Guía completa de métricas de evaluación de clasificación
Complete guide to classification evaluation metrics
Explora una amplia variedad de métricas y encuentra la mejor para tu problema
Introducción
La clasificación es un problema en el aprendizaje automático donde el objetivo es ordenar una lista de documentos para un usuario final de la manera más adecuada, para que los documentos más relevantes aparezcan en la parte superior. La clasificación aparece en varios dominios de la ciencia de datos, comenzando desde los sistemas de recomendación donde un algoritmo sugiere un conjunto de elementos para su compra y terminando con los motores de búsqueda de procesamiento del lenguaje natural (NLP) donde, a partir de una consulta dada, el sistema intenta devolver los resultados de búsqueda más relevantes.
La pregunta que surge naturalmente es cómo estimar la calidad de un algoritmo de clasificación. Como en el aprendizaje automático clásico, no existe una única métrica universal que sea adecuada para cualquier tipo de tarea. ¿Por qué? Simplemente porque cada métrica tiene su propio campo de aplicación que depende de la naturaleza de un problema dado y de las características de los datos.
Por eso es crucial conocer todas las métricas principales para abordar con éxito cualquier problema de aprendizaje automático. Esto es exactamente lo que vamos a hacer en este artículo.
- ¿Qué tan aleatorios son los goles en el fútbol?
- Consulta tus DataFrames con potentes modelos de lenguaje grandes utilizando LangChain.
- Transformada de Fourier para series de tiempo Graficando números complejos
Sin embargo, antes de seguir adelante, debemos entender por qué ciertas métricas populares no deberían utilizarse normalmente para la evaluación de clasificación. Al tener en cuenta esta información, será más fácil comprender la necesidad de la existencia de otras métricas más sofisticadas.
Nota. El artículo y las fórmulas utilizadas se basan en la presentación sobre la evaluación sin conexión de Ilya Markov.
Métricas
Existen varios tipos de métricas de recuperación de información que vamos a discutir en este artículo:
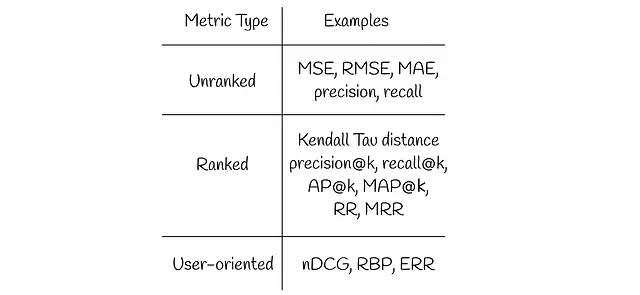
Métricas no clasificadas
Imagina un sistema de recomendación que predice calificaciones de películas y muestra las películas más relevantes a los usuarios. La calificación suele representar un número real positivo. A primera vista, una métrica de regresión como MSE (RMSE, MAE, etc.) parece una elección razonable para evaluar la calidad del sistema en un conjunto de datos de prueba.
MSE tiene en cuenta todas las películas predichas y mide el error cuadrático medio promedio entre las etiquetas verdaderas y las predichas. Sin embargo, los usuarios finales generalmente están interesados solo en los resultados principales que aparecen en la primera página de un sitio web. Esto indica que realmente no están interesados en películas con calificaciones más bajas que aparecen al final de los resultados de búsqueda y que también son igualmente estimadas por las métricas de regresión estándar.
Un ejemplo simple a continuación demuestra un par de resultados de búsqueda y mide el valor de MSE en cada uno de ellos.

Aunque el segundo resultado de búsqueda tiene un MSE más bajo, el usuario no estará satisfecho con esa recomendación. Al mirar solo los elementos no relevantes primero, el usuario tendrá que desplazarse hacia abajo hasta encontrar el primer elemento relevante. Por eso, desde la perspectiva de la experiencia del usuario, el primer resultado de búsqueda es mucho mejor: el usuario está feliz con el elemento superior y procede a él sin preocuparse por los demás.
