador del autoencoder produce imágenes borrosas o de baja calidad, nuestro modelo generativo no podrá generar imágenes de mayor calidad.
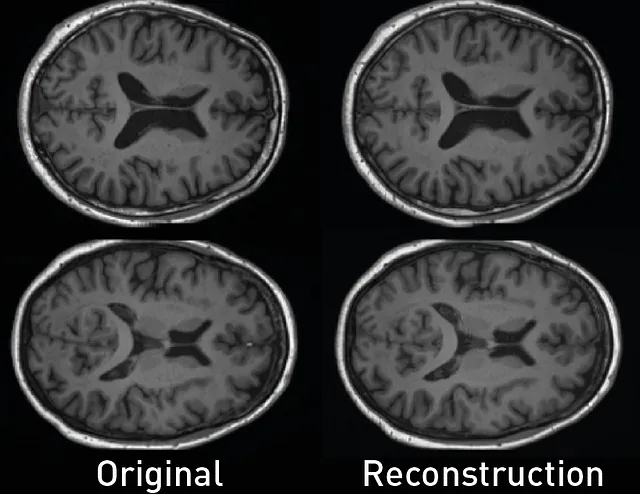
Utilizando este script, podemos cuantificar la fidelidad del autoencoder utilizando el Índice de Similitud Estructural Multiescala (MS-SSIM) entre las imágenes originales y sus reconstrucciones. En este ejemplo, obtenemos un alto rendimiento con una métrica MS-SSIM igual a 0,9876.
Después de entrenar el autoencoder, entrenaremos el modelo de difusión en el espacio latente z. El modelo de difusión es capaz de generar imágenes a partir de una imagen de ruido puro al desenfocarla iterativamente a lo largo de una serie de pasos de tiempo. Por lo general, utiliza una arquitectura U-Net (que tiene un formato de codificador-descodificador), donde tenemos capas del codificador conectadas a capas en la parte del descodificador (a través de conexiones de salto largas), lo que permite la reutilización de características y estabiliza el entrenamiento y la convergencia.
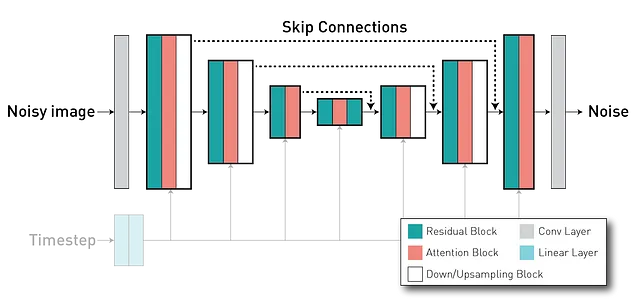
Durante el entrenamiento, el modelo de difusión latente aprende una predicción de ruido condicional dada estas indicaciones. De nuevo, estamos usando MONAI para crear y entrenar esta red. En este script, estamos instanciando el modelo con esta configuración, donde el entrenamiento y la evaluación se realizan en esta parte del código. Dado que no estamos muy interesados en las indicaciones textuales en este tutorial, estamos usando la misma para todas las imágenes (una frase que dice “Imagen ponderada en T1 de un cerebro.”).
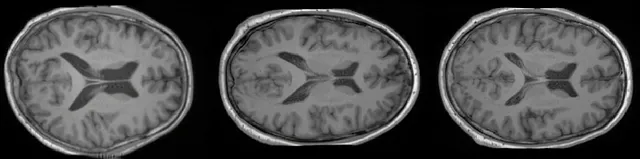
Nuevamente, podemos cuantificar el rendimiento de nuestro modelo generativo entrenado, esta vez evaluando la calidad de las muestras (utilizando la Distancia de Inception Fréchet (FID)) y la diversidad del modelo (calculando el MS-SSIM entre todas las parejas de muestras de un grupo de 1.000 muestras). Usando estos dos scripts (1 y 2), obtuvimos un FID = 2,1986 y una Diversidad MS-SSIM = 0,5368.
Como se puede observar en las imágenes y resultados anteriores, ahora tenemos un modelo capaz de generar imágenes de alta resolución con gran calidad. Sin embargo, no tenemos ningún control espacial sobre cómo se ven las imágenes. Para esto, usaremos un ControlNet para guiar la generación de nuestro modelo de difusión latente.
