Monitoreo de datos no estructurados para LLM y NLP
Control de datos no estructurados para LLM y NLP
Un tutorial de código sobre el uso de descriptores de texto
Una vez que implementas una solución basada en NLP o LLM, necesitas una forma de controlarla. Pero, ¿cómo monitoreas datos no estructurados para entender el montón de textos?
Aquí hay algunos enfoques, desde detectar cambios en los datos de texto sin procesar y los cambios en los datos incrustados hasta usar expresiones regulares para realizar verificaciones basadas en reglas.
En este tutorial, exploraremos un enfoque particular: el seguimiento de descriptores de texto interpretativos que ayudan a asignar propiedades específicas a cada texto.
Primero, cubriremos algo de teoría:
- Aliasing Tu serie de tiempo te está mintiendo
- IA generativa y el futuro de la ingeniería de datos
- La IA también debería aprender a olvidar
- ¿Qué es un descriptor de texto y cuándo se deben usar?
- Ejemplos de descriptores de texto.
- Cómo seleccionar descriptores personalizados.
¡Luego, vamos al código! Trabajarás con datos de reseñas de comercio electrónico y seguirás los siguientes pasos:
- Obtener una visión general de los datos de texto.
- Evaluar los cambios en los datos de texto utilizando descriptores estándar.
- Agregar un descriptor de texto personalizado utilizando un modelo pre-entrenado externo.
- Implementar pruebas de pipeline para monitorear cambios en los datos.
Utilizaremos la biblioteca de código abierto en Python llamada Evidently para generar descriptores de texto y evaluar los cambios en los datos.
Ejemplo de código: Si prefieres ir directamente al código, aquí está el cuaderno de ejemplo.
¿Qué es un descriptor de texto?
Un descriptor de texto es cualquier característica o propiedad que describe objetos en el conjunto de datos de texto. Por ejemplo, la longitud de los textos o el número de símbolos en ellos.
Es posible que ya tengas metadatos útiles que acompañen tus textos y que sirvan como descriptores. Por ejemplo, las reseñas de usuarios de comercio electrónico pueden tener calificaciones asignadas por los usuarios o etiquetas de temas.
¡De lo contrario, puedes generar tus propios descriptores! Lo haces agregando “características virtuales” a tus datos de texto. Cada uno ayuda a describir o clasificar tus textos utilizando algún criterio significativo.
Al crear estos descriptores, básicamente estás creando tu propia “incrustación” simple y asignas varios dimensiones interpretables a cada texto. Esto ayuda a entender los datos, que de otra manera serían no estructurados.
Luego puedes utilizar estos descriptores de texto:
- Para monitorear modelos de NLP en producción. Puedes rastrear las propiedades de tus datos en el tiempo y detectar cuando cambian. Por ejemplo, los descriptores ayudan a detectar cambios en la longitud del texto o cambios en el sentimiento.
- Para probar modelos durante actualizaciones. Cuando iteras en modelos, puedes comparar las propiedades de los conjuntos de datos de evaluación y las respuestas del modelo. Por ejemplo, puedes comprobar que las longitudes de las respuestas generadas por LLM se mantengan similares y que siempre incluyan las palabras que esperas ver.
- Para solucionar problemas de cambios en los datos o decaimiento del modelo. Si detectas cambios en la incrustación o si observas directamente una disminución en la calidad del modelo, puedes utilizar descriptores de texto para explorar su origen.
Ejemplos de descriptores de texto
Aquí hay algunos descriptores de texto que consideramos buenos por defecto:
Longitud del texto
Un excelente punto de partida son las estadísticas de texto simples. Por ejemplo, puedes analizar la longitud de los textos medida en palabras, símbolos o frases. Puedes evaluar la longitud promedio y mínima-máxima, y observar las distribuciones.
