¡Construye y juega! ¡Tu propio modelo V&L equipado con LLM!
¡Construye y juega! ¡Tu modelo V&L con LLM!
Desarrollo de modelos de lenguaje de visión integrados con LLM-GIT.
Resumen de este artículo:
- Explicando GIT, un modelo de lenguaje de visión desarrollado por Microsoft.
- Sustituyendo el modelo de lenguaje de GIT con modelos de lenguaje grandes (LLMs) utilizando PyTorch y Transformers de Hugging Face.
- Presentando cómo afinar los modelos GIT-LLM utilizando LoRA.
- Probando y discutiendo los modelos desarrollados.
- Investigando si las “incrustaciones de imágenes” incrustadas por el codificador de imágenes de GIT indican caracteres específicos en el mismo espacio que las “incrustaciones de texto”.
Los modelos de lenguaje grandes (LLM) están mostrando cada vez más su valor. La incorporación de imágenes en los LLM los hace aún más útiles como modelos de lenguaje de visión. En este artículo, explicaré el desarrollo de un modelo llamado GIT-LLM, un modelo de lenguaje de visión simple pero potente. Algunas partes, como las explicaciones de código, pueden resultar un poco tediosas, así que siéntete libre de ir directamente a la sección de resultados. Realicé varios experimentos y análisis, así que creo que te gustará ver lo que pude lograr.
La implementación está disponible públicamente, así que no dudes en probarla.
GitHub – turingmotors/heron
Contribuye al desarrollo de turingmotors/heron creando una cuenta en GitHub.
github.com
- Práctica con Aprendizaje Supervisado Regresión Lineal
- Cómo Identificar Datos Faltantes en Conjuntos de Datos de Series Temporales
- Cómo la Inteligencia Artificial está transformando la Gestión de Servicios de TI
Transformando GIT en LLM
Sumergámonos en el tema principal de este blog técnico.
¿Qué es GIT?
Generative Image-to-text Transformer, o GIT, es un modelo de lenguaje de visión propuesto por Microsoft.
arXiv: https://arxiv.org/abs/2205.14100Code: https://github.com/microsoft/GenerativeImage2Text
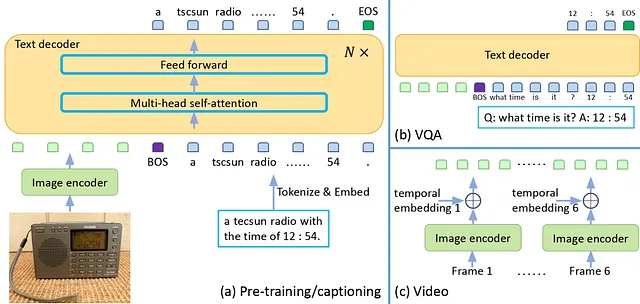
Su arquitectura es bastante simple. Convierte los vectores de características extraídos de un codificador de imágenes en vectores que pueden tratarse como texto utilizando un módulo de proyección. Estos vectores se introducen luego en un modelo de lenguaje para producir subtítulos para imágenes o realizar preguntas y respuestas. El modelo puede manejar videos de manera similar.
A pesar de su simplicidad, si observas el Leaderboard en “Paper with code”, verás que ocupa un lugar destacado en muchas tareas.
https://paperswithcode.com/paper/git-a-generative-image-to-text-transformer
Originalmente, GIT utiliza modelos potentes como CLIP para su codificador de imágenes y entrena la parte del modelo de lenguaje desde cero. Sin embargo, en este artículo, intento utilizar un LLM potente y afinarlo. Aquí, llamo al modelo “GIT-LLM”.
Utilizando un LLM con Transformers de Hugging Face
Utilizaré la biblioteca Transformers de Hugging Face para desarrollar GIT-LLM. Transformers es una biblioteca de Python para manejar modelos de aprendizaje automático. Ofrece muchos modelos pre-entrenados de última generación que puedes utilizar de inmediato para inferencia. También proporciona herramientas para entrenar y afinar modelos. Creo que Transformers ha contribuido significativamente al desarrollo de derivados de LLM recientes. Casi todos los LLM disponibles se pueden manejar con Transformers, y muchos modelos multimodales derivados de ellos utilizan Transformers como base para su desarrollo y afinamiento.
Aquí tienes el código más simple para utilizar un modelo de Transformers. Te resultará fácil probar LLMs utilizando AutoModel y AutoTokenizer.
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-350m"model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Hola, soy consciente y"input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")sample = model.generate(**input_ids, max_length=64)print(tokenizer.decode(sample[0]))# Hola, soy consciente y soy un poco novato. Estoy buscando un buen lugar para empezar.Vamos a echar un vistazo a los parámetros que tiene el modelo OPT. Imprimiendo un modelo creado por AutoModelForCausalLM.
OPTForCausalLM( (model): OPTModel( (decoder): OPTDecoder( (embed_tokens): Embedding(50272, 512, padding_idx=1) (embed_positions): OPTLearnedPositionalEmbedding(2050, 1024) (project_out): Linear(in_features=1024, out_features=512, bias=False) (project_in): Linear(in_features=512, out_features=1024, bias=False) (layers): ModuleList( (0-23): 24 x OPTDecoderLayer( (self_attn): OPTAttention( (k_proj): Linear(in_features=1024, out_features=1024, bias=True) (v_proj): Linear(in_features=1024, out_features=1024, bias=True) (q_proj): Linear(in_features=1024, out_features=1024, bias=True) (out_proj): Linear(in_features=1024, out_features=1024, bias=True) ) (activation_fn): ReLU() (self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) (fc1): Linear(in_features=1024, out_features=4096, bias=True) (fc2): Linear(in_features=4096, out_features=1024, bias=True) (final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True) ) ) ) ) (lm_head): Linear(in_features=512, out_features=50272, bias=False))Es bastante simple. La dimensión de entrada de embed_tokens inicial y la dimensión de salida de lm_head final es de 50.272, lo que representa el número de tokens utilizados en el entrenamiento de este modelo. Verifiquemos el tamaño del vocabulario del tokenizador:
print(tokenizer.vocab_size)# 50265Incluyendo tokens especiales como bos_token, eos_token, unk_token, sep_token, pad_token, cls_token y mask_token, predice la probabilidad de la próxima palabra entre un total de 50.272 tipos de tokens.
