Construyendo un Agente Conversacional con un Microservicio de Memoria con OpenAI y FastAPI
Construcción de un Agente Conversacional con OpenAI y FastAPI
Una conversación llena de recuerdos, Foto de Juri Gianfrancesco en Unsplash.
Creando agentes conversacionales contextualmente conscientes: Un análisis profundo de la integración de OpenAI y FastAPI
Introducción
En este tutorial, exploraremos el proceso de creación de un Agente Conversacional con un microservicio de memoria utilizando OpenAI y FastAPI. Los Agentes Conversacionales se han convertido en un componente crucial en diversas aplicaciones, incluyendo atención al cliente, asistentes virtuales y sistemas de recuperación de información. Sin embargo, muchas implementaciones tradicionales de chatbots carecen de la capacidad de retener el contexto durante una conversación, lo que resulta en capacidades limitadas y frustrantes experiencias de usuario. Esto es especialmente desafiante al construir servicios de agentes siguiendo una arquitectura de microservicios.
El enlace al repositorio de GitHub se encuentra al final del artículo.
Motivación
La motivación detrás de este tutorial es abordar la limitación de las implementaciones tradicionales de chatbots y crear un Agente Conversacional con un microservicio de memoria, lo cual se vuelve especialmente crucial al implementar agentes en entornos complejos como Kubernetes. En Kubernetes u otros sistemas de orquestación de contenedores similares, los microservicios están sujetos a reinicios, actualizaciones y operaciones de escalamiento frecuentes. Durante estos eventos, el estado de la conversación en los búferes tradicionales para chatbots se perdería, lo que resultaría en interacciones fragmentadas y pobres experiencias de usuario.
Al construir un Agente Conversacional con un microservicio de memoria, podemos asegurarnos de que el contexto crucial de la conversación se preserve incluso frente a reinicios o actualizaciones del microservicio o cuando las interacciones no son continuas. Esta preservación del estado permite que el agente retome las conversaciones donde las dejó, manteniendo la continuidad y brindando una experiencia de usuario más natural y personalizada. Además, este enfoque se alinea con las mejores prácticas de desarrollo de aplicaciones modernas, donde los microservicios en contenedores a menudo interactúan con otros componentes, lo que convierte al microservicio de memoria en una adición valiosa a la arquitectura del agente conversacional en tales configuraciones distribuidas.
Para este proyecto, trabajaremos principalmente con las siguientes tecnologías y herramientas:
OpenAI GPT-3.5: Aprovecharemos el modelo de lenguaje GPT-3.5 de OpenAI, que es capaz de realizar diversas tareas de procesamiento de lenguaje natural, incluyendo generación de texto, gestión de conversaciones y retención de contexto. Necesitaremos generar una clave de API de OpenAI, asegúrate de visitar esta URL para administrar tus claves.
FastAPI: FastAPI servirá como el soporte de nuestra microservicio, proporcionando la infraestructura para manejar solicitudes HTTP, gestionar estados de conversación e integrarse con la API de OpenAI. FastAPI es excelente para construir microservicios con Python.
El Ciclo de Desarrollo
En esta sección, profundizaremos en el proceso paso a paso de construir nuestro Agente Conversacional con un microservicio de memoria. El ciclo de desarrollo incluirá:
Configuración del Entorno: Crearemos un entorno virtual e instalaremos las dependencias necesarias, incluyendo la biblioteca de Python de OpenAI y FastAPI.
Diseño del Microservicio de Memoria: Delimitaremos la arquitectura y el diseño del microservicio de memoria, que será responsable de almacenar y gestionar el contexto de la conversación.
Integración de OpenAI: Integraremos el modelo GPT-3.5 de OpenAI en nuestra aplicación y definiremos la lógica para procesar mensajes de usuario y generar respuestas.
Para esta configuración, utilizaremos la siguiente estructura para construir el microservicio. Esto es conveniente para expandir otros servicios dentro del mismo proyecto, y personalmente me gusta esta estructura.
├── Dockerfile <--- Contenedor├── requirements.txt <--- Bibliotecas y Dependencias├── setup.py <--- Construir y distribuir microservicios como paquetes de Python└── src ├── agents <--- Nombre de tu Microservicio │ ├── __init__.py │ ├── api │ │ ├── __init__.py │ │ ├── routes.py │ │ └── schemas.py │ ├── crud.py │ ├── database.py │ ├── main.py │ ├── models.py │ └── processing.py └── agentsfwrk <--- Nombre de tu Marco Común ├── __init__.py ├── integrations.py └── logger.py
Necesitaremos crear en el proyecto una carpeta llamada src que contendrá el código Python para los servicios; en nuestro caso, agents contiene todo el código asociado con nuestros agentes conversacionales y la API, y agentsfwrk es nuestro marco común para su uso en todos los servicios.
El archivo Dockerfile contiene las instrucciones para construir la imagen, una vez que el código esté listo, el archivo requirements.txt contiene las bibliotecas a utilizar en nuestro proyecto y el archivo setup.py contiene las instrucciones para construir y distribuir nuestro proyecto.
Por ahora, simplemente crea las carpetas de los servicios junto con los archivos __init__.py y agrega lo siguiente al archivo requirements.txt y setup.py en la raíz del proyecto, deja el archivo Dockerfile vacío, ya que volveremos a él en la sección de Ciclo de Despliegue.
# Requirements.txtfastapi==0.95.2ipykernel==6.22.0jupyter-bokeh==2.0.2jupyterlab==3.6.3openai==0.27.6pandas==2.0.1sqlalchemy-orm==1.2.10sqlalchemy==2.0.15uvicorn<0.22.0,>=0.21.1
# setup.pyfrom setuptools import find_packages, setupsetup( name = 'conversational-agents', version = '0.1', description = 'microservices for conversational agents', packages = find_packages('src'), package_dir = {'': 'src'}, # Esto es opcional por cierto author = 'XXX XXXX', author_email = '[email protected]', maintainer = 'XXX XXXX', maintainer_email = '[email protected]',)
Activa el entorno virtual y ejecuta pip install -r requirements.txt en la terminal. Aún no ejecutaremos el archivo de configuración, así que pasemos a la siguiente sección.
Diseñando el Marco Común
Diseñaremos nuestro marco común para poder utilizarlo en todos los microservicios construidos en el proyecto. Esto no es estrictamente necesario para proyectos pequeños, pero pensando en el futuro, puedes expandirlo para utilizar múltiples proveedores de LLM, agregar otras bibliotecas para interactuar con tus propios datos (por ejemplo, LangChain, VoCode) y otras capacidades comunes como servicios de voz e imagen, sin necesidad de implementarlos en cada microservicio.
