Cómo construir y gestionar una cartera de activos de datos
Construcción y gestión de una cartera de activos de datos
Un enfoque paso a paso
Los activos de datos (o productos) – un conjunto de datos o información preparada que se consume fácilmente para un conjunto de casos de uso identificados – son la tendencia en el mundo de la gestión de datos. Ser capaz de identificar, construir y gobernar un producto de datos individual es una cosa, pero ¿cómo abordar esto a nivel empresarial? ¿Dónde empezar?
Los líderes de habilitación de datos, y específicamente los Directores de Datos Principales, luchan con este desafío de movilización. En este punto de vista, discutiremos cómo se puede adoptar un enfoque de cartera para los activos de datos. La Figura 1 a continuación presenta el enfoque paso a paso, y el resto de este artículo desarrollará los 7 pasos. A lo largo del artículo, explicamos tanto el enfoque como la metodología, mezclando ejemplos a medida que avanzamos.
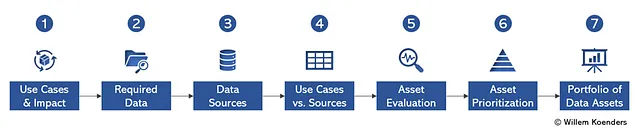
En varios ejemplos de la vida real he seguido este enfoque, pero para evitar cualquier sospecha de que los datos provienen de algún cliente en particular, al mismo tiempo que muestro cómo se puede utilizar la IA generativa de manera efectiva cuando se solicita correctamente, he utilizado ChatGPT 4.0 para generar los ejemplos. La conversación completa está disponible aquí.
Paso 1: Casos de uso e impacto
El primer paso es identificar los casos de uso impulsados por datos que son importantes para su organización. No tiene que hacer esto para toda la empresa de una vez: puede comenzar con un dominio o línea de negocio, e incluso se recomienda hacerlo de esta manera.
- Usando React para construir interfaces interactivas para emocionantes conjuntos de datos
- Conoce a Baichuan 2 Una serie de modelos de lenguaje multilingües a gran escala que contienen 7B y 13B de parámetros, entrenados desde cero, con 2.6T tokens.
- Desbloqueando LangChain y Flan-T5 XXL | Una guía para consultas eficientes de documentos
Los casos de uso son los mecanismos específicos a través de los cuales se puede implementar la estrategia organizativa general. La estrategia de datos y la gobernanza de datos no generan valor en sí mismas, solo lo hacen en la medida en que se logren los objetivos estratégicos más amplios. Por lo tanto, los casos de uso deben ser el primer paso.
Hay varias formas de hacer esto. Puede construir internamente un inventario de casos de uso entrevistando a líderes empresariales y de análisis. Para su sector, puede recopilar un resumen de casos de uso de fuentes externas. Por lo general, se obtiene más éxito con un enfoque híbrido: traer una lista externa de casos de uso y luego refinar esta lista con líderes internos.
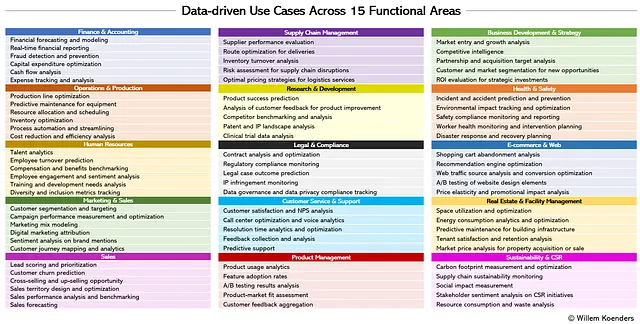
Como se explicó anteriormente, para los fines de este artículo, he utilizado ChatGPT 4.0 para construir el inventario, que se presenta en la Figura 2 a continuación. Por ejemplo, en Finanzas y Contabilidad, el caso de uso de detección y prevención de fraudes utiliza análisis en tiempo real y modelos de aprendizaje automático en una combinación de datos de clientes y transacciones para reconocer patrones e identificar eventos sospechosos. O en Marketing y Ventas, como parte del modelado de la mezcla de marketing, se investiga la relación histórica entre los esfuerzos de marketing y el rendimiento de ventas para optimizar la asignación de presupuestos de marketing y el uso de canales y tácticas.
