Comprendiendo los Algoritmos de Aprendizaje Automático Una Visión General Detallada
Comprender los Algoritmos de Aprendizaje Automático Una Visión General Detallada

Aprendizaje automático. Un bloque impresionante de palabras, ¿verdad? Dado que la IA y sus herramientas, como ChatGPT y Bard, están en auge en este momento, es hora de profundizar y aprender los fundamentos.
Estos conceptos fundamentales pueden no iluminarte de inmediato, pero si estás interesado en los conceptos, tendrás enlaces adicionales para profundizar aún más.
La fortaleza del aprendizaje automático proviene de sus algoritmos complejos, que se encuentran en el núcleo de cada proyecto de aprendizaje automático. A veces, estos algoritmos incluso se inspiran en la cognición humana, como el reconocimiento de voz o el reconocimiento facial.
- Los Chatbots de IA construyen software en minutos por menos de $1
- 4 formas de codificar características categóricas con alta cardinalidad – con implementación en Python
- Aprendizaje automático inspirado en Indigos como una búsqueda poética de perspicacia
En este artículo, explicaremos primero las clases de aprendizaje automático, como el aprendizaje supervisado, no supervisado y por refuerzo.
Luego, profundizaremos en las tareas que maneja el aprendizaje automático, como la clasificación, la regresión y el agrupamiento.
Después de eso, descubriremos en detalle los árboles de decisiones, las máquinas de vectores de soporte y los vecinos más cercanos, y la regresión lineal, visualmente y con definiciones.
Pero, por supuesto, ¿cómo puedes elegir el mejor algoritmo que se alinee con tus necesidades? Por supuesto, comprender conceptos como “comprender los datos” o “definir tu problema” te guiará para abordar posibles desafíos y obstáculos en tu proyecto.
¡Comencemos el viaje del aprendizaje automático!
Categorías de aprendizaje automático
Cuando exploramos el aprendizaje automático, podemos ver que hay tres categorías principales que dan forma a su marco.
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje por refuerzo.
En el aprendizaje supervisado, la etiqueta que deseas predecir está en el conjunto de datos.
En este escenario, el algoritmo actúa como un aprendiz cuidadoso, asociando características con salidas correspondientes. Después de que finaliza la fase de aprendizaje, puede proyectar la salida para los nuevos datos y los datos de prueba. Considera escenarios como etiquetar correos electrónicos no deseados o predecir precios de casas.
Imagina estudiar sin un mentor al lado; debe ser desalentador. Los métodos de aprendizaje no supervisado en particular hacen esto, haciendo predicciones sin etiquetas.
Se adentran valientemente en lo desconocido, descubriendo patrones ocultos y estructuras en datos no etiquetados, similar a exploradores que descubren artefactos perdidos.
Entender la estructura genética en biología y la segmentación de clientes en marketing son ejemplos de aprendizaje no supervisado.
Finalmente, llegamos al aprendizaje por refuerzo, donde el algoritmo aprende cometiendo errores, al igual que un cachorro pequeño. Imagina enseñar a una mascota: se desalienta el mal comportamiento, mientras que se recompensa el buen comportamiento.
De manera similar, el algoritmo toma acciones, experimenta recompensas o penalizaciones y finalmente descubre cómo optimizar. Esta estrategia se utiliza con frecuencia en industrias como la robótica y los videojuegos.
Tipos de aprendizaje automático
Aquí dividiremos los algoritmos de aprendizaje automático en tres subsecciones. Estas subsecciones son la clasificación, la regresión y el agrupamiento.
Clasificación
Como su nombre indica, la clasificación se centra en el proceso de agrupar o categorizar elementos. Imagínate como un botánico asignado a clasificar plantas en categorías benignas o peligrosas según diferentes características. Es similar a clasificar dulces en frascos diferentes según sus colores.
Regresión
La regresión es el siguiente paso; piénsalo como un intento de predecir variables numéricas.
El objetivo en esta situación es predecir una cierta variable, como el costo de una propiedad considerando sus características (número de habitaciones, ubicación, etc.).
Es similar a determinar la cantidad de fruta a partir de sus dimensiones, porque no hay categorías claramente definidas, sino más bien un rango continuo.
Agrupamiento
Ahora llegamos al agrupamiento, que es comparable a organizar ropa desorganizada. Incluso si no tienes categorías predefinidas (o etiquetas), aún puedes agrupar objetos relacionados.
