Congelación de capas de un modelo de aprendizaje profundo – la forma correcta
Congelación de capas en un modelo de aprendizaje profundo - la forma correcta
Ejemplo del optimizador ADAM en PyTorch
Introducción
A menudo es útil congelar algunos de los parámetros, por ejemplo, cuando se está ajustando el modelo y se desea congelar algunas capas según el ejemplo que se procesa, como se ilustra
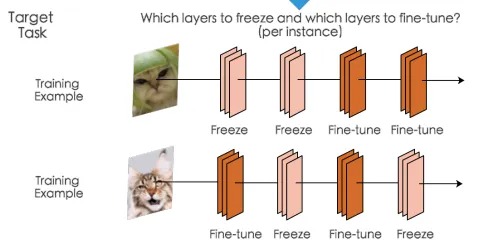
Como podemos ver en el primer ejemplo, estamos congelando las dos primeras capas y actualizando los parámetros de las dos últimas, mientras que en el segundo ejemplo congelamos la segunda y cuarta capa y ajustamos las demás. Habrá muchos otros casos en los que esta técnica sea útil y si está leyendo este artículo, probablemente tendrá un caso para esto.
Configuración del problema
Para simplificar un poco las cosas, supongamos que tenemos un modelo que acepta dos tipos diferentes de entradas: una con 3 características y otra con 2 características, y según las entradas que se pasen, las vamos a pasar a través de dos capas iniciales diferentes. Por lo tanto, solo queremos actualizar los parámetros relacionados con esas entradas particulares durante el entrenamiento. Como podemos ver a continuación, queremos congelar la capa hidden_task1 cuando se pasa la entrada1 y congelar la capa hidden_task2 cuando se pasa la entrada2.
class Network(nn.Module): def __init__(self): super().__init__() # Transformación lineal de las entradas a la capa oculta self.hidden_task1 = nn.Linear(3, 3, bias=False) self.hidden_task2 = nn.Linear(2, 3, bias=False) self.output = nn.Linear(3, 4, bias=False) # Definir la activación sigmoidal y la salida softmax self.sigmoid = nn.Sigmoid() self.softmax = nn.Softmax(dim=1) def forward(self, x, task='task1'): if task == 'task1': x = self.hidden_task1(x) else: x = self.hidden_task2(x) x = self.sigmoid(x) x = self.output(x) x = self.softmax(x) return x def freeze_params(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.grad = None def freeze_params_grad(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.requires_grad = False def unfreeze_params_grad(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.requires_grad = True# Definir la entrada y el objetivo input1 = torch.randn(10, 3).to(device)input2 = torch.randn(10, 2).to(device)target1 = torch.randint(0, 4, (10, )).long().to(device) target2 = torch.randint(0, 4, (10, )).long().to(device) net = Network().to(device)# Función auxiliar para mostrar los parámetros cambiados def changed_parameters(initial, final): for n, p in initial.items(): if not torch.allclose(p, final[n]): print("Cambiado: ", n)En un mundo con solo optimizadores SGD
Si solo estuviéramos trabajando con el optimizador SGD, el problema se resolvería simplemente usando requires_grad = False, que no calcularía los gradientes para los parámetros que especificamos y así obtendríamos los resultados deseados.
- Modelo Segment Anything Modelo base para la segmentación de imágenes
- 50 principales preguntas de entrevista de Google para roles de Ciencia de Datos
- Guía de un científico de datos de Spotify para convertir tus ideas en acciones impactantes
original_param = {n : p.clone() for (n, p) in net.named_parameters()}print("Parámetros originales")pprint(original_param)print(100 * "=")# vamos a definir 2 funciones de pérdida (en realidad podríamos definir solo una en este caso, ya que son iguales) criterion1 = nn.CrossEntropyLoss()criterion2 = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.9)# establecer requires_grad en False para las capas seleccionadasnet.freeze_params_grad(['hidden_task2.weight'])print("Parámetros después de la actualización de la tarea 1")params_hid1 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid1)print(100 * "=")# salida para la tarea 1 - queremos mantener congelados los parámetros de la capa de la tarea 2output = net(input1, task='task1')optimizer.zero_grad() # poner a cero los gradientes de los parámetrosloss1 = criterion(output, target)loss1.backward()optimizer.step()print("Estados del optimizador 1: ")print(optimizer.state)# establecer requires_grad nuevamente en True para las capas seleccionadasnet.unfreeze_params_grad(['hidden_task2.weight'])# salida para la tarea 2 - queremos mantener congelados los parámetros de la capa de la tarea 1output1 = net(input2, task='task2')optimizer.zero_grad() # poner a cero los gradientes de los parámetrosloss2 = criterion1(output1, target1)loss2.backward()optimizer.step() # realizar la actualizaciónprint("Estados del optimizador 1: ")print(optimizer.state)# establecer requires_grad nuevamente en True para las capas seleccionadasnet.unfreeze_params_grad(['hidden_task1.weight'])print("Parámetros después de la actualización de la tarea 2")params_hid2 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid2)changed_parameters(params_hid1, params_hid2)En las salidas a continuación podemos ver que el parámetro “Changed” después de las actualizaciones de la tarea 1 y la tarea 2 son correctas y hemos logrado el resultado deseado.