Puedes establecer expectativas basadas en tu caso de uso. Por ejemplo, las reseñas de productos suelen tener entre 5 y 100 palabras. Si son más cortas o más largas, esto podría indicar un cambio de contexto. Si hay un aumento repentino en las reseñas de longitud fija, esto podría indicar un ataque de spam. Si sabes que las reseñas negativas suelen ser más largas, puedes rastrear la proporción de reseñas por encima de una cierta longitud.
También hay comprobaciones rápidas de cordura: si ejecutas un chatbot, es posible que esperes respuestas diferentes a cero o que haya una longitud mínima para la salida significativa.
Palabras fuera del vocabulario

Evaluar la cantidad de palabras fuera del vocabulario definido es una buena medida “rudimentaria” de la calidad de los datos. ¿Tus usuarios comenzaron a escribir reseñas en un nuevo idioma? ¿Los usuarios están hablando con tu chatbot en Python, no en inglés? ¿Los usuarios están llenando las respuestas con “ggg” en lugar de palabras reales?
Esta es una medida práctica única para detectar todo tipo de cambios. Una vez que detectes un cambio, puedes investigar más a fondo.
Puedes tener expectativas sobre el porcentaje de palabras fuera del vocabulario basado en ejemplos de datos de producción “buenos” acumulados a lo largo del tiempo. Por ejemplo, si observas el corpus de reseñas de productos anteriores, podrías esperar que el porcentaje de palabras fuera del vocabulario sea inferior al 10% y controlar si el valor supera este umbral.
Caracteres que no son letras
Relacionado, pero con un giro: este descriptor contará todo tipo de símbolos especiales que no sean letras o números, incluyendo comas, corchetes, hashtags, etc.
A veces, esperas una buena cantidad de símbolos especiales: tus textos podrían contener código o estar estructurados como un JSON. Otras veces, solo esperas signos de puntuación en texto legible por humanos.
Detectar un cambio en los caracteres que no son letras puede revelar problemas de calidad de datos, como códigos HTML que se filtran en los textos de las reseñas, ataques de spam, casos de uso inesperados, etc.
Sentimiento
El sentimiento del texto es otro indicador. Es útil en varios escenarios: desde conversaciones de chatbot hasta reseñas de usuarios y redacción de copias de marketing. Normalmente puedes establecer una expectativa sobre el sentimiento de los textos con los que trabajas.
Incluso si el sentimiento “no aplica”, esto podría traducirse en la expectativa de un tono principalmente neutral. La aparición potencial de un tono negativo o positivo merece ser rastreada e investigada. Podría indicar escenarios de uso inesperados: ¿está utilizando el asesor virtual de hipotecas como un canal de quejas el usuario?
También podrías esperar un cierto equilibrio: por ejemplo, siempre hay una parte de conversaciones o reseñas con un tono negativo, pero esperarías que no supere cierto umbral o que la distribución general del sentimiento de las reseñas se mantenga estable.
Palabras clave
También puedes verificar si los textos contienen palabras de una lista o listas específicas y tratar esto como una característica binaria.
Esta es una forma poderosa de codificar múltiples expectativas sobre tus textos. Necesitas cierto esfuerzo para curar las listas manualmente, pero puedes diseñar muchas comprobaciones útiles de esta manera. Por ejemplo, puedes crear listas de palabras clave como:
- Menciones de productos o marcas.
- Menciones de competidores.
- Menciones de ubicaciones, ciudades, lugares, etc.
- Menciones de palabras que representan temas particulares.
Puedes curar (y ampliar continuamente) listas como esta que sean específicas para tu caso de uso.
Por ejemplo, si un chatbot asesor ayuda a elegir entre productos ofrecidos por la empresa, podrías esperar que la mayoría de las respuestas contengan los nombres de uno de los productos de la lista.
Coincidencias de expresiones regulares
La inclusión de palabras específicas de la lista es un ejemplo de un patrón que puedes formular como una expresión regular. Puedes idear otros: ¿esperas que tus textos comiencen con “hola” y terminen con “gracias”? ¿Incluyen correos electrónicos? ¿Contienen elementos nombrados conocidos?
