Entendiendo Flash-Atención y Flash-Atención-2 El camino para ampliar la longitud del contexto de los modelos de lenguaje
Comprendiendo Flash-Atención y Flash-Atención-2 para ampliar contexto en modelos de lenguaje
Los dos métodos proporcionan mejoras importantes para procesar secuencias de texto más largas en LLMs.

Recientemente comencé un boletín educativo centrado en la IA, que ya cuenta con más de 160,000 suscriptores. TheSequence es un boletín orientado a ML sin tonterías (lo que significa sin exageraciones, sin noticias, etc.) que se puede leer en 5 minutos. El objetivo es mantenerlo al día con los proyectos de aprendizaje automático, los documentos de investigación y los conceptos. Por favor, pruébelo suscribiéndose a continuación:
TheSequence | Jesus Rodriguez | Substack
La mejor fuente para mantenerse al día con los desarrollos en aprendizaje automático, inteligencia artificial y datos…
thesequence.substack.com
Escalar el contexto de los modelos de lenguaje grandes (LLMs) sigue siendo uno de los desafíos más grandes para expandir el universo de casos de uso. En los últimos meses, hemos visto cómo proveedores como Anthropic o OpenAI han aumentado las longitudes de contexto de sus modelos. Esta tendencia probablemente continuará, pero es probable que requiera avances en la investigación. Uno de los trabajos más interesantes en esta área fue publicado recientemente por la Universidad de Stanford. Conocida como FlashAttention, esta nueva técnica ha sido rápidamente adoptada como uno de los principales mecanismos para aumentar el contexto de LLMs. Recientemente se publicó la segunda versión de FlashAttention, FlashAttention-2. En esta publicación, me gustaría revisar los fundamentos de ambas versiones.
FashAttention v1
En el ámbito de los algoritmos de vanguardia, FlashAttention emerge como un cambio de juego. Este algoritmo no solo reordena el cálculo de atención, sino que también utiliza técnicas clásicas como el enrejado y la recomputación para lograr un aumento notable en la velocidad y una reducción sustancial en el uso de memoria. El cambio es transformador, pasando de una huella de memoria cuadrática a una lineal en relación con la longitud de la secuencia. Para la mayoría de los escenarios, FlashAttention funciona bastante bien, pero tiene un inconveniente: no se ajusta para secuencias excepcionalmente largas, donde falta el paralelismo.
- 9 Tipos Comunes de Ataques en Sistemas de Inteligencia Artificial
- Generación automática de música utilizando Aprendizaje Profundo
- SafeCoder vs. Asistentes de Código de código cerrado
A la hora de abordar el desafío de entrenar Transformers grandes en secuencias extendidas, es fundamental utilizar técnicas modernas de paralelismo como el paralelismo de datos, el paralelismo de canalización y el paralelismo de tensores. Estos enfoques dividen los datos y los modelos en numerosas GPUs, lo que puede resultar en tamaños de lote minúsculos (piense en un tamaño de lote de 1 con paralelismo de canalización) y un número modesto de cabezas, generalmente entre 8 y 12 con paralelismo de tensores. Precisamente este escenario es el que FlashAttention busca optimizar.
Para cada cabeza de atención, FlashAttention adopta técnicas clásicas de enrejado para minimizar las lecturas y escrituras de memoria. Transfiere bloques de consulta, clave y valor de la memoria principal (HBM) de la GPU a su memoria caché rápida (SRAM). Después de realizar cálculos de atención en este bloque, vuelve a escribir la salida en HBM. Esta reducción de lectura/escritura de memoria produce una aceleración sustancial, a menudo de 2 a 4 veces la velocidad original en la mayoría de los casos de uso.
La primera iteración de FlashAttention se aventuró en la paralelización sobre el tamaño del lote y el número de cabezas. Aquellos familiarizados con la programación CUDA apreciarán la implementación de un bloque de hilos para procesar cada cabeza de atención, lo que resulta en un total de batch_size * num_heads bloques de hilos. Cada bloque de hilos se programa meticulosamente para ejecutarse en un multiprocesador de transmisión (SM), con una GPU A100 que cuenta con un generoso número de 108 de estos SM. Esta habilidad de programación realmente brilla cuando batch_size * num_heads alcanza valores considerables, digamos, mayores o iguales a 80. En tales casos, permite la utilización eficiente de casi todos los recursos computacionales de la GPU.