Imagina un algoritmo que, sin conocimiento previo de los temas involucrados, clasifica noticias en función de esos temas. ¡El agrupamiento es obvio ahí!
Analicemos algunos algoritmos populares que realizan estas tareas, ¡porque aún hay mucho más por explorar!
Algoritmos populares de aprendizaje automático
Aquí, nos adentraremos en algoritmos populares de aprendizaje automático, como Árboles de Decisión, Máquinas de Vectores de Soporte, Vecinos más Cercanos y Regresión Lineal.
A. Árbol de Decisión
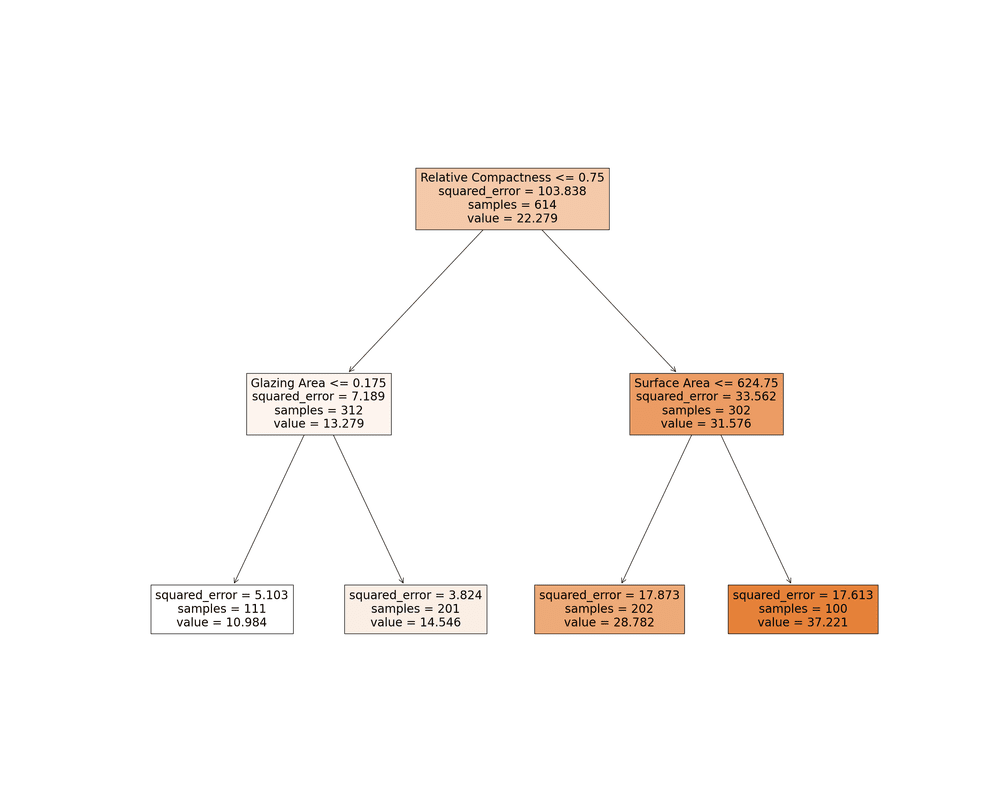
Imagina que estás planeando un evento al aire libre y debes decidir si continuar o cancelarlo dependiendo del clima. Un Árbol de Decisión se puede utilizar para representar este proceso de toma de decisiones.
Un método de Árbol de Decisión en el campo del aprendizaje automático (ML) hace una serie de preguntas binarias sobre los datos (por ejemplo, “¿Está lloviendo?”) hasta llegar a una decisión (continuar con la recolección o detenerla). Este método es muy útil cuando necesitamos entender el razonamiento detrás de una predicción.
Si deseas obtener más información sobre los árboles de decisión, puedes leer el artículo “Árbol de Decisión y Algoritmo de Bosque Aleatorio (básicamente un árbol de decisión mejorado)”.