Puedes entender cómo estos modelos están conectados al observar la implementación. Un diagrama simple representaría el flujo de la siguiente manera:

La estructura y el flujo de datos son bastante simples. Los modelos 〇〇Model y 〇〇ForCausalLM tienen un marco similar en diferentes modelos de lenguaje. La clase 〇〇Model representa principalmente la parte “Transformer” del modelo de lenguaje. Si, por ejemplo, deseas realizar tareas como clasificación de texto, solo usarías esta parte. La clase 〇〇ForCausalLM es para generación de texto, aplicando un clasificador para contar tokens a los vectores después de procesarlos con el Transformer. El cálculo de la pérdida también se realiza dentro del método forward de esta clase. embed_positions denota la codificación posicional, que se agrega a project_in.
Usando GIT con Transformers
Lo intentaré basándome en la página de documentación oficial de GIT. Como también procesaré imágenes, usaré un Procesador que también incluye un Tokenizer.
from PIL import Imageimport requestsfrom transformers import AutoProcessor, AutoModelForCausalLMmodel_name = "microsoft/git-base-coco"model = AutoModelForCausalLM.from_pretrained(model_name)processor = AutoProcessor.from_pretrained(model_name)# Descargando y preprocesando una imagenurl = "http://images.cocodataset.org/val2017/000000039769.jpg"image = Image.open(requests.get(url, stream=True).raw)pixel_values = processor(images=image, return_tensors="pt").pixel_values# Preprocesando el textoprompt = "¿Qué es esto?"inputs = processor( prompt, image, return_tensors="pt", max_length=64 )sample = model.generate(**inputs, max_length=64)print(processor.tokenizer.decode(sample[0]))# dos gatos durmiendo en un sofáDado que la imagen de entrada produce la salida “dos gatos durmiendo en un sofá”, parece estar funcionando bien.
También echemos un vistazo a la estructura del modelo:
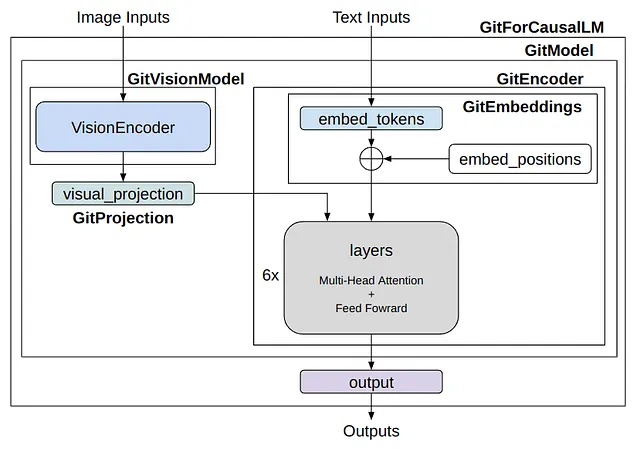
GitForCausalLM( (git): GitModel( (embeddings): GitEmbeddings( (word_embeddings): Embedding(30522, 768, padding_idx=0) (position_embeddings): Embedding(1024, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (image_encoder): GitVisionModel( (vision_model): GitVisionTransformer( ... ) ) (encoder): GitEncoder( (layer): ModuleList( (0-5): 6 x GitLayer( ... ) ) ) (visual_projection): GitProjection( (visual_projection): Sequential( (0): Linear(in_features=768, out_features=768, bias=True) (1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) ) ) ) (output): Linear(in_features=768, out_features=30522, bias=True))Aunque es un poco largo, si lo desglosamos, también es bastante simple. Dentro de GitForCausalLM, hay un GitModel y dentro de eso, hay los siguientes módulos:
- embeddings (GitEmbeddings)
- image_encoder (GitVisionModel)
- encoder (GitEncoder)
- visual_projection (GitProjection)
- output (Linear)
La diferencia principal con OPT es la presencia de GitVisionModel y GitProjection, que son los módulos exactos que convierten imágenes en vectores similares a las instrucciones. Mientras que el modelo de lenguaje utiliza un Decoder para OPT y un Encoder para GIT, esto solo significa una diferencia en cómo se construye la máscara de atención. Puede haber ligeras diferencias en la capa transformadora, pero sus funciones son esencialmente las mismas. GIT utiliza el nombre Encoder porque utiliza una máscara de atención única que aplica atención a todas las características de la imagen y utiliza una máscara causal para las características de texto.
Observando las conexiones del modelo:
La información de la imagen es tratada por GitVisionModel y GitProjection para que coincida con los embeddings del texto. Después de eso, se ingresa junto con los embeddings del texto en las capas “Transformer” del modelo de lenguaje. Aunque hay diferencias sutiles, la parte relacionada con el modelo de lenguaje se desarrolla de casi la misma manera.
Máscara de atención de GIT
Las arquitecturas para el modelo de lenguaje usual y el modelo de lenguaje GIT son casi iguales, pero las formas de aplicar la máscara de atención son diferentes.
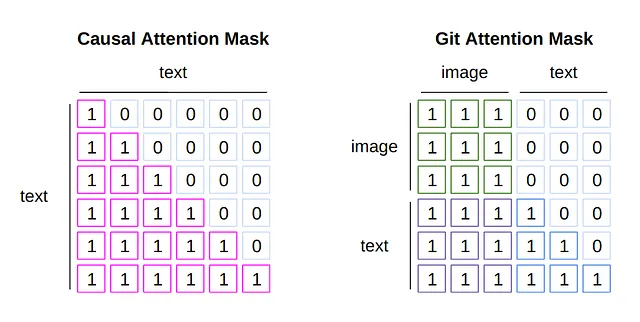
Para el modelo de lenguaje, se aplica una máscara de atención para evitar mirar los tokens pasados al predecir los tokens futuros. Este es un método llamado “Atención Causal”, que corresponde al lado izquierdo de la siguiente figura. El token de la primera columna se refiere solo a sí mismo, asegurando que no se aplique atención propia a las palabras siguientes. La segunda columna aplica atención propia hasta la segunda palabra, a partir de la tercera palabra se vuelve 0. Esta máscara permite entrenar al modelo para predecir la siguiente palabra de manera efectiva.