Entrenamiento del ControlNet
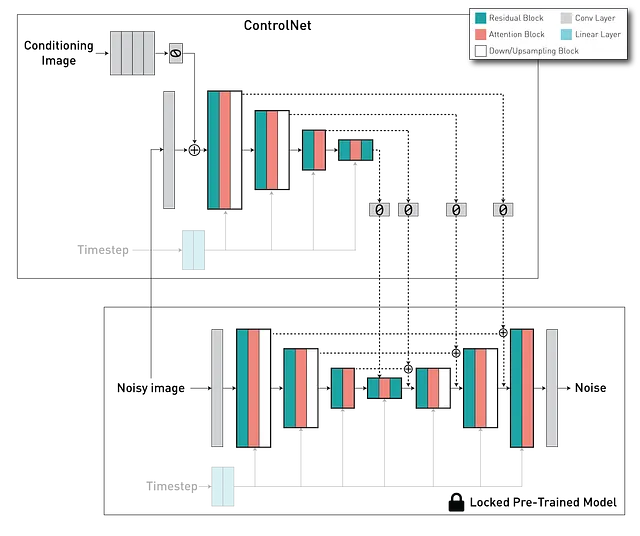
La arquitectura ControlNet consta de dos componentes principales: una versión entrenable del codificador del modelo U-Net, que incluye los bloques medios, y una versión “bloqueada” pre-entrenada del modelo de difusión. Aquí, la copia bloqueada conserva la capacidad generativa, mientras que la copia entrenable se entrena en conjuntos de datos específicos de imagen a imagen para aprender control condicional. Estos dos componentes están interconectados mediante una capa de “convolución cero”: una capa de convolución 1×1 con pesos y sesgos inicializados en cero. Los pesos de la convolución pasan gradualmente de cero a parámetros optimizados, asegurando que durante los primeros pasos del entrenamiento, las salidas tanto de las copias entrenables como bloqueadas sean consistentes con lo que serían si no hubiera ControlNet. En otras palabras, cuando se aplica un ControlNet a ciertos bloques de redes neuronales antes de cualquier optimización, no introduce ninguna influencia o ruido adicional a las características neuronales profundas.
Al integrar estos dos componentes, ControlNet nos permite controlar el comportamiento de cada nivel en el modelo U-Net del modelo de difusión.
En nuestro ejemplo, instanciamos ControlNet en este script, utilizando el siguiente fragmento equivalente:
import torchfrom generative.networks.nets import ControlNet, DiffusionModelUNet# Cargar modelo de difusión pre-entrenadodiffusion_model = DiffusionModelUNet( spatial_dims=2, in_channels=3, out_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768],)diffusion_model.load_state_dict(torch.load("diffusion_model.pt"))# Crear ControlNetcontrolnet = ControlNet( spatial_dims=2, in_channels=3, num_res_blocks=2, num_channels=[256, 512, 768], attention_levels=[False, True, True], with_conditioning=True, cross_attention_dim=1024, num_head_channels=[0, 512, 768], conditioning_embedding_in_channels=1, conditioning_embedding_num_channels=[64, 128, 128, 256],)# Crear copia entrenable del modelo de difusióncontrolnet.load_state_dict(diffusion_model.state_dict(), strict=False)# Bloquear peso del modelo de difusiónfor p in diffusion_model.parameters(): p.requires_grad = FalseDado que estamos utilizando un modelo de difusión latente, se requiere que los ControlNets conviertan las condiciones basadas en imágenes al mismo espacio latente para que coincidan con el tamaño de convolución. Para ello, utilizamos una red convolucional entrenada conjuntamente con el modelo completo. En nuestro caso, tenemos tres niveles de reducción de muestreo (similar al autoencoder KL) definidos en “conditioning_embedding_num_channels=[64, 128, 128, 256]”. Dado que nuestra imagen condicional es una imagen FLAIR con un solo canal, también necesitamos especificar su número de canales de entrada en “conditioning_embedding_in_channels=1”.
Después de inicializar nuestra red, la entrenamos de manera similar a un modelo de difusión. En el siguiente fragmento (y en esta parte del código), podemos ver que primero pasamos nuestra imagen FLAIR condicional a la red entrenable y obtenemos las salidas de sus conexiones saltadas. Luego, estos valores se introducen en el modelo de difusión al calcular el ruido predicho. Internamente, el modelo de difusión suma la conexión saltada de ControlNets con las suyas propias antes de alimentar la parte del decodificador (código).
