Conoce Magic123 Un novedoso proceso de conversión de imagen a 3D que utiliza una optimización en dos etapas, de áspero a refinado, para producir geometría y texturas 3D de alta calidad y alta resolución.
Conoce Magic123, un innovador proceso de conversión de imagen a 3D que utiliza una optimización en dos etapas para producir geometría y texturas 3D de alta calidad y resolución.


A pesar de ver el mundo solo en dos dimensiones, los humanos son hábiles para navegar, pensar e interactuar con su entorno tridimensional. Esto sugiere una conciencia cognitiva profundamente arraigada de las características y acciones del entorno 3D, lo cual es un gran aspecto de la naturaleza humana. Los artistas que pueden crear reproducciones detalladas en 3D a partir de una sola fotografía llevan esta habilidad a un nuevo nivel. Contrariamente, después de décadas de investigación y avance, el desafío de la reconstrucción 3D a partir de una imagen sin poses, incluyendo la producción de geometría y texturas, sigue siendo un tema abierto e indefinido en la visión por computadora. Muchas actividades de creación 3D pueden ser aprendidas gracias a los avances recientes en el aprendizaje profundo.
Aunque el aprendizaje profundo ha logrado grandes avances en la identificación y creación de imágenes, todavía necesita mejorar en el desafío específico del mundo real de la reconstrucción 3D a partir de una sola imagen. Se culpa a dos problemas principales por esta brecha significativa entre las habilidades de reconstrucción 3D humanas y de las máquinas: (i) la falta de conjuntos de datos 3D a gran escala que impide el aprendizaje a gran escala de la geometría 3D, y (ii) el equilibrio entre el nivel de detalle y los recursos computacionales al trabajar con datos 3D. Utilizar prioridades 2D es una estrategia para resolver el problema. Existe una gran cantidad de datos de imágenes reales en línea. Para entrenar algoritmos de interpretación y generación de imágenes de vanguardia como CLIP y Stable Diffusion, uno de los conjuntos de datos más completos de pares de texto-imagen es LAION.
Ha habido un aumento notable en las estrategias que utilizan modelos 2D como prioridades para crear contenido 3D debido a las capacidades de generalización en expansión de los modelos de generación 2D. DreamFusion fue pionero en esta tecnología basada en prioridades 2D para la creación de texto a 3D. El método muestra una notable capacidad para dirigir vistas únicas y mejorar un campo de radiación neural (NeRF) en una situación de cero disparo. Basándose en DreamFusion, investigaciones recientes han intentado adaptar estas prioridades 2D para reconstrucciones 3D de una sola imagen utilizando RealFusion y NeuralLift. Una estrategia diferente es utilizar prioridades 3D. En esfuerzos anteriores, se utilizaron prioridades 3D como restricciones topológicas para ayudar en la creación 3D. Estas prioridades 3D hechas a mano pueden crear algunos objetos 3D, pero podrían ser mejores en cuanto a contenido 3D.
- Bootcamp Intensivo de Aprendizaje Automático para el Desarrollo de Habilidades
- Usé ChatGPT (todos los días) durante 5 meses. Aquí hay algunas joyas ocultas que cambiarán tu vida.
- AI Engaña a los Estafadores La Ingeniosa Batalla Contra las Llamadas Automáticas
Recientemente, se modificó un modelo de difusión 2D para que fuera dependiente de la vista, y esta difusión dependiente de la vista se utilizó como prioridad 3D en técnicas como Zero-1-to-3 y 3Dim. Según su análisis del comportamiento, tanto las prioridades 2D como las 3D tienen ventajas y desventajas. En comparación con las prioridades 3D, las prioridades 2D tienen una generalización excepcional para la creación 3D, como se muestra en el ejemplo de la estatua de dragón en la Figura 1. Debido a su comprensión limitada de 3D, los enfoques que dependen únicamente de las prioridades 2D sufren en última instancia la pérdida de fidelidad y consistencia en 3D. Esto resulta en geometrías irrealistas, como muchas caras (problemas de Jano), tamaños dispares, texturas desiguales, etc. El ejemplo del osito de peluche en la Figura 1 es un escenario de fracaso.
Sin embargo, debido a la pequeña cantidad de datos de entrenamiento 3D, se necesita más que una dependencia severa de las prioridades 3D para la reconstrucción en el mundo real. Como resultado, como se muestra en la Fig. 1, aunque las soluciones basadas en prioridades 3D manejan con éxito objetos comunes (como el ejemplo del osito de peluche en la fila superior), luchan con cosas menos frecuentes, produciendo geometrías 3D demasiado simplistas y ocasionalmente incluso planas (como la estatua de dragón en la parte inferior izquierda). En este estudio, investigadores de la King Abdullah University of Science and Technology (KAUST), Snap Inc. y el Visual Geometry Group de la Universidad de Oxford promueven el uso simultáneo de ambas prioridades para dirigir perspectivas innovadoras en la creación de imágenes a 3D en lugar de depender únicamente de una prioridad 2D o 3D. Pueden controlar el equilibrio entre la exploración y la explotación en la geometría 3D resultante variando el parámetro de compensación específico pero útil entre la potencia de las prioridades 2D y 3D.
