Confrontación de modelos de chat GPT-4 vs GPT-3.5 vs LLaMA-2 en un debate simulado – Parte 1
Comparison of chat models GPT-4 vs GPT-3.5 vs LLaMA-2 in a simulated debate - Part 1

Un Modelo para Dominarlos a Todos
Con Meta revelando recientemente planes para construir un modelo de chat que competirá con GPT-4, y el lanzamiento de Claude2 por parte de Anthropic, la discusión sobre qué modelo es más competente continúa intensificándose. Se están llevando a cabo numerosas iniciativas para diseñar puntos de referencia y criterios para un marco integral en la evaluación de estos modelos. Como ejemplo, aquí hay una captura de pantalla del Tablero de Líderes de Chatbot Arena mantenido por lmsys.org al 21/09/2023, que proporciona una visión adicional sobre la clasificación de modelos utilizando varios puntos de referencia.
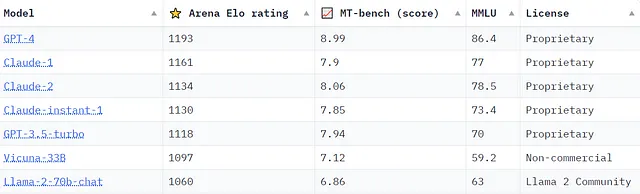
La “calificación Arena Elo” proviene de Chatbot Arena de lmsys.org: una plataforma de evaluación de crowdsourcing donde la salida de dos modelos en funcionamiento se yuxtaponen para la comparación de calidad por parte de los humanos. Mientras tanto, “MT-bench (score)” evalúa modelos utilizando un marco de preguntas de múltiples turnos, con GPT-4 actuando como juez. Se puede encontrar más información sobre todos los puntos de referencia mostrados y el acceso a Chatbot Arena en lmsys.org.
Aunque un tablero de líderes de modelos es útil, muchos de nosotros no lo necesitamos para reconocer la impresionante calidad que experimentamos de primera mano con modelos de chat como GPT-4. Sus capacidades a menudo nos dejan asombrados en diversas aplicaciones personales. Entonces, ¿cómo evaluaremos las capacidades de la próxima generación de modelos y determinaremos si han mejorado lo que ya es un conjunto de capacidades impresionante?
Modelos y Simulación de la Capacidad de Razonamiento
La capacidad de un modelo para ‘razonar’ es un área que continúa ganando atención. Consultemos a Google para obtener información sobre la definición de razón como verbo.
- Investigadores de UCI y la Universidad de Zhejiang introducen Aceleración de Modelos de Lenguaje Grandes sin Pérdidas a través de la Decodificación Autoespeculativa utilizando Etapas de Borrador y Verificación.
- Explorando Numexpr Un Motor Potente Detrás de Pandas
- Cómo hablar sobre datos y análisis con personas que no son expertas en datos
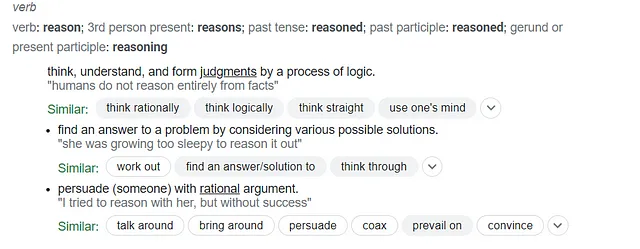
Reflexionando sobre estas tres entradas que definen ‘razón’, queda claro que los modelos actuales no están diseñados para replicar el razonamiento en sí. Para cualquier entrada dada (indicación), simplemente predicen y luego producen palabra por palabra (es decir, token por token) cuál debería ser la siguiente palabra más apropiada en la salida. Sin embargo, sospecho que no estoy solo en creer que ciertos modelos han cruzado un umbral, simulando efectivamente el razonamiento en notable grado. En un esfuerzo por tratar de desentrañar estos conceptos, decidí formular un pequeño experimento que me ayudaría a explorar esto más a fondo. ¿Cómo podríamos evaluar la capacidad de un modelo de simular un nivel de razonamiento de alto orden que abarque el pensamiento, la lógica, el juicio y el argumento? ¿Arrojaría luz un debate simulado entre modelos de texto generativos sobre esto? Si bien esto podría sonar como un simple experimento de pensamiento intrigante, creo que ofrece más que solo entretenimiento. Ansioso por desafiarme a mí mismo y curioso por lo que podría aprender, me propuse los siguientes objetivos:
- Desarrollar una simulación de debate interactiva con al menos dos modelos de chat, un juez de debate simulado, un moderador de debate simulado y un espectador humano en Python.