# Ciclo de entrenamiento...images = batch["t1w"].to(device)cond = batch["flair"].to(device)...noise = torch.randn_like(latent_representation).to(device)noisy_z = scheduler.add_noise( original_samples=latent_representation, noise=noise, timesteps=timesteps)# Calcular parte entrenabledown_block_res_samples, mid_block_res_sample = controlnet( x=noisy_z, timesteps=timesteps, context=prompt_embeds, controlnet_cond=cond)# Usar salidas de ControlNet para controlar el comportamiento del modelo de difusiónnoise_pred = diffusion_model( x=noisy_z, timesteps=timesteps, context=prompt_embeds, down_block_additional_residuals=down_block_res_samples, mid_block_additional_residual=mid_block_res_sample,)# Luego, calcular la pérdida del modelo de difusión como de costumbre...Muestreo y evaluación de ControlNet
Después de entrenar nuestros modelos, podemos muestrearlos y evaluarlos. Aquí, utilizamos las imágenes FLAIR del conjunto de prueba para generar imágenes T1w condicionadas. Al igual que en nuestro entrenamiento, el proceso de muestreo es muy parecido al utilizado con el modelo de difusión, la única diferencia es que pasamos la imagen de la condición a ControlNet entrenado y usamos su salida para alimentar el modelo de difusión en cada paso de muestreo. Como podemos observar en la figura de abajo, nuestras imágenes generadas siguen con alta fidelidad espacial la condición original, con los giros corticales siguiendo formas similares y las imágenes preservando la frontera entre diferentes tejidos.
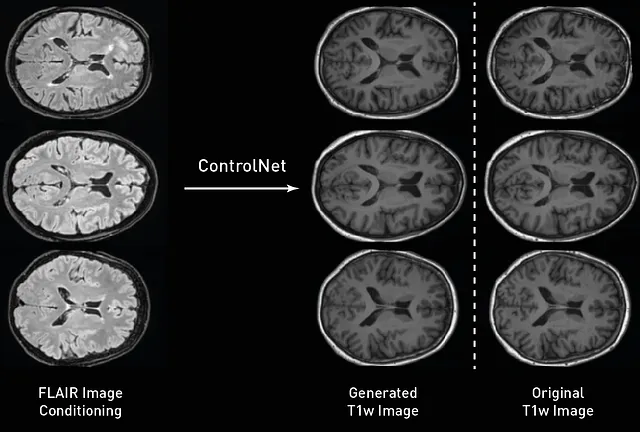
Después de muestrear las imágenes de nuestros modelos, podemos cuantificar el rendimiento de nuestro ControlNet al traducir las imágenes entre diferentes contrastes. Dado que tenemos las imágenes T1w esperadas del conjunto de prueba, también podemos verificar sus diferencias y calcular la distancia entre las imágenes reales y sintéticas utilizando el error absoluto medio (MAE) , el pico relación señal-ruido (PSNR) , y el MS-SSIM . En nuestro conjunto de prueba, obtuvimos un PSNR= 26.2458+-1.0092, MAE=0.02632+-0.0036 y MSSIM=0.9526+-0.0111 al ejecutar este script .
¡Y eso es todo! ControlNet ofrece un control increíble sobre nuestros modelos de difusión y enfoques recientes han extendido su método para combinar diferentes ControlNets entrenados ( Multi-ControlNet ), trabajar con diferentes tipos de acondicionamiento en el mismo modelo ( T2I adapters ), e incluso acondicionar el modelo en estilos (usando métodos como ControlNet 1.1 – solo referencia ). Si estos métodos le parecen interesantes, ¡no olvide seguirme para obtener más guías como esta! 😁
Para obtener más tutoriales de modelos generativos MONAI y aprender más sobre nuestras características, ¡visite nuestra página de tutoriales!
Nota: Todas las imágenes, a menos que se indique lo contrario, son del autor
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Los 5 Mejores Plugins de SEO de ChatGPT
- Herramienta gratuita de fotografía de productos de inteligencia artificial.
- Los efectos de ChatGPT en las escuelas y por qué está siendo prohibido.
- Explorando los Beneficios y Desventajas de Integrar ChatGPT en el Cuidado de la Salud
- Arte generado por IA las implicaciones éticas y los debates
- Crear un panel de análisis de ratios de series de tiempo.
- Aumento de personal de TI Cómo la IA está cambiando la industria del desarrollo de software.