B. Máquinas de Vectores de Soporte (SVM)
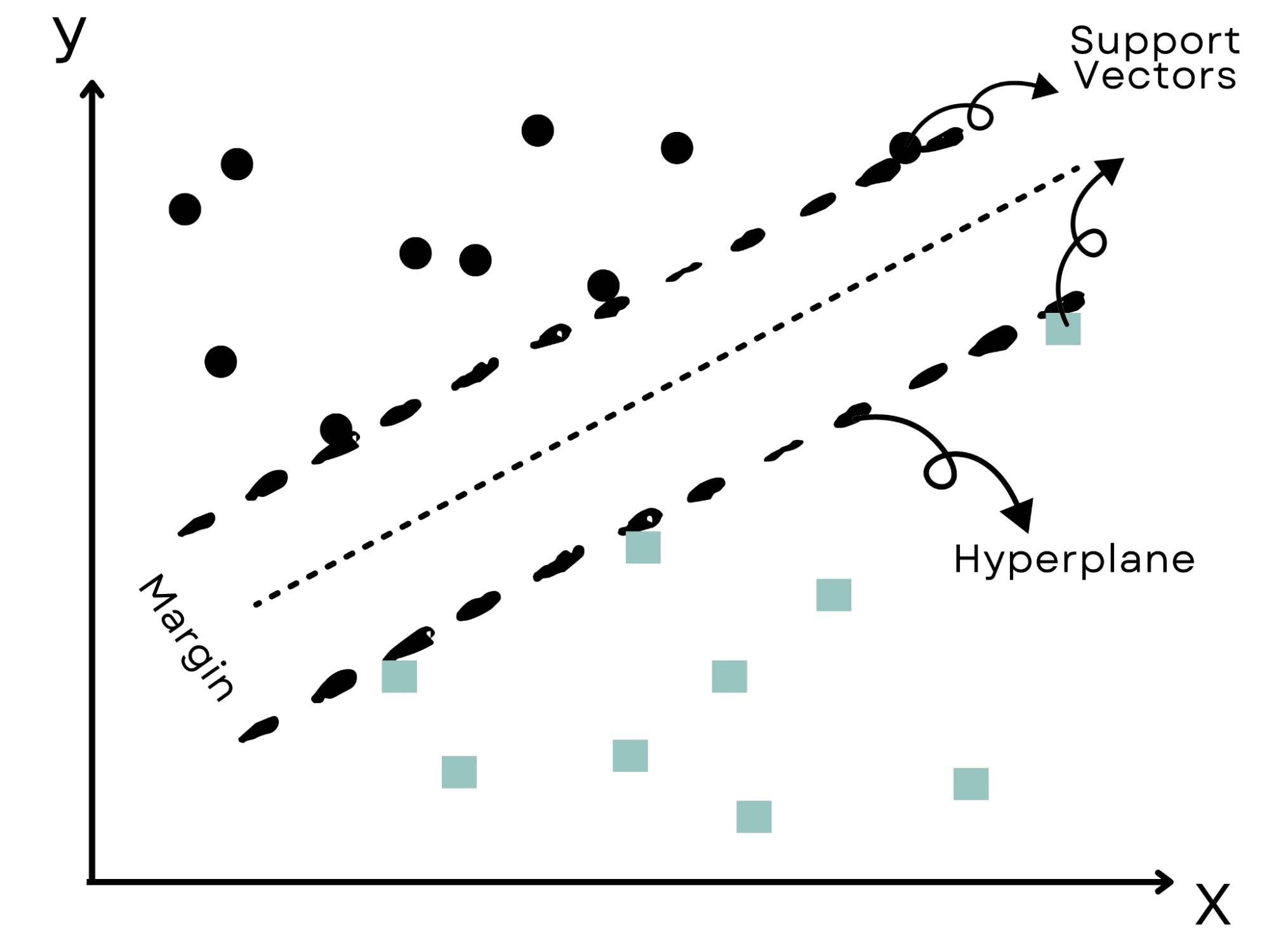
Imagina un escenario similar al Salvaje Oeste donde el objetivo es dividir dos grupos rivales.
Para evitar conflictos, elegiríamos el límite práctico más grande; esto es exactamente lo que hacen las Máquinas de Vectores de Soporte (SVM).
Identifican el ‘hiperplano’ o límite más efectivo que divide los datos en grupos mientras mantiene la mayor distancia de los puntos de datos más cercanos.
Aquí puedes encontrar más información sobre las SVM.