La misma lógica se aplica a las métricas de clasificación (precisión, recuperación) que también consideran todos los elementos.

¿Qué tienen en común todas las métricas descritas? Todas ellas consideran todos los elementos por igual y no tienen en cuenta ninguna diferenciación entre resultados de alta y baja relevancia. Por eso se llaman no clasificadas.
Al haber pasado por estos dos ejemplos problemáticos similares anteriores, el aspecto en el que debemos enfocarnos al diseñar una métrica de clasificación parece más claro:
Una métrica de clasificación debe poner más peso en los resultados más relevantes mientras reduce o ignora los menos relevantes.
Métricas clasificadas
Distancia de Kendall Tau
La distancia de Kendall Tau se basa en el número de inversiones de clasificación.
Una inversión es un par de documentos (i, j) en el que el documento i, que tiene una relevancia mayor que el documento j, aparece después en los resultados de búsqueda que j.
La distancia de Kendall Tau calcula todas las inversiones en la clasificación. Cuanto menor sea el número de inversiones, mejor será el resultado de búsqueda. Aunque la métrica puede parecer lógica, todavía tiene una desventaja que se demuestra en el siguiente ejemplo.
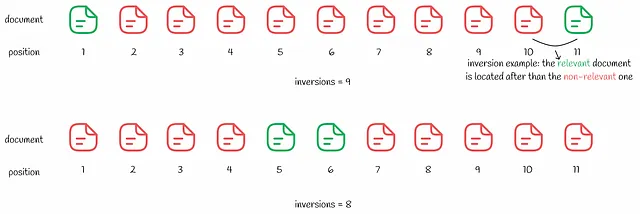
Parece que el segundo resultado de búsqueda es mejor con solo 8 inversiones en comparación con 9 en el primero. Al igual que en el ejemplo del error cuadrático medio anterior, al usuario solo le interesa el primer resultado relevante. Al pasar por varios resultados de búsqueda no relevantes en el segundo caso, la experiencia del usuario será peor que en el primer caso.
Precisión@k y Recall@k
En lugar de la precisión y el recall habituales, es posible considerar solo un cierto número de recomendaciones principales k. De esta manera, la métrica no se preocupa por los resultados de baja clasificación. Dependiendo del valor elegido de k, las métricas correspondientes se denotan como precisión@k (“precisión en k”) y recall@k (“recuperación en k”) respectivamente. Sus fórmulas se muestran a continuación.

Imaginemos que se muestran al usuario los k mejores resultados en los que cada resultado puede ser relevante o no. precisión@k mide el porcentaje de resultados relevantes entre los k mejores resultados. Al mismo tiempo, recall@k evalúa la proporción de resultados relevantes entre los k mejores y el número total de elementos relevantes en todo el conjunto de datos.
Para comprender mejor el proceso de cálculo de estas métricas, veamos el ejemplo a continuación.
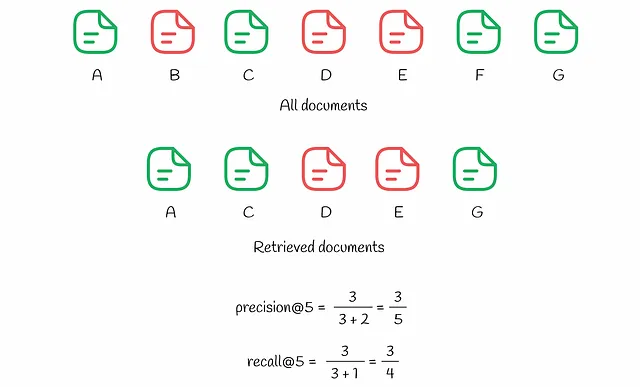
Hay 7 documentos en el sistema (nombrados de A a G). Según sus predicciones, el algoritmo elige k = 5 documentos entre ellos para el usuario. Como podemos observar, hay 3 documentos relevantes (A, C, G) entre los k = 5 mejores resultados, lo que hace que la precisión@5 sea igual a 3 / 5. Al mismo tiempo, recall@5 tiene en cuenta los elementos relevantes en todo el conjunto de datos: hay 4 de ellos (A, C, F y G), lo que hace que recall@5 = 3 / 4.