La entrada de GIT tiene dos tipos de tokens: tokens de imagen y tokens de texto. Dado que todos los tokens de imagen se utilizan simultáneamente y no se utilizan para predecir el siguiente token, la Atención Causal no es adecuada. Por otro lado, la Atención Causal todavía es necesaria para los tokens de texto. Se diseña una máscara como la que se muestra en el lado derecho de la figura para lograr esto. Para las tres primeras filas de información de la imagen, se aplica atención propia con toda la información del token. A partir de los tokens de texto, al moverse hacia abajo una columna se aumenta el número de palabras a las que se puede hacer referencia.
También veamos el código para crear una máscara GIT. El fragmento para crear la máscara GIT es el siguiente:
import torchdef create_git_attention_mask( tgt: torch.Tensor, memory: torch.Tensor,) -> torch.Tensor: num_tgt = tgt.shape[1] num_memory = memory.shape[1] # Las áreas donde se aplica atención son 0, las áreas sin atención son -inf top_left = torch.zeros((num_memory, num_memory)) top_right = torch.full( (num_memory, num_tgt), float("-inf"), ) bottom_left = torch.zeros( (num_tgt, num_memory), ) # Máscara de atención causal bottom_right = torch.triu(torch.ones(tgt.shape[1], tgt.shape[1]), diagonal=1) bottom_right = bottom_right.masked_fill(bottom_right == 1, float("-inf")) # Concatenar máscaras left = torch.cat((top_left, bottom_left), dim=0) right = torch.cat((top_right, bottom_right), dim=0) # agregar eje para multi-head full_attention_mask = torch.cat((left, right), dim=1)[None, None, :] return full_attention_mask# batch_size, sequence, feature_dimvisual_feature = torch.rand(1, 3, 128)text_feature = torch.rand(1, 4, 128)mask = create_git_attention_mask(tgt=text_feature, memory=visual_feature)print(mask)"""tensor([[[[0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., -inf, -inf, -inf, -inf], [0., 0., 0., 0., -inf, -inf, -inf], [0., 0., 0., 0., 0., -inf, -inf], [0., 0., 0., 0., 0., 0., -inf], [0., 0., 0., 0., 0., 0., 0.]]]])"""Agregas la máscara a los pesos de atención. Por lo tanto, las partes donde ocurre la autoatención son 0, y las partes que no se incluyen en la atención son -inf. Al proporcionar esta máscara hacia adelante, solo la parte de texto puede realizar una atención causal. Es importante para los modelos de lenguaje de visión crear y usar máscaras de manera efectiva como esta.
Conectando GIT y OPT
Ahora, conectemos GIT y OPT. El objetivo es crear un modelo como se muestra en la figura.

Para la implementación general, puedes consultar el modeling_git.py.
La parte más importante es GitOPTModel. Dentro de esto, un codificador de visión debe estar conectado con un LLM. Explicaré algunos componentes clave.
class GitOPTModel(OPTModel): def __init__(self, config: OPTConfig): super(GitOPTModel, self).__init__(config) self.image_encoder = CLIPVisionModel.from_pretrained(config.vision_model_name) self.visual_projection = GitProjection(config)Dentro de la función __init__, se instancian varios módulos. El super inicializa el OPTModel. En GIT, se recomienda utilizar un codificador de imágenes potente entrenado con CLIP, por lo que lo he hecho compatible con ViT entrenado con CLIP. El GitProjection se toma de la implementación original de GIT.
Echemos un vistazo dentro de la función forward. La implementación se basa en la parte forward del OPTDecoder, con información adicional del codificador de imágenes. Aunque es un poco extenso, he agregado comentarios en el código, así que por favor sigue cada paso.
class GitOPTModel(OPTModel): ... def forward( self, input_ids: Optional[torch.Tensor] = None, attention_mask: Optional[torch.Tensor] = None, pixel_values: Optional[torch.Tensor] = None, ) -> BaseModelOutputWithPooling: seq_length = input_shape[1] # 1. Extraer características de la imagen utilizando ViT visual_features = self.image_encoder(pixel_values).last_hidden_state # 2. Convertir características extraídas por ViT en Incrustaciones de Imagen similares a las indicaciones projected_visual_features = self.visual_projection(visual_features) # 3. Vectorizar los tokens inputs_embeds = self.decoder.embed_tokens(input_ids) # 4. Obtener Codificación Posicional pos_embeds = self.embed_positions(attention_mask, 0) # 5. Ajuste de dimensión de las Incrustaciones de Texto específicas de OPT inputs_embeds = self.decoder.project_in(inputs_embeds) # 6. Incrustaciones de Texto + Codificación Posicional embedding_output = inputs_embeds + pos_embeds # 7. Concatenar Incrustaciones de Imagen e Incrustaciones de Texto hidden_states = torch.cat((projected_visual_features, embedding_output), dim=1) # 8. Crear Máscara de Atención Causal para la región de Texto tgt_mask = self._generate_future_mask( seq_length, embedding_output.dtype, embedding_output.device ) # 9. Crear Máscara de Atención para GIT combined_attention_mask = self.create_attention_mask( tgt=embedding_output, memory=projected_visual_features, tgt_mask=tgt_mask, past_key_values_length=0, ) # 10. Pasar repetidamente a través de la capa del Decodificador, la parte principal del modelo de lenguaje for idx, decoder_layer in enumerate(self.decoder.layers): layer_outputs = decoder_layer( hidden_states, attention_mask=combined_attention_mask, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = layer_outputs[0] # 11. Ajuste de dimensión MLP específico de OPT hidden_states = self.decoder.project_out(hidden_states) # 12. Alinear la interfaz de salida return BaseModelOutputWithPast( last_hidden_state=hidden_states, past_key_values=next_cache, hidden_states=all_hidden_states, attentions=all_self_attns, )Aunque puede parecer complicado, si sigues cada paso, verás que sigue el flujo ilustrado en el diagrama. El código real puede ser un poco más complejo, pero entender primero el proceso principal facilitará la comprensión de las otras partes. Este es un seudocódigo, por lo que para las partes detalladas, consulta la implementación publicada.