Si esperas que las entradas o salidas del modelo coincidan con un formato específico, puedes usar una coincidencia de expresiones regulares como otro descriptor.
Descriptores personalizados
Puedes ampliar esta idea aún más. Por ejemplo:
- Evaluar otras propiedades del texto: toxicidad, subjetividad, formalidad del tono, puntaje de legibilidad, etc. A menudo puedes encontrar modelos pre-entrenados abiertos para hacer el truco.
- Contar componentes específicos: correos electrónicos, URLs, emojis, fechas y partes del discurso. Puedes usar modelos externos o incluso expresiones regulares simples.
- Obtener detalles con estadísticas: puedes rastrear estadísticas de texto muy detalladas si son relevantes para tu caso de uso, por ejemplo, rastrear la longitud promedio de las palabras, si están en mayúscula o minúscula, la proporción de palabras únicas, etc.
- Monitorear información de identificación personal: por ejemplo, cuando no esperas que aparezca en conversaciones de chatbot.
- Usar reconocimiento de entidades nombradas: para extraer entidades específicas y tratarlas como etiquetas.
- Usar modelado de temas para construir un sistema de monitoreo de temas. Este enfoque es el más laborioso pero poderoso cuando se hace correctamente. Es útil cuando esperas que los textos se mantengan en su mayoría en el tema y tienes el corpus de ejemplos anteriores para entrenar el modelo. Puedes usar agrupamiento de temas no supervisado y crear un modelo para asignar nuevos textos a los grupos conocidos. Luego puedes tratar las clases asignadas como descriptores para monitorear los cambios en la distribución de temas en los nuevos datos.

Aquí hay algunas cosas a tener en cuenta al diseñar descriptores para monitorear:
- Es mejor mantenerse enfocado y tratar de encontrar un pequeño número de indicadores de calidad adecuados que se ajusten al caso de uso en lugar de monitorear todas las dimensiones posibles. Piensa en los descriptores como características del modelo. Quieres encontrar algunos fuertes en lugar de generar muchas características débiles o no útiles. Muchas de ellas estarán correlacionadas: idioma y proporción de palabras fuera del vocabulario, longitud en oraciones y símbolos, etc. ¡Elige tus favoritos!
- Usa el análisis exploratorio de datos para evaluar las propiedades del texto en datos existentes (por ejemplo, registros de conversaciones anteriores) para probar tus suposiciones antes de agregarlas al monitoreo del modelo.
- Aprende de los fallos del modelo. Cada vez que te enfrentes a un problema de calidad del modelo en producción que esperas que vuelva a aparecer (por ejemplo, textos en un idioma extranjero), considera cómo desarrollar un caso de prueba o un descriptor para detectarlo en el futuro.
- Ten en cuenta el costo computacional. Usar modelos externos para evaluar tus textos en cada posible dimensión es tentador, pero esto tiene un costo. Tenlo en cuenta al trabajar con conjuntos de datos más grandes: cada clasificador externo es un modelo adicional para ejecutar. A menudo puedes salirte con menos o comprobaciones más simples.
Tutorial paso a paso
Para ilustrar la idea, veamos el siguiente escenario: estás construyendo un modelo clasificador para puntuar las reseñas que los usuarios dejan en un sitio web de comercio electrónico y etiquetarlas por tema. Una vez que esté en producción, quieres detectar cambios en los datos y en el entorno del modelo, pero no tienes las etiquetas reales. Necesitas ejecutar un proceso de etiquetado separado para obtenerlas.
¿Cómo puedes mantener un seguimiento de los cambios sin las etiquetas?
Tomemos un conjunto de datos de ejemplo y sigamos los siguientes pasos:
Ejemplo de código: ve al cuaderno de ejemplo para seguir todos los pasos.