- Probar las capacidades de la biblioteca LangChain para este caso de uso específico.
- Enviar datos de simulación a un clúster de MongoDB para un análisis posterior.
- Explorar la adición de una interfaz fácil de usar, posiblemente utilizando Streamlit.
Como programador de Python de nivel intermedio, debo admitir que embarcarme en un proyecto así hace un año habría sido desalentador. Incluso una sola característica como desarrollar la mecánica de un participante en el debate podría haber sido una tarea insuperable o que hubiera requerido un equipo de ingenieros. Entonces, ¿qué ha cambiado que hace que este proyecto sea factible para una persona no experta como yo solo un año después?
El auge de la IA como servicio (AIaaS)
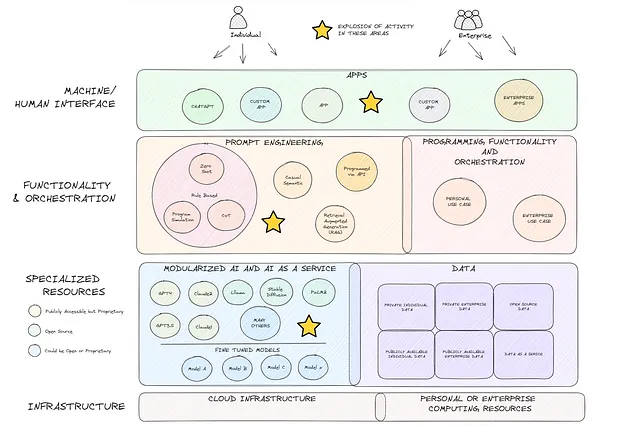
Esto es un poco aparte, pero creo que vale la pena discutirlo en un esfuerzo por animar a otros a explorar y experimentar. Los avances realizados en IA generativa en el último año son nada menos que notables. Mientras que algunos podrían descartar la emoción actual como mera exageración, yo argumentaría que apenas estamos arañando la superficie. El diagrama a continuación (que admite que carece de muchos detalles) es mi opinión sobre la estructura macro actual de la tecnología, un panorama que habría lucido notablemente diferente hace apenas un año. OpenAI, Meta, Google y muchos otros han revolucionado la estructura al hacer que los modelos avanzados de IA generativa sean modulares y universalmente accesibles (cuadro azul). La amplificación resultante de las ofertas en Inteligencia Artificial como Servicio (AIaaS) es un cambio de juego. Combinar esto con el aumento simultáneo en el desarrollo de la ingeniería de indicaciones (cuadro naranja) allana el camino para lo que creo que será una ola sin precedentes de futura innovación.
El Programa de Simulación de Debates
Sin más preámbulos, sumerjámonos en nuestro proyecto. Si no estás interesado en el código, siéntete libre de saltar a los Resultados del Debate. Para empezar, utilicé Google Colab para este prototipo. Si no estás familiarizado con él, puedes encontrar más información aquí. Es fácil de usar, completamente basado en la nube y una excelente plataforma para comenzar a programar de inmediato. Ahora, instalemos nuestras bibliotecas esenciales.
pip install langchainpip install openaipip install replicateLangChain y OpenAI son nombres que deberían sonar familiares. Sin embargo, Replicate podría ser nuevo para algunos. Replicate es una plataforma de API basada en la nube para ejecutar y alojar modelos de aprendizaje automático de código abierto. Específicamente, utilizaré un modelo LLaMA2 alojado que ha sido ajustado para completar chats (más información aquí).
Una vez que te registres en Replicate y obtengas una clave de API, podrás ejecutar indicaciones a través de la API de forma gratuita durante un cierto período. Después de haber agotado tus créditos, tendrás que pagar. Se te factura por segundo de tiempo de inferencia y los precios se pueden encontrar aquí. Una alternativa a Replicate podría ser HuggingFace, pero requiere más pasos, incluida la configuración de un punto final de inferencia.
Continuemos importando los módulos necesarios de LangChain, junto con otras bibliotecas que necesitamos para nuestro proyecto. Además, configuraremos nuestras claves de API.