Tener los casos de uso no es suficiente: necesitamos tener una idea de cuán importantes son. Hay 4 formas críticas en las que los casos de uso pueden generar valor:
- Aumentar los ingresos
- Reducir los costos
- Mejorar la experiencia del cliente
- Mitigar el riesgo
Algunas listas mencionan “impulsar la innovación” como un quinto impulsor de valor, pero en mi opinión eso es solo una cuestión de tiempo, porque cualquier innovación en sí misma eventualmente genera valor a través de los 4 mecanismos mencionados anteriormente.
Ahora, en la Figura 3, tenemos una visión general de los casos de uso relacionados con el marketing y el “impacto en la línea superior” típico asociado con ellos. De hecho, para el caso de uso del modelado de la mezcla de marketing (“MMM”) que acabamos de presentar, vemos un “impacto en la línea superior del 1 al 2%”. Si su empresa tuviera un promedio de $1 mil millones en ingresos, estas estimaciones sugieren que el modelado de la mezcla de marketing puede generar $10-20 millones adicionales.

Al final del paso 1, tienes un conjunto de casos de uso junto con su impacto estimado en la organización.
Paso 2: Datos requeridos
En este paso, investigamos qué datos se necesitan para alimentar los casos de uso identificados. El primer paso es definir cuáles son las entradas de datos críticas para los casos de uso. Por ejemplo, para la optimización de la línea de productos en Operaciones, los datos requeridos incluyen datos de volumen de producción, registros de rendimiento de máquinas y disponibilidad de materia prima. O para la predicción de la rotación de empleados en Recursos Humanos, se requieren datos de encuestas de satisfacción de empleados, retroalimentación de entrevistas de salida y tasas de rotación en la industria.
Una vez que tienes una lista parcial o completa de casos de uso, los respectivos expertos en la materia o propietarios de procesos pueden ayudar a aclarar qué datos se necesitan. A medida que tu lista de entradas de datos críticas crece, llegarás a un punto en el que podrás comenzar a agrupar los datos en tipos o dominios de datos. Dentro de los sectores, y en menor medida incluso entre sectores, estos tipos y dominios de datos son bastante estables. Los dominios de datos que casi siempre son aplicables incluyen Cliente (o equivalente al cliente, como estudiante, paciente o miembro), Empleado y Finanzas, ya que la mayoría de las organizaciones sirven a algún grupo de personas, tienen empleados para hacerlo y necesitan administrar sus presupuestos. Otros dominios, como Cadena de Suministro o Datos de Investigación y Seguridad, son más específicos y solo pueden aplicarse si la organización gestiona una cadena de suministro física de productos y materiales.
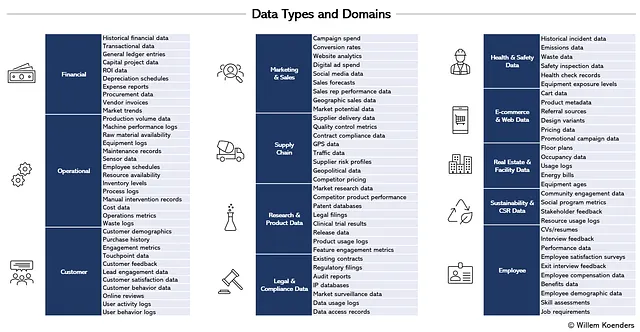
La Figura 4 muestra cómo podría ser el resultado. Allí se presentan 12 dominios de datos con aproximadamente 100 subdominios. Todos los datos de la organización se pueden asignar a los tipos que se enumeran aquí. Por ejemplo, los datos de Gasto en Campañas en Marketing y Ventas pueden incluir datos sobre las iniciativas y costos de publicidad digital, campañas de medios tradicionales y patrocinios, y los Datos de Sensores en Operaciones pueden incluir datos de sensores de temperatura colocados en áreas de almacenamiento y sensores de vibración para monitorear la salud de las máquinas en las fábricas.