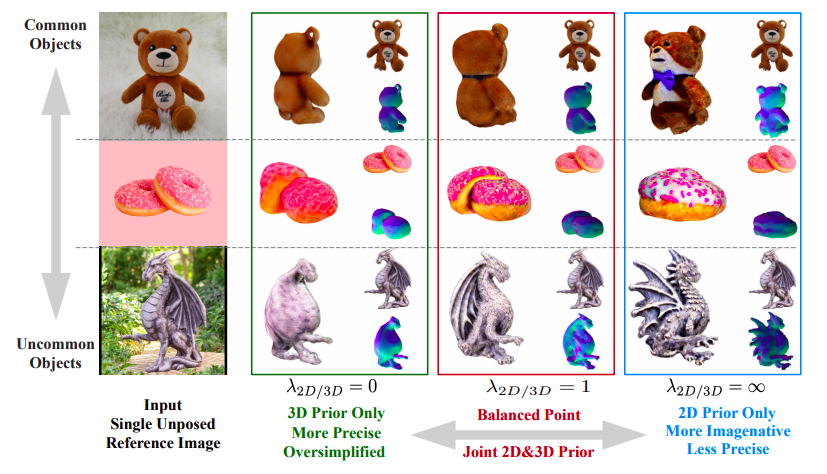
Figura 1 muestra el compromiso entre las prioridades 2D y 3D de Magic123. Un oso de peluche (un objeto frecuente), dos rosquillas apiladas (algo menos común) y una estatua de dragón (un objeto poco común) son los tres escenarios con los que comparan las reconstrucciones de una sola imagen. Como se puede ver a la derecha, Magic123, que solo tiene un fondo 2D, favorece la exploración geométrica y crea material 3D con mayor creatividad pero tal vez con menos consistencia. Con solo la prioridad 3D, Magic123 (a la izquierda) prioriza la explotación de la geometría, lo que resulta en una geometría exacta pero tal vez más simple y con menos características.
La priorización de la prioridad 2D puede mejorar las habilidades creativas en 3D para compensar la falta de información 3D en cada imagen 2D. Sin embargo, esto podría dar lugar a una geometría 3D menos precisa debido a la falta de comprensión 3D. Por otro lado, la priorización de la prioridad 3D puede resultar en soluciones más restringidas en 3D y una geometría 3D más precisa, pero a costa de una menor creatividad y una capacidad disminuida para encontrar soluciones viables para circunstancias difíciles e inusuales. Presentan Magic123, un innovador proceso de conversión de imagen a 3D que produce salidas 3D de alta calidad utilizando un enfoque de optimización de dos etapas de grueso a fino que utiliza tanto prioridades 2D como 3D.
Refinan un campo de radiancia neuronal (NeRF) en la etapa gruesa. NeRF aprende de manera efectiva una representación de volumen implícita para aprender geometría complicada. Sin embargo, NeRF utiliza mucha memoria, lo que resulta en imágenes generadas de baja resolución que se envían a los modelos de difusión, lo que reduce la calidad de salida para el proceso de imagen a 3D. Instant-NGP, un sustituto de NeRF más eficiente en recursos, está limitado a una resolución de tubería de imagen a 3D de 128 128 en una GPU de memoria de 16 GB. Como resultado, agregan un segundo paso y utilizan Deep Marching Tetrahedra (DMTet), una representación híbrida SDF-Mesh eficiente en memoria y descompuesta en textura, para mejorar la calidad del contenido 3D.
Con la ayuda de este método, pueden separar las mejoras de geometría y textura de NeRF y aumentar la resolución a 1K. Utilizan una combinación de prioridades 2D y 3D en ambas etapas para orientar perspectivas innovadoras. Ofrecen el siguiente resumen de sus contribuciones:
• Presentan Magic123, un innovador proceso de conversión de imagen a 3D que crea geometría y texturas 3D de alta calidad y alta resolución utilizando un procedimiento de optimización de dos etapas de grueso a fino.
• Sugieren utilizar simultáneamente prioridades 2D y 3D para crear contenido 3D preciso a partir de cualquier imagen dada. El parámetro de fuerza de las prioridades permite un compromiso entre explorar y utilizar la geometría. Los usuarios pueden experimentar con este parámetro de compromiso para crear el contenido 3D deseado.
• Pueden descubrir un equilibrio adecuado entre las prioridades 2D y 3D, lo que resulta en reconstrucciones 3D relativamente realistas y detalladas. Magic123 produce resultados de última generación en la reconstrucción 3D a partir de fotos únicas sin pose en contextos del mundo real y sintéticos utilizando el mismo conjunto de parámetros para todas las muestras sin necesidad de reconfiguración adicional.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Creando una Infografía con Matplotlib
- ¿Cuál es la diferencia entre la covarianza y la correlación?
- Trabajos que la IA no puede reemplazar
- Conoce SDFStudio un marco unificado y modular para la reconstrucción de superficies neuronales implícitas basado en el proyecto Nerfstudio.
- Qué hacer después de obtener un título de licenciatura (BSc)? Explora las 10 mejores opciones de carrera.
- ‘Remnant II’ Encabeza 14 Juegos que se unen a GeForce NOW en Julio
- Cuatro errores comunes al realizar pruebas A/B y cómo solucionarlos