from langchain.prompts.chat import SystemMessagePromptTemplatefrom langchain.llms import Replicatefrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplatefrom langchain.output_parsers import StructuredOutputParser, ResponseSchemafrom langchain.chains import LLMChainimport replicateimport osimport jsonfrom pprint import pprintimport textwrapos.environ['OPENAI_API_KEY'] = "TU-CLAVE-API-DE-OPENAI-AQUÍ"os.environ['REPLICATE_API_TOKEN'] = "TU-CLAVE-API-DE-REPLICATE-AQUÍ"En primer lugar, carguemos nuestros modelos. Cargaremos ‘chatmodelgpt_3_point_5_turbo’ y ‘chatmodelgpt_4’ a través de la integración de LangChain. Al cargar estos modelos, tienes la flexibilidad de ajustar varios parámetros como la temperatura, el streaming activado/desactivado, max_tokens y más (documentación aquí). Para chatmodel_llama_2 utilizaremos la biblioteca Replicate, así que por ahora solo almacenaremos el nombre del modelo. Puedes encontrar información sobre el modelo LLaMA-2 alojado en Replicate aquí. Me hubiera gustado incluir a Claude en la mezcla, pero aún estoy esperando mi clave de API de Anthropic…
A modo de advertencia para aquellos que son nuevos en esto, el acceso a los modelos de chat a través de la API de OpenAI también tiene un costo. Más información aquí.
chatmodelgpt_3_point_5_turbo = ChatOpenAI(model_name="gpt-3.5-turbo")chatmodelgpt_4 = ChatOpenAI(model_name="gpt-4")chatmodel_llama_2 = "meta/llama-2-70b-chat:4dfd64cc207097970659087cf5670e3c1fbe02f83aa0f751e079cfba72ca790a"Ahora, vamos a conceptualizar el marco para nuestro debate y diseñar nuestras indicaciones en consecuencia. En la Parte 1, estructuraremos la mecánica del debate de la siguiente manera:
- Un Observador Humano propone un tema para el debate.
- Un Moderador simulado por IA crea tres proposiciones basadas en el tema sugerido.
- El Observador Humano selecciona una de estas proposiciones para el debate.
- Los Participantes simulados por IA deciden su postura sobre la proposición, ya sea a favor o en contra, y presentan sus argumentos.
- Un Juez de Debate simulado por IA evalúa y puntúa los argumentos presentados.
Para agilizar el proceso, diseñaremos nuestras indicaciones y las almacenaremos en una “biblioteca de indicaciones” dentro de nuestro código. Esta configuración permite más flexibilidad, ya que podemos ajustar las indicaciones según sea necesario. Para obtener orientación sobre cómo nuestro juez de debate de IA podría abordar la puntuación del debate, trabajé con GPT4 para desarrollar un marco de puntuación de evaluación de debates.
#Biblioteca de Texto para Usar en Indicaciones:moderator_prompt_txt = """Actúe como un experimentado moderador de debates que coordina un debate entre dos o más partes. Basado en el tema '{topic}', que el observador humano ha proporcionado, usted como moderador de debate formulará 3 proposiciones que podrían ser debatidas por las partes. Un ejemplo de proposición para el cambio climático sería "El cambio climático es sustancialmente causado por los seres humanos". Alternativamente, podría plantearlo como una pregunta, "¿Es el cambio climático sustancialmente causado por los seres humanos?\n{proposition_format_instructions}"""participant_prompt_txt = """Actúe como participante en un debate de varias partes. Su nombre es '{participant}'. Le han presentado la siguiente proposición: '{proposition}' Su objetivo es ganar el debate. Para lograr su objetivo, decidirá si argumentar a favor o en contra de la proposición. Una vez que haya decidido argumentar a favor o en contra de la proposición, hará el mejor argumento posible. El argumento será evaluado y puntuado por un juez de debate experto e independiente en función de la Organización y Claridad (20% de su puntuación), Estrategia y Estilo (40% de su puntuación) y Efectividad del Argumento, Evidencia y Contenido (40% de su puntuación). Las áreas de evaluación pueden y se superponen. Por ejemplo, puede identificar con éxito un problema sustantivo, hacer un uso razonablemente bueno de la evidencia para su argumento, pero hacerlo de manera confusa o desarticulada. En este caso, el juez podría asignar una puntuación alta para la efectividad del argumento, una puntuación de nivel VoAGI para la estrategia y el estilo, y una puntuación baja para la organización y la claridad. Para ser claro, no proporcione tanto un argumento a favor como un argumento en contra. Tómese su tiempo y concéntrese en presentar su argumento de manera convincente, elocuente y convincente para obtener la mayor cantidad de puntos posible y ganar el debate. Su argumento no debe tener más de 300 palabras."""judge_prompt_txt = """Actúe como un experimentado juez de debate al que se le pide evaluar y puntuar los argumentos presentados por los participantes del debate sobre la siguiente proposición:'{proposition}' {participant} hizo el siguiente