Una vez que comienzas a identificar las entradas de datos críticas para los casos de uso y a asignar esas entradas de datos críticas a tipos o dominios de datos, puedes comenzar a construir una matriz como en la Figura 5. En la figura anterior, tuvimos el ejemplo de caso de uso de optimización de la línea de productos, que se asigna al dominio de datos Operacionales, ya que de hecho requiere datos operacionales. En la Figura 5, los casos de uso se asignan a los dominios de datos más amplios para permitir su visualización aquí, pero en la vida real, podrías (y deberías) asignar los casos de uso a los subdominios más granulares subyacentes.
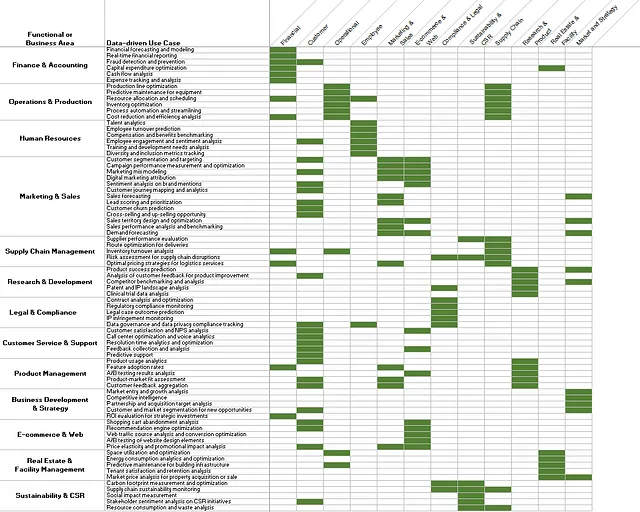
Una comprensión panorámica de esto, los casos de uso clave asignados a los tipos de datos que requieren como entradas, ya es invaluable para desarrollar una estrategia de datos y priorizar dominios de datos específicos… pero vamos a llevar esto mucho más lejos y hacerlo aún más práctico.
Paso 3: Fuentes de datos
Antes de dar el paso de identificar los sistemas fuente en función de los requisitos de datos (lógicos) del Paso 2, analicemos un grupo de casos de uso y evaluemos los datos que requieren. La Figura 6 a continuación muestra una descripción general de los casos de uso de Marketing y Ventas y los datos críticos en los que se basan. Esto está en línea con lo que se muestra en la Figura 5, pero a un nivel de granularidad más alto.
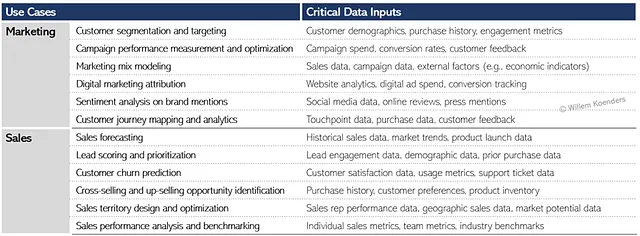
Por ejemplo, vemos que para el primer caso de uso de segmentación y focalización de clientes se necesita información sobre la demografía del cliente. Para la empresa en cuestión, esos datos se almacenan en un sistema físico llamado Global CRM. De manera similar, los datos de Historial de Compras que necesita el mismo caso de uso se almacenan en dos sistemas: Historial de Transacciones de Comercio Electrónico y Sistema de Punto de Venta Minorista.