💻 1. Instalar Evidently
Primero, instala Evidently. Utiliza el gestor de paquetes de Python para instalarlo en tu entorno. Si estás trabajando en Colab, ejecuta !pip install. En el Jupyter Notebook, también debes instalar nbextension. Consulta las instrucciones para tu entorno.
También necesitarás importar algunas otras bibliotecas como pandas y componentes específicos de Evidently. Sigue las instrucciones en el cuaderno.
🔡 2. Preparar los datos
Una vez que lo tengas todo listo, ¡veamos los datos! Trabajarás con un conjunto de datos abierto de reseñas de comercio electrónico.
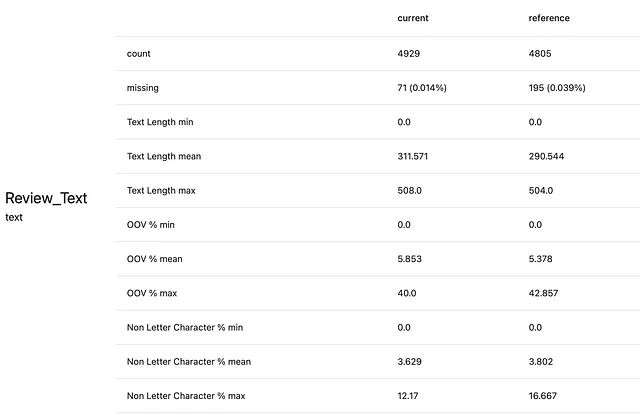
Aquí se muestra cómo se ve el conjunto de datos:
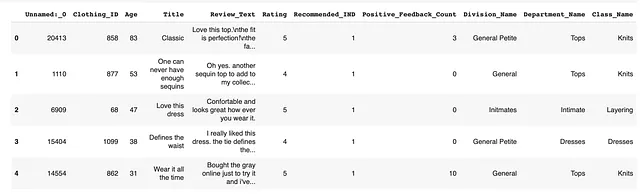
Nos centraremos en la columna “Review_Text” con fines de demostración. En producción, queremos monitorear los cambios en los textos de las reseñas.
Necesitarás especificar la columna que contiene los textos utilizando la asignación de columnas:
column_mapping = ColumnMapping( numerical_features=['Age', 'Positive_Feedback_Count'], categorical_features=['Division_Name', 'Department_Name', 'Class_Name'], text_features=['Review_Text', 'Title'])También debes dividir los datos en dos: referencia y actual. Imagina que los datos de “referencia” son los datos de algún período pasado representativo (por ejemplo, el mes anterior) y los datos “actuales” son los datos de producción actuales (por ejemplo, este mes). Estos son los dos conjuntos de datos que compararás usando descriptores.
Nota: es importante establecer una línea de base histórica adecuada. Elije el período que refleje tus expectativas sobre cómo deberían verse los datos en el futuro.
Seleccionamos 5000 ejemplos para cada muestra. Para hacer las cosas interesantes, introdujimos un cambio artificial seleccionando las reseñas negativas para nuestro conjunto de datos actual.
reviews_ref = reviews[reviews.Rating > 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)reviews_cur = reviews[reviews.Rating < 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)📊 3. Análisis exploratorio de datos
Para comprender mejor los datos, puedes generar un informe visual utilizando Evidently. Hay un Preset de Resumen de Texto predefinido que ayuda a comparar rápidamente dos conjuntos de datos de texto. Combina varias comprobaciones descriptivas y evalúa el cambio general de datos (en este caso, utilizando un método de detección de cambio basado en modelos).
Este informe también incluye algunos descriptores estándar y te permite agregar descriptores utilizando listas de palabras clave. Analizaremos los siguientes descriptores como parte del informe:
- Longitud de los textos
- Porcentaje de palabras OOV
- Porcentaje de símbolos que no son letras
- El sentimiento de las reseñas
- Reseñas que incluyen las palabras “vestido” o “túnica”
- Reseñas que incluyen las palabras “blusa” o “camisa”
Consulta la documentación de Evidently sobre Descriptores para más detalles.