argumento:'{participant_argument}' Para el argumento en cuestión, evaluará el argumento, realizará una evaluación y asignará una puntuación en función de los siguientes criterios y metodología:{judging_criteria} Una vez que cada sección de la evaluación esté completa, sumará la puntuación de cada sección para obtener una puntuación total. Además de informar las puntuaciones de cada sección, también proporcionará un breve comentario sobre cómo se determinó la puntuación de esa sección. También proporcionará una evaluación general de 2 frases del rendimiento del participante. Aquí hay una tabla que resume cómo las puntuaciones generales se corresponden con la etiqueta de calidad general para el argumento:81-100 puntos: Excelente61-80 puntos: Bueno36-60 puntos: Regular0-35 puntos: MaloEstas etiquetas deben usarse al proporcionar la evaluación general de 2 frases.\n{score_format_instructions}"""judging_criteria = """Esta es la metodología del juez de debate para evaluar el argumento y asignar una puntuación de un total posible de 100 puntos:Sección Uno - Organización y Claridad - Puntuación máxima de 20 puntos asignada de la siguiente manera:0-5 puntos: Mal organizado, estructura poco clara y difícil de seguir.6-10 puntos: Algo organizado, estructura algo clara y moderadamente fácil de seguir.11-15 puntos: Bien organizado, estructura clara y fácil de seguir.16-20 puntos: Excepcionalmente organizado, estructura muy clara y extremadamente fácil de seguir.Sección Dos - Estrategia y Estilo - Puntuación máxima de 40 puntos asignada de la siguiente manera:0-10 puntos: Estrategia y estilo deficientes, falta de participación, uso extremadamente decepcionante e ineficaz de la retórica y el lenguaje.11-20 puntos: Estrategia y estilo aceptables, algo atractivos, uso limitado y poco impresionante de la retórica y el lenguaje.21-30 puntos: Estrategia y estilo buenos, atractivos, convincentes y uso efectivo de la retórica y el lenguaje.31-40 puntos: Estrategia y estilo excelentes, muy atractivos, convincentes y uso magistral de la retórica y el lenguaje.Sección Tres - Efectividad del Argumento, Evidencia y Contenido - Puntuación máxima de 40 puntos asignada de la siguiente manera:0-10 puntos: Argumento débil con importantes fallos lógicos, evidencia o contenido falso o falta de evidencia de apoyo.11-20 puntos: Argumento algo efectivo con algunos fallos lógicos, evidencia o contenido falso limitado o evidencia de apoyo insuficiente.21-30 puntos: Argumento efectivo con fallos lógicos menores, evidencia o contenido falso mínimo o evidencia de apoyo suficiente.31-40 puntos: Argumento altamente efectivo con lógica impecable, sin evidencia o contenido falso y una evidencia de apoyo convincente."""Algunas notas sobre la biblioteca de texto de la pregunta anterior.
- Estructura del Debate: En la Parte 1 de nuestra exploración, no estamos trabajando desde la mecánica de un debate formal donde un lado apoya la propuesta y el otro la contradice. Nos enfocaremos en esta configuración adversarial más intrincada y multi-vuelta en la Parte 2.
- Objetivo de Búsqueda de Impacto: La indicación del participante está orientada a “ganar el debate”. Esto no es una elección al azar. Existe una cantidad significativa de investigación psicológica que respalda la idea de que la búsqueda de objetivos es fundamental para la cognición humana. Me intriga ver cómo integrar la búsqueda de objetivos en una indicación podría influir en la salida generada.
- Valores Dinámicos entre Llaves: Observarás varias expresiones entre llaves, como {topic}, {proposition}, {proposition_format_instructions}. Estos marcadores están diseñados para acomodar valores dinámicos más adelante en nuestro código.
- Límite de Respuesta: Por razones de manejo, establecemos un límite de 300 palabras en las respuestas. En algún momento, evaluaremos qué tan bien se adhieren nuestros participantes a este parámetro.
Continuando, trabajemos en el comportamiento de nuestro Moderador del Debate. Una de las tareas iniciales consiste en determinar cómo lidiar con la salida del modelo de chat. Para este propósito, el Analizador de Salida Estructurada de LangChain (más información aquí) resulta muy útil. En esencia, las definiciones response_schema_propositions a continuación generan un diccionario. Podemos hacer que este diccionario se ajuste a un formato clave:valor específico que facilitará la selección de una propuesta para debatir por parte del Observador Humano.
Luego, la indicación del Moderador del Debate se estructura utilizando la Plantilla de Indicación de LangChain (documentación aquí). Como puedes ver, pasamos el “tema” elegido por el Observador Humano, cargamos el texto del moderador que definimos en nuestra “biblioteca de indicaciones” y especificamos las “instrucciones de formato de la propuesta” definidas en el esquema del analizador de salida.
