Conoce CutLER (Cut-and-LEaRn) Un enfoque simple de IA para entrenar modelos de detección de objetos y segmentación de instancias sin anotaciones humanas
Conoce CutLER Un enfoque simple de IA para entrenar modelos de detección de objetos y segmentación de instancias sin anotaciones humanas


La detección de objetos y la segmentación de imágenes son tareas cruciales en la visión por computadora e inteligencia artificial. Son fundamentales en numerosas aplicaciones, como vehículos autónomos, imágenes médicas y sistemas de seguridad.
La detección de objetos implica detectar instancias de objetos dentro de una imagen o un flujo de video. Consiste en identificar la clase del objeto y su ubicación dentro de la imagen. El objetivo es producir un cuadro delimitador alrededor del objeto, que luego se puede utilizar para un análisis adicional o para rastrear el objeto a lo largo del tiempo en un flujo de video. Los algoritmos de detección de objetos se pueden dividir en dos categorías: de una etapa y de dos etapas. Los métodos de una etapa son más rápidos pero menos precisos, mientras que los métodos de dos etapas son más lentos pero más precisos.
Por otro lado, la segmentación de imágenes implica dividir una imagen en múltiples segmentos o regiones, donde cada segmento corresponde a un objeto diferente o a una parte de un objeto. El objetivo es etiquetar cada píxel de la imagen con una clase semántica, como “persona”, “automóvil”, “cielo”, etc. Los algoritmos de segmentación de imágenes se pueden dividir en dos categorías: segmentación semántica y segmentación de instancias. La segmentación semántica implica etiquetar cada píxel con una etiqueta de clase, mientras que la segmentación de instancias se refiere a detectar y segmentar objetos individuales dentro de una imagen.
- Cómo Patsnap utilizó la inferencia de GPT-2 en Amazon SageMaker con baja latencia y costo
- ¿Está cambiando el comportamiento de ChatGPT con el tiempo? Los investigadores evalúan las versiones de marzo de 2023 y junio de 2023 de GPT-3.5 y GPT-4 en cuatro tareas diversas.
- 8 Ejemplos Modernos de Inteligencia Artificial en los Videojuegos
Tanto los algoritmos de detección de objetos como los de segmentación de imágenes han avanzado significativamente en los últimos años, principalmente debido a enfoques de aprendizaje profundo. Debido a su capacidad para aprender representaciones jerárquicas de imágenes, las Redes Neuronales Convolucionales (CNNs) se han convertido en la opción preferida para estos problemas. Sin embargo, entrenar estos modelos requiere anotaciones especializadas como cuadros delimitadores de objetos, máscaras y puntos localizados, lo cual es desafiante y consume mucho tiempo. Sin tener en cuenta los gastos generales, la anotación manual de 164 000 imágenes en el conjunto de datos COCO con máscaras para solo 80 clases requirió más de 28 000 horas.
Con una nueva arquitectura llamada Cut-and-LEaRn (CutLER), los autores intentan abordar estos problemas mediante el estudio de modelos de detección de objetos y segmentación de instancias no supervisados que se pueden entrenar sin etiquetas humanas. El método consta de tres mecanismos simples independientes de la arquitectura y los datos. El flujo de trabajo para la arquitectura propuesta se muestra a continuación.