C. Vecinos más Cercanos (KNN)
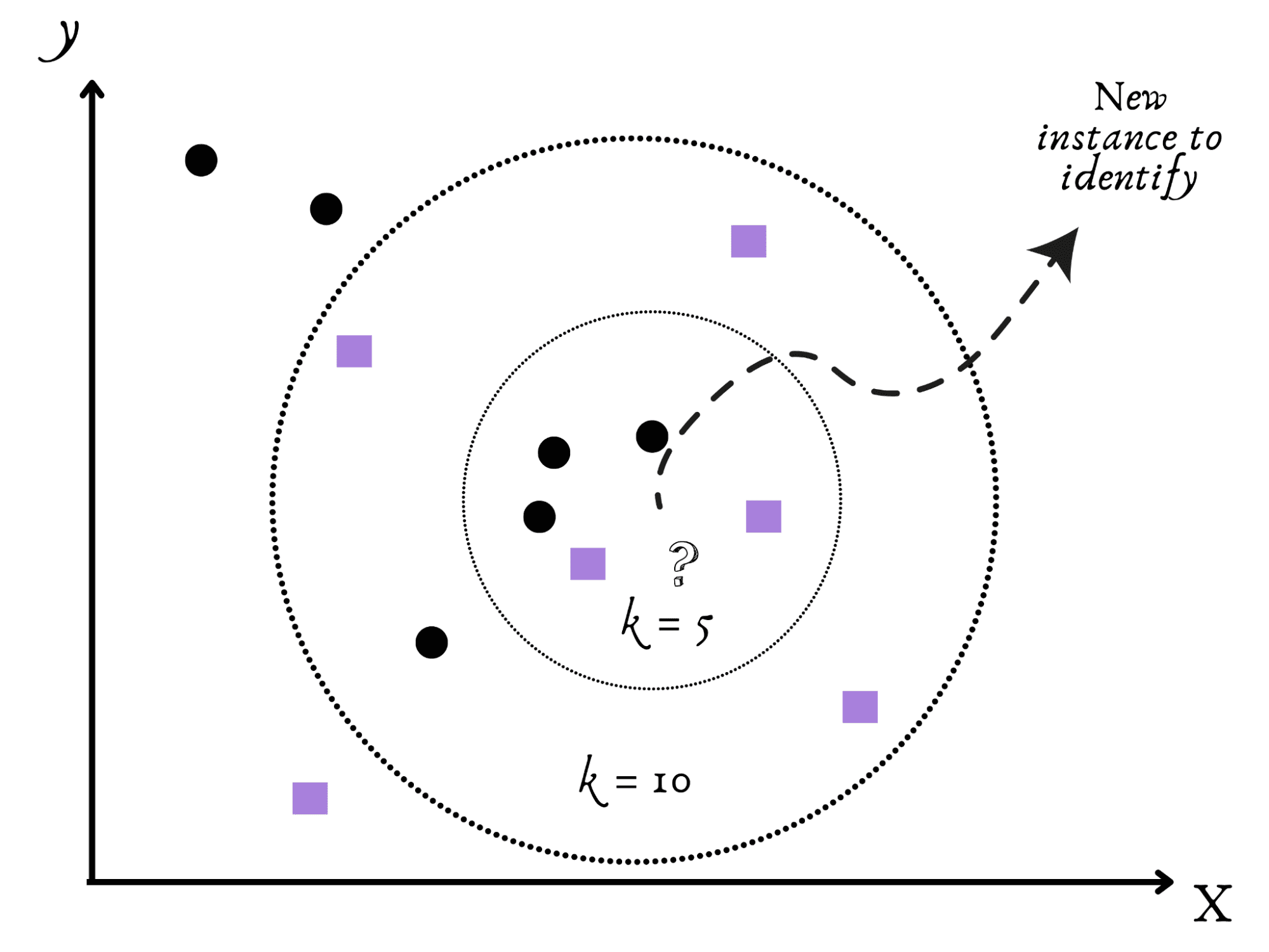
A continuación, tenemos el algoritmo amigable y social de los Vecinos más Cercanos (KNN).
Imagina que te mudas a una nueva ciudad y tratas de averiguar si es tranquila o bulliciosa.
Tiene sentido que tu curso de acción natural sea observar a tus vecinos más cercanos para obtener información.
Similar a esto, KNN clasifica nuevos datos según los argumentos, como k, de sus vecinos más cercanos en el conjunto de datos.
Aquí puedes obtener más información sobre KNN.