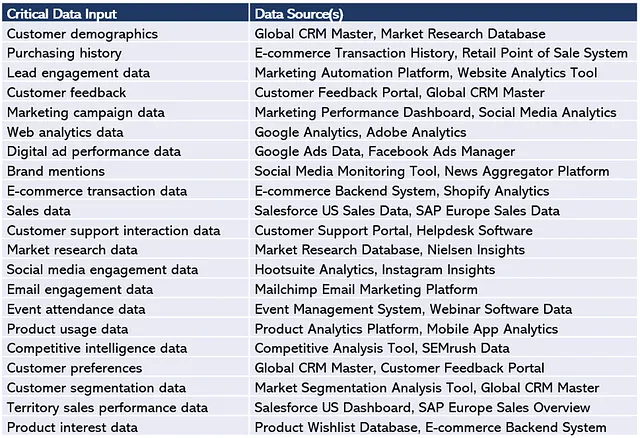
Y así sucesivamente. Si tomamos todas las entradas de datos críticos de la Figura 6 anterior e identificamos los sistemas de origen, obtenemos la tabla de la Figura 7. Como puedes ver, algunas fuentes de datos contienen múltiples tipos de datos críticos. Por ejemplo, Global CRM Master contiene Datos Demográficos del Cliente, pero también Preferencias del Cliente, Retroalimentación del Cliente y Datos de Segmentación del Cliente.
Paso 4: Casos de Uso vs Sistemas de Origen
Identificamos los datos requeridos para los casos de uso (Paso 2) y luego los mapeamos frente a los sistemas de origen (Paso 3). La siguiente vista que se puede crear ahora es el mapeo de casos de uso frente a los sistemas de origen, que para Marketing y Ventas se muestra en la Figura 8 a continuación.
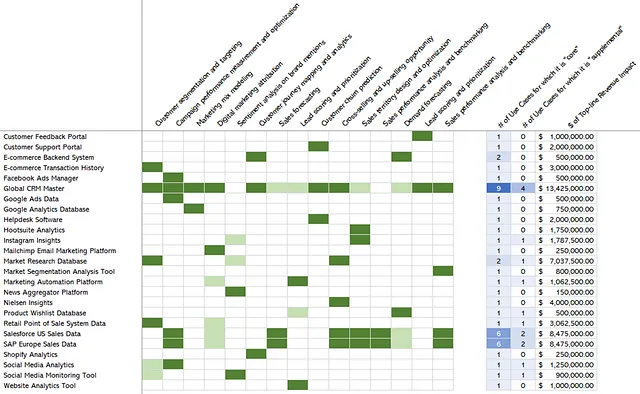
Aquí, el verde oscuro significa que los datos son críticos para el caso de uso, y el verde claro significa que es ‘agradable de tener’ o de apoyo. Por ejemplo, para la segmentación y focalización de clientes, los datos de Global CRM Master son críticos, pero los datos de Análisis de Redes Sociales son ‘agradables de tener’.
Pero ya sabemos mucho más sobre los casos de uso. De hecho, en el Paso 1 anterior, lo primero que hicimos fue identificar los casos de uso y los ingresos incrementales que estos casos de uso podrían generar. Esto ahora nos permite decir algo sobre la creación de valor que depende de fuentes de datos específicas. Porque si sabemos que un conjunto de datos dado es crítico para 3 casos de uso que respectivamente se estima que generarán 2, 3 y 5 millones de dólares en ingresos incrementales, podemos afirmar que 10 millones de dólares en ingresos dependen de este conjunto de datos.
No puedes completar este ejercicio de forma aislada, necesitarás involucrar a los respectivos expertos y propietarios de casos de uso y procesos comerciales. Puede llevar algún tiempo identificar a estas personas, pero una vez que las encuentres, generalmente las encontrarás cooperativas porque tienen un interés en asegurarse de que el caso de uso sea exitoso y, por lo tanto, aclarar qué datos son críticos y el impacto que pueden generar.
