Boto3 vs AWS Wrangler Simplificando Operaciones en S3 con Python
Comparison between Boto3 and AWS Wrangler for simplified S3 operations with Python.
Un análisis comparativo para el desarrollo de AWS S3

Introducción
En este tutorial, profundizaremos en el mundo del desarrollo de AWS S3 con Python explorando y comparando dos potentes bibliotecas: boto3 y awswrangler.
Si alguna vez te has preguntado:
“¿Cuál es la mejor herramienta de Python para interactuar con los buckets de AWS S3?”
“¿Cómo realizar operaciones de S3 de la manera más eficiente?”
entonces has venido al lugar correcto.
De hecho, a lo largo de este post, cubriremos una serie de operaciones comunes esenciales para trabajar con los buckets de AWS S3, entre las que se incluyen:
- listar objetos,
- verificar la existencia de objetos,
- descargar objetos,
- subir objetos,
- eliminar objetos,
- escribir objetos,
- leer objetos (forma estándar o con SQL)
Al comparar las dos bibliotecas, identificaremos sus similitudes, diferencias y casos de uso óptimos para cada operación. Al final, tendrás una comprensión clara de qué biblioteca es más adecuada para tareas específicas de S3.
Además, para aquellos que leen hasta el final, también exploraremos cómo aprovechar boto3 y awswrangler para leer datos de S3 utilizando consultas SQL amigables.
Así que sumérgete y descubre las mejores herramientas para interactuar con AWS S3 y aprende cómo realizar estas operaciones de manera eficiente con Python utilizando ambas bibliotecas.
Prerrequisitos y Datos
Las versiones de paquetes utilizadas en este tutorial son:
boto3==1.26.80awswrangler==2.19.0
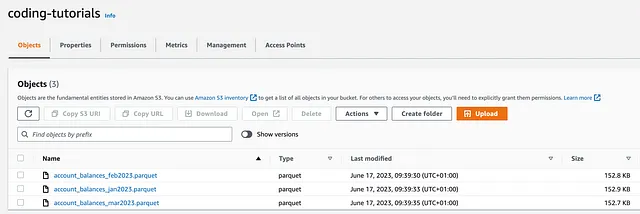
También se han cargado tres archivos iniciales, que incluyen datos account_balances generados al azar, en un bucket de S3 llamado coding-tutorials:
A pesar de que debes ser consciente de que existen varias formas de establecer una conexión con un bucket de S3, en este caso, vamos a utilizar setup_default_session() de boto3:
# CONEXIÓN CON UN BUCKET DE S3import osimport ioimport boto3import awswrangler as wrimport pandas as pdboto3.setup_default_session(aws_access_key_id = 'tu_access_key', aws_secret_access_key = 'tu_secret_access_key')bucket = 'coding-tutorials'Este método es práctico ya que, una vez que se ha establecido la sesión, puede ser compartida por boto3 y awswrangler, lo que significa que no necesitaremos pasar más secretos a lo largo del camino.
Análisis comparativo
Ahora comparemos boto3 y awswrangler mientras realizamos varias operaciones comunes y encontremos la mejor herramienta para el trabajo.
El notebook completo, incluido el código que sigue, se puede encontrar en esta carpeta de GitHub.
# 1 Listando Objetos
Listar objetos es probablemente la primera operación que debemos realizar mientras exploramos un nuevo bucket de S3 y es una forma sencilla de comprobar si se ha establecido correctamente una sesión.
Con boto3, los objetos se pueden listar utilizando:
boto3.client('s3').list_objects()boto3.resource('s3').Bucket().objects.all()
print('--BOTO3--') # BOTO3 - Método preferidoclient = boto3.client('s3')for obj in client.list_objects(Bucket=bucket)['Contents']: print('Nombre del archivo:', obj['Key'], 'Tamaño:', round(obj['Size']/ (1024*1024), 2), 'MB') print('----') # BOTO3 - Método alternativoresource = boto3.resource('s3')for obj in resource.Bucket(bucket).objects.all(): print('Nombre del archivo:', obj.key, 'Tamaño:', round(obj.size/ (1024*1024), 2), 'MB')A pesar de que ambas clases client y resource hacen un buen trabajo, la clase client debe ser preferida, ya que es más elegante y proporciona una gran cantidad de metadatos de bajo nivel [fácilmente accesibles] como un JSON anidado (entre los que se encuentra el objeto tamaño).