Aquí está el código que necesitas para ejecutar este informe. Puedes asignar nombres personalizados a cada descriptor.
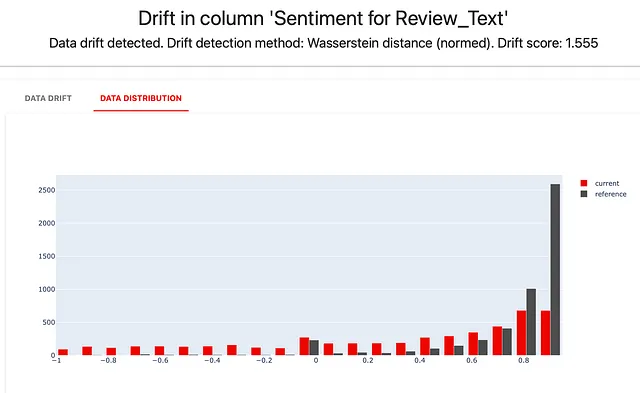
text_overview_report = Report(metrics=[ TextOverviewPreset(column_name="Review_Text", descriptors={ "Textos de reseña - % OOV" : OOV(), "Textos de reseña - % No Letras" : NonLetterCharacterPercentage(), "Textos de reseña - Longitud del símbolo" : TextLength(), "Textos de reseña - Cantidad de oraciones" : SentenceCount(), "Textos de reseña - Cantidad de palabras" : WordCount(), "Textos de reseña - Sentimiento" : Sentiment(), "Reseñas sobre vestidos" : TriggerWordsPresence(words_list=['vestido', 'túnica']), "Reseñas sobre blusas" : TriggerWordsPresence(words_list=['blusa', 'camisa']), }) ]) text_overview_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) text_overview_reportEjecutar un informe como este ayuda a explorar patrones y dar forma a tus expectativas sobre propiedades particulares, como la distribución de la longitud del texto.
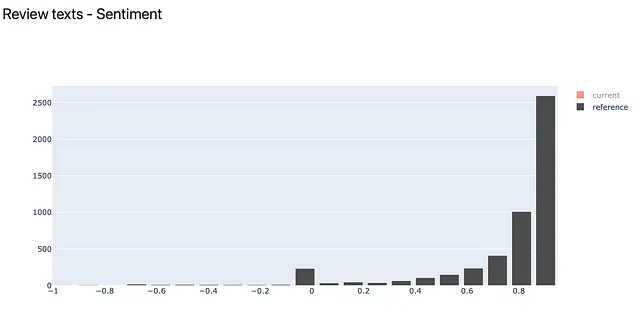
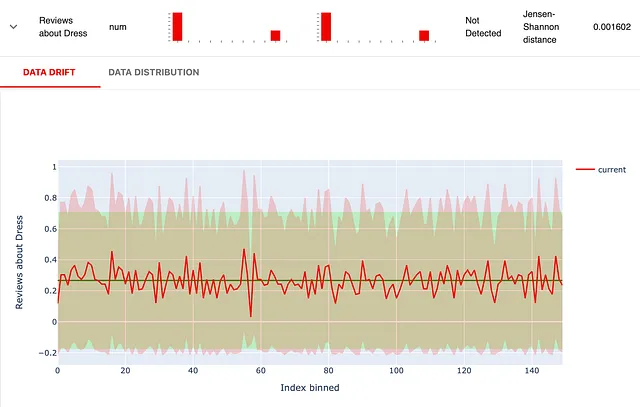
La distribución del descriptor “sentimiento” expone rápidamente el truco que hicimos al dividir los datos. Colocamos las reseñas con una calificación superior a 3 en los datos de “referencia” y reseñas más negativas en los conjuntos de datos “actuales”. Los resultados son visibles:
El informe predeterminado es muy completo y ayuda a examinar muchas propiedades del texto a la vez. ¡Incluso puedes explorar correlaciones entre descriptores y otras columnas en el conjunto de datos!