recall@k siempre aumenta con el crecimiento de k, lo que hace que esta métrica no sea realmente objetiva en algunos escenarios. En el caso extremo en el que se muestran al usuario todos los elementos del sistema, el valor de recall@k es igual al 100%. precisión@k no tiene la misma propiedad monotónica que tiene recall@k, ya que mide la calidad de clasificación en relación con los mejores k resultados, no en relación con el número de elementos relevantes en todo el sistema. La objetividad es una de las razones por las que precisión@k suele ser una métrica preferida sobre recall@k en la práctica.
AP@k (Precisión Promedio) y MAP@k (Precisión Promedio Media)
El problema con la precisión@k básica es que no tiene en cuenta el orden de los elementos relevantes que aparecen entre los documentos recuperados. Por ejemplo, si hay 10 documentos recuperados y 2 de ellos son relevantes, la precisión@10 siempre será la misma independientemente de la ubicación de estos 2 documentos entre los 10. Por ejemplo, si los elementos relevantes se encuentran en las posiciones (1, 2) o (9, 10), la métrica no diferencia ambos casos, lo que resulta en una precisión@10 igual a 0.2.
Sin embargo, en la vida real, el sistema debería otorgar mayor importancia a los documentos relevantes clasificados en la parte superior en lugar de en la parte inferior. Este problema se resuelve mediante otra métrica llamada precisión promedio (AP). Al igual que la precisión normal, AP toma valores entre 0 y 1.

AP@k calcula el valor promedio de la precisión@i para todos los valores de i desde 1 hasta k para aquellos en los que el i-ésimo documento es relevante.
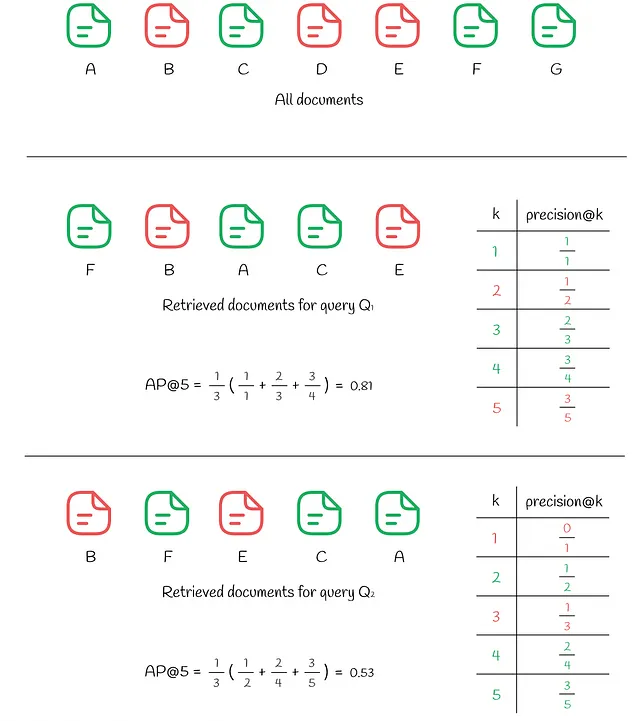
En la figura de arriba, podemos ver los mismos 7 documentos. La respuesta a la consulta Q₁ resultó en k = 5 documentos recuperados donde 3 documentos relevantes se encuentran en las posiciones (1, 3, 4). Para cada una de estas posiciones i, se calcula la precisión@i:
- precisión@1 = 1 / 1
- precisión@3 = 2 / 3
- precisión@4 = 3 / 4
Se ignoran todos los demás índices i que no coinciden. El valor final de AP@5 se calcula como un promedio de las precisiones anteriores:
- AP@5 = (precisión@1 + precisión@3 + precisión@4) / 3 = 0.81
Para comparar, veamos la respuesta a otra consulta Q₂ que también contiene 3 documentos relevantes entre los primeros k. Sin embargo, esta vez, 2 documentos irrelevantes se encuentran en una posición más alta en la parte superior (en las posiciones (1, 3)) que en el caso anterior, lo que resulta en un AP@5 más bajo igual a 0.53.