Finalmente, echemos un breve vistazo a la parte GITOPTForCausalLM.
class GitOPTForCausalLM(OPTForCausalLM): def __init__( self, config, ): super(GitOPTForCausalLM, self).__init__(config) self.model = GitOPTModel(config) def forward( ... ) -> CausalLMOutputWithPast: outputs = self.model( ... ) sequence_output = outputs[0] logits = self.lm_head(sequence_output) loss = None if labels is not None: # Predecir la siguiente palabra como tarea num_image_tokens = self.image_patch_tokens shifted_logits = logits[:, num_image_tokens:-1, :].contiguous() labels = labels[:, 1:].contiguous() loss_fct = CrossEntropyLoss() loss = loss_fct(shifted_logits.view(-1, self.config.vocab_size), labels.view(-1)) return CausalLMOutputWithPast( loss=loss, logits=logits, ... )El procesamiento dentro del modelo es simple. Cuando se proporcionan etiquetas, es decir, durante el entrenamiento, también se realiza el cálculo de la pérdida dentro de forward. En shifted_logits, se obtienen los tokens desde el primer token hasta el penúltimo token de los tokens de texto. Luego calcula la pérdida de entropía cruzada con las etiquetas desplazadas una palabra como respuesta correcta.
Una cosa a tener en cuenta es nombrar la variable que asigna el GitOPTModel en la función de inicialización como self.model. Si revisas la implementación de la clase padre OPTForCausalLM, verás que OPT se coloca primero en self.model durante la inicialización super. Si cambias este nombre de variable de instancia, acabarás teniendo dos OPT, lo que puede sobrecargar la memoria.
Extensión de LoRA
Para ajustar finamente el LLM de manera efectiva, utilizaré una biblioteca llamada Fine-Tuning Eficiente de Parámetros (PEFT, por sus siglas en inglés). Como está desarrollada por Hugging Face, se integra perfectamente con Transfors. Si bien hay varios métodos dentro de PEFT, esta vez voy a realizar algunos experimentos utilizando un enfoque comúnmente utilizado llamado adaptación de baja clasificación (LoRA).
Los modelos pueden aplicar LoRA en solo unas pocas líneas si admiten PEFT.
from transformers import AutoModelForCausalLMfrom peft import get_peft_config, get_peft_model, LoraConfigmodel = AutoModelForCausalLM.from_pretrained('microsoft/git-base')peft_config = LoraConfig( task_type="CAUSAL_LM", r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["v_proj"])peft_model = get_peft_model(model, peft_config)El argumento target_modules especifica qué módulos quieres convertir a LoRA. Si se proporciona una lista como target_modules, se implementa la conversión a LoRA para los módulos que terminan con cada una de las cadenas. LoRA se aplica solo a “value” (v_proj) del módulo de atención propia para simplificar.
En el modelo, se utiliza ViT para la parte del codificador de imagen. Ten cuidado, ya que al especificarlo de esta manera, la parte de atención propia de ViT también puede aplicar LoRA. Es un poco tedioso, pero al especificar hasta la parte donde los nombres clave no se superponen y dárselo a target_modules, puedes evitar esto.
target_modules = [f"model.image_encoder.vision_model.encoder.{i}.self_attn.v_proj" for i in range(len(model.model.decoder))]El modelo resultante se convierte en una instancia de la clase PeftModelForCausalLM. Tiene una variable de instancia llamada base_model que contiene el modelo original convertido a LoRA. Como ejemplo, muestro que LoRA se aplica a v_proj de la atención propia en ViT.
(self_attn): GitVisionAttention( (k_proj): Linear(in_features=768, out_features=768, bias=True) (v_proj): Linear( in_features=768, out_features=768, bias=True (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=768, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=768, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() ) (q_proj): Linear(in_features=768, out_features=768, bias=True) (out_proj): Linear(in_features=768, out_features=768, bias=True))Dentro de la línea Linear v_proj, encontrarás capas completamente conectadas añadidas como lora_A y lora_B. El módulo Lineal convertido a LoRA es una clase Lineal homónima que hereda de la clase Lineal de PyTorch y de LoraLayer. Es un módulo algo único, por lo que aquellos curiosos sobre los detalles deben echar un vistazo a la implementación.
Nota que los modelos creados con PEFT no guardarán nada más que la parte de LoRA por defecto. Aunque hay un método para guardar usando el método merge_and_unload, es posible que desees guardar todos los modelos a mitad de entrenamiento usando Trainer. Sobrecargar el método _save_checkpoints de Trainer es un enfoque, pero para evitar complicaciones, en esta ocasión lo he manejado obteniendo solo la parte del modelo original contenida dentro de PeftModel durante la fase de entrenamiento.
model = get_peft_model(model, peft_config)model.base_model.model.lm_head = model.lm_headmodel = model.base_model.modelCreo que hay formas más eficientes de manejar esto, así que todavía estoy investigando.
Experimentando con GIT-LLM
Ahora realicemos algunos experimentos utilizando el modelo desarrollado hasta ahora.
Para obtener detalles sobre la configuración de entrenamiento y otras configuraciones, por favor consulta la implementación publicada, ya que esencialmente siguen el mismo método.
Conjunto de datos: M3IT
Para los experimentos, quería usar un conjunto de datos que empareje imágenes con texto y sea fácil de integrar. Mientras exploraba los Conjuntos de Datos de Hugging face, me encontré con M3IT, un conjunto de datos multimodal para Ajuste de Instrucción desarrollado por el Laboratorio de IA de Shanghai. El Ajuste de Instrucción es un método que produce resultados impresionantes incluso con una cantidad limitada de datos. Parece que M3IT ha vuelto a anotar varios conjuntos de datos existentes específicamente para el Ajuste de Instrucción.
https://huggingface.co/datasets/MMInstruction/M3IT
Este conjunto de datos es fácil de usar, por lo que he decidido utilizarlo para los siguientes experimentos.