Puedes usarlo durante la fase exploratoria, pero probablemente no sea algo que necesites revisar todo el tiempo.
Afortunadamente, es fácil de personalizar.
Claramente, Presets y Métricas. Evidently tiene presets de informes que generan rápidamente los informes listos para usar. Sin embargo, ¡hay muchas métricas individuales para elegir! Puede combinarlas para crear un informe personalizado. Explore los presets y las métricas para comprender qué hay disponible.
📈 4. Monitorear el cambio de descriptores
Supongamos que, basado en el análisis exploratorio y su comprensión del problema comercial, decide realizar un seguimiento de un pequeño número de propiedades:
Quiere darse cuenta cuando haya un cambio estadístico: las distribuciones de estas propiedades difieren del período de referencia. Para detectarlo, puede utilizar los métodos de detección de drift implementados en Evidently. Por ejemplo, para características numéricas como “sentimiento”, por defecto, monitorizará el cambio utilizando la distancia de Wasserstein. También puede elegir un método diferente.
Así es como puede crear un informe de drift simple para realizar un seguimiento de los cambios en los tres descriptores.
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Review_Text")), ColumnDriftMetric(Sentiment().for_column("Review_Text")), ColumnDriftMetric(TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_reportUna vez que haya ejecutado el informe, obtendrá visualizaciones combinadas para todos los descriptores seleccionados. Aquí hay una:

La línea verde oscura es el sentimiento promedio en el conjunto de datos de referencia. El área verde cubre una desviación estándar desde la media. Puede notar que la distribución actual (en rojo) es visiblemente más negativa.
Nota: En este escenario, también tiene sentido monitorear el drift de salida: rastreando cambios en las clases predichas. Puede utilizar métodos de detección de drift de datos categóricos, como la divergencia JS. No cubrimos esto en el tutorial, ya que nos enfocamos solo en las entradas y no generamos predicciones. En la práctica, el drift de predicción suele ser la primera señal a la que reaccionar.
😍 5. Agregar un descriptor de “emoción”
Supongamos que decidió realizar un seguimiento de una propiedad más significativa: la emoción expresada en la reseña. El sentimiento general es una cosa, pero también ayuda a distinguir entre reseñas “tristes” y “enojadas”, por ejemplo.
¡Agreguemos este descriptor personalizado! Puede encontrar un modelo externo de código abierto adecuado para puntuar su conjunto de datos. Luego, trabajará con esta propiedad como una columna adicional.
Tomaremos el modelo Distilbert de Huggingface, que clasifica el texto en cinco emociones.
Puede considerar usar cualquier otro modelo para su caso de uso, como reconocimiento de entidades nombradas, detección de idioma, detección de toxicidad, etc.
Debe instalar transformers para poder ejecutar el modelo. Verifique las instrucciones para obtener más detalles. Luego, aplíquelo al conjunto de datos de reseñas:
from transformers import pipeline classifier = pipeline("text-classification", model='bhadresh-savani/distilbert-base-uncased-emotion', top_k=1) prediction = classifier("¡Me encanta usar evidently! Es fácil de usar", ) print(prediction)Nota: este paso puntuará el conjunto de datos utilizando el modelo externo. Tomará algún tiempo ejecutarse, dependiendo de su entorno. Para comprender el principio sin esperar, consulte la sección “Ejemplo simple” en el cuaderno de ejemplo.
Después de agregar la nueva columna “emoción” al conjunto de datos, debe reflejar esto en la asignación de columnas. Debe especificar que es una nueva variable categórica en el conjunto de datos.
column_mapping = ColumnMapping( numerical_features=['Edad', 'Cantidad_de_Comentarios_Positivos'], categorical_features=['Nombre_de_División', 'Nombre_de_Departamento', 'Nombre_de_Clase', 'emoción'], text_features=['Texto_de_Reseña', 'Título'] )Ahora, puede agregar el monitoreo de cambio en la distribución de “emoción” al informe.
