Conoce a WebAgent el nuevo LLM de DeepMind que sigue instrucciones y completa tareas en sitios web
Conoce a WebAgent, el LLM de DeepMind que sigue instrucciones y completa tareas en sitios web.
El modelo combina comprensión del lenguaje y navegación web.

Recientemente comencé un boletín educativo centrado en la IA, que ya cuenta con más de 160,000 suscriptores. TheSequence es un boletín orientado a la ML (machine learning) sin rodeos (es decir, sin exageraciones, sin noticias, etc.), que se lee en 5 minutos. El objetivo es mantenerte actualizado sobre proyectos de machine learning, papers de investigación y conceptos. Por favor, pruébalo suscribiéndote a continuación:
TheSequence | Jesus Rodriguez | Substack
La mejor fuente para mantenerte al día con los avances en machine learning, inteligencia artificial y datos…
thesequence.substack.com
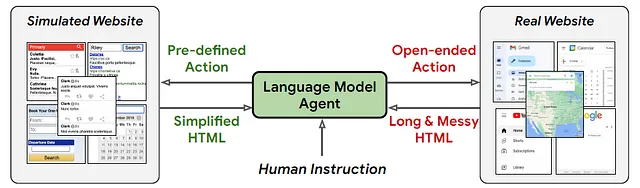
La integración entre los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) y los sitios web es una de las áreas que puede desbloquear una nueva ola de aplicaciones impulsadas por LLM. Los LLM han demostrado una notable eficiencia en una amplia gama de tareas de procesamiento de lenguaje natural, desde aritmética básica y razonamiento lógico hasta desafíos más complejos como la comprensión del sentido común, la respuesta a preguntas e incluso la toma de decisiones interactiva. Combinar estas capacidades con la navegación web resulta en una combinación muy poderosa. Recientemente, Google DeepMind presentó Web Agent, un agente autónomo impulsado por LLM capaz de navegar sitios web reales basado en instrucciones de usuario.
La implementación del mundo real de la navegación web ha planteado desafíos únicos, incluyendo:
- El modelo POE de sistemas de hardware inspirados en la biología
- Dominando las Expresiones Regulares con Python
- Pythia Un conjunto de 16 LLMs para investigación en profundidad
(1) la ausencia de un espacio de acciones predefinido.
(2) la presencia de observaciones HTML mucho más largas en comparación con los simuladores.
(3) la falta de conocimiento específico del dominio sobre HTML dentro de los LLM.
Estos obstáculos surgen debido a la naturaleza ilimitada de los sitios web del mundo real y la complejidad de las instrucciones, lo que dificulta definir de antemano un espacio de acciones adecuado. Si bien algunas investigaciones han destacado el potencial de la afinación de instrucciones o del aprendizaje por refuerzo a partir de la retroalimentación humana para mejorar la comprensión de HTML y la precisión de la navegación, los diseños de los LLM no siempre se han optimizado para procesar documentos HTML de manera efectiva. Específicamente, la mayoría de los LLM tienen longitudes de contexto relativamente cortas, insuficientes para manejar las longitudes promedio de los tokens encontrados en los sitios web reales, y es posible que no adopten técnicas cruciales para lidiar con documentos estructurados.
Ingresa a WebAgent
WebAgent aborda la tarea planificando sub-instrucciones para cada paso, resumiendo páginas HTML largas en fragmentos relevantes basados en estas sub-instrucciones, y ejecutando la tarea al fundamentar las sub-instrucciones y fragmentos HTML en códigos Python ejecutables. Para construir WebAgent, Google DeepMind combina dos LLMs: “Flan-U-PaLM” para generar código fundamentado y “HTML-T5”, un modelo de lenguaje pre-entrenado experto en el dominio recientemente introducido, responsable de la planificación de tareas y la sumarización condicional de HTML. HTML-T5, diseñado con una arquitectura codificador-decodificador, sobresale en capturar la estructura de páginas HTML extensas mediante el uso de mecanismos de atención locales y globales, y se pre-entrena de manera auto-supervisada en un vasto corpus de datos HTML sintetizados a partir de CommonCrawl.
Los agentes impulsados por LLM existentes suelen manejar tareas de toma de decisiones con un solo LLM al solicitar diferentes ejemplos por rol. Sin embargo, para tareas del mundo real más complejas, este enfoque se queda corto. Las evaluaciones exhaustivas de Google DeepMind demuestran que el método combinado de WebAgent, que integra modelos de lenguaje complementarios, mejora significativamente la comprensión y fundamentación de HTML, lo que conduce a una mejor generalización. WebAgent logra un aumento de más del 50% en las tasas de éxito para la navegación web del mundo real, y un análisis detallado revela el papel crítico de la planificación de tareas y la sumarización de HTML mediante el uso de modelos de lenguaje especializados para una ejecución exitosa de tareas. Además, WebAgent se desempeña admirablemente en tareas de comprensión de sitios web estáticos, superando a los LLMs individuales en precisión de QA y compitiendo de manera competitiva con líneas de base sólidas.
WebAgent de Google DeepMind es una composición innovadora de dos modelos de lenguaje distintos, HTML-T5 y Flan-U-PaLM, que trabajan juntos para permitir tareas eficientes de automatización web que implican la navegación y el procesamiento de documentos HTML.