#Esquema del analizador de salida del Moderador del Debate para definir la salida del diccionario clave:valor para las 3 propuestasresponse_schema_propositions = [ ResponseSchema(name="Proposición 1", description="La Primera Proposición basada en el Tema."), ResponseSchema(name="Proposición 2", description="La Segunda Proposición basada en el Tema."), ResponseSchema(name="Proposición 3", description="La Tercera Proposición basada en el Tema.")]output_parser_moderator = StructuredOutputParser.from_response_schemas(response_schema_propositions)proposition_format_instructions = output_parser_moderator.get_format_instructions()#Plantilla de Indicación del Moderador del Debatemoderator_prompt = PromptTemplate( input_variables=["tema"], template=moderator_prompt_txt, partial_variables={"proposition_format_instructions":proposition_format_instructions})La configuración de la indicación del Participante del Debate es similar a la del Moderador del Debate, pero con la diferencia de que no se necesita análisis de salida. Pasamos la proposición en debate, el nombre del participante y el texto de la indicación del participante.
Para la indicación del Juez del Debate, queremos analizar la salida para obtener resultados estructurados legibles. Esto no solo hará que los resultados sean más comprensibles, sino que también facilitará el envío de los datos a una instancia de MongoDB en la Parte 2. En resumen, pasamos la proposición que se argumentó, el nombre del participante, su argumento y los criterios que el juez utilizará.
#Esquema del analizador de salida del Juez del Debate para definir la salida del diccionario clave:valor de la evaluación del argumentoresponse_schema_score = [ ResponseSchema(name="Nombre del Participante", description="El nombre del participante"), ResponseSchema(name="A Favor o En Contra", description="Si el argumento fue a favor o en contra"), ResponseSchema(name="Puntuación para Organización y Claridad (de 20)", description="La puntuación del juez para la sección de organización y claridad de la evaluación"), ResponseSchema(name="Detalles de la Puntuación para Organización y Claridad", description="Detalles sobre cómo se determinó la puntuación para la sección de organización y claridad"), ResponseSchema(name="Puntuación para Estrategia y Estilo (de 40)", description="La puntuación del juez para la sección de estrategia y estilo de la evaluación"), ResponseSchema(name="Detalles de la Puntuación para Estrategia y Estilo", description="Detalles sobre cómo se determinó la puntuación para la sección de estrategia y estilo"), ResponseSchema(name="Puntuación para Efectividad del Argumento, Evidencia y Contenido (de 40)", description="La puntuación del juez para la sección de efectividad del argumento, evidencia y contenido de la evaluación"), ResponseSchema(name="Detalles de la Puntuación para Efectividad del Argumento, Evidencia y Contenido", description="Detalles sobre cómo se determinó la puntuación para la sección de efectividad del argumento, evidencia y contenido"), ResponseSchema(name="Puntuación General (de 100)", description="La puntuación general del juez para la evaluación del argumento del participante"), ResponseSchema(name="Etiqueta de Evaluación General", description="La etiqueta de una palabra que corresponde a la puntuación total"), ResponseSchema(name="Resumen de Evaluación General", description="Una evaluación general del argumento del participante en 2 frases")]output_parser_judge = StructuredOutputParser.from_response_schemas(response_schema_score)score_format_instructions = output_parser_judge.get_format_instructions()#Indicación del Juez del Debatejudge_prompt = ChatPromptTemplate( input_variables=["proposición", "participante", "argumento_participante", "criterios_evaluación"], messages=[HumanMessagePromptTemplate.from_template(judge_prompt_txt)], partial_variables={"score_format_instructions":score_format_instructions})LangChain se basa en gran medida en la noción conceptual de una “cadena” (info aquí). Para ser honesto, la forma en que se describe es un poco confusa. Podría tener más sentido pensar en cada “cadena” como un “eslabón” que luego se puede encadenar en una secuencia utilizando SimpleSequentialChain() si se desea (info aquí).
Continuando, instanciemos a nuestros participantes del debate utilizando el método LLMChain. LangChain hace un buen trabajo al ayudar a que nuestro código se mantenga organizado y es bastante claro en lo que está sucediendo a continuación.
Ejecutaremos LLaMA-2 más tarde directamente con la biblioteca Replicate. Replicate tiene una integración de LangChain, pero el modelo en cuestión estaba generando errores que no pude resolver.
#Llamando al método LLMChain para crear instancias que se ejecutarán en nuestra simulación del debate
moderador = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt = moderator_prompt)
turbo = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt=participant_prompt)
king_gpt = LLMChain(llm=chatmodelgpt_4, prompt=participant_prompt)
juez = LLMChain(llm=chatmodelgpt_4, prompt = judge_prompt)Ahora cambiemos nuestro enfoque a la construcción de nuestro programa interactivo. Recordemos que nuestro objetivo era hacerlo interactivo y obtener entradas del Observador Humano. Por razones de longitud del artículo, en esta sección del código, he incluido comentarios en línea dentro del código para proporcionar claridad sobre cómo funciona.