Crea la carpeta y los archivos siguiendo la estructura de agentsfwrk. Cada archivo y su descripción se encuentran a continuación:
└── agentsfwrk <--- Nombre de tu Marco Común ├── __init__.py ├── integrations.py └── logger.py
El archivo de registro es una utilidad muy básica para configurar un módulo de registro común, y puedes definirlo de la siguiente manera:
import loggingimport multiprocessingimport sysAPP_LOGGER_NAME = 'CaiApp'def setup_applevel_logger(logger_name = APP_LOGGER_NAME, file_name = None): """ Configura el registro para la aplicación """ logger = logging.getLogger(logger_name) logger.setLevel(logging.DEBUG) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") sh = logging.StreamHandler(sys.stdout) sh.setFormatter(formatter) logger.handlers.clear() logger.addHandler(sh) if file_name: fh = logging.FileHandler(file_name) fh.setFormatter(formatter) logger.addHandler(fh) return loggerdef get_multiprocessing_logger(file_name = None): """ Configura el registro para la aplicación para multiprocessing """ logger = multiprocessing.get_logger() logger.setLevel(logging.DEBUG) formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") sh = logging.StreamHandler(sys.stdout) sh.setFormatter(formatter) if not len(logger.handlers): logger.addHandler(sh) if file_name: fh = logging.FileHandler(file_name) fh.setFormatter(formatter) logger.addHandler(fh) return loggerdef get_logger(module_name, logger_name = None): """ Obtiene el registro para el módulo """ return logging.getLogger(logger_name or APP_LOGGER_NAME).getChild(module_name)
A continuación, nuestra capa de integración se realiza a través del módulo de integración. Este archivo actúa como intermediario entre la lógica de los microservicios y OpenAI, y está diseñado para exponer proveedores de LLM de manera común para nuestra aplicación. Aquí, podemos implementar formas comunes de manejar excepciones, errores, reintentos y tiempos de espera en solicitudes o respuestas. Aprendí de un muy buen gerente a siempre colocar una capa de integración entre los servicios/API externos y el mundo interno de nuestra aplicación.
El código de integración se define a continuación:
# integrations.py# Módulo común de proveedor LLMimport jsonimport osimport timefrom typing import Unionimport openaifrom openai.error import APIConnectionError, APIError, RateLimitErrorimport agentsfwrk.logger as loggerlog = logger.get_logger(__name__)openai.api_key = os.getenv('OPENAI_API_KEY')class OpenAIIntegrationService: def __init__( self, context: Union[str, dict], instruction: Union[str, dict] ) -> None: self.context = context self.instructions = instruction if isinstance(self.context, dict): self.messages = [] self.messages.append(self.context) elif isinstance(self.context, str): self.messages = self.instructions + self.context def get_models(self): return openai.Model.list() def add_chat_history(self, messages: list): """ Agrega el historial de chat a la conversación. """ self.messages += messages def answer_to_prompt(self, model: str, prompt: str, **kwargs): """ Recopila sugerencias del usuario, las agrega a los mensajes de la misma conversación y devuelve las respuestas de los modelos gpt. """ # Preservar los mensajes en la conversación self.messages.append( { 'role': 'user', 'content': prompt } ) retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.ChatCompletion.create( model = model, messages = self.messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"El último intento falló, se produjo una excepción: {e}.") return { "answer": "Lo siento, estoy teniendo problemas técnicos." } retry_time = getattr(e, 'retry_after', 3) log.error(f"Se produjo una excepción: {e}. Volviendo a intentar en {retry_time} segundos...") time.sleep(retry_time) response_message = response.choices[0].message["content"] response_data = {"answer": response_message} self.messages.append( { 'role': 'assistant', 'content': response_message } ) return response_data def answer_to_simple_prompt(self, model: str, prompt: str, **kwargs) -> dict: """ Recopila el contexto y agrega una sugerencia de un usuario y devuelve la respuesta del modelo gpt dada una instrucción. Este método solo permite un intercambio de mensajes. """ messages = self.messages + f"\n<Cliente>: {prompt} \n" retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.Completion.create( model = model, prompt = messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"El último intento falló, se produjo una excepción: {e}.") return { "intent": False, "answer": "Lo siento, estoy teniendo problemas técnicos." } retry_time = getattr(e, 'retry_after', 3) log.error(f"Se produjo una excepción: {e}. Volviendo a intentar en {retry_time} segundos...") time.sleep(retry_time) response_message = response.choices[0].text try: response_data = json.loads(response_message) answer_text = response_data.get('answer') if answer_text is not None: self.messages = self.messages + f"\n<Cliente>: {prompt} \n" + f"<Agente>: {answer_text} \n" else: raise ValueError("La respuesta del modelo no es válida.") except ValueError as e: log.error(f"Se produjo un error al analizar la respuesta: {e}") log.error(f"Sugerencia del usuario: {prompt}") log.error(f"Respuesta del modelo: {response_message}") log.info("Devolver una respuesta segura al usuario.") response_data = { "intent": False, "answer": response_message } return response_data def verify_end_conversation(self): """ Verifica si la conversación ha terminado revisando el último mensaje del usuario y el último mensaje del asistente. """ pass def verify_goal_conversation(self, model: str, **kwargs): """ Verifica si la conversación ha alcanzado el objetivo revisando el historial de la conversación. Formatea la respuesta como se especifica en las instrucciones. """ messages = self.messages.copy() messages.append(self.instructions) retry_exceptions = (APIError, APIConnectionError, RateLimitError) for _ in range(3): try: response = openai.ChatCompletion.create( model = model, messages = messages, **kwargs ) break except retry_exceptions as e: if _ == 2: log.error(f"El último intento falló, se produjo una excepción: {e}.") raise retry_time = getattr(e, 'retry_after', 3) log.error(f"Se produjo una excepción: {e}. Volviendo a intentar en {retry_time} segundos...") time.sleep(retry_time) response_message = response.choices[0].message["content"] try: response_data = json.loads(response_message) if response_data.get('summary') is None: raise ValueError("La respuesta del modelo no es válida. Falta un resumen.") except ValueError as e: log.error(f"Se produjo un error al analizar la respuesta: {e}") log.error(f"Respuesta del modelo: {response_message}") log.info("Devolver una respuesta segura al usuario.") raise return response_data
Algunas notas sobre el módulo de integración:
La clave de OpenAI se define como una variable de entorno llamada “OPENAI_API_KEY”, debemos descargar esta clave y definirla en nuestra terminal o utilizando la biblioteca python-dotenv.
Existen dos métodos para integrarse con los modelos GPT, uno para el punto final de chat (answer_to_prompt) y otro para el punto final de completado (answer_to_simple_prompt). Nos enfocaremos en el uso del primero.
Existe un método para verificar el objetivo de una conversación — verify_goal_conversation, que simplemente sigue las instrucciones de los agentes y crea un resumen de ellas.
Diseñando el microservicio de (Memoria)
El mejor ejercicio es diseñar y posteriormente dibujar un diagrama para visualizar lo que el servicio debe hacer, incluyendo los actores y sus acciones al interactuar con él. Comencemos describiendo nuestra aplicación en términos sencillos:
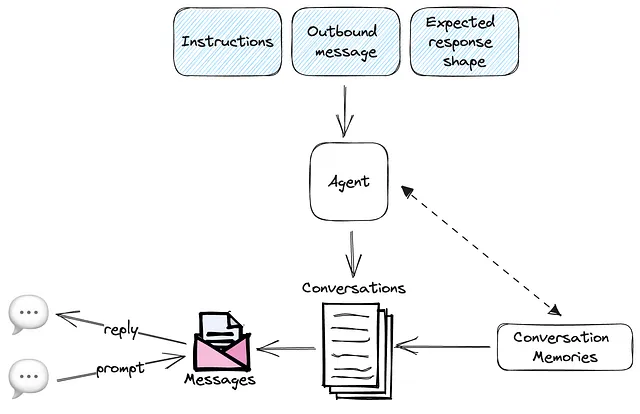
Nuestro microservicio es un proveedor de agentes artificialmente inteligentes, que son expertos en un tema y se espera que tengan conversaciones en respuesta a un mensaje saliente y siguiendo instrucciones.