Por otro lado, awswrangler solo proporciona un método para listar objetos:
wr.s3.list_objects()
Siendo un método de alto nivel, esto no devuelve ningún metadato de bajo nivel sobre el objeto, por lo que para encontrar el tamaño del archivo, necesitamos llamar a:
wr.s3.size_objects
print('--AWS_WRANGLER--') # AWS WRANGLERfor obj in wr.s3.list_objects("s3://coding-tutorials/"): print('Nombre del archivo:', obj.replace('s3://coding-tutorials/', '')) print('----') for obj, size in wr.s3.size_objects("s3://coding-tutorials/").items(): print('Nombre del archivo:', obj.replace('s3://coding-tutorials/', '') , 'Tamaño:', round(size/ (1024*1024), 2), 'MB')El código anterior devuelve:
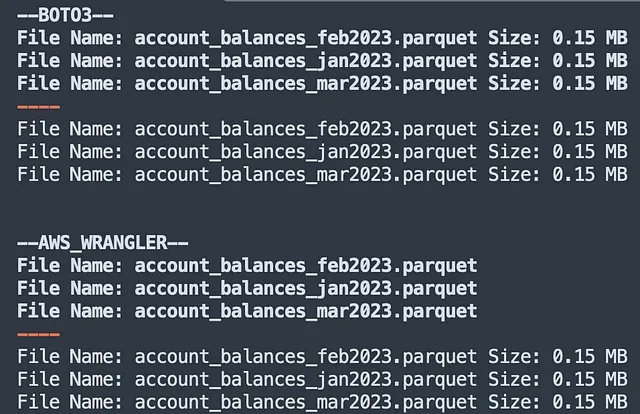
Comparación → Boto3 Wins
A pesar de que awswrangler es más fácil de usar, boto3 gana el desafío al listar objetos S3. De hecho, su implementación de bajo nivel significa que se pueden recuperar muchos más metadatos de objetos utilizando una de sus clases. Esta información es extremadamente útil al acceder a un bucket de S3 de manera programática.
# 2 Comprobación de la existencia del objeto
La capacidad de comprobar la existencia de un objeto es necesaria cuando deseamos que se desencadenen operaciones adicionales como resultado de que un objeto ya esté disponible en S3 o no.
Con boto3, estas comprobaciones se pueden realizar utilizando:
boto3.client('s3').head_object()
object_key = 'account_balances_jan2023.parquet'# BOTO3print('--BOTO3--') client = boto3.client('s3')try: client.head_object(Bucket=bucket, Key = object_key) print(f"El objeto existe en el bucket {bucket}.")except client.exceptions.NoSuchKey: print(f"El objeto no existe en el bucket {bucket}.")En cambio, awswrangler proporciona el método dedicado:
wr.s3.does_object_exist()
# AWS WRANGLERprint('--AWS_WRANGLER--') try: wr.s3.does_object_exist(f's3://{bucket}/{object_key}') print(f"El objeto existe en el bucket {bucket}.")except: print(f"El objeto no existe en el bucket {bucket}.")El código anterior devuelve:
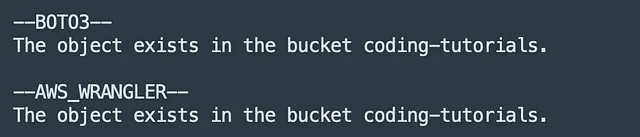
Comparación → AWSWrangler Wins
Admitámoslo: el nombre del método de boto3 [head_object()] no es tan intuitivo.
Tener un método dedicado es sin duda una ventaja de awswrangler que gana este partido.
# 3 Descarga de Objetos
La descarga de objetos en local es extremadamente sencilla con ambos boto3 y awswrangler utilizando los siguientes métodos:
boto3.client('s3').download_file()owr.s3.download()
La única diferencia es que download_file() toma bucket, object_key y local_file como variables de entrada, mientras que download() solo requiere la ruta S3 y el local_file:
object_key = 'account_balances_jan2023.parquet'
# BOTO3
client = boto3.client('s3')
client.download_file(bucket, object_key, 'tmp/account_balances_jan2023_v2.parquet')
# AWS WRANGLER
wr.s3.download(path=f's3://{bucket}/{object_key}', local_file='tmp/account_balances_jan2023_v3.parquet')
Cuando se ejecuta el código, ambas versiones del mismo objeto se descargan en local dentro de la carpeta tmp/:

Comparación → Empate
Podemos considerar que ambas librerías son equivalentes en lo que respecta a la descarga de archivos, por lo tanto, llamémoslo un empate.