{'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parámetros después de hidden {'hidden_task1.weight': tensor([[ 0.0010, 0.3107, -0.4746], [-0.4289, -0.2261, 0.1547], [-0.0105, 0.4596, -0.0528]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0554, 0.2788, 0.3800], [-0.4105, -0.2702, 0.1917], [ 0.4552, -0.1496, 0.4091], [-0.0838, 0.0601, 0.5301]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Cambiado : hidden_task1.weightCambiado : output.weightParámetros después de hidden 1 {'hidden_task1.weight': tensor([[ 0.0010, 0.3107, -0.4746], [-0.4289, -0.2261, 0.1547], [-0.0105, 0.4596, -0.0528]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1906, -0.2102], [-0.1412, -0.6783], [-0.4657, -0.2929]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0386, 0.2673, 0.3726], [-0.3818, -0.2414, 0.2232], [ 0.4402, -0.1698, 0.3898], [-0.0807, 0.0631, 0.5254]], device='cuda:0', grad_fn=<CloneBackward0>)}Cambiado : hidden_task2.weightCambiado : output.weightComplicaciones con los Optimizadores Adaptativos
Ahora intentemos ejecutar lo mismo nuevamente, pero usando el optimizador Adam:
optimizer = optim.Adam(net.parameters(), lr=0.9)En la parte “Cambiado” ahora vemos que después de la segunda actualización de la tarea, hidden_task1.weight también cambió, lo cual no es lo que queremos.
Parámetros originales {'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parámetros después de hidden {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Cambiado : hidden_task1.weightCambiado : output.weightParámetros después de hidden 1 {'hidden_task1.weight': tensor([[ 1.4907, 1.7991, 1.0283], [-1.9122, -1.7133, -1.3428], [ 1.4837, 1.9445, -1.5453]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', grad_fn=<CloneBackward0>)}Cambiado : hidden_task1.weightCambiado : hidden_task2.weightCambiado : output.weightIntentemos entender qué está sucediendo aquí. La regla de actualización para SGD se define como:
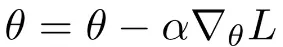
Donde alpha es la tasa de aprendizaje, nabla L es el gradiente con respecto a los parámetros. Como podemos ver, si el gradiente es cero, los parámetros no se actualizan, ya que la regla de actualización es solo una función de los gradientes. Y cuando establecemos requires_grad = False, los gradientes serán cero para esas capas y no se calcularán.