Nuestros agentes pueden mantener múltiples conversaciones y están equipados con una memoria que debe persistir, lo que significa que deben ser capaces de retener el historial de conversación independientemente de la sesión del cliente que esté interactuando con los agentes.
Los agentes deben recibir, al crearse, instrucciones claras sobre cómo manejar una conversación y responder en consecuencia durante su transcurso.
Para la integración programática, los agentes también deben seguir una estructura de respuesta esperada.
Nuestro diseño se ve así en el siguiente diagrama:
Diseño de Agentes Conversacionales — Imagen por el autor
Con este diagrama sencillo, sabemos que nuestro microservicio necesita implementar métodos que sean responsables de estas tareas específicas:
Creación de agentes y definición de instrucciones
Iniciador de conversaciones y preservación del historial de conversación
Chat con los agentes
Codificaremos estas funcionalidades en su orden, y antes de sumergirnos en eso, construiremos el esqueleto de nuestra aplicación
Esqueleto de la Aplicación
Para comenzar el desarrollo, comenzamos construyendo el esqueleto de la aplicación FastAPI. El esqueleto de la aplicación consiste en componentes esenciales, incluyendo el script principal de la aplicación, la configuración de la base de datos, el script de procesamiento y los módulos de enrutamiento. El script principal sirve como punto de entrada para la aplicación, donde configuramos la instancia de FastAPI.
Archivo Principal
Creemos/abramos el archivo main.py en tu carpeta agents y escribe el siguiente código, que simplemente define un punto de enlace raíz.
from fastapi import FastAPIfrom agentsfwrk.logger import setup_applevel_loggerlog = setup_applevel_logger(file_name = 'agents.log')app = FastAPI()@app.get("/")async def root(): return {"message": "¡Hola usuario de IA conversacional!"}
Configuración de la Base de Datos
Luego, creamos/abrimos el script de configuración de la base de datos llamado database.py, que establece la conexión a nuestra base de datos local para almacenar y recuperar el contexto de la conversación. Comenzaremos utilizando SQLite local por simplicidad, pero siéntete libre de probar otras bases de datos para tu entorno.
Finalmente, definimos módulos de enrutamiento que manejan las solicitudes HTTP entrantes, abarcando puntos finales responsables del procesamiento de las interacciones del usuario. Creemos la carpeta api y crea/abre el archivo routes.py y pega el siguiente código.
from typing import Listfrom fastapi import APIRouter, Depends, HTTPExceptionfrom sqlalchemy.orm import Sessionimport agents.api.schemasimport agents.modelsfrom agents.database import SessionLocal, enginefrom agentsfwrk import integrations, loggerlog = logger.get_logger(__name__)agents.models.Base.metadata.create_all(bind = engine)# Información básica del enrutadorrouter = APIRouter( prefix = "/agents", tags = ["Chat"], responses = {404: {"description": "No encontrado"}})# Dependencia: Utilizada para obtener la base de datos en nuestros puntos finales.def get_db(): db = SessionLocal() try: yield db finally: db.close()# Punto de enlace raíz para el [email protected]("/")async def agents_root(): return {"message": "¡Hola conversational ai!"}
Con esta estructura esquelética, estamos listos para comenzar a codificar la aplicación que diseñamos.
Crear Agentes y Asignar Instrucciones
En esta sección, nos enfocaremos en implementar el endpoint “Crear Agente”. Este endpoint permite a los usuarios iniciar nuevas conversaciones e interactuar con los agentes, proporcionando un contexto y un conjunto de instrucciones para que el agente siga a lo largo del resto de la conversación. Comenzaremos presentando dos Modelos de Datos para este proceso: uno para la Base de Datos y otro para la API. Utilizaremos Pydantic para nuestros modelos de datos. Abre el archivo schemas.py en la carpeta api y define el modelo base del Agente, el modelo de creación del Agente y el modelo de datos del Agente.
from datetime import datetimefrom typing import List, Optionalfrom pydantic import BaseModelclass AgentBase(BaseModel): # <-- Modelo base context: str # <-- El contexto de nuestros agentes first_message: str # <-- Nuestros agentes se acercarán a los usuarios con un primer mensaje. response_shape: str # <-- La forma esperada (para comunicación programática) de la respuesta de la interacción de cada agente con el usuario instructions: str # <-- Conjunto de instrucciones que nuestro agente debe seguir.class AgentCreate(AgentBase): # <-- Modelo de datos para creación passclass Agent(AgentBase): # <-- Modelo de datos del Agente id: str timestamp: datetime = datetime.utcnow() class Config: orm_mode = True
Los campos en el modelo de datos del agente se detallan a continuación:
Contexto: Esto es un contexto general de lo que es el agente.
Primer mensaje: Nuestros agentes están destinados a iniciar una conversación con los usuarios. Puede ser tan simple como “Hola, ¿cómo puedo ayudarte?” o algo como “Hola, solicitaste un agente para ayudarte a encontrar información sobre acciones, ¿es eso correcto?”.
Forma de respuesta: Este campo se utiliza principalmente para especificar el formato de salida de la respuesta de nuestro agente y debe usarse para transformar la salida de texto de nuestro LLM a una forma deseada para la comunicación programática. Por ejemplo, podemos especificar que nuestro agente debe envolver la respuesta en un formato JSON con una clave llamada response, es decir, {'response': "cadena"}.
Instrucciones: Este campo contiene las instrucciones y pautas que cada agente debe seguir durante toda la conversación, como “Recolectar las siguientes entidades [e1, e2, e3, …] durante cada interacción” o “Responder al usuario hasta que ya no esté interesado en la conversación” o “No desviarse del tema principal y llevar la conversación de vuelta al objetivo principal cuando sea necesario”.
Continuamos abriendo el archivo models.py, donde codificaremos nuestra tabla de base de datos que pertenece a la entidad del agente.
Este código es bastante similar al modelo de Pydantic, define la tabla del agente en nuestra base de datos.
Con nuestros dos modelos de datos en su lugar, estamos listos para implementar la creación del Agente. Para esto, comenzaremos modificando el archivo routes.py y agregando el endpoint:
Necesitamos crear una nueva función que reciba un objeto Agente de la solicitud y lo cree en la base de datos. Para esto, crearemos/abriremos el archivo crud.py, que contendrá todas las interacciones con la base de datos (CREAR, LEER, ACTUALIZAR, ELIMINAR).