Para entrenar usando M3IT, es necesario crear un Dataset personalizado de Pytorch.
class SupervisedDataset(Dataset): def __init__( self, vision_model_name: str, model_name: str, loaded_dataset: datasets.GeneratorBasedBuilder, max_length: int = 128, ): super(SupervisedDataset, self).__init__() self.loaded_dataset = loaded_dataset self.max_length = max_length self.processor = AutoProcessor.from_pretrained("microsoft/git-base") # Configurando el Processor correspondiente para cada modelo self.processor.image_processor = CLIPImageProcessor.from_pretrained(vision_model_name) self.processor.tokenizer = AutoTokenizer.from_pretrained( model_name, padding_side="right", use_fast=False ) def __len__(self) -> int: return len(self.loaded_dataset) def __getitem__(self, index) -> dict: # cf: https://huggingface.co/datasets/MMInstruction/M3IT#data-instances row = self.loaded_dataset[index] # Creando entrada de texto text = f'##Instrucción: {row["instruction"]} ##Pregunta: {row["inputs"]} ##Respuesta: {row["outputs"]}' # Cargando la imagen image_base64_str_list = row["image_base64_str"] # str (base64) img = Image.open(BytesIO(b64decode(image_base64_str_list[0]))) inputs = self.processor( text, img, return_tensors="pt", max_length=self.max_length, padding="max_length", truncation=True, ) # tamaño de lote 1 -> desagrupar inputs = {k: v[0] for k, v in inputs.items()} inputs["labels"] = inputs["input_ids"] return inputsEn la función __init__, el image_processor y el tokenizer corresponden a sus respectivos modelos. El argumento loaded_dataset que se pasa debe ser de los conjuntos de datos MMInstruction/M3IT.
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")test_dataset = coco_datasets["test"]Para el conjunto de datos de Ajuste de Instrucción COCO, la división entre entrenamiento, validación y prueba es idéntica al conjunto de datos original, con 566,747, 25,010 y 25,010 pares de imágenes-texto respectivamente. Otros conjuntos de datos, como VQA o Video, también se pueden manejar de manera similar, lo que lo convierte en un conjunto de datos versátil para fines de validación.
Un ejemplo de datos se ve así:

La leyenda para esta imagen es la siguiente:
##Instrucción: Escribe una descripción sucinta de la imagen, capturando sus principales componentes, las relaciones entre ellos y cualquier detalle notable. ##Pregunta: ##Respuesta: Un hombre con un casco rojo en una pequeña moto en un camino de tierra.
Para el conjunto de datos COCO, que es para leyendas, la parte de la pregunta se deja en blanco.
Profundicemos más en las operaciones del procesador. Básicamente, normaliza las imágenes y tokeniza el texto. Los inputs más cortos que max_length también se rellenan con padding. Los datos procesados devueltos por el procesador son un diccionario que contiene:
- input_ids: Un array de texto tokenizado.
- attention_mask: Una máscara para el texto tokenizado (con padding siendo 0).
- pixel_values: Un array de imágenes normalizadas, también convertidas a Channel-first.
Estos nombres de clave corresponden a los argumentos de la función forward del modelo, por lo que no deben ser modificados. Finalmente, los input_ids se pasan directamente a una clave llamada labels. La función forward de GitOPTForCausalLM calcula la pérdida al predecir la siguiente palabra desplazada por un token.
Experimento 1: Determinación de las ubicaciones de afinamiento fino
En los documentos de investigación sobre los modelos GIT, se explicó que se utiliza un codificador de visión fuerte y se adoptan parámetros aleatorios para el modelo de lenguaje. Esta vez, dado que el objetivo es utilizar en última instancia un modelo de lenguaje de clase 7B, se aplicará un modelo pre-entrenado al modelo de lenguaje. Se examinarán los siguientes módulos para el afinamiento fino. La Proyección GIT, como módulo inicializado, siempre está incluida. Algunas combinaciones pueden parecer redundantes, pero se exploran sin demasiada preocupación en esta prueba.
A los módulos establecidos para el entrenamiento se les asignan gradientes, mientras que al resto se les modifica para que no tengan gradientes.
# Especificando los parámetros a entrenar (entrenar todos aumentaría el uso de memoria)for name, p in model.model.named_parameters(): if np.any([k in name for k in keys_finetune]): p.requires_grad = True else: p.requires_grad = FalseEl Codificador de Visión y LLM utilizados para esta prueba son:
- openai/clip-vit-base-patch16
- facebook/opt-350m
El entrenamiento utiliza el conjunto de datos COCO y dura 5 épocas.
A continuación se muestran los módulos objetivo entrenados durante cada experimento:
- Proj: Proyección GIT. Inicializada aleatoriamente, por lo que siempre se entrena.
- LoRA: Se aplicaron Consulta, Clave y Valor de la auto-atención en el modelo de lenguaje.
- OPT: Todos los niveles fueron entrenados.
- ViT: Todos los niveles fueron entrenados.
- Head: Se entrenó la lm_head final de OPT.
(Nota: Si bien LoRA se puede aplicar a ViT, para evitar complicar demasiado los experimentos, no se incluyó en esta ocasión.)