D. Regresión Lineal
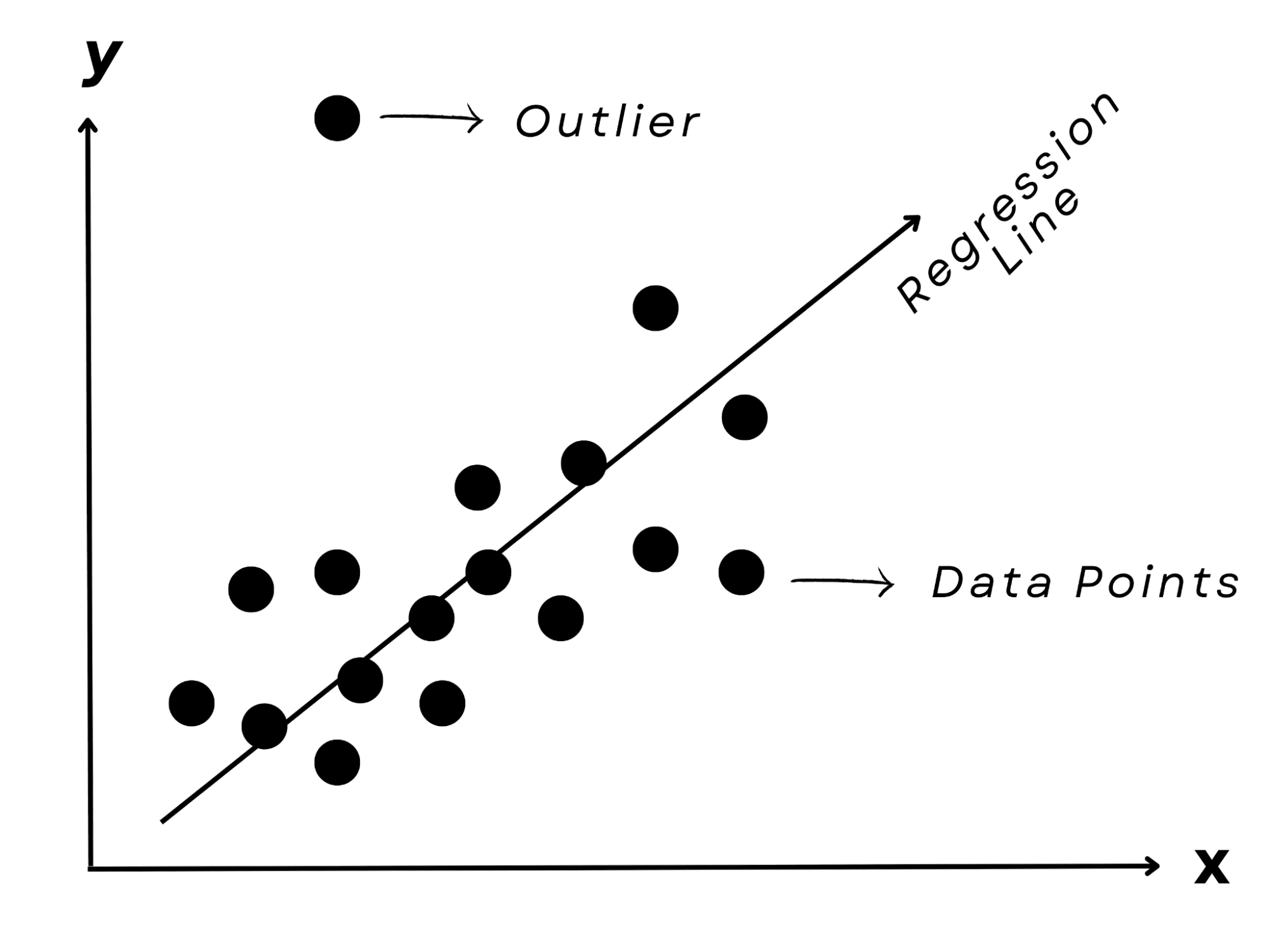
Por último, imagina que intentas predecir el resultado de un examen de un amigo en función de las horas que estudió. Probablemente notarías un patrón: más tiempo dedicado al estudio generalmente se traduce en mejores resultados.
Un modelo de regresión lineal, que como su nombre indica, representa la conexión lineal entre la entrada (horas de estudio) y la salida (nota del examen), puede capturar esta correlación.
Es un enfoque popular para predecir valores numéricos, como el costo de bienes raíces o los valores del mercado de valores.
Para obtener más información sobre la regresión lineal, puedes leer este artículo.
Elegir el modelo de aprendizaje automático adecuado
Elegir el algoritmo correcto entre todas las opciones disponibles puede parecer como buscar una aguja en un pajar muy grande. ¡Pero no te preocupes! Vamos a aclarar este proceso con algunas cosas importantes en las que debes pensar.