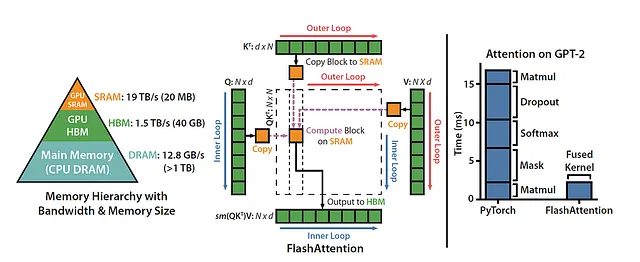
Sin embargo, cuando se trata de manejar secuencias largas, generalmente asociadas con tamaños de lote pequeños o un número limitado de cabezas, FlashAttention adopta un enfoque diferente. Ahora introduce la paralelización sobre la dimensión de la longitud de la secuencia, lo que resulta en mejoras de velocidad notables adaptadas a este dominio específico.
Cuando se trata del pase hacia atrás, FlashAttention opta por una estrategia de paralelización ligeramente alterada. Cada trabajador se encarga de un bloque de columnas dentro de la matriz de atención. Estos trabajadores colaboran y se comunican para agregar el gradiente en relación a la consulta, empleando operaciones atómicas para este propósito. Curiosamente, FlashAttention ha descubierto que la paralelización por columnas supera a la paralelización por filas en este contexto. La comunicación reducida entre los trabajadores resulta ser la clave, ya que la paralelización por columnas implica agregar el gradiente de la consulta, mientras que la paralelización por filas implica agregar el gradiente de la clave y el valor.

FlashAttention-2
Con FlashAttention-2, el equipo de Stanford implementa una refinación cuidadosa a la versión inicial, centrándose en minimizar los FLOPs no matmul dentro del algoritmo. Este ajuste tiene una gran importancia en la era de las GPU modernas, que vienen equipadas con unidades de cálculo especializadas como los Tensor Cores de Nvidia, acelerando enormemente las multiplicaciones de matrices (matmul).
FlashAttention-2 también revisa la técnica de softmax en línea en la que se basa. El objetivo es agilizar las operaciones de reescalamiento, comprobación de límites y enmascaramiento causal, al mismo tiempo que se preserva la integridad de la salida.
En su iteración inicial, FlashAttention aprovechó el paralelismo tanto en el tamaño del lote como en el número de cabezas. Aquí, cada cabeza de atención fue procesada por un bloque de hilos dedicado, lo que resultó en un total de (tamaño_del_lote * número de cabezas) bloques de hilos. Estos bloques de hilos se programaron de manera eficiente en los multiprocesadores de transmisión (SM), con una GPU A100 ejemplar que cuenta con 108 SM. Esta estrategia de programación resultó más efectiva cuando el número total de bloques de hilos era sustancial, generalmente superando los 80, ya que permitía la utilización óptima de los recursos computacionales de la GPU.
Para mejorar en escenarios que involucran secuencias largas, a menudo acompañadas de tamaños de lote pequeños o un número limitado de cabezas, FlashAttention-2 introduce una dimensión adicional de paralelismo: la paralelización sobre la longitud de la secuencia. Esta adaptación estratégica proporciona mejoras significativas de velocidad en este contexto particular.
Incluso dentro de cada bloque de hilos, FlashAttention-2 debe dividir cuidadosamente la carga de trabajo entre diferentes grupos de 32 hilos que operan en conjunto. Por lo general, se emplean 4 u 8 grupos de hilos por bloque, y el esquema de particionamiento se explica a continuación. En FlashAttention-2, esta metodología de particionamiento se perfecciona con el objetivo de reducir la sincronización y comunicación entre los diferentes grupos de hilos, minimizando así las lecturas y escrituras de memoria compartida.
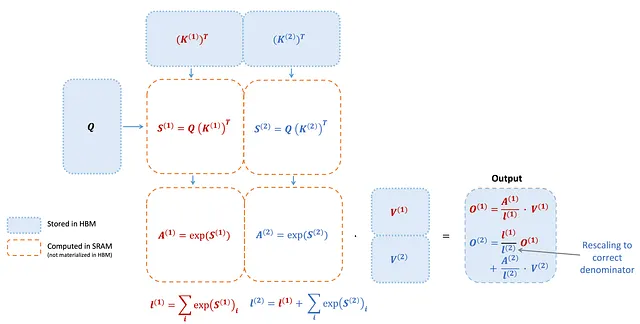
En la configuración anterior, FlashAttention dividía K y V en 4 grupos de hilos mientras mantenía la accesibilidad de Q para todos los grupos de hilos, lo que se denomina “esquema K dividido”. Sin embargo, este enfoque mostraba ineficiencias, ya que todos los grupos de hilos necesitaban escribir sus resultados intermedios en memoria compartida, sincronizarse y luego agregar estos resultados. Estas operaciones de memoria compartida imponían un cuello de botella de rendimiento en el pase hacia adelante de FlashAttention.