A veces es necesario evaluar la calidad del algoritmo no en una sola consulta sino en varias consultas. Para ese propósito, se utiliza el promedio de precisión promedio (MAP). Simplemente toma la media de AP entre varias consultas Q:
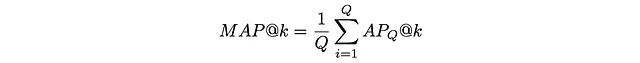
El ejemplo a continuación muestra cómo se calcula MAP para 3 consultas diferentes:

RR (Reciprocal Rank) y MRR (Mean Reciprocal Rank)
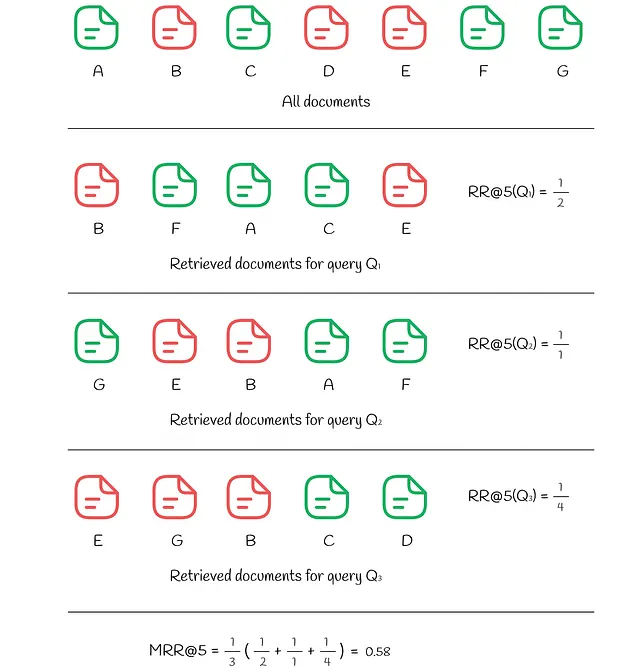
A veces los usuarios están interesados solo en el primer resultado relevante. El rango recíproco es una métrica que devuelve un número entre 0 y 1 que indica qué tan lejos está el primer resultado relevante de la parte superior: si el documento se encuentra en la posición k, entonces el valor de RR es 1 / k.
De manera similar a AP y MAP, el promedio de rangos recíprocos (MRR) mide el RR promedio entre varias consultas.

El ejemplo a continuación muestra cómo se calculan RR y MRR para 3 consultas:
Métricas orientadas al usuario
Aunque las métricas ordenadas consideran las posiciones de clasificación de los elementos, por lo que son una opción preferible en comparación con las no ordenadas, aún tienen una desventaja significativa: no se tiene en cuenta la información sobre el comportamiento del usuario.
Los enfoques orientados al usuario hacen ciertas suposiciones sobre el comportamiento del usuario y, en función de ello, producen métricas que se adaptan mejor a los problemas de clasificación.
DCG (Ganancia acumulada descontada) y nDCG (Ganancia acumulada descontada normalizada)
El uso de la métrica DCG se basa en la siguiente suposición:
Los documentos altamente relevantes son más útiles cuando aparecen antes en una lista de resultados de un motor de búsqueda (tienen rangos más altos) – Wikipedia
Esta suposición representa naturalmente cómo los usuarios evalúan los resultados de búsqueda más altos en comparación con los que se presentan en posiciones inferiores.