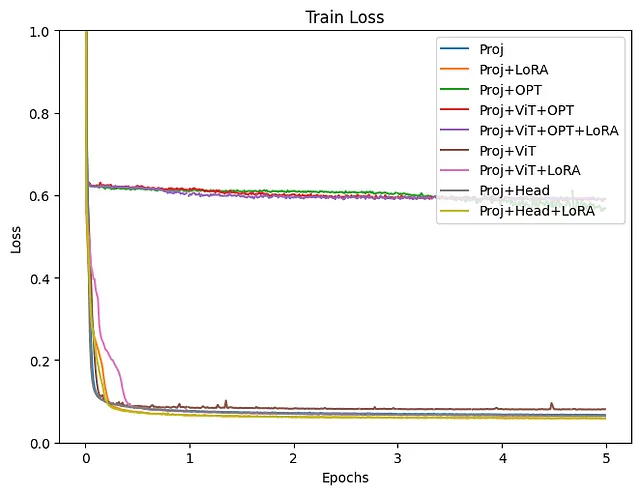
Como se muestra en el gráfico de pérdida de entrenamiento, es evidente que algunos grupos no están funcionando bien. Este fue el caso cuando se incluye OPT en el entrenamiento. Aunque todos los experimentos se realizaron en condiciones bastante similares, podrían ser necesarios ajustes más detallados, como la tasa de aprendizaje, al afinar finamente el modelo de lenguaje. A continuación, se examinarán los resultados, excluyendo los modelos en los que se incluye OPT en el entrenamiento.
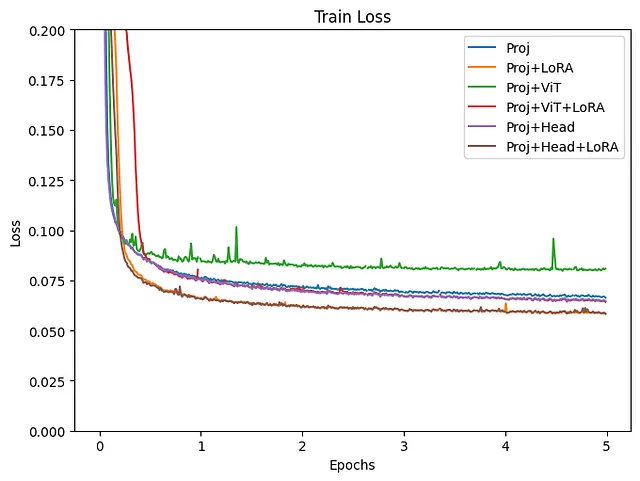
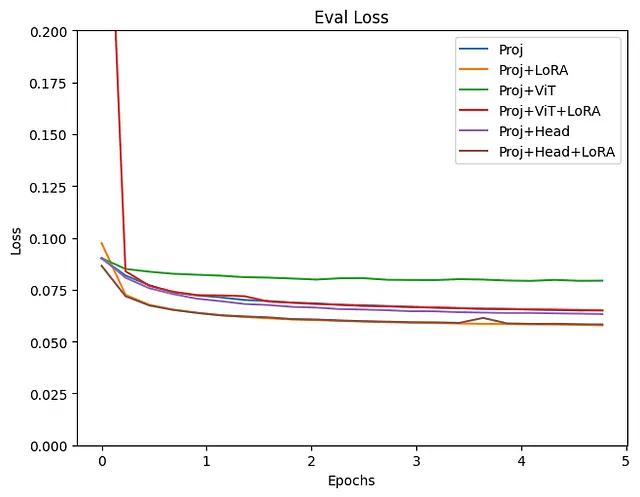
Tanto la pérdida de entrenamiento como la de validación disminuyeron más con el modelo de Proyección+LoRA. El ajuste fino de la capa final de Head mostró resultados casi idénticos. Si también se entrena ViT, la pérdida parece ligeramente mayor y los resultados parecen inestables. Incluso cuando se agrega LoRA durante el entrenamiento de ViT, la pérdida tiende a ser alta. Para el ajuste fino con estos datos, parece que usar un modelo preentrenado de ViT sin actualizar sus parámetros produce resultados más estables. La efectividad de LoRA ha sido reconocida en varios lugares, y es evidente a partir de este experimento que agregar LoRA al LLM mejoró tanto la pérdida de entrenamiento como la de validación.
Revisando los resultados de inferencia en algunos datos de prueba:

Cuando se entrena OPT en sí mismo, los resultados son tan pobres como el resultado de pérdida, dejando al modelo sin palabras. Además, cuando se entrena ViT, la salida tiene sentido semántico, pero describe algo completamente diferente a la imagen dada. Sin embargo, los demás resultados parecen capturar las características de las imágenes en cierta medida. Por ejemplo, la primera imagen menciona “gato” y “banana”, y la segunda identifica “señal de tráfico”. Al comparar los resultados con y sin LoRA, este último tiende a usar palabras similares repetidamente, pero usar LoRA parece hacerlo ligeramente más natural. El entrenamiento de la capa Head produce resultados intrigantes, como usar “jugar” en lugar de “comer” para la primera imagen. Si bien hay algunos elementos poco naturales en estos resultados, se puede deducir que el entrenamiento fue exitoso en la captura de las características de la imagen.
Experimento 2: Comparación de Modelos a Escala de Billones
Para las condiciones de ajuste fino en los experimentos anteriores, se utilizó un modelo de lenguaje ligeramente más pequeño, OPT-350m. Ahora, la intención es cambiar el modelo de lenguaje a un modelo de 7B. No solo conformándose con OPT, también se introducirán LLMs más fuertes, LLaMA y MPT.
La integración de estos dos modelos se puede hacer de manera similar a OPT. Refiriéndose a las funciones forward de LlamaModel y MPTModel, se combinan los vectores de imagen proyectados con los tokens de texto y se cambia la máscara de Máscara de Atención Causal a la Máscara de Atención de GIT. Una cosa a tener en cuenta: para MPT, la máscara no es (0, -inf), sino (False, True). Los procesos posteriores se pueden implementar de manera similar.
Para usar el modelo de clase 7B con OPT, simplemente cambie el nombre del modelo de facebook/opt-350m a facebook/opt-6.7b.
Para LLaMA, con la disponibilidad de LLaMA2, ese será el modelo de elección. Para usar este modelo preentrenado, se necesitan aprobaciones tanto de Meta como de Hugging Face. Se requiere una cuenta para Hugging Face, así que asegúrese de configurarla. Las aprobaciones suelen llegar en unas pocas horas. Después, inicie sesión en Hugging Face en la terminal donde se ejecuta el entrenamiento.
huggingface-cli loginPuede iniciar sesión utilizando el token creado en la cuenta de Hugging Face → Configuración → Token de Acceso.