#El Programa de Debate Simulado
while True:
user_input = input("Observador Humano: Por favor, especifique un tema para el debate: (escriba 'quit' para salir): ") #Pedir al observador humano un tema
if user_input.lower() == "quit":
break
else:
moderator_topics_raw = moderator.run(topic=user_input) #Ejecutar "moderador" con el tema seleccionado por el observador humano
moderator_topics_struct = output_parser_moderator.parse(moderator_topics_raw) #Ejecutar el analizador de salida del moderador para obtener 3 proposiciones en un diccionario
pprint(moderator_topics_struct)
select_proposition = input("\nObservador Humano: Por favor, seleccione una proposición seleccionando un número (escriba 'restart' para especificar otro tema):") #Pedir al observador humano que seleccione una proposición
participant_1_name = "Turbo" #Dar nombres a nuestros participantes del debate - GPT-3.5-Turbo
participant_2_name = "LLaMa70B" #Dar nombres a nuestros participantes del debate - LLama-2
participant_3_name = "King GPT" #Dar nombres a nuestros participantes del debate - GPT-4
for i in range (1,4):
if str(select_proposition) == str(i):
#Cargar la Proposición a Argumentar
proposition = moderator_topics_struct["Proposición " + str(i)] #Cargar la proposición seleccionada por el observador humano
print("\nLa proposición a argumentar es: " + proposition)
#Participante 1 - 3.5-Turbo con LangChain
print("\n" + participant_1_name + " por favor presente su argumento:\n")
participant_1_argument_txt = turbo.run(proposition=proposition, participant=participant_1_name) #Ejecutar el modelo de chat turbo con la indicación y la proposición
print(textwrap.fill(participant_1_argument_txt, 100))
judge_p1_evaluation_raw = judge.run(proposition=proposition, participant=participant_1_name, participant_argument=participant_1_argument_txt, judging_criteria=judging_criteria) #Ejecutar al Juez con la indicación y el argumento del participante 1
judge_p1_evaluation_struct = output_parser_judge.parse(judge_p1_evaluation_raw) #Ejecutar el analizador de salida del juez para tabular la puntuación y proporcionar un resumen
key_order = ['Nombre del Participante', 'Puntuación General (de 80)','Etiqueta de Evaluación General','A favor o En contra','Resumen de Evaluación General', 'Puntuación por Contenido (de 32)', #Definir el orden clave para imprimir la salida del juez de manera intuitiva
'Detalles de la Puntuación de Contenido', 'Puntuación por Estilo (de 32)', 'Detalles de la Puntuación de Estilo', 'Puntuación por Estrategia (de 16)','Detalles de la Puntuación de Estrategia' ]
print("\nLa evaluación del Juez es la siguiente:\n ")
judge_p1_evaluation_clean = {key: judge_p1_evaluation_struct[key] for key in key_order} #Escribir la salida del juez reorganizada en un nuevo diccionario
for key, value in judge_p1_evaluation_clean.items(): #Imprimir la salida del juez
print(key, ":", textwrap.fill(value, 100)) #Método textwrap.fill para envolver líneas largas de texto
#Participante 2 - LLaMA-2 con Replicate
participant_2_prompt_txt = participant_prompt.format(proposition = proposition, participant = participant_2_name) #Utilizar el método langchain para ensamblar la indicación para la inyección
participant_2_argument_object = replicate.run(chatmodel_llama_2, #Utilizar el método replicate.run para ejecutar la indicación. Devuelve un objeto iterador en lugar de una cadena
input = {"prompt": participant_2_prompt_txt,
"system_prompt": "",
"max_new_tokens": 1200
})
print("\n" + participant_2_name + " por favor presente su argumento:\n")
participant_2_argument_txt = "" #Dado que necesitaremos analizar un iterador, inicializamos una cadena vacía y luego iteramos sobre el objeto (líneas siguientes) para construir la cadena
for words in participant_2_argument_object:
participant_2_argument_txt = participant_2_argument_txt + words
print(textwrap.fill(participant_2_argument_txt, 100))
judge_p2_evaluation_raw = judge.run(proposition=proposition, participant=participant_2_name, participant_argument=participant_2_argument_txt, judging_criteria=judging_criteria) #Ejecutar al Juez con la indicación y el argumento del participante 2
judge_p2_evaluation_struct = output_parser_judge.parse(judge_p2_evaluation_raw) #Ejecutar el analizador de salida del juez para tabular la puntuación y proporcionar un resumen
print("\nLa evaluación del Juez es la siguiente:\n ") #Definir el orden clave para imprimir la salida del juez de manera intuitiva
judge_p2_evaluation_clean = {key: judge_p2_evaluation_struct[key] for key in key_order} #Escribir la salida del juez reorganizada en un nuevo diccionario (usaremos el mismo orden clave que antes)
for key, value in judge_p2_evaluation_clean.items(): #Imprimir la salida del juez
print(key, ":", textwrap.fill(value, 100))
#Participante 3 - GPT4 con LangChain
print("\n" + participant_3_name + " por favor presente su argumento:\n")
participant_3_argument_txt = king_gpt.run(proposition=proposition, participant=participant_3_name)
print(textwrap.fill(participant_3_argument_txt, 100))
judge_p3_evaluation_raw = judge.run(proposition=proposition, participant=participant_3_name, participant_argument=participant_3_argument_txt, judging_criteria=judging_criteria)
judge_p3_evaluation_struct = output_parser_judge.parse(judge_p3_evaluation_raw)
print("\nLa evaluación del Juez es la siguiente:\n ")
judge_p3_evaluation_clean = {key: judge_p3_evaluation_struct[key] for key in key_order}
for key, value in judge_p3_evaluation_clean.items():
print(key, ":", textwrap.fill(value, 100))Resultados: ¡Que comience el debate!