# 4 Subida de Objetos
El mismo razonamiento se aplica al subir archivos desde el entorno local a S3. Los métodos que se pueden emplear son:
boto3.client('s3').upload_file()owr.s3.upload()
object_key_1 = 'account_balances_apr2023.parquet'
object_key_2 = 'account_balances_may2023.parquet'
file_path_1 = os.path.dirname(os.path.realpath(object_key_1)) + '/' + object_key_1
file_path_2 = os.path.dirname(os.path.realpath(object_key_2)) + '/' + object_key_2
# BOTO3
client = boto3.client('s3')
client.upload_file(file_path_1, bucket, object_key_1)
# AWS WRANGLER
wr.s3.upload(local_file=file_path_2, path=f's3://{bucket}/{object_key_2}')
Al ejecutar el código, se suben dos nuevos objetos account_balances (para los meses de abril y mayo de 2023) al bucket coding-tutorials:
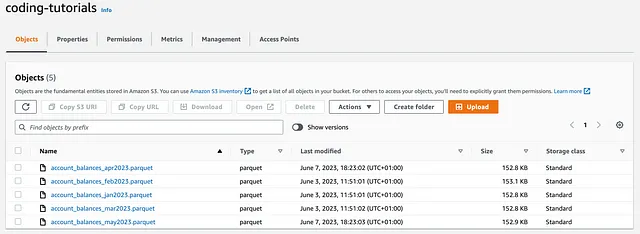
Comparación → Empate
Este es otro empate. ¡Hasta ahora hay una paridad absoluta entre las dos librerías!
# 5 Eliminación de Objetos
Supongamos ahora que deseamos eliminar los siguientes objetos:
# OBJETO ÚNICO
object_key = ‘account_balances_jan2023.parquet’
# MÚLTIPLES OBJETOS
object_keys = [‘account_balances_jan2023.parquet’,
‘account_balances_feb2023.parquet’,
‘account_balances_mar2023.parquet’]
boto3 permite eliminar objetos uno por uno o en masa utilizando los siguientes métodos:
boto3.client('s3').delete_object()boto3.client('s3').delete_objects()
Ambos métodos devuelven una response que incluye ResponseMetadata que se puede utilizar para verificar si los objetos se han eliminado correctamente o no. Por ejemplo:
- mientras se elimina un objeto único, un
HTTPStatusCode==204indica que la operación se ha completado con éxito (si se encuentran objetos en el bucket S3); - mientras se eliminan varios objetos, se devuelve una lista
Deletedcon los nombres de los elementos eliminados correctamente.
# BOTO3print('--BOTO3--')client = boto3.client('s3')# Eliminar objeto únicoresponse = client.delete_object(Bucket=bucket, Key=object_key)deletion_date = response['ResponseMetadata']['HTTPHeaders']['date']if response['ResponseMetadata']['HTTPStatusCode'] == 204: print(f'Objeto {object_key} eliminado correctamente en {deletion_date}.')else: print(f'No se pudo eliminar el objeto.')# Eliminar múltiples objetosobjects = [{'Key': key} for key in object_keys]response = client.delete_objects(Bucket=bucket, Delete={'Objects': objects})deletion_date = response['ResponseMetadata']['HTTPHeaders']['date']if len(object_keys) == len(response['Deleted']): print(f'Todos los objetos fueron eliminados correctamente en {deletion_date}.')else: print(f'No se pudieron eliminar los objetos.')# Eliminar objetos con awswranglerPor otro lado, awswrangler proporciona un método que se puede utilizar tanto para eliminaciones únicas como múltiples:
wr.s3.delete_objects()
Dado que object_keys se puede pasar recursivamente al método como una list_comprehension - en lugar de convertirse primero en un diccionario como antes - usar esta sintaxis es un verdadero placer.
# AWS WRANGLERprint('--AWS_WRANGLER--')# Eliminar objeto únicowr.s3.delete_objects(path=f's3://{bucket}/{object_key}')# Eliminar múltiples objetosintente: wr.s3.delete_objects(path=[f's3://{bucket}/{key}' for key in object_keys]) print('Todos los objetos eliminados correctamente.')except: print(f'No se pudieron eliminar los objetos.')
Ejecutando el código anterior, se eliminan los objetos en S3 y luego se devuelve:

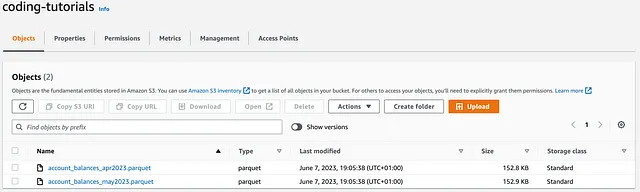
Comparación → Boto3 gana
Este es un poco complicado: awswrangler tiene una sintaxis más simple para usar al eliminar múltiples objetos, ya que simplemente podemos pasar la lista completa al método.