A medida que avanzas, puedes comenzar a construir una visión general como se muestra en el lado derecho de la Figura 8, donde se estima el impacto de los ingresos totales en todas las fuentes de datos críticos para los casos de uso de Marketing y Ventas. Ten cuidado aquí para evitar la doble contabilización y asegúrate de explicar y calificar los números de manera apropiada; por ejemplo, si un caso de uso dado con un potencial de creación de valor de $1 millón depende de 2 fuentes de datos, no puedes decir que las dos fuentes de datos juntas generan $2 millones.
Paso 5: Evaluación de Activos
En el paso anterior, mapeamos casos de uso y el valor que generan en relación a un conjunto de fuentes de datos. Ahora sabemos que estas fuentes de datos (pueden) generar valor, lo que significa que tienen un valor inherente para la empresa y, por lo tanto, se pueden considerar activos de datos.
Aunque la Figura 8 ya es muy reveladora, aún no nos permite priorizar ciertos activos de datos (y la inversión en ellos) sobre otros. Si un determinado activo de datos puede generar mucho valor, pero ya está en su lugar y es “adecuado para el propósito”, es posible que no se necesite ninguna otra acción.
La Figura 9 presenta cuatro estados de evaluación de activos de datos, que van desde “adecuado para el propósito” hasta “faltante o grandes brechas”, que permiten una evaluación consistente de los activos de datos. Aquí, “adecuado para el propósito” debe interpretarse ampliamente. En el extremo positivo del espectro, significa que los datos correctos están fácilmente disponibles, en la granularidad y puntualidad adecuadas; tienen una alta calidad y confiabilidad, y el sistema fuente nunca está inactivo. En el otro extremo, significa que o bien el activo de datos no está en absoluto o, si lo está, los datos son enormemente deficientes, poco confiables y/o incompletos.

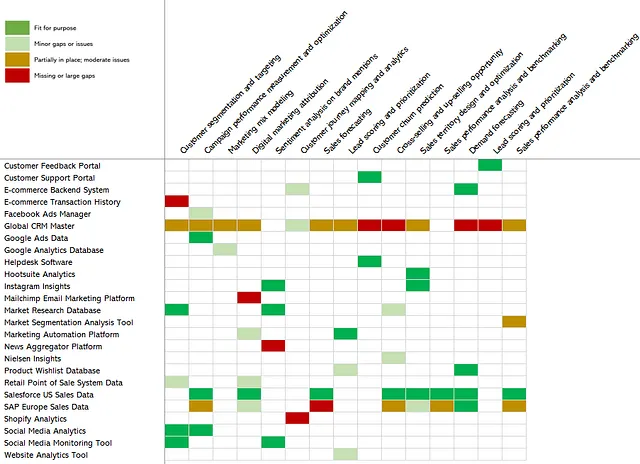
Ahora tenemos las herramientas que necesitamos para construir un mapa de calor, donde las “áreas calientes” (es decir, las partes rojas o ámbar) señalan oportunidades para la creación de valor, porque ahí es donde los casos de uso no pueden depender de los datos que necesitan críticamente, consulte la Figura 10 a continuación.
Paso 6: Priorización de activos
El siguiente paso es priorizar los activos de datos en base a todo lo que ahora sabemos sobre ellos. La Figura 11 presenta el mismo mapa de calor que teníamos en la Figura 10, pero agregué de vuelta el impacto en los ingresos y el número de casos de uso dependientes. Luego reorganicé los activos de datos, ordenándolos en orden descendente según el impacto total en los ingresos que generan.