A. Comprender tus datos
Considera tus datos como un mapa del tesoro que contiene pistas sobre el mejor algoritmo.
- ¿Tus datos tienen etiquetas? (Aprendizaje supervisado vs. no supervisado)
- ¿Cuántas características incluye? (¿Necesitamos reducción de dimensionalidad?)
- ¿Son categóricos o numéricos? (¿Clasificación o regresión?)
Las respuestas a estas preguntas podrían orientarte en la dirección correcta. En contraste, los datos sin etiquetar podrían fomentar algoritmos de aprendizaje no supervisado como el agrupamiento. Por ejemplo, los datos etiquetados fomentan el uso de algoritmos de aprendizaje supervisado como los árboles de decisión.
B. Define Tu Problema
Imagina usar un destornillador para clavar un clavo; no es muy efectivo, ¿verdad?
El “herramienta” o algoritmo correcto se elige al definir claramente tu problema. ¿Tu objetivo es identificar patrones ocultos (agrupamiento), predecir una categoría (clasificación) o una métrica (regresión)?
Hay algoritmos compatibles para cada tipo de tarea.
C. Considera Aspectos Prácticos
Un algoritmo ideal puede funcionar ocasionalmente peor en aplicaciones reales de lo que lo hace en teoría. La cantidad de datos que tienes, los recursos computacionales disponibles y la necesidad de los resultados juegan roles importantes.
Recuerda que ciertos algoritmos, como KNN, podrían tener un rendimiento deficiente con conjuntos de datos grandes, mientras que otros, como Naive Bayes, podrían funcionar bien con datos complejos.
D. Nunca Subestimes la Evaluación
Finalmente, es crucial evaluar y validar el rendimiento de tu modelo. Quieres asegurarte de que el algoritmo funcione de manera efectiva con tus datos, similar a probarse ropa antes de realizar una compra.
Esta “adaptación” se puede medir utilizando una variedad de medidas, como la precisión para tareas de clasificación o el error cuadrado medio para tareas de regresión.
Conclusión
¿No hemos recorrido un largo camino?
Al igual que categorizar una biblioteca en diferentes géneros, comenzamos dividiendo el campo del aprendizaje automático en Aprendizaje Supervisado, No Supervisado y Reforzamiento. Luego, para entender la diversidad de libros dentro de estos géneros, profundizamos en los tipos de tareas como clasificación, regresión y agrupamiento que se encuentran bajo estos encabezados.
Primero conocimos algunos de los algoritmos de ML, que incluyen Árboles de Decisión, Máquinas de Vectores de Soporte, Vecinos más Cercanos, Naive Bayes y Regresión Lineal. Cada uno de estos algoritmos tiene sus propias especialidades y fortalezas.
También nos dimos cuenta de que elegir el algoritmo adecuado es como seleccionar al actor ideal para un papel, teniendo en cuenta los datos, la naturaleza del problema, las aplicaciones del mundo real y la evaluación del rendimiento.
Cada proyecto de aprendizaje automático ofrece un viaje distinto, al igual que cada libro brinda una nueva narrativa.
Ten en cuenta que aprender, experimentar y mejorar son más importantes que siempre hacerlo bien la primera vez.
Así que prepárate, ponte tu gorra de científico de datos y ¡embárcate en tu propia aventura de ML! Nate Rosidi es un científico de datos y estratega de productos. También es profesor adjunto que enseña análisis de datos y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas reales de empresas importantes. Conéctate con él en Twitter: StrataScratch o LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una Guía Completa de las Bases de Datos de Vectores de Pinecone
- Visión general de los esquemas de cuantización admitidos de forma nativa en 🤗 Transformers
- Estadísticas en Ciencia de Datos Teoría y Visión General
- ¿Cómo podemos mitigar el sesgo inducido por el fondo en la clasificación de imágenes de granularidad fina? Un estudio comparativo de estrategias de enmascaramiento y arquitecturas de modelos
- Investigadores de Google proponen MEMORY-VQ un nuevo enfoque de IA para reducir los requisitos de almacenamiento de los modelos de memoria aumentada sin sacrificar el rendimiento
- ¿Qué características son perjudiciales para su modelo de clasificación?
- Conoce T2I-Adapter-SDXL Modelos de Control Pequeños y Eficientes.