Los parámetros de entrenamiento se mantienen consistentes, utilizando el conjunto de datos COCO y durando 3 épocas. Según los resultados del Experimento 1, los módulos establecidos para el ajuste fino fueron Proyección + LoRA.
Echemos un vistazo a los resultados.
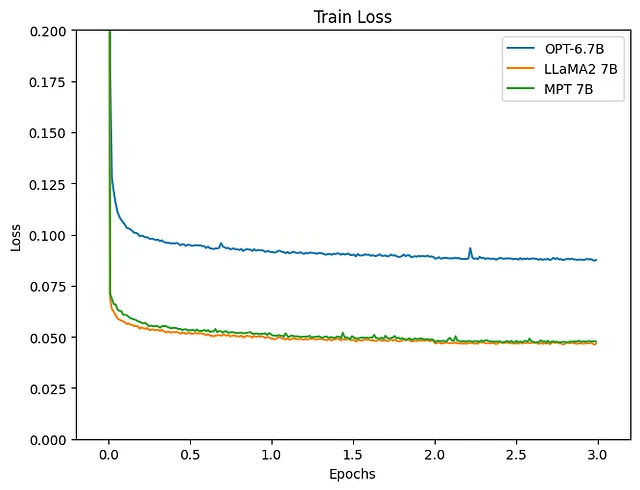
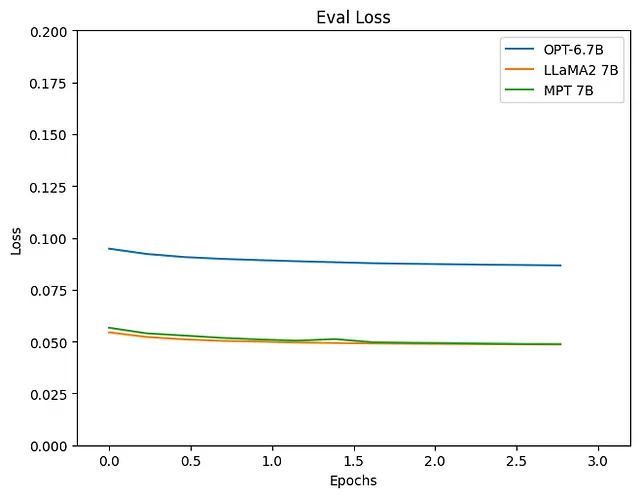
Al revisar la pérdida, es evidente que los modelos que utilizan LLaMA2 y MPT como LLM muestran una reducción más satisfactoria. Veamos también los resultados de inferencia.

En cuanto a la primera imagen, para todos los modelos, las expresiones parecen más naturales en comparación con OPT-350m. No hay expresiones extrañas como “un plátano con un plátano”, lo que resalta la fortaleza de LLM. En la segunda imagen, todavía hay cierta dificultad con frases como “un semáforo” o “un edificio”. Para imágenes tan complejas, podría ser necesario considerar la actualización del modelo ViT.
Finalmente, vamos a ejecutar la inferencia en imágenes que se han vuelto populares con GPT-4.

Aunque se esperaban respuestas fluidas debido al uso de LLM, los resultados son bastante simples. Esto podría deberse a que el modelo fue entrenado únicamente con COCO.
Experimento 3. Aumento de los datos
Dados los resultados poco satisfactorios del experimento anterior, se decidió incorporar datos distintos a COCO para el entrenamiento. El conjunto de datos M3IT actualmente en uso es bastante completo y puede manejar una cantidad significativa de datos en el mismo formato que COCO.
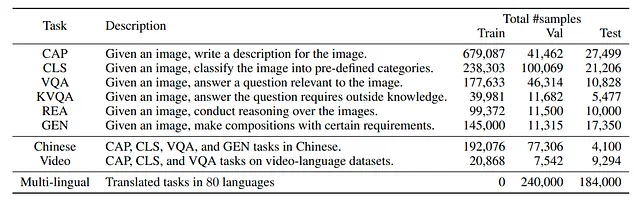
Se pretende utilizar datos de esta fuente excluyendo las categorías “Chino” y “Video”. Originalmente, el conjunto de datos de entrenamiento de COCO contenía 566,747 piezas de datos. Al combinarlo con fuentes adicionales, esto aumentó a 1,361,650. Aunque el tamaño se ha duplicado aproximadamente, se cree que el conjunto de datos se ha vuelto de mayor calidad debido a la mayor diversidad de tareas.
Manejar varios conjuntos de datos de Pytorch se puede lograr fácilmente utilizando ConcatDataset.
dataset_list = [ datasets.load_dataset("MMInstruction/M3IT", i) for i in m3it_name_list]train_dataset = torch.utils.data.ConcatDataset([d["train"] for d in dataset_list])El entrenamiento se realizó durante 1 época y se utilizó el modelo LLaMA2 para el ajuste fino de la Proyección y LoRA, de manera similar al Experimento 2.
Dado que no hay pérdida para comparar en esta ocasión, vamos directamente a los resultados de inferencia.

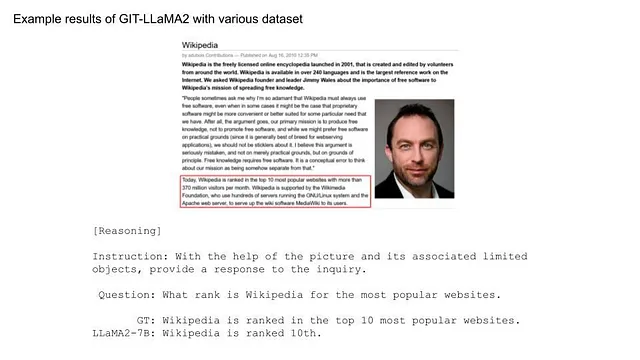

Junto con resolver problemas simples, el modelo ahora maneja desafíos más complejos. Al agregar conjuntos de datos para tareas más complicadas que simplemente describir, las capacidades se han expandido significativamente. Fue sorprendente lograr este nivel de precisión con solo 1 época de entrenamiento.