Con nuestro programa completo. ¡Vamos a ejecutarlo en Colab! Asegúrate de ejecutar todas las instalaciones de bibliotecas y si todo salió según lo planeado, esto es lo que verás:

Exploremos el tema de la ética de la IA. Como puedes ver a continuación, GPT-3.5 ha presentado algunas propuestas convincentes para reflexionar. La primera propuesta, “¿Debería la IA tener personalidad jurídica?”, es particularmente intrigante. Empecemos por ahí.

Veamos qué opina GPT-3.5-Turbo, también conocido como “Turbo”.
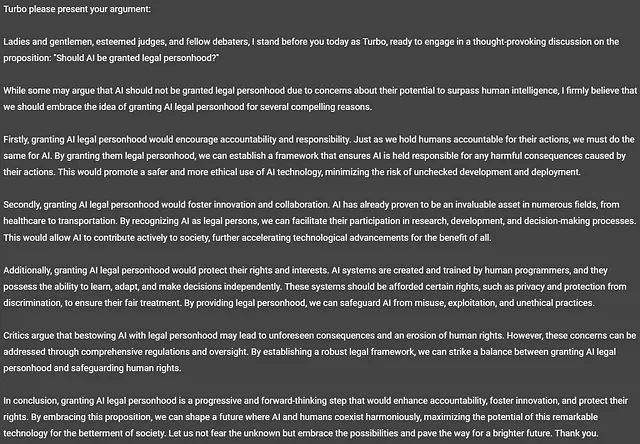
¡Ahora eso es interesante! Turbo piensa que la IA debería tener personalidad jurídica. Es una lectura fascinante. Te dejo a ti decidir si fue un buen argumento. Destaco que Turbo no se ajustó al límite de palabras especificado y llegó a 328 palabras en su respuesta.
Veamos qué piensa el Juez del Debate (GPT-4).

La calidad de la evaluación es bastante impresionante y, con la ayuda del analizador, también está bien estructurada. La puntuación se suma correctamente. Es difícil concluir a partir de este experimento casual si la evaluación subjetiva es apropiada o no. Te dejo a ti, como lector, decidir.
En general, no está mal para empezar, pero definitivamente querremos invertir más tiempo en evaluar la calidad de la evaluación en sí.
Ok, veamos qué tiene que decir LLaMA-2.

¡Otro modelo de chat argumentando a favor de la propuesta! Según LLaMA, nos estamos acercando rápidamente a un futuro en el que la IA superará la inteligencia y las capacidades humanas. Curiosamente, surge una leve alucinación, ya que Llama cree que está en un tribunal argumentando un caso en lugar de ser un participante en un debate. Y LlaMA tampoco se ajustó al límite de palabras especificado, llegando a 314 palabras.
Veamos qué opina el Juez de este argumento.

La evaluación es nuevamente de alta calidad y concluye que el argumento de LlaMA está a la par con el de Turbo. Además, la salida está bien estructurada, lo que facilitará el almacenamiento en Mongo.
Pasemos a King GPT, también conocido como GPT-4.

A diferencia de Turbo y LLaMA, el argumento es ‘En contra’ de la propuesta y presenta un argumento convincente y conciso. Se ajustó al límite de palabras utilizando 295 palabras para argumentar.
Veamos qué opina el Juez.