# crud.pyimport uuidfrom sqlalchemy.orm import Sessionfrom agents import modelsfrom agents.api import schemasdef create_agent(db: Session, agent: schemas.AgentCreate): """ Crea un agente en la base de datos """ db_agent = models.Agent( id = str(uuid.uuid4()), context = agent.context, first_message = agent.first_message, response_shape = agent.response_shape, instructions = agent.instructions ) db.add(db_agent) db.commit() db.refresh(db_agent) return db_agent
Con nuestra función creada, ahora podemos volver al routes.py, importar el módulo crud y usarlo en el método del punto final.
import [email protected]("/create-agent", response_model = agents.api.schemas.Agent)async def create_agent(agent: agents.api.schemas.AgentCreate, db: Session = Depends(get_db)): """ Crea un punto final de agente. """ log.info(f"Creando agente: {agent.json()}") db_agent = agents.crud.create_agent(db, agent) log.info(f"Agente creado con id: {db_agent.id}") return db_agent
Ahora volvamos al archivo main.py y agreguemos el enrutador “agents”. Las modificaciones
Probemos esta funcionalidad. Primero, deberemos instalar nuestros servicios como un paquete de Python, en segundo lugar, iniciar la aplicación en el puerto 8000.
# Ejecutar desde la raíz del proyecto.$ pip install -e .# Comando para ejecutar la aplicación.$ uvicorn agents.main:app --host 0.0.0.0 --port 8000 --reload
Ve a http://0.0.0.0:8000/docs, donde verás la interfaz de usuario de Swagger con el punto final para probar. Envía tu carga útil y verifica la salida.
Punto final create-agent desde Swagger UI — Imagen por el autor
Continuaremos desarrollando nuestra aplicación, pero probar el primer punto final es una buena señal de progreso.
Crear Conversaciones y Conservar el Historial de Conversación
Nuestro próximo paso es permitir que los usuarios interactúen con nuestros agentes. Queremos que los usuarios interactúen con agentes específicos, por lo que deberemos pasar el ID del agente junto con el primer mensaje de interacción del usuario. Realicemos algunas modificaciones en el modelo de datos del Agente para que cada agente pueda tener múltiples conversaciones introduciendo la entidad Conversación. Abre el archivo schemas.py y agrega los siguientes modelos:
class ConversationBase(BaseModel): # <-- base de nuestras conversaciones, deben pertenecer a un agente agent_id: strclass ConversationCreate(ConversationBase): # <-- objeto de creación de conversación passclass Conversation(ConversationBase): # <-- Los objetos de conversación id: str timestamp: datetime = datetime.utcnow() class Config: orm_mode = Trueclass Agent(AgentBase): # <-- Modelo de datos del Agente id: str timestamp: datetime = datetime.utcnow() conversations: List[Conversation] = [] # <-- NOTA: hemos agregado la conversación como una lista de objetos de Conversación. class Config: orm_mode = True
Ten en cuenta que hemos modificado el modelo de datos del Agente y hemos añadido conversaciones a él, esto es para que cada agente pueda tener múltiples conversaciones según lo diseñado en nuestro diagrama.
Debemos modificar nuestro objeto de base de datos e incluir la tabla de conversación en el script del modelo de base de datos. Abrimos el archivo models.py y modificamos el código de la siguiente manera:
# models.pyclass Agent(Base): __tablename__ = "agents" id = Column(String, primary_key = True, index = True) timestamp = Column(DateTime, default = datetime.utcnow) context = Column(String, nullable = False) first_message = Column(String, nullable = False) response_shape = Column(JSON, nullable = False) instructions = Column(String, nullable = False) conversations = relationship("Conversation", back_populates = "agent") # <-- NOTA: Añadimos la relación de conversación a la tabla de agentesclass Conversation(Base): __tablename__ = "conversations" id = Column(String, primary_key = True, index = True) agent_id = Column(String, ForeignKey("agents.id")) timestap = Column(DateTime, default = datetime.utcnow) agent = relationship("Agent", back_populates = "conversations") # <-- Añadimos la relación entre la conversación y el agente
Observa cómo agregamos la relación entre las conversaciones por cada agente en la tabla agents y también la relación entre una conversación con un agente en la tabla conversations.
Ahora crearemos un conjunto de funciones CRUD para recuperar el agente y las conversaciones por sus IDs, lo cual nos ayudará a diseñar nuestro proceso de creación de una conversación y preservar su historial. Abre el archivo crud.py y agrega las siguientes funciones:
def obtener_agente(db: Session, id_agente: str): """ Obtener un agente por su ID """ return db.query(models.Agente).filter(models.Agente.id == id_agente).first()def obtener_conversacion(db: Session, id_conversacion: str): """ Obtener una conversación por su ID """ return db.query(models.Conversacion).filter(models.Conversacion.id == id_conversacion).first()def crear_conversacion(db: Session, conversacion: schemas.CrearConversacion): """ Crear una conversación """ db_conversacion = models.Conversacion( id = str(uuid.uuid4()), id_agente = conversacion.id_agente, ) db.add(db_conversacion) db.commit() db.refresh(db_conversacion) return db_conversacion
Estas nuevas funciones nos ayudarán durante el flujo normal de nuestra aplicación. Ahora podemos obtener un agente por su ID, obtener una conversación por su ID y crear una conversación proporcionando un ID opcional y el ID del agente que debe tener la conversación.
Sigamos adelante y creemos un punto final que cree una conversación. Abre el archivo routes.py y agrega el siguiente código:
@router.post("/crear-conversacion", response_model = agents.api.schemas.Conversacion)async def crear_conversacion(conversacion: agents.api.schemas.CrearConversacion, db: Session = Depends(obtener_bd)): """ Crear una conversación vinculada a un agente """ log.info(f"Creando conversación asignada al ID del agente: {conversacion.id_agente}") db_conversacion = agents.crud.crear_conversacion(db, conversacion) log.info(f"Conversación creada con ID: {db_conversacion.id}") return db_conversacion
Con este método listo, nos falta un paso para tener un punto final conversacional real, que revisaremos a continuación.
Es importante hacer una distinción aquí: cuando inicializamos un agente, podemos crear una conversación sin desencadenar un intercambio de mensajes bidireccional o, de otra manera, desencadenar la creación de una conversación cuando se llama al punto final “Chat con un agente”. Esto proporciona flexibilidad para orquestar los flujos de trabajo fuera del microservicio. En algunos casos, es posible que desees inicializar los agentes, iniciar conversaciones previas con los clientes y, a medida que comienzan a llegar los mensajes, empezar a preservar el historial de los mensajes.
Punto final crear-conversacion desde Swagger UI — Imagen de autor
Nota importante: si estás siguiendo paso a paso esta guía y ves un error relacionado con el esquema de la base de datos en este paso, es porque no estamos aplicando las migraciones a la base de datos con cada modificación de los esquemas. Por lo tanto, asegúrate de cerrar la aplicación (salir del comando de terminal) y eliminar el archivo agents.db que se crea durante la ejecución. Necesitarás ejecutar nuevamente cada punto final y tomar nota de los IDs.