¿Y qué pasa con los optimizadores adaptativos como ADAM u otros en los que la regla de actualización no es solo una función de los gradientes? Veamos ADAM:
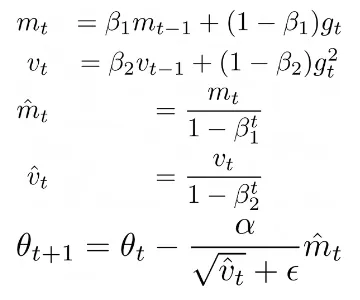
Donde Beta1, Beta2 son algunos hiperparámetros, alpha es la tasa de aprendizaje, mt es el primer momento y vt es el segundo momento de los gradientes gt. Esta regla de actualización permite calcular tasas de aprendizaje adaptativas para cada parámetro. Lo más importante para nuestro problema es que, incluso si el gradiente actual gt se establece en cero mediante requires_grad = False, los parámetros aún se actualizan por el optimizador utilizando los valores almacenados de mt y vt. De hecho, si imprimimos optimizer.state, podemos ver que el optimizador almacena el número de pasos (es decir, el número de actualizaciones de gradientes) que cada parámetro ha tenido, exp_avg, que es el primer momento y exp_avg_sq el segundo momento:
# optimizador paso 1defaultdict(<class 'dict'>, {Parameter containing:tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-5.9304e-04, -1.0966e-04, -5.9985e-05], [ 4.4068e-04, 4.1636e-04, 1.7705e-05], [-1.0544e-04, -2.0357e-04, 1.7783e-04]], device='cuda:0'), 'exp_avg_sq': tensor([[3.5170e-08, 1.2025e-09, 3.5982e-10], [1.9420e-08, 1.7336e-08, 3.1345e-11], [1.1118e-09, 4.1440e-09, 3.1623e-09]], device='cuda:0')}, Parameter containing:tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-0.0038, -0.0056, -0.0037], [ 0.0021, 0.0021, 0.0020], [ 0.0027, 0.0034, 0.0025], [-0.0010, 0.0001, -0.0008]], device='cuda:0'), 'exp_avg_sq': tensor([[1.4261e-06, 3.1517e-06, 1.3953e-06], [4.4782e-07, 4.3352e-07, 3.9994e-07], [7.2213e-07, 1.1702e-06, 6.4754e-07], [1.0547e-07, 1.2353e-09, 6.5470e-08]], device='cuda:0')}})# optimizador paso 2tensor([[ 1.4907, 1.7991, 1.0283], [-1.9122, -1.7133, -1.3428], [ 1.4837, 1.9445, -1.5453]], device='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-5.3374e-04, -9.8693e-05, -5.3987e-05], [ 3.9661e-04, 3.7472e-04, 1.5934e-05], [-9.4899e-05, -1.8321e-04, 1.6005e-04]], device='cuda:0'), 'exp_avg_sq': tensor([[3.5135e-08, 1.2013e-09, 3.5946e-10], [1.9400e-08, 1.7318e-08, 3.1314e-11], [1.1107e-09, 4.1398e-09, 3.1592e-09]], device='cuda:0')}, Parameter containing:tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-0.0002, -0.0025, -0.0017], [ 0.0011, 0.0011, 0.0010], [ 0.0019, 0.0029, 0.0021], [-0.0028, -0.0015, -0.0014]], device='cuda:0'), 'exp_avg_sq': tensor([[2.4608e-06, 3.7819e-06, 1.6833e-06], [5.1839e-07, 4.8712e-07, 4.7173e-07], [7.4856e-07, 1.1713e-06, 6.4888e-07], [4.4950e-07, 2.6660e-07, 1.1588e-07]], device='cuda:0')}, Parameter containing:tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[ 0.0009, 0.0011], [ 0.0045, -0.0002], [ 0.0003, 0.0012]], device='cuda:0'), 'exp_avg_sq': tensor([[8.7413e-08, 1.3188e-07], [1.9946e-06, 4.3840e-09], [8.1403e-09, 1.3691e-07]], device='cuda:0')}})Podemos ver que en la primera actualización optimizer.step() obtenemos solo dos parámetros en los estados del optimizador: hidden_task1 y output. En el segundo paso del optimizador, tenemos todos los parámetros pero notamos que hidden_task1 se actualiza dos veces, lo cual no debería suceder.
Entonces, ¿cómo lidiar con ellos? La solución es en realidad muy simple: en lugar de usar requires_grad, simplemente establezca grad = None para los parámetros. El código se vuelve así:
original_param = {n: p.clone() for (n, p) in net.named_parameters()}print("Parámetros originales ")pprint(original_param)print(100 * "=")# vamos a definir 2 funciones de pérdida (en realidad podríamos definir solo una en este caso ya que son iguales) criterion1 = nn.CrossEntropyLoss()criterion2 = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.9)print("Parámetros después de la actualización de la tarea 1 ")params_hid1 = {n: p.clone() for (n, p) in net.named_parameters()}pprint(params_hid1)print(100 * "=")# salida para la tarea 1 - queremos mantener los parámetros de la capa de la tarea 2 congeladosoutput = net(input1, task='task1')optimizer.zero_grad() # reiniciar los gradientesloss1 = criterion1(output, target1)loss1.backward()# ¡Congelar parámetros aquí!net.freeze_params(['hidden_task2.weight'])optimizer.step()# salida para la tarea 2 - queremos mantener los parámetros de la capa de la tarea 1 congeladosoutput = net(input2, task='task2')optimizer.zero_grad() # reiniciar los gradientesloss2 = criterion2(output, target2)loss2.backward()# ¡Congelar parámetros aquí!net.freeze_params_grad(['hidden_task1.weight'])optimizer.step() # Realiza la actualizaciónprint("Parámetros después de la actualización de la tarea 2 ")params_hid2 = {n: p.clone() for (n, p) in net.named_parameters()}pprint(params_hid2)changed_parameters(params_hid1, params_hid2)Tenga en cuenta que necesitamos establecer
grad = Nonedespués deloss.backward()ya que necesitamos calcular los gradientes para todos los parámetros primero, pero antes deoptimizer.step().