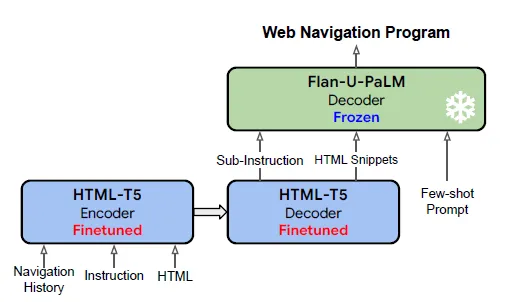
HTML-T5, un modelo de lenguaje codificador-decodificador experto en el dominio, desempeña un papel crucial en la predicción de subinstrucciones para el programa del próximo paso y en la summarización condicional de documentos HTML extensos. Este modelo especializado encuentra un equilibrio entre las capacidades generales de modelos de lenguaje como T5, Flan-T5 y Instruct-GPT, que exhiben una navegación web superior con una sólida comprensión de HTML, y los sesgos inductivos específicos de HTML que se encuentran en modelos de transformadores anteriores propuestos por Guo et al. HTML-T5 aprovecha mecanismos de atención local y global en el codificador para manejar de manera efectiva la estructura jerárquica de las entradas HTML. La atención local se centra en los tokens cercanos a la izquierda y derecha de cada elemento en el HTML, como <input>, <label> o <button>, mientras que la atención global transitoria permite que los tokens atiendan más allá del vecindario inmediato, dividiendo la secuencia de entrada en bloques y calculando tokens globales mediante sumas y normalización. Este enfoque jerárquico se alinea naturalmente con la estructura de los documentos HTML, donde los elementos se definen localmente e integran globalmente de forma iterativa, como <body>, <form> o <div>. El modelo se preentrena en un corpus de HTML a gran escala extraído de CommonCrawl, utilizando una mezcla de objetivos de eliminación de ruido de largo alcance.
En contraste con la atención densa tradicional utilizada en modelos de lenguaje natural, la adopción de mecanismos de atención local y global por parte de HTML-T5 captura mejor la jerarquía explícita presente en los documentos HTML. Los elementos hoja en HTML (por ejemplo, <input>, <label>, etc.) se procesan de manera efectiva utilizando la atención local, mientras que los elementos internos (por ejemplo, <body>, <form>, etc.) se comprimen en la atención global transitoria. Esta elección de diseño se alinea perfectamente con la sintaxis jerárquica de HTML, mejorando la capacidad del modelo para comprender la estructura y los atributos de los elementos HTML.
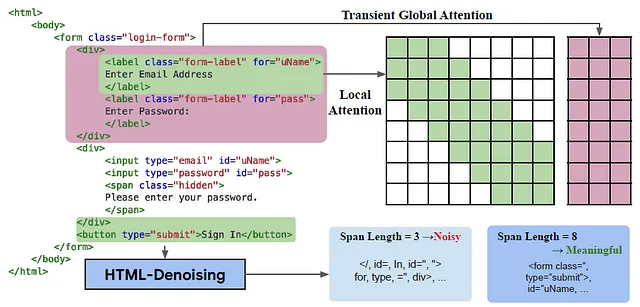
Para implementar HTML-T5, Google DeepMind se basa en la arquitectura base de LongT5, que incorpora atención densa en el decodificador. Esta combinación de mecanismos de atención local y global con la atención densa del decodificador proporciona una solución efectiva y completa para manejar documentos HTML en tareas de automatización web.
Los Resultados
Para ilustrar las capacidades de WebAgent de Google DeepMind, veamos la automatización en el contexto de un sitio web de bienes raíces. En este entorno, WebAgent ejemplifica un flujo poderoso que abarca la planificación, la summarización y la síntesis programática fundamentada. En este proceso, HTML-T5 toma la delantera, empleando un enfoque iterativo para predecir subinstrucciones descompuestas y fragmentos relevantes para la tarea, representados en naranja, al analizar de cerca los documentos HTML, las instrucciones en amarillo y las predicciones históricas en verde. Al mismo tiempo, Flan-U-PaLM, activado por las subinstrucciones y fragmentos en naranja, decodifica hábilmente programas de Python representados en azul.

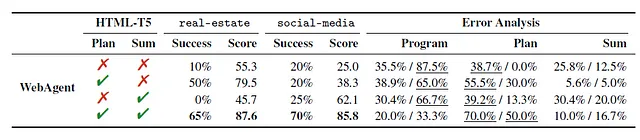
Los resultados logrados por WebAgent son realmente notables, con una impresionante tasa de éxito del 70% en sitios web reales. Este avance significativo supera el rendimiento del enfoque LLM individual en más de un 50%. Este logro indica que descomponer la tarea en una secuencia de subproblemas, cada uno abordado por diferentes modelos de lenguaje, puede mejorar sustancialmente el éxito general de la tarea.
Además, Google DeepMind presenta una receta innovadora y escalable para crear modelos de lenguaje especializados en HTML. Este enfoque implica entrenar mecanismos de atención local y global utilizando una combinación de objetivos de eliminación de ruido de largo alcance. El objetivo final es capturar hábilmente las estructuras jerárquicas que subyacen a los documentos HTML, allanando el camino para una mejor comprensión y un manejo más efectivo de tareas relacionadas con HTML.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una guía completa sobre la arquitectura UNET | Dominando la segmentación de imágenes
- Un enfoque sistemático para elegir la mejor tecnología/proveedor versión MLOps
- 4 formas en las que no puedes usar el intérprete de código ChatGPT que perturbarán tus análisis
- Implementación de ParDo y DoFn en Apache Beam en Detalles
- Generando datos sintéticos con Python
- Todos los Modelos de Lenguaje Grande (LLMs) que Debes Conocer en 2023
- ¿Es bueno tu modelo? Un análisis en profundidad de las métricas avanzadas de Amazon SageMaker Canvas