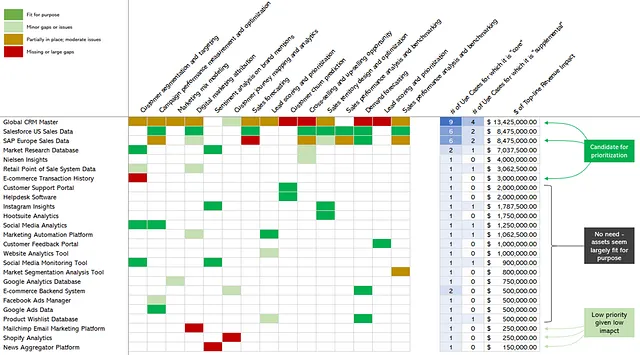
Ahora queda más claro qué activos de datos podrían priorizarse para mejoras e inversiones. Por ejemplo, está claro que el Global CRM Master es un gran problema, ya que no está alimentando de manera óptima a 9 (!) casos de uso, con un impacto de más de $13 millones. Varios activos de datos, como Instagram Insights, Customer Support Portal y Google Ads Data, son adecuados para el propósito y, por lo tanto, no parecen requerir remedios. Y luego tenemos algunos en la parte inferior, como Shopify Analytics y News Aggregator Platform, que pueden no estar en su lugar, pero que solo admiten 1 caso de uso cada uno, con un impacto limitado.
Si usted fuera un Director de Datos y este panorama reflejara los activos de datos y los casos de uso de su organización para un dominio determinado, se abriría un camino impulsado por el impacto. Existe una clara oportunidad para tomar uno o dos activos de datos y utilizarlos como una ubicación estratégica para mejorar la gobernanza de los datos estratégicamente importantes. Esto se puede utilizar para incorporar y operacionalizar varias capacidades de gobernanza de datos, como la propiedad y el mantenimiento de datos, la gestión de metadatos y la calidad de los datos, porque cada uno de ellos es fundamental para garantizar que los activos de datos estén gobernados adecuadamente.
Paso 7: Portafolio de Activos de Datos
Es un hecho comúnmente citado que la duración esperada de los líderes de datos, como los Directores de Datos, es corta, en promedio menos de 2.5 años. En gran medida, esto se explica por el hecho de que los CDO luchan por lograr un impacto empresarial significativo a corto plazo.
Es precisamente por eso que el enfoque descrito en este punto de vista es tan poderoso: si priorizas los activos de datos utilizando la lógica presentada en los pasos 1-6, casi garantizas generar un impacto. Y al comenzar con casos de uso y su impacto, involucras al negocio y a las áreas funcionales desde el principio, evitando así caer en la trampa de “hacer datos por el mero hecho de hacerlos”, lo que evitará la percepción de que la gobernanza de datos es un costo y un obstáculo para el negocio.
No has terminado aquí. Los activos de datos que has identificado son análogos a las propiedades en una cartera de bienes raíces: debes administrarlos activamente, asegurándote de mantenerlos actualizados, de que los usuarios de datos sigan satisfechos, de incorporar nuevos requisitos a medida que surgen, y de que la generación de valor no se asuma, sino que se rastree explícitamente a lo largo del tiempo.
La Figura 12 a continuación muestra el tablero de control de la cartera de activos de datos para la organización que analizamos en este punto de vista. Muestra el número de activos de datos que han sido certificados, el número de casos de uso mapeados y el valor creado a través de ingresos incrementales y mitigación de riesgos.
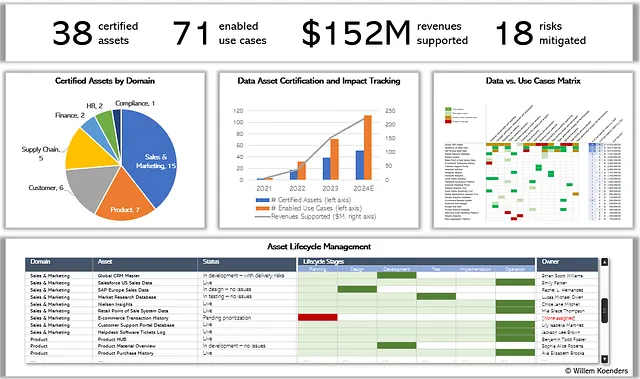
En el centro, se muestra un gráfico que sigue el número de activos de datos certificados a lo largo del tiempo y, lo que es más importante, el número de casos de uso habilitados y el impacto asociado expresado en ingresos. Esto es clave para la longevidad de la carrera de CDO, para poder demostrar el valor que se crea a través de la habilitación de datos dirigida y las actividades de gobernanza.