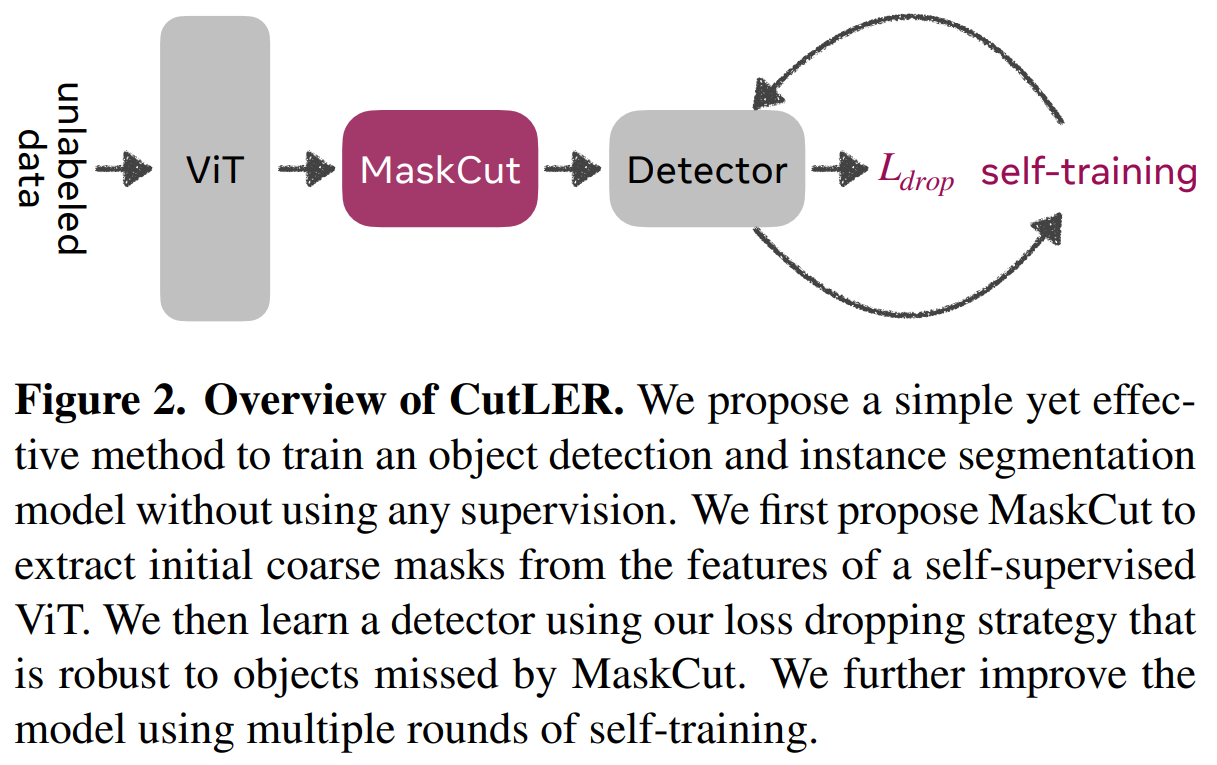
Los autores de CutLER primero presentan MaskCut, una herramienta capaz de generar automáticamente varias máscaras iniciales aproximadas para cada imagen basadas en características calculadas por un transformador de visión preentrenado auto-supervisado llamado ViT. MaskCut se ha desarrollado para abordar las limitaciones de las herramientas de enmascaramiento actuales, como Cuts Normalizados (NCut). De hecho, las aplicaciones de NCut están restringidas a la detección de un solo objeto en una imagen, lo cual puede ser muy limitante. Por esta razón, MaskCut lo extiende para descubrir múltiples objetos por imagen aplicando iterativamente NCut a una matriz de similitud enmascarada.
En segundo lugar, los autores implementan una estrategia sencilla de eliminación de pérdidas para entrenar los detectores utilizando estas máscaras aproximadas, que son robustas frente a los objetos que MaskCut no detectó. A pesar de estar entrenados con estas máscaras aproximadas, los detectores pueden refinar la verdad del terreno y producir máscaras (y cuadros) más precisos. Por lo tanto, múltiples rondas de autoentrenamiento basado en las predicciones de los modelos pueden permitir que el modelo evolucione desde centrarse en similitudes de píxeles locales hasta considerar la geometría general del objeto, lo que resulta en máscaras de segmentación más precisas.
La figura siguiente ofrece una comparación entre el marco propuesto y enfoques de vanguardia.

Este fue el resumen de CutLER, una nueva herramienta de IA para detección precisa y consistente de objetos y segmentación de imágenes.
Si estás interesado/a o quieres aprender más sobre este marco de trabajo, puedes encontrar un enlace al artículo y a la página del proyecto.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Un nuevo conjunto de datos de imágenes del Ártico impulsará la investigación en inteligencia artificial
- Un superordenador de inteligencia artificial cobra vida, impulsado por gigantes chips de computadora
- Interprete de Código GPT-4 Tu Varita Mágica para Visualizaciones Instantáneas de Datos en Python
- Loguru Tan simple como imprimir, tan flexible como el registro
- Desacoplamiento consciente ¿Hasta dónde es demasiado lejos para el almacenamiento, el cálculo y la pila de datos moderna?
- 10 Mejores Generadores de Juegos de IA (Julio 2023)
- Interfaz Cerebro-Computadora se Conecta a través del Canal Auditivo