Si ejecutamos el código ahora con el optimizador ADAM, los resultados son los esperados
Parámetros originales {'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parámetros después de la actualización de la tarea 1 {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Cambiados : hidden_task1.weightCambiados : output.weightParámetros después de la actualización de la tarea 2 {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', grad_fn=<CloneBackward0>)}Cambiados : hidden_task2.weightCambiados : output.weightTambién el optimizer.state es ahora diferente: en el segundo paso del optimizador hidden_task1 no se actualiza y su valor de step es 1.
tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], dispositivo='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-5.9304e-04, -1.0966e-04, -5.9985e-05], [ 4.4068e-04, 4.1636e-04, 1.7705e-05], [-1.0544e-04, -2.0357e-04, 1.7783e-04]], dispositivo='cuda:0'), 'exp_avg_sq': tensor([[3.5170e-08, 1.2025e-09, 3.5982e-10], [1.9420e-08, 1.7336e-08, 3.1345e-11], [1.1118e-09, 4.1440e-09, 3.1623e-09]], dispositivo='cuda:0')}, Parámetro que contiene:tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], dispositivo='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-0.0002, -0.0025, -0.0017], [ 0.0011, 0.0011, 0.0010], [ 0.0019, 0.0029, 0.0021], [-0.0028, -0.0015, -0.0014]], dispositivo='cuda:0'), 'exp_avg_sq': tensor([[2.4608e-06, 3.7819e-06, 1.6833e-06], [5.1839e-07, 4.8712e-07, 4.7173e-07], [7.4856e-07, 1.1713e-06, 6.4888e-07], [4.4950e-07, 2.6660e-07, 1.1588e-07]], dispositivo='cuda:0')}, Parámetro que contiene:tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], dispositivo='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[ 0.0009, 0.0011], [ 0.0045, -0.0002], [ 0.0003, 0.0012]], dispositivo='cuda:0'), 'exp_avg_sq': tensor([[8.7413e-08, 1.3188e-07], [1.9946e-06, 4.3840e-09], [8.1403e-09, 1.3691e-07]], dispositivo='cuda:0')}})Distribución de Datos Paralelos
Como nota adicional, en caso de que queramos el soporte de DistributedDataParallel en PyTorch para trabajar con múltiples GPU, necesitamos modificar ligeramente la implementación descrita anteriormente de la siguiente manera:
Es un poco más complicado, y si sabes de una forma más limpia de escribirlo, ¡por favor compártela en los comentarios!
Comentarios
Agradecería cualquier comentario sobre lo anterior, si sabes si puede haber algún problema potencial haciendo esto de esta manera y si hay otras formas de lograr lo mismo.
Conclusiones
En este artículo, describimos cómo congelar capas cuando durante el entrenamiento necesitamos congelar y descongelar algunas capas. Si lo que quieres es congelar completamente algunas de las capas durante todo el entrenamiento, puedes utilizar ambas soluciones descritas en este artículo, ya que no importaría en tu caso si estás utilizando SGD u otro optimizador adaptativo. Sin embargo, como hemos visto, el problema surge cuando necesitas congelar y descongelar capas durante el entrenamiento, y el diferente comportamiento que vemos al utilizar optimizadores cuya regla de actualización depende únicamente del gradiente y aquellos cuya regla de actualización depende de otras variables como el momentum. También puedes encontrar el código completo aquí.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo *no* obtener modelos de aprendizaje automático en producción
- Las Complejidades y Desafíos de Integrar LLMs en Aplicaciones
- 9 puntos clave de Cómo convertirse en un científico de datos por Adam Ross Nelson
- ¿Cómo afectará la IA al papel de los profesionales de datos?
- Nuevos investigadores de Microsoft presentan el modelo de lenguaje multimodal de gran tamaño KOSMOS-2
- Nuevo plan de política de IA presentado por el CEO de los Grammy
- 8 Modelos de Lenguaje Grandes y Nuevos que Debes Tener en Cuenta