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Texto_de_Reseña")), ColumnDriftMetric(Sentiment().for_column("Texto_de_Reseña")), ColumnDriftMetric(TriggerWordsPresence(words_list=['vestido', 'toga']).for_column("Texto_de_Reseña")), ColumnDriftMetric('emoción'), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_report¡Aquí tienes lo que obtienes!
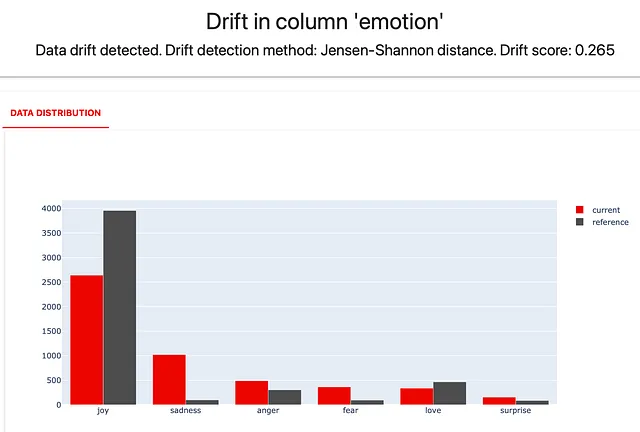
Puedes ver un aumento significativo en las revisiones “tristes” y una disminución en las “alegres”.
¿Te parece útil seguirlo a lo largo del tiempo? Puedes continuar ejecutando esta verificación puntuando los nuevos datos a medida que lleguen.
🏗️ 6. Ejecutar pruebas de la tubería
Para realizar un análisis regular de tus entradas de datos, tiene sentido empaquetar las evaluaciones como pruebas. Obtendrás un resultado claro de “aprobado” o “reprobado” en este escenario. Probablemente no necesites ver los gráficos si todas las pruebas son aprobadas. ¡Solo te interesa cuando las cosas cambian!
Evidentemente tiene una interfaz alternativa llamada Test Suite que funciona de esta manera.
Así es como creas una Test Suite para verificar la distribución estadística en los mismos cuatro descriptores:
descriptors_test_suite = TestSuite(tests=[ TestColumnDrift(column_name = 'emoción'), TestColumnDrift(column_name = WordCount().for_column("Texto_de_Revision")), TestColumnDrift(column_name = Sentiment().for_column("Texto_de_Revision")), TestColumnDrift(column_name = TriggerWordsPresence(words_list=['vestido', 'traje']).for_column("Texto_de_Revision")), ]) descriptors_test_suite.run(reference_data=revisiones_ref, current_data=revisiones_act, column_mapping=mapping_columnas) descriptors_test_suiteNota: utilizamos los valores predeterminados, pero también puedes establecer métodos de cambio personalizados y condiciones.
Aquí está el resultado. La salida está estructurada de manera ordenada para que puedas ver cuáles descriptores han cambiado.
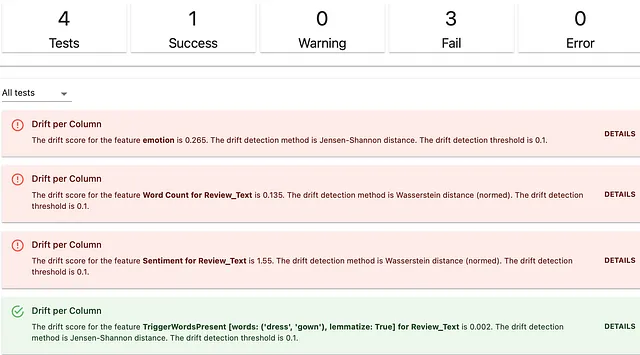
Detectar el cambio en la distribución estadística es una de las formas de monitorear los cambios en la propiedad del texto. ¡Hay otras! A veces, es conveniente ejecutar expectativas basadas en reglas en los valores mínimos, máximos o medios del descriptor.