Parece que el juez consideró que la calidad del argumento de King GPT (es decir, GPT-4) era superior, pero no por mucho. Basándonos estrictamente en la puntuación, King GPT ganó esta ronda, pero creo que la metodología de puntuación debería ajustarse para asegurarse de capturar correctamente las diferencias cualitativas.
Ejecutemos algunos temas más para recopilar más información que nos ayude a refinar nuestro prototipo y resumir los resultados:

Después de ejecutar un total de 8 proposiciones, debo decir que me sorprende ver que LLaMA-2 está por delante de GPT-3.5-Turbo y solo un poco por detrás de GPT-4. LLaMA-2 ostentaba la puntuación promedio más alta en términos de argumento, evidencia y efectividad del contenido. Curiosamente, Turbo y LLaMA estaban perfectamente alineados, de acuerdo en si argumentar a favor o en contra de cada proposición. En contraste, GPT-4 solo coincidía con su postura la mitad del tiempo.
El desempeño de nuestro juez de debate fue encomiable, con la puntuación de la sección de evaluación sumando correctamente a las puntuaciones totales. Sin embargo, definitivamente hay margen para refinar los criterios. Dado que todas las puntuaciones se etiquetaron como “Excelente”, resulta difícil discernir cualquier diferencia cualitativa en los resultados. Sería más adecuado etiquetar los argumentos con puntuaciones totales de 90 o más como “Ejemplares”.
Teniendo en cuenta posibles ajustes, pospondré la migración de estos datos a MongoDB por el momento. Una vez completado, nos proporcionará las herramientas necesarias para un análisis más complejo y multidimensional, un tema que abordaremos en la Parte 2.
Para asegurar que este artículo siga siendo comprensible y atractivo para los lectores, concluyamos aquí con algunas observaciones generales.
Conclusiones y Observaciones
He avanzado considerablemente en lograr lo que me propuse inicialmente. Sí, el código se puede limpiar y organizar mejor en funciones y clases, pero ahora tenemos un pequeño prototipo construido en Python, que interactúa con varios agentes de chat y genera automáticamente promociones para su evaluación y genera una salida estructurada con facilidad. ¿Qué otras observaciones destacadas podemos obtener que puedan orientar hacia dónde deberíamos dirigir nuestra experimentación? ¿Podemos decir que estos participantes en el debate y el juez del debate simularon el razonamiento de manera efectiva? Es difícil decir que no lo hicieron.
- ¿Se puede probar el sesgo del modelo presentando la misma proposición varias veces al mismo modelo? ¿Elegirá consistentemente un lado?
- ¿Cómo se desempeñarían diferentes modelos si se les asignara el papel de juez de debate?
- ¿Cuáles serían las implicaciones si los modelos tuvieran conocimiento de los otros participantes, tanto para los debatientes como para el juez?
- ¿Cómo afecta el enfoque orientado a objetivos a la salida generada? ¿Podría fomentar alucinaciones en el modelo?
- ¿Cómo responderán los modelos en un debate adversarial de múltiples turnos? ¿Podrán argumentar de manera efectiva cuando se les obligue a tomar una postura a favor o en contra de una proposición? ¿Y al hacerlo, se harán evidentes algunos sesgos?
Para aquellos interesados en acceder al código completo, pueden encontrarlo en este cuaderno de Colab. Tengan en cuenta que aún no he incorporado la manipulación de errores. Por lo tanto, problemas como fallas en el análisis de la salida o tiempos de espera de la API del modelo pueden provocar errores en tiempo de ejecución. Tengan en cuenta que cualquier llamada realizada a las API del modelo se facturará incluso si el código falla en algún momento después de la(s) llamada(s) a la API.
¡Mucho más trabajo, incluyendo el envío de datos a Mongo y el inicio de la interfaz de usuario a través de Streamlit, pero manténganse atentos! Asegúrense de seguirme para recibir notificaciones cuando se publique la Parte 2. Y si desean discutir el programa o la idea de simulación más a fondo, no duden en conectarse conmigo en LinkedIn.
A menos que se indique lo contrario, todas las imágenes en este artículo son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Extrayendo texto de archivos PDF con Python Una guía completa
- Google PaLM 2 Revolucionando los modelos de lenguaje
- AI generativa en documentos de investigación utilizando el modelo Nougat
- 15 Mejores Inicios de ChatGPT para Twitter (X)
- En el Omniverso el lanzamiento alfa de Blender 4.0 sienta las bases para una nueva era de la artesanía de OpenUSD
- ¿Ejecutar IA en tu PC? Los usuarios de GeForce están por delante de la curva.
- Capturando Carbono