En DCG, a cada documento se le asigna una ganancia que indica cuán relevante es un documento en particular. Dado un valor de relevancia real Rᵢ para cada elemento, existen varias formas de definir una ganancia. Una de las más populares es:
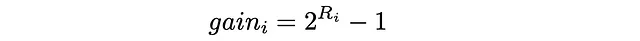
Básicamente, el exponente pone un fuerte énfasis en los elementos relevantes. Por ejemplo, si a una película se le asigna una calificación entre 0 y 5, cada película con una calificación correspondiente tendrá aproximadamente el doble de importancia en comparación con una película con la calificación reducida en 1:
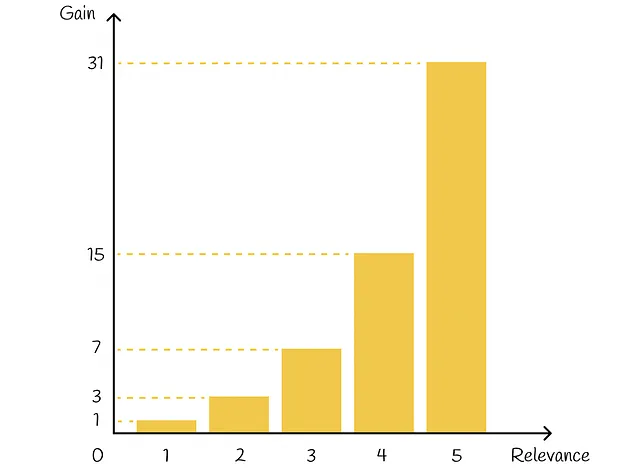
Además de esto, en función de su posición de clasificación, cada elemento recibe un valor de descuento: cuanto mayor sea la posición de clasificación de un elemento, mayor será el descuento correspondiente. El descuento actúa como una penalización al reducir proporcionalmente la ganancia del elemento. En la práctica, el descuento suele elegirse como una función logarítmica de un índice de clasificación:
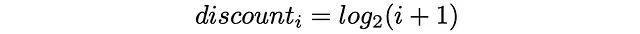
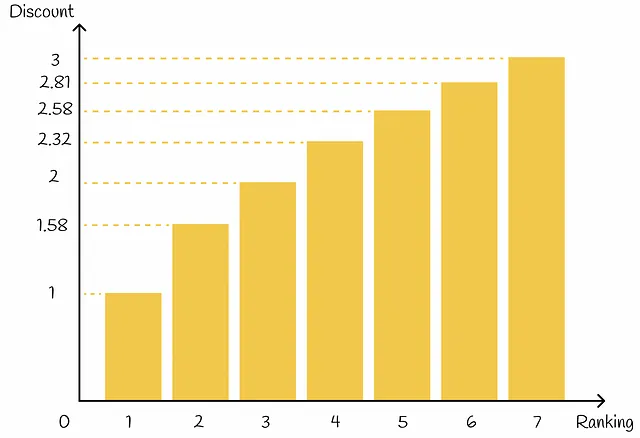
Finalmente, DCG@k se define como la suma de una ganancia sobre un descuento para todos los primeros k elementos recuperados:
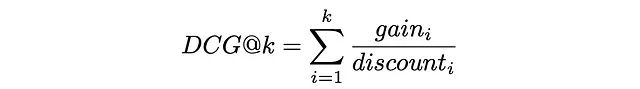
Reemplazando gainᵢ y discountᵢ con las fórmulas anteriores, la expresión toma la siguiente forma:
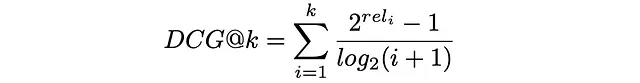
Para que la métrica DCG sea más interpretable, generalmente se normaliza por el valor máximo posible de DCGₘₐₓ en el caso de una clasificación perfecta cuando todos los elementos están correctamente ordenados por su relevancia. La métrica resultante se llama nDCG y toma valores entre 0 y 1.