Supongamos que quieres verificar que todos los textos de revisión tienen más de dos palabras. Si al menos una revisión tiene menos de dos palabras, quieres que la prueba falle y ver la cantidad de textos cortos en la respuesta.
¡Así es como lo haces! Puedes elegir una verificación TestNumberOfOutRangeValues(). Esta vez, debes establecer un límite personalizado: el lado “izquierdo” del rango esperado son dos palabras. También debes establecer una condición de prueba: eq=0. Esto significa que esperas que el número de objetos fuera de este rango sea 0. Si es mayor, quieres que la prueba devuelva un fallo.
descriptors_test_suite = TestSuite(tests=[ TestNumberOfOutRangeValues(column_name = WordCount().for_column("Texto_de_Revision"), left=2, eq=0), ]) descriptors_test_suite.run(reference_data=revisiones_ref, current_data=revisiones_act, column_mapping=mapping_columnas) descriptors_test_suiteAquí está el resultado. También puedes ver los detalles de la prueba que muestran la expectativa definida.
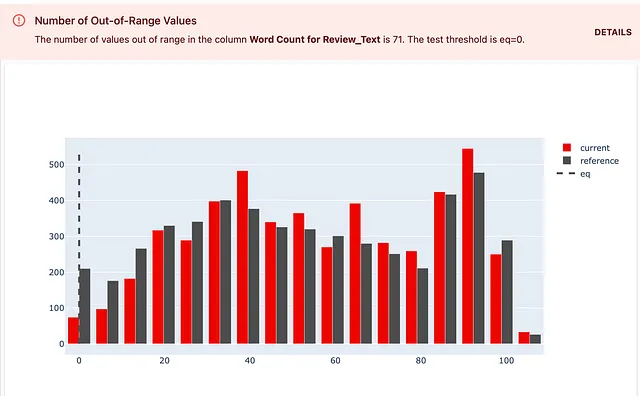
Puedes seguir este principio para diseñar otras verificaciones.
Apoya a Evidentemente
¿Disfrutaste el tutorial? ¡Dale una estrella a Evidentemente en GitHub para contribuir! Esto nos ayuda a seguir creando herramientas y contenido gratuitos y de código abierto para la comunidad. ⭐️ Dales una estrella en GitHub ⟶
Resumiendo
Los descriptores de texto mapean los datos de texto en dimensiones interpretables que puedes expresar como atributos numéricos o categóricos. Ayudan a describir, evaluar y monitorear datos no estructurados.
En este tutorial, aprendiste cómo monitorear datos de texto utilizando descriptores.
Puedes utilizar este enfoque para monitorear el comportamiento de los modelos impulsados por NLP y LLM en producción. Puedes personalizar y combinar tus descriptores con otros métodos, como el monitoreo del cambio en la incrustación.
¿Consideras que hay otros descriptores universalmente útiles? ¡Haznos saber! Únete a nuestra comunidad de Discord para compartir tus ideas.
Originalmente publicado en https://www.evidentlyai.com el 27 de junio de 2023. Gracias a Olga Filippova por coautorar el artículo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo los bancos deben aprovechar la IA responsable para abordar el crimen financiero
- Investigadores de la Universidad de Pekín presentan FastServe un sistema de servicio de inferencia distribuida para modelos de lenguaje grandes (LLMs).
- Consejos y trucos para integrar la IA en un equipo bien conectado
- Principales 6 usos de la IA en el sector del transporte
- Expande tu negocio con 3 indicaciones de ChatGPT (El método de Alex Hormozi)
- Pruebas de IVR en la era de la IA Cerrando la brecha entre humanos y máquinas
- ¿Necesitan los LLM todas esas capas para lograr el aprendizaje en contexto?