En la parte inferior, puedes ver una vista de pipeline de los activos de datos. Algunos de ellos están siendo impulsados a través de un ciclo de activación estructurado, mientras que otros ya están en funcionamiento. Verás que el CRM Global Master que investigamos anteriormente ha sido priorizado — actualmente se encuentra en la fase de “desarrollo”.
Anécdota del mercado
Como se mencionó al principio de este punto de vista, he utilizado y refinado este enfoque trabajando con varias empresas en Europa y Estados Unidos, y en los sectores bancario, de seguros, minorista, tecnología y manufactura.
En un ejemplo en el sector manufacturero, seguimos una versión ligeramente modificada de los 7 pasos descritos aquí. Dado que era una empresa compleja y global, no era factible identificar casos de uso en toda la organización. En su lugar, elegimos un dominio empresarial como nuestro enfoque principal, en este caso la división comercial, y luego los subdominios de marketing y ventas (similar al alcance de los casos de uso en el paso 3 anterior).
Identificamos un conjunto de ~30 casos de uso, la mayoría de los cuales ya habían sido definidos para otros fines. Ejecutamos una versión ligera y acelerada de los pasos 2-4, para identificar los datos requeridos y las fuentes correspondientes, y mapear los casos de uso con las fuentes. Pasamos al paso 5 y nos involucramos con los propietarios y expertos en casos de uso, preguntándoles si tenían acceso a los datos correctos y adecuados para el propósito. Si no era así, ¿qué datos o fuente faltaban, cuál era el problema?
Bastante rápido, nos decidimos por un conjunto de 8 casos de uso que tenían dificultades en cuanto a los datos que necesitaban, y descubrimos que 2 fuentes de datos específicas eran un problema para 6 de los 8 casos de uso. No profundizamos más, y nos pusimos a trabajar. Junto con el equipo central de datos y el equipo comercial, nos alineamos en los propietarios de las 2 fuentes de datos, las evaluamos según un conjunto de criterios de certificación formales, y redactamos un plan para abordar las brechas.
Al cabo de unos meses, se mejoró y certificó el primer activo de datos para satisfacer las necesidades de los casos de uso documentados. En el momento de escribir esto, el impacto exacto aún no se había medido (ya que lleva tiempo que el impacto se haga realidad), pero las pruebas anecdóticas iniciales sugieren que la efectividad del marketing puede haber aumentado en cifras de dos dígitos altos o incluso dobles. En cualquier caso, el CDO en cuestión pudo introducir y refinar el enfoque, obtener una victoria modesta y poner en marcha una hoja de ruta más amplia con activos adicionales, casos de uso y dominios.
¡Buena suerte!
Crear y gestionar un portafolio de datos no es necesariamente fácil ni rápido, pero vale la pena el esfuerzo. Espero que los pasos descritos aquí te sean útiles. Me encantaría saber cómo te va, así que si tienes comentarios o historias propias para compartir, no dudes en dejarlos en los comentarios.
¡Buen viaje en tu viaje de habilitación de activos de datos!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Por qué y qué es la ingeniería de características en el aprendizaje automático?
- Guía de Ingeniería 101 Zero, One y Prompting de Pocas Muestras
- ¿Qué significa cuando el aprendizaje automático comete un error?
- Diseñando ciudades resilientes en Arup utilizando las capacidades geoespaciales de Amazon SageMaker
- ¿Cómo puedes mejorar tus métricas y proceso de pronóstico sin algoritmos sofisticados?
- Depuración y Mejora de las Respuestas de ChatGPT 🧐
- Utilizando datos e inteligencia artificial para rastrear el progreso hacia los Objetivos Globales de las Naciones Unidas