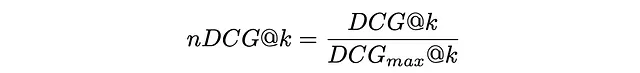
En la siguiente figura se muestra un ejemplo de cálculo de DCG y nDCG para 5 documentos.
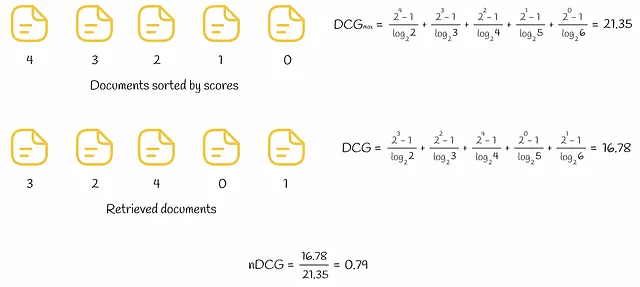
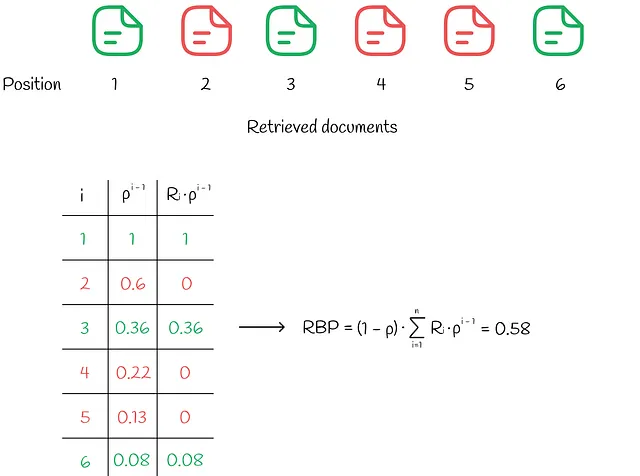
RBP (Precision Sesgada por Rango)
En el flujo de trabajo de RBP, el usuario no tiene la intención de examinar cada posible elemento. En su lugar, progresa secuencialmente de un documento a otro con una probabilidad p y con una probabilidad inversa de 1 — p termina el procedimiento de búsqueda en el documento actual. Cada decisión de terminación se toma de forma independiente y no depende de la profundidad de la búsqueda. Según la investigación realizada, este comportamiento del usuario se ha observado en muchos experimentos. Según la información de “Precision Sesgada por Rango para la Medición de la Efectividad de la Recuperación”, el flujo de trabajo se puede ilustrar en el siguiente diagrama.
El parámetro p se llama persistence.
En este paradigma, el usuario siempre mira el primer documento, luego mira el segundo documento con una probabilidad p, mira el tercer documento con una probabilidad p² y así sucesivamente. En última instancia, la probabilidad de mirar el documento i se vuelve igual a:
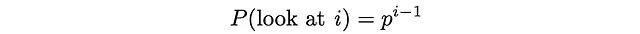
El usuario examina el documento i solo cuando el documento i ya ha sido mirado y el procedimiento de búsqueda se termina inmediatamente con una probabilidad de 1 — p.
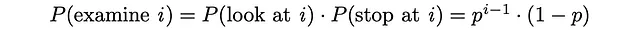
Después de eso, es posible estimar el número esperado de documentos examinados. Dado que 0 ≤ p ≤ 1, la serie a continuación converge y la expresión se puede transformar en el siguiente formato:

De manera similar, dada la relevancia Rᵢ de cada documento, encontramos la relevancia esperada del documento. Valores más altos de relevancia esperada indican que el usuario estará más satisfecho con el documento que decide examinar.