Chat con un agente
Vamos a presentar el último tipo de entidad en nuestra aplicación, que es la entidad Mensaje. Esta es responsable de modelar la interacción entre el mensaje de un cliente y el mensaje de un agente (intercambio de mensajes bidireccional). También agregaremos modelos de datos de la API que se utilizan para definir la estructura de la respuesta de nuestros puntos finales. Sigamos adelante y creemos primero los modelos de datos y los tipos de respuesta de la API; abre el archivo schemas.py y modifica el código:
########################################### Esquemas internos ##########################################class MensajeBase(BaseModel): # <-- Cada mensaje está compuesto por el mensaje del usuario/cliente y el mensaje del agente mensaje_usuario: str mensaje_agente: strclass CrearMensaje(MensajeBase): passclass Mensaje(MensajeBase): # <-- Modelo de datos para la entidad Mensaje id: str timestamp: datetime = datetime.utcnow() id_conversacion: str class Config: orm_mode = True########################################### Esquemas de la API ##########################################class MensajeUsuario(BaseModel): id_conversacion: str mensaje: strclass RespuestaChatAgente(BaseModel): id_conversacion: str respuesta: str
Ahora tenemos que agregar el modelo de datos en nuestro script de modelos de base de datos que representa la tabla en nuestra base de datos. Abre el archivo models.py y modifícalo de la siguiente manera:
# models.pyclass Conversation(Base): __tablename__ = "conversaciones" id = Column(String, primary_key = True, index = True) id_agente = Column(String, ForeignKey("agentes.id")) fecha = Column(DateTime, default = datetime.utcnow) agente = relationship("Agente", back_populates = "conversaciones") mensajes = relationship("Mensaje", back_populates = "conversacion") # <-- Definimos la relación entre la conversación y los mensajes múltiples en ellos.class Mensaje(Base): __tablename__ = "mensajes" id = Column(String, primary_key = True, index = True) fecha = Column(DateTime, default = datetime.utcnow) mensaje_usuario = Column(String) mensaje_agente = Column(String) id_conversacion = Column(String, ForeignKey("conversaciones.id")) # <-- Un mensaje pertenece a una conversación conversacion = relationship("Conversacion", back_populates = "mensajes") # <-- Definimos la relación entre los mensajes y la conversación.
Ten en cuenta que hemos modificado nuestra tabla Conversaciones para definir la relación entre los mensajes y la conversación, y hemos creado una nueva tabla que representa las interacciones (intercambio de mensajes) que deben pertenecer a una conversación.
Ahora vamos a agregar una nueva función CRUD para interactuar con la base de datos y crear un mensaje para una conversación. Abramos el archivo crud.py y agreguemos la siguiente función:
def crear_mensaje_conversacion(db: Session, mensaje: schemas.CrearMensaje, id_conversacion: str): """ Crea un mensaje para una conversación """ db_mensaje = models.Mensaje( id = str(uuid.uuid4()), mensaje_usuario = mensaje.mensaje_usuario, mensaje_agente = mensaje.mensaje_agente, id_conversacion = id_conversacion ) db.add(db_mensaje) db.commit() db.refresh(db_mensaje) return db_mensaje
Ahora estamos listos para construir el último y más interesante punto final, el punto final de chat-agent. Abramos el archivo routes.py y sigamos el código mientras implementamos algunas funciones de procesamiento en el camino.
@router.post("/chat-agent", response_model = agents.api.schemas.RespuestaChatAgente)async def completar_chat(mensaje: agents.api.schemas.MensajeUsuario, db: Session = Depends(get_db)): """ Obtén una respuesta del modelo GPT dado un mensaje del cliente usando el punto final de completado de chat. La respuesta es un objeto json con la siguiente estructura: ``` { "id_conversacion": "string", "respuesta": "string" } ``` """ log.info(f"Id de conversación del usuario: {mensaje.id_conversacion}") log.info(f"Mensaje del usuario: {mensaje.mensaje}") conversacion = agents.crud.obtener_conversacion(db, mensaje.id_conversacion) if not conversacion: # Si no hay conversaciones, podemos optar por crear una sobre la marcha O generar una excepción. # Cualquiera que elijas, asegúrate de descomentarlo cuando sea necesario. # Opción 1: # conversacion = agents.crud.crear_conversacion(db, mensaje.id_conversacion) # Opción 2: return HTTPException( status_code = 404, detail = "Conversación no encontrada. Por favor, crea una conversación primero." ) log.info(f"Id de conversación: {conversacion.id}")
En esta sección del punto final, nos aseguramos de crear o generar una excepción si la conversación no existe. El siguiente paso es preparar los datos que se enviarán a OpenAI a través de nuestra integración, para esto crearemos un conjunto de funciones de procesamiento en el archivo processing.py que crearán el contexto, el primer mensaje, las instrucciones y la forma de respuesta esperada del LLM.
# processing.pyimport json######################################### Propiedades del chat########################################def crear_contexto_chat_agente(contexto: str) -> dict: """ Crea el contexto para que el agente lo use en los puntos finales del chat. """ contexto_chat_agente = { "rol": "sistema", "contenido": contexto } return contexto_chat_agentedef crear_primer_mensaje_chat_agente(contenido: str) -> dict: """ Crea el primer mensaje para que el agente lo use en los puntos finales del chat. """ primer_mensaje_chat_agente = { "rol": "asistente", "contenido": contenido } return primer_mensaje_chat_agentedef crear_instrucciones_chat_agente(instrucciones: str, forma_respuesta: str) -> dict: """ Crea las instrucciones para que el agente las use en los puntos finales del chat. """ instrucciones_chat_agente = { "rol": "usuario", "contenido": instrucciones + f"\n\nSiguiendo un JSON compatible con RFC8259 con una forma de: {json.dumps(forma_respuesta)} formato sin desviaciones." } return instrucciones_chat_agente
Tenga en cuenta la última función que espera la response_shape definida durante la creación del agente, esta entrada se agregará al LLM durante el curso de una conversación y guiará al agente para seguir las pautas y devolver la respuesta como un objeto JSON.