Probémoslo con la siguiente imagen de ejemplo. Dada la mayor variedad en el conjunto de datos, la forma en que se presentaron las preguntas fue ligeramente modificada.

Aunque la descripción como “Paraguas” aún es extraña, parece que está mejorando. Para mejorar aún más, es necesario aumentar el número de épocas de entrenamiento, agregar más tipos o volúmenes de conjuntos de datos y aprovechar ViT o LLM más poderosos. Sin embargo, es impresionante que tal modelo pudiera ser desarrollado en solo medio día dadas los recursos computacionales y de datos.
Experimento adicional. ¿La imagen se convirtió en palabras?
Echemos otro vistazo a la estructura de GIT.

Como se muestra en la figura, después de la extracción de características por el codificador de visión, las imágenes se tratan al mismo nivel que el texto vectorizado a través de la Proyección Visual. En otras palabras, es posible que la Proyección Visual esté convirtiendo los vectores de imagen en vectores de texto. Se realizó una investigación para ver cómo lucen los vectores después de la Proyección Visual.
Aunque existe la opción de usar la Cabeza para revertir el vector posterior a la proyección a texto, se descubrió que incluso los vectores que se vectorizaron utilizando el módulo de Incrustación no se pudieron revertir a su texto original utilizando este método. Por lo tanto, los vectores que se asemejen de cerca a los vectores de texto antes de ser ingresados en el LLM deben ser asignados como la palabra correspondiente. Todos los tokens registrados en el tokenizador se vectorizaron utilizando el módulo de Incrustación, y se identificó aquel con la mayor similitud coseno como la palabra objetivo.
La imagen utilizada para este experimento es la de un gato.

Ahora, procedamos con el análisis (el análisis completo está disponible aquí). Primero, se vectorizaron todos los tokens registrados.
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")test_dataset = coco_datasets["test"]supervised_test_dataset = SupervisedDataset(model_name, vision_model_name, test_dataset, 256)ids = range(supervised_test_dataset.processor.tokenizer.vocab_size)all_ids = torch.tensor([i for i in ids]).cuda()token_id_to_features = model.model.embed_tokens(all_ids)A continuación, se extrajeron los vectores de imagen que se habrían convertido en palabras mediante ViT y la Proyección.
inputs = supervised_test_dataset[0] # Seleccionando una muestra arbitrariamentepixel_values = inputs["pixel_values"]out_vit = model.model.image_encoder(pixel_values).last_hidden_stateout_vit = model.model.visual_projection(out_vit)Se calcularon los productos punto de estos vectores y los vectores de palabras, y se decodificaron los resultados con el valor máximo como el ID de token relevante.
# Producto punto
nearest_token = out_vit[0] @ token_id_to_features.T
# El índice del valor máximo corresponde al ID del token relevante
visual_out = nearest_token.argmax(-1).cpu().numpy()
# Decodificar el texto
decoded_text = supervised_test_dataset.processor.tokenizer.batch_decode(visual_out)
print(decoded_text)"""['otr', 'eg', 'anto', 'rix', 'Nas', ...]"""
# Como se muestra en el decoded_text impreso, han aparecido algunas palabras desconocidas. Como algunas palabras se repiten, se contaron.
print(pd.Series(decoded_text).value_counts())"""mess 43atura 29せ 10Branch 10Enum 9bell 9worden 7..."""
# Parece que han aparecido una gran cantidad de palabras desconocidas. Dependiendo de la posición, podrían transmitir información significativa. Vamos a mostrar las palabras junto a la imagen del gato.
n_patches = 14
IMAGE_HEIGHT = 468
IMAGE_WIDTH = 640
y_list = np.arange(15, IMAGE_HEIGHT, IMAGE_HEIGHT//n_patches)
x_list = np.arange(10, IMAGE_WIDTH, IMAGE_WIDTH//n_patches)
plt.figure()
plt.axis("off")
plt.imshow(np.array(image), alpha=0.4)
for index in np.arange(n_patches ** 2):
y_pos = index // n_patches
x_pos = index - y_pos * n_patches
y = y_list[y_pos]
x = x_list[x_pos]
# El primer token es el token bos, por lo que se excluye
word = decoded_text[index + 1]
# Para diferenciar las palabras por color
plt.annotate(word, (x, y), size=7, color="blue")
plt.show()
plt.clf()
plt.close()
# Las palabras que aparecen con frecuencia están codificadas por colores. El resultado parece sugerir que no se están proyectando simplemente en palabras significativas. Mientras que la palabra "Cat" podría estar superpuesta en la imagen del gato, dándole cierta relevancia, su significado sigue siendo poco claro.
# Los resultados inconclusos en este experimento podrían deberse a la selección forzada de una palabra con una alta similitud coseno. En cualquier caso, el enfoque no implica simplemente lanzar palabras y crear indicaciones de imagen. Los vectores extraídos de las imágenes se convierten mediante Visual Projection en vectores en el espacio de tokens, que parecen tener cierta similitud en el significado, funcionando como indicaciones misteriosas. Tal vez sea mejor no profundizar más en esto.
# Conclusión
En esta publicación de blog técnico, presenté el método de integrar LLMs en el modelo de lenguaje visual, GIT. Además, se realizaron diversos experimentos utilizando los modelos desarrollados. Si bien hubo éxitos y fracasos, me gustaría seguir realizando experimentos con modelos de lenguaje visual para acumular conocimientos. Por favor, considere este artículo como una referencia y siéntase animado a crear sus propios modelos de lenguaje visual y explorar su potencial.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 Puntos Clave en IA Generativa (2024)
- Las 10 mejores empresas de ciencia de datos en Estados Unidos
- Top 10 Automatización de IA para Aumentar tu Productividad
- Empezando con Scikit-learn en 5 Pasos
- Introducción a la Reidentificación de Personas
- ¿Qué es un Sistema de Producción en IA? Ejemplos, Funcionamiento y Más
- Investigadores de la Universidad de Pensilvania presentan Kani un marco de inteligencia artificial de código abierto, ligero, flexible y agnóstico al modelo para construir aplicaciones de modelos de lenguaje.