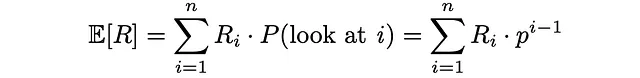
Finalmente, RPB se calcula como la relación entre la relevancia esperada del documento (utilidad) y el número esperado de documentos revisados:
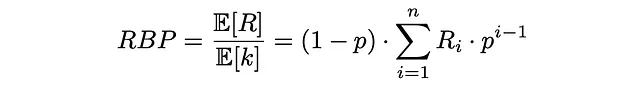
La formulación de RPB asegura que toma valores entre 0 y 1. Normalmente, las puntuaciones de relevancia son de tipo binario (1 si un documento es relevante, 0 en caso contrario) pero también pueden tomar valores reales entre 0 y 1.
El valor apropiado de p debe elegirse en función de cuán persistentes sean los usuarios en el sistema. Los valores pequeños de p (menores a 0.5) enfatizan más los documentos de mayor rango en la clasificación. Con valores más grandes de p, el peso en las primeras posiciones se reduce y se distribuye en posiciones más bajas. A veces puede ser difícil encontrar un buen valor de persistencia p, por lo que es mejor realizar varios experimentos y elegir p que funcione mejor.
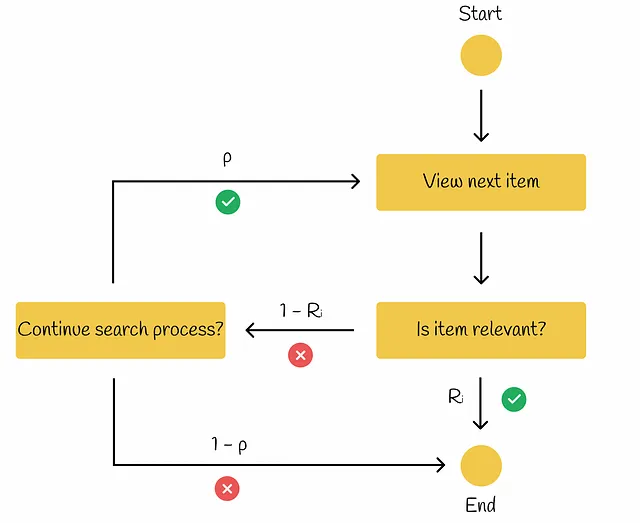
ERR (Expected Reciprocal Rank)
Como su nombre sugiere, esta métrica mide el rango recíproco promedio en muchas consultas.
Este modelo es similar a RPB pero con una pequeña diferencia: si el elemento actual es relevante (Rᵢ) para el usuario, entonces el procedimiento de búsqueda finaliza. De lo contrario, si el elemento no es relevante (1 — Rᵢ), entonces, con probabilidad p, el usuario decide si desea continuar con el proceso de búsqueda. Si es así, la búsqueda continúa con el siguiente elemento. De lo contrario, el usuario finaliza el procedimiento de búsqueda.
De acuerdo con la presentación sobre evaluación sin conexión de Ilya Markov, encontraremos la fórmula para el cálculo de ERR.
En primer lugar, calculemos la probabilidad de que el usuario mire el documento i. Básicamente, esto significa que todos los i — 1 documentos anteriores no fueron relevantes y en cada iteración, el usuario procedió con probabilidad p al siguiente elemento:
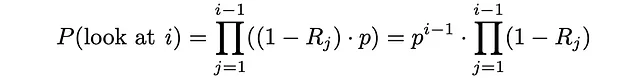
Si un usuario se detiene en el documento i, significa que este documento ya ha sido visto y con probabilidad Rᵢ, el usuario ha decidido terminar el procedimiento de búsqueda. La probabilidad correspondiente a este evento es, de hecho, el rango recíproco igual a 1 / i.
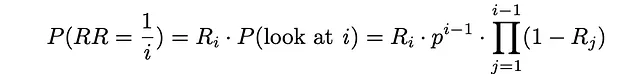
A partir de ahora, simplemente utilizando la fórmula para el valor esperado, es posible estimar el rango recíproco esperado:
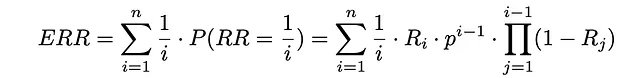
El parámetro p generalmente se elige cerca de 1.