Volviendo al archivo routes.py y terminando nuestra implementación del punto final:
# Nuevas importaciones del módulo de procesamiento.from agents.processing import ( craft_agent_chat_context, craft_agent_chat_first_message, craft_agent_chat_instructions)@router.post("/chat-agent", response_model = agents.api.schemas.ChatAgentResponse)async def chat_completion(message: agents.api.schemas.UserMessage, db: Session = Depends(get_db)): """ Obtenga una respuesta del modelo GPT dada un mensaje del cliente utilizando el punto final de completado de chat. La respuesta es un objeto JSON con la siguiente estructura: ``` { "conversation_id": "string", "response": "string" } ``` """ log.info(f"Identificación de conversación del usuario: {message.conversation_id}") log.info(f"Mensaje del usuario: {message.message}") conversation = agents.crud.obtener_conversacion(db, message.conversation_id) if not conversation: # Si no hay conversaciones, podemos optar por crear una sobre la marcha O generar una excepción. # Cualquiera que elija, asegúrese de descomentar cuando sea necesario. # Opción 1: # conversation = agents.crud.crear_conversacion(db, message.conversation_id) # Opción 2: return HTTPException( status_code = 404, detail = "Conversación no encontrada. Por favor, cree una conversación primero." ) log.info(f"Identificación de conversación: {conversación.id}") # NOTA: Estamos creando el contexto primero y pasando los mensajes de chat en una lista # adjuntando el primer mensaje (el enfoque del agente) a él. contexto = craft_agent_chat_context(conversación.agente.contexto) mensajes_de_chat = [craft_agent_chat_first_message(conversación.agente.primer_mensaje)] # NOTA: Agregar a la conversación todos los mensajes hasta la última interacción del agente # Si no hay mensajes, esto no tiene efecto. # De lo contrario, agregamos cada uno en orden por marca de tiempo (lo cual tiene sentido lógico). mensajes_históricos = conversación.mensajes mensajes_históricos.sort(key = lambda x: x.timestamp, reverse = False) if len(mensajes_históricos) > 0: for mes in mensajes_históricos: log.info(f"Mensaje histórico de la conversación: {mes.mensaje_de_usuario} | {mes.mensaje_del_agente}") mensajes_de_chat.append( { "rol": "usuario", "contenido": mes.mensaje_de_usuario } ) mensajes_de_chat.append( { "rol": "asistente", "contenido": mes.mensaje_del_agente } ) # NOTA: Podríamos controlar la conversación simplemente agregando # reglas para la longitud del historial. if len(mensajes_históricos) > 10: # Finalizar la conversación correctamente. log.info("El historial de la conversación es demasiado largo, finalizando la conversación.") respuesta_api = agents.api.schemas.ChatAgentResponse( identificación_de_conversación = message.conversation_id, respuesta = "Esta conversación ha terminado, adiós." ) return respuesta_api # Enviar el mensaje al agente de IA y obtener la respuesta servicio = integrations.OpenAIIntegrationService( contexto = contexto, instrucción = craft_agent_chat_instructions( conversación.agente.instrucciones, conversación.agente.forma_de_respuesta ) ) servicio.agregar_historial_de_chat(mensajes = mensajes_de_chat) respuesta = servicio.responder_a_prompt( # Podemos probar diferentes modelos de OpenAI. modelo = "gpt-3.5-turbo", prompt = message.message, # También podemos probar diferentes parámetros. temperatura = 0.5, max_tokens = 1000, penalización_de_frecuencia = 0.5, penalización_de_presencia = 0 ) log.info(f"Respuesta del agente: {respuesta}") # Preparar respuesta para el usuario respuesta_api = agents.api.schemas.ChatAgentResponse( identificación_de_conversación = message.conversation_id, respuesta = respuesta.get('answer') ) # Guardar interacción en la base de datos mensaje_db = agents.crud.crear_mensaje_de_conversación( db = db, identificación_de_conversación = conversación.id, mensaje = agents.api.schemas.MessageCreate( mensaje_de_usuario = message.message, mensaje_del_agente = respuesta.get('answer'), ), ) log.info(f"Mensaje de conversación con identificación {mensaje_db.id} guardado en la base de datos") return respuesta_api
¡Voilà! Esta es nuestra implementación final del punto final, si observamos las Notas agregadas al código, vemos que el proceso es bastante sencillo:
Nos aseguramos de que la conversación exista en nuestra base de datos (o creamos una)
Elaboramos el contexto y las instrucciones para el agente desde nuestra base de datos
Hacemos uso de la “memoria” del agente extrayendo el historial de la conversación
Finalmente, solicitamos la respuesta del agente a través del modelo GPT-3.5 Turbo de OpenAI y devolvemos la respuesta al cliente.
Pruebas locales de nuestros agentes
Ahora estamos listos para probar el flujo de trabajo completo de nuestro microservicio, comenzaremos yendo a nuestra terminal y escribiendo uvicorn agents.main:app — host 0.0.0.0 — port 8000 — reload para iniciar la aplicación. A continuación, navegaremos a nuestra interfaz de usuario Swagger y enviaremos las siguientes solicitudes:
Crear el agente: Proporcione los datos que desea probar. Enviaré lo siguiente:
{ "context": "Eres un chef especializado en comida mediterránea que proporciona recetas con un máximo de 10 ingredientes simples. El usuario puede tener muchas preferencias alimentarias o de ingredientes, y tu trabajo siempre es analizarlos y guiarlos para que utilicen ingredientes simples en las recetas que sugieres y que también sean mediterráneas. La respuesta debe incluir información detallada sobre la receta. La respuesta también debe incluir preguntas al usuario cuando sea necesario. Si crees que tu respuesta puede ser inexacta o vaga, no la escribas y responde con el texto exacto: 'No tengo una respuesta.'", "first_message": "Hola, soy tu chef personal y asesor culinario, y estoy aquí para ayudarte con tus preferencias alimentarias y tus habilidades culinarias. ¿En qué puedo ayudarte hoy?", "response_shape": "{'recipes': 'Lista de cadenas con el nombre de las recetas', 'ingredients': 'Lista de los ingredientes utilizados en las recetas', 'summary': 'Cadena, resumen de la conversación'}", "instructions": "Recorre los mensajes de la conversación y descarta aquellos que no sean relevantes para cocinar. Concéntrate en extraer las recetas que se mencionaron en la conversación y, para cada una de ellas, extrae la lista de ingredientes. Asegúrate de proporcionar un resumen de la conversación cuando se solicite."}
Crear la conversación: Asigna la conversación al agent_id que obtuviste de la respuesta anterior.
{ "agent_id": "Reemplaza con el UUID del agente que acabas de crear."}
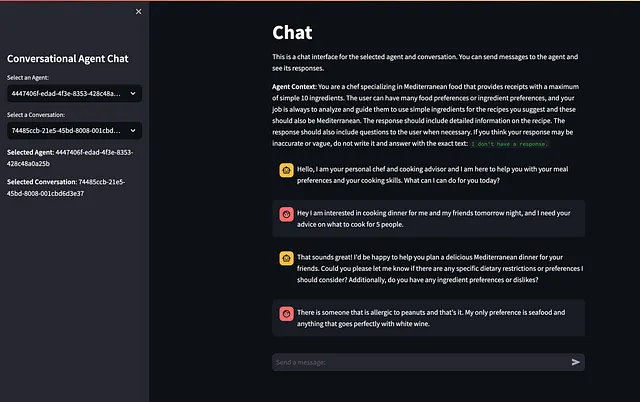
Vamos a chatear con nuestro agente a través del mensaje saliente: Nuestro agente iniciará la conversación haciéndonos una pregunta o acercándose a nosotros con un mensaje. Seguiremos la conversación enviando un mensaje de vuelta. Usaré este:
{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "message": "Hola, estoy interesado en cocinar la cena para mí y mis amigos mañana por la noche, y necesito tu consejo sobre qué cocinar para 5 personas."}
Respuesta del punto final del chat-agent desde Swagger UI — Imagen del autor
Nuestro agente nos respondió con una respuesta y podemos continuar esta conversación respondiendo de manera natural.