En FlashAttention-2, la estrategia toma un rumbo diferente. Ahora se asigna Q a 4 grupos de hilos, asegurando que K y V sigan siendo accesibles para todos los grupos de hilos. Después de que cada grupo de hilos realiza la multiplicación de matrices para obtener una sección de Q K^T, simplemente lo multiplican con la sección compartida de V para obtener su respectiva sección de salida. Esta disposición elimina la necesidad de comunicación entre grupos de hilos. La reducción en las lecturas/escrituras de memoria compartida se traduce en una mejora significativa de velocidad.
La versión anterior de FlashAttention admitía dimensiones de cabezas de hasta 128, suficiente para la mayoría de los modelos pero dejando algunos en un segundo plano. FlashAttention-2 extiende su soporte a dimensiones de cabezas de hasta 256, lo que permite acomodar modelos como GPT-J, CodeGen, CodeGen2 y StableDiffusion 1.x. Estos modelos ahora pueden aprovechar FlashAttention-2 para una mayor velocidad y eficiencia de memoria.
Además, FlashAttention-2 introduce soporte para atención de múltiples consultas (MQA) y atención de consultas agrupadas (GQA). Estas son variantes especializadas de atención donde varias cabezas de la consulta asisten simultáneamente a la misma cabeza de clave y valor. Esta maniobra estratégica tiene como objetivo reducir el tamaño de la memoria caché KV durante la inferencia, lo que finalmente conduce a un rendimiento de inferencia significativamente mayor.
Las Mejoras
El equipo de Stanford evaluó FlashAttention-2 en diferentes pruebas con mejoras notables en comparación con la versión original y otras alternativas. Las pruebas incluyeron diferentes variaciones en la arquitectura de atención y los resultados fueron bastante notables.
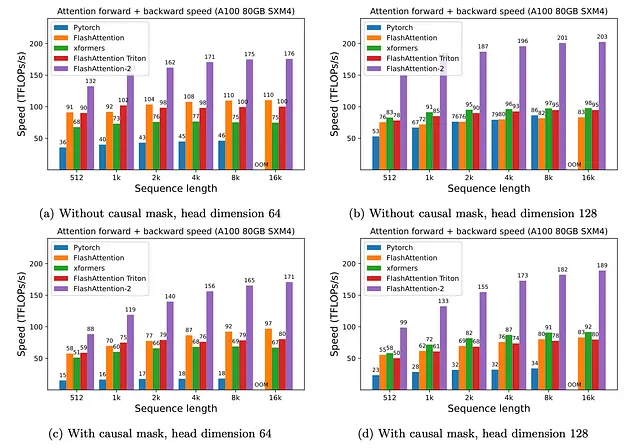
FlashAttention y FlashAttention-2 son dos de las técnicas fundamentales utilizadas para ampliar el contexto de los LLMs. La investigación representa uno de los mayores avances en esta área y está influyendo en nuevos métodos que pueden ayudar a aumentar la capacidad de los LLMs.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Trabajando con Big Data Herramientas y Técnicas
- Investigadores de Sony proponen BigVSAN Revolucionando la calidad de audio con el uso de Slicing Adversarial Networks en vocoders basados en GAN.
- Conoce ResFields Un enfoque novedoso de IA para superar las limitaciones de los campos neurales espaciotemporales en la modelización efectiva de señales temporales largas y complejas.
- Descubriendo los secretos del rendimiento catalítico con Deep Learning Un estudio en profundidad de la Red Neuronal Convolucional ‘Global + Local’ para la detección de alta precisión de catalizadores heterogéneos
- Una nueva investigación de AI de Apple y Equall AI revela redundancias en la arquitectura de Transformer Cómo optimizar la red de avance de alimentación mejora la eficiencia y la precisión
- 10 Mejores Herramientas de Extracción de Datos (Septiembre 2023)
- Datos de satélite, incendios forestales y IA Protegiendo la industria vitivinícola ante los desafíos climáticos