Al igual que en el caso de RBP, los valores de Rᵢ pueden ser binarios o reales en el rango de 0 a 1. Un ejemplo de cálculo de ERR se muestra en la siguiente figura para un conjunto de 6 documentos.
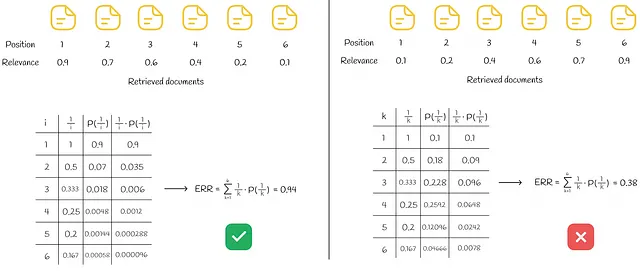
En la parte izquierda, todos los documentos recuperados se ordenan en orden descendente de su relevancia, lo que da como resultado el ERR posible mejor. Contrariamente a la situación en la parte derecha, los documentos se presentan en orden ascendente de su relevancia, lo que lleva al ERR posible peor.
La fórmula ERR asume que todas las puntuaciones de relevancia están en el rango de 0 a 1. En caso de que las puntuaciones de relevancia iniciales se den fuera de ese rango, es necesario normalizarlas. Una de las formas más populares de hacerlo es normalizarlas exponencialmente:
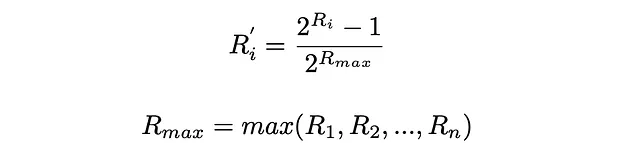
Conclusión
Hemos discutido todas las métricas principales utilizadas para la evaluación de calidad en la recuperación de información. Las métricas orientadas al usuario se utilizan con más frecuencia porque reflejan el comportamiento real del usuario. Además, las métricas nDCG, BPR y ERR tienen una ventaja sobre otras métricas que hemos visto hasta ahora: funcionan con múltiples niveles de relevancia, lo que las hace más versátiles en comparación con métricas como AP, MAP o MRR que están diseñadas solo para niveles binarios de relevancia.
Desafortunadamente, todas las métricas descritas son discontinuas o planas, lo que hace que el gradiente en puntos problemáticos sea igual a 0 o incluso no esté definido. Como consecuencia, es difícil para la mayoría de los algoritmos de clasificación optimizar estas métricas directamente. Sin embargo, se ha elaborado una gran cantidad de investigaciones en esta área y han aparecido muchas heurísticas avanzadas bajo la cubierta de los algoritmos de clasificación más populares para resolver este problema.
Recursos
- Distancia de Kendall Tau | Wikipedia
- Precisión sesgada por rango para medir la efectividad de la recuperación
- Ganancia acumulada descontada | Wikipedia
- Incertidumbre en la precisión sesgada por rango
- Recuperación de información, Evaluación offline | Ilya Markov
Todas las imágenes, a menos que se indique lo contrario, son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 5 Programas de Certificación en IA en línea – Explora e Inscríbete
- Optimizando Conexiones Optimización Matemática dentro de Grafos
- Utilizando cámaras en los autobuses de transporte público para monitorear el tráfico
- OpenAI discontinúa su detector de escritura de IA debido a una baja tasa de precisión
- Cómo la IA está transformando el panorama de la contratación a través de la coincidencia de candidatos
- LLMs en IA Conversacional Construyendo Chatbots y Asistentes más Inteligentes
- RepVGG Una explicación detallada para la reparametrización estructural