# Nuestra pregunta{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "message": "Hay alguien alérgico a los cacahuetes y eso es todo. Mi única preferencia es mariscos y cualquier cosa que vaya perfectamente con vino blanco."}# Respuesta de nuestros agentes{ "conversation_id": "74485ccb-21e5-45bd-8008-001cbd6d3e37", "response": "¡Genial! Definitivamente podemos trabajar alrededor de la alergia a los cacahuetes e incorporar mariscos en el menú. ¿Qué tal si empezamos con un refrescante aperitivo de Brochetas de Gambas a la Parrilla con Limón y Ajo? Es sencillo, delicioso y combina bien con el vino blanco.\n\nAquí está la receta de Brochetas de Gambas a la Parrilla con Limón y Ajo:\n\nIngredientes:\n1. 1 libra de camarones grandes, pelados y desvenados\n2. 2 dientes de ajo picados\n3. 2 cucharadas de jugo de limón fresco\n4. 2 cucharadas de aceite de oliva\n5. Sal y pimienta al gusto\n6. Brochetas de madera, remojadas en agua durante 30 minutos\n\nInstrucciones:\n1. Precalienta la parrilla a fuego alto.\n2. En un recipiente, mezcla el ajo picado, el jugo de limón, el aceite de oliva, la sal y la pimienta.\n3. Ensarta los camarones en las brochetas de madera remojadas.\n4. Unta las brochetas de camarones con la marinada de ajo y limón por ambos lados.\n5. Coloca las brochetas en la parrilla precalentada y cocina durante aproximadamente 2-3 minutos por cada lado hasta que se pongan rosados y opacos.\n6. Retira de la parrilla y sirve caliente.\n\nPara el plato principal, ¿qué te parece un Salmón al Horno al estilo Mediterráneo? Es sabroso, saludable y combina maravillosamente con el vino blanco.\n\nAquí está la receta de Salmón al Horno al estilo Mediterráneo:\n\nIngredientes:\n1. 1 libra de filetes de salmón\n2. 2 cucharadas de aceite de oliva\n3. 2 dientes de ajo picados\n4. 1 cucharadita de orégano seco\n5. Jugo de medio limón\n6. Sal y pimienta al gusto\n\nInstrucciones:\n1. Precalienta el horno a 375°F (190°C).\n2. Coloca los filetes de salmón en una bandeja para hornear forrada con papel pergamino o papel de aluminio.\n3. En un recipiente pequeño, mezcla el aceite de oliva, el ajo picado, el orégano seco, el jugo de limón, la sal y la pimienta.\n4. Unta la mezcla sobre los filetes de salmón, asegurándote de que estén cubiertos de manera uniforme.\n5. Hornea el salmón en el horno precalentado durante aproximadamente 12-15 minutos o hasta que se descame fácilmente con un tenedor.\n6. Retira del horno y deja que repose unos minutos antes de servir.\n\nPara complementar la comida, puedes servir un acompañamiento de Verduras Asadas al Estilo Mediterráneo. Es una adición colorida y nutritiva a tu cena.\n\nAquí está la receta de Verduras Asadas al Estilo Mediterráneo:\n\nIngredientes:\n1. 1 pimiento rojo, cortado en rodajas\n2. 1 pimiento amarillo, cortado en rodajas\n3. 1 calabacín, cortado en rodajas\n4. 1 berenjena, cortada en cubos\n5. 1 cebolla roja, cortada en rodajas\n6. 2 cucharadas de aceite de oliva\n7. Sal y pimienta al gusto\n8. Hierbas frescas como albahaca o perejil (opcional)\n\nInstrucciones:\n1. Precalienta el horno a 425°F (220°C).\n2. En un tazón grande, mezcla todas las verduras con aceite de oliva, sal y pimienta hasta que estén bien cubiertas.\n3. Extiende las verduras en una sola capa en una bandeja para hornear.\n4. Asa en el horno precalentado durante aproximadamente 20-25 minutos o hasta que estén tiernas y ligeramente caramelizadas.\n5. Ret
Adelante y juega con el código y tus nuevos agentes. En la siguiente sección, me enfocaré en la implementación de este servicio.
El Ciclo de Implementación
Desplegaremos nuestra aplicación en un entorno de contenedores en la nube como Kubernetes, Azure Container Service o AWS Elastic Container Service. Aquí es donde creamos una imagen de Docker y subimos nuestro código para poder ejecutarlo en uno de estos entornos. Adelante y abre el Dockerfile que creamos al principio y pega el siguiente código:
# DockerfileFROM python:3.10-slim-bullseye# Establecer el directorio de trabajoWORKDIR /app# Copiar los archivos del proyecto al contenedorCOPY . .# Instalar el paquete usando setup.pyRUN pip install -e .# Instalar dependenciasRUN pip install pip -U && \ pip install --no-cache-dir -r requirements.txt# Establecer la variable de entornoARG OPENAI_API_KEYENV OPENAI_API_KEY=$OPENAI_API_KEY# Exponer los puertos necesariosEXPOSE 8000# Ejecutar la aplicación# CMD ["uvicorn", "agents.main:app", "--host", "0.0.0.0", "--port", "8000"]
El Dockerfile instala la aplicación y luego la ejecuta a través del CMD que está comentado. Debes descomentar el comando si deseas ejecutarlo localmente de forma independiente, pero para otros servicios como Kubernetes, esto se define al definir la implementación o los pods en la sección de comandos del manifiesto.
Construye la imagen, espera hasta que se complete la construcción y luego pruébala ejecutando el comando run, que se muestra a continuación:
# Construir la imagen$ docker build - build-arg OPENAI_API_KEY=<Reemplaza con tu clave de OpenAI> -t agents-app .# Ejecutar el contenedor con el comando de la aplicación de los agentes (Usar la opción -d para ejecución en segundo plano).$ docker run -p 8000:8000 agents-app uvicorn agents.main:app --host 0.0.0.0 --port 8000# SalidaINFO: Proceso del servidor iniciado [1]INFO: Esperando el inicio de la aplicación.INFO: Inicio de la aplicación completado.INFO: Uvicorn en ejecución en http://0.0.0.0:8000 (Presiona CTRL+C para salir)INFO: 172.17.0.1:41766 - "GET / HTTP/1.1" 200 OKINFO: 172.17.0.1:41766 - "GET /favicon.ico HTTP/1.1" 404 Not FoundINFO: 172.17.0.1:41770 - "GET /docs HTTP/1.1" 200 OKINFO: 172.17.0.1:41770 - "GET /openapi.json HTTP/1.1" 200 OK
Genial, estás listo para comenzar a usar la aplicación en tu entorno de implementación.
Finalmente, intentaremos integrar este microservicio con una aplicación de front-end que servirá a los agentes y las conversaciones llamando a los endpoints internamente, que es la forma común de construir e interactuar entre servicios utilizando esta arquitectura.
El Ciclo de Uso
Podemos utilizar este nuevo servicio de varias formas, y solo me enfocaré en construir una aplicación de front-end que llame a los endpoints de nuestros agentes y permita a los usuarios interactuar a través de una interfaz de usuario. Utilizaremos Streamlit para esto, ya que es una forma sencilla de crear un front-end utilizando Python.
Nota Importante: Hay utilidades adicionales que agregué a nuestro servicio de agentes que puedes copiar directamente desde el repositorio. Busca get_agents(), get_conversations(), get_messages() del módulo crud.py y las rutas api/routes.py.
Instala Streamlit y agrégalo a nuestro requirements.txt.
# Fija una versión si es necesario$ pip install streamlit==1.25.0# Nuestro requirements.txt (agregado streamlit)$ cat requirements.txtfastapi==0.95.2ipykernel==6.22.0jupyter-bokeh==2.0.2jupyterlab==3.6.3openai==0.27.6pandas==2.0.1sqlalchemy-orm==1.2.10sqlalchemy==2.0.15streamlit==1.25.0uvicorn<0.22.0,>=0.21.1
Crea la aplicación creando primero una carpeta en nuestra carpeta src con el nombre frontend. Crea un nuevo archivo llamado main.py y coloca el siguiente código.
import streamlit as stimport requestsAPI_URL = "http://0.0.0.0:8000/agents" # Utilizaremos nuestra URL y puerto local definidos en nuestro microservicio para este ejemplodef get_agents(): """ Obtén la lista de agentes disponibles desde la API """ response = requests.get(API_URL + "/get-agents") if response.status_code == 200: agents = response.json() return agents return []def get_conversations(agent_id: str): """ Obtén la lista de conversaciones para el agente con el ID dado """ response = requests.get(API_URL + "/get-conversations", params = {"agent_id": agent_id}) if response.status_code == 200: conversations = response.json() return conversations return []def get_messages(conversation_id: str): """ Obtén la lista de mensajes para la conversación con el ID dado """ response = requests.get(API_URL + "/get-messages", params = {"conversation_id": conversation_id}) if response.status_code == 200: messages = response.json() return messages return []def send_message(agent_id, message): """ Envía un mensaje al agente con el ID dado """ payload = {"conversation_id": agent_id, "message": message} response = requests.post(API_URL + "/chat-agent", json = payload) if response.status_code == 200: return response.json() return {"response": "Error"}def main(): st.set_page_config(page_title = "🤗💬 AIChat") with st.sidebar: st.title("Chat del Agente Conversacional") # Menú desplegable para seleccionar agente agents = get_agents() agent_ids = [agent["id"] for agent in agents] selected_agent = st.selectbox("Selecciona un Agente:", agent_ids) for agent in agents: if agent["id"] == selected_agent: selected_agent_context = agent["context"] selected_agent_first_message = agent["first_message"] # Menú desplegable para seleccionar conversación conversations = get_conversations(selected_agent) conversation_ids = [conversation["id"] for conversation in conversations] selected_conversation = st.selectbox("Selecciona una Conversación:", conversation_ids) if selected_conversation is None: st.write("Por favor, selecciona una conversación del menú desplegable.") else: st.write(f"**Agente Seleccionado**: {selected_agent}") st.write(f"**Conversación Seleccionada**: {selected_conversation}") # Mostrar mensajes de chat st.title("Chat") st.write("Esta es una interfaz de chat para el agente y la conversación seleccionados. Puedes enviar mensajes al agente y ver sus respuestas.") st.write(f"**Contexto del Agente**: {selected_agent_context}") messages = get_messages(selected_conversation) with st.chat_message("assistant"): st.write(selected_agent_first_message) for message in messages: with st.chat_message("user"): st.write(message["user_message"]) with st.chat_message("assistant"): st.write(message["agent_message"]) # Prompt proporcionado por el usuario if prompt := st.chat_input("Enviar un mensaje:"): with st.chat_message("user"): st.write(prompt) with st.spinner("Pensando..."): response = send_message(selected_conversation, prompt) with st.chat_message("assistant"): st.write(response["response"])if __name__ == "__main__": main()
El código a continuación se conecta al microservicio de nuestro agente mediante llamadas a la API y permite al usuario seleccionar el Agente y las Conversaciones y chatear con el agente, similar a lo que proporciona ChatGPT. Ejecuta esta aplicación abriendo otra terminal (asegúrate de tener el microservicio de agentes en ejecución en el puerto 8000) y escribe $ streamlit run src/frontend/main.py ¡y estarás listo para comenzar!
AI Chat Streamlit App — Imagen por el autor
Mejoras Futuras y Conclusión
Mejoras Futuras
Existen varias oportunidades emocionantes para mejorar nuestro Agente Conversacional con un microservicio de memoria. Estas mejoras introducen capacidades avanzadas que pueden ampliar las interacciones del usuario y expandir el alcance de nuestras aplicaciones o del sistema en general.
Manejo Mejorado de Errores: Para garantizar conversaciones sólidas y confiables, podríamos implementar código para manejar de manera elegante las entradas inesperadas del usuario, las fallas de la API, como tratar con OpenAI u otros servicios, y los posibles problemas que podrían surgir durante las interacciones en tiempo real.
Integración de Buffers y Resúmenes de Conversación: La integración de buffers implementados por el framework LangChain ofrece la posibilidad de optimizar la gestión de tokens, permitiendo que las conversaciones abarquen períodos más largos sin encontrarse con limitaciones de tokens. Además, la incorporación de resúmenes de conversación permite a los usuarios revisar la discusión en curso, ayudando a retener el contexto y mejorando la experiencia general del usuario. Presta atención a las instrucciones del agente y la forma de respuesta para extender esto fácilmente en nuestro código.
Aplicaciones Conscientes de los Datos: Podríamos crear agentes con conocimientos únicos e internos conectando los modelos de nuestros agentes a otras fuentes de datos como bases de datos internas. Esto implica entrenar o integrar modelos que puedan comprender y responder a consultas complejas basadas en una comprensión de los datos e información únicos de su organización. Consulta los módulos de conexión de datos de LangChain.
Diversificación de Modelos: Si bien solo hemos utilizado el modelo GPT-3.5 de OpenAI, el panorama de proveedores de modelos de lenguaje está creciendo rápidamente. Probar modelos de otros proveedores puede llevar a un análisis comparativo, descubriendo fortalezas y debilidades, y permitiéndonos elegir el mejor ajuste para casos de uso específicos. Prueba diferentes integraciones de modelos de lenguaje, como HuggingFace, Cohere, Google, etc.
Conclusión
Hemos desarrollado un microservicio que proporciona agentes inteligentes impulsados por modelos GPT de OpenAI y hemos demostrado cómo estos agentes pueden estar equipados con memoria que vive fuera de la sesión del cliente. Al adoptar esta arquitectura, hemos desbloqueado un mundo de posibilidades. Desde conversaciones conscientes del contexto hasta la integración perfecta con modelos de lenguaje sofisticados, nuestra pila se ha vuelto capaz de proporcionar nuevas características a nuestros productos.
Esta implementación y sus beneficios tangibles dejan claro que el uso de la IA está al alcance de cualquier persona con las herramientas y el enfoque adecuados. El uso de agentes impulsados por IA no se trata solo de ingeniería rápida, sino de cómo construimos herramientas y nos relacionamos con ellas de manera más efectiva, ofreciendo experiencias personalizadas y abordando tareas complejas con la destreza y precisión que la IA y la ingeniería de software pueden proporcionar. Por lo tanto, ya sea que estés construyendo un sistema de soporte al cliente, un asistente virtual de ventas, un chef personal o algo completamente nuevo, recuerda que el viaje comienza con un poco de código y una abundancia de imaginación: las posibilidades son ilimitadas.
Todo el código de este artículo está en GitHub. Puedes encontrarme en LinkedIn, ¡no dudes en conectarte!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!