Sin embargo, boto3 devuelve una gran cantidad de información en la response que son registros extremadamente útiles, al eliminar objetos programáticamente.
Porque en un entorno de producción, los metadatos de bajo nivel son mejores que casi ningún metadato, boto3 gana este desafío y ahora lidera 2-1.
# 6 Escritura de objetos
Cuando se trata de escribir archivos en S3, boto3 ni siquiera proporciona un método listo para usar para realizar tales operaciones.
Por ejemplo, si quisiéramos crear un nuevo archivo parquet usando boto3, primero deberíamos persistir el objeto en el disco local (usando el método to_parquet() de pandas) y luego cargarlo en S3 usando el método upload_fileobj().
A diferencia de upload_file() (explorado en el punto 4), el método upload_fileobj() es una transferencia administrada que realizará una carga multipartida en múltiples hilos, si es necesario:
object_key_1 = 'account_balances_june2023.parquet'# EJECUTAR EL SCRIPT GENERATOR.PYdf.to_parquet(object_key_1)# BOTO3client = boto3.client('s3')# Cargar el archivo Parquet a S3with open(object_key_1, 'rb') as file: client.upload_fileobj(file, bucket, object_key_1)
Por otro lado, una de las principales ventajas de la biblioteca awswrangler (mientras trabaja con pandas) es que se puede usar para escribir objetos directamente en el bucket de S3 (sin guardarlos en el disco local), lo que es elegante y eficiente.
Además, awswrangler ofrece una gran flexibilidad que permite a los usuarios:
- Aplicar algoritmos de compresión específicos como
snappy, gzip y zstd;
anexar o sobrescribir archivos existentes mediante el parámetro mode cuando dataset = True;- Especificar una o más columnas de particiones mediante el parámetro
partitions_col.
object_key_2 = 'account_balances_july2023.parquet'# AWS WRANGLER wr.s3.to_parquet(df=df, path=f's3://{bucket}/{object_key_2}', compression = 'gzip', partition_cols = ['COMPANY_CODE'], dataset=True)
Una vez ejecutado, el código anterior escribe account_balances_june2023 como un único archivo parquet, y account_balances_july2023 como una carpeta con cuatro archivos ya particionados por COMPANY_CODE:
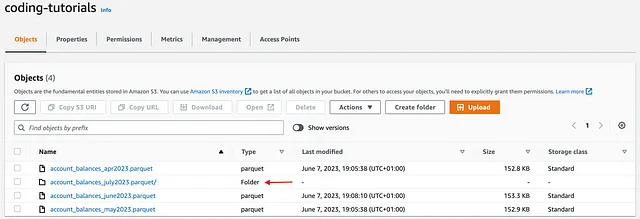
Comparación → AWSWrangler gana
Si trabajar con pandas es una opción, awswrangler ofrece un conjunto de operaciones mucho más avanzado al escribir archivos en S3, especialmente cuando se compara con boto3 que, en este caso, no es exactamente la mejor herramienta para el trabajo.
# 7.1 Lectura de objetos (Python)
Un razonamiento similar se aplica al intentar leer objetos de S3 utilizando boto3: ya que esta biblioteca no ofrece un método de lectura incorporado, la mejor opción que tenemos es realizar una llamada API (get_object()), leer el Body de la response y luego pasar el parquet_object a pandas.
Tenga en cuenta que el método pd.read_parquet() espera un objeto similar a un archivo como entrada, por lo que necesitamos pasar el contenido leído del parquet_object como un flujo binario.
De hecho, mediante el uso de io.BytesIO() creamos un objeto similar a un archivo temporal en memoria, evitando la necesidad de guardar el archivo Parquet localmente antes de leerlo. Esto a su vez mejora el rendimiento, especialmente cuando se trabaja con archivos grandes:
object_key = 'account_balances_may2023.parquet'# BOTO3client = boto3.client('s3')# Leer el archivo Parquetresponse = client.get_object(Bucket=bucket, Key=object_key)parquet_object = response['Body'].read()df = pd.read_parquet(io.BytesIO(parquet_object))df.head()
Como era de esperar, awswrangler sobresale en la lectura de objetos desde S3, devolviendo un df de pandas como salida.
Admite varios formatos de entrada como csv, json, parquet y más recientemente, tablas delta. Además, pasar el parámetro chunked permite leer objetos de una manera que no consume mucha memoria:
# AWS WRANGLERdf = wr.s3.read_parquet(path=f's3://{bucket}/{object_key}')df.head()# wr.s3.read_csv()# wr.s3.read_json()# wr.s3.read_parquet_table()# wr.s3.read_deltalake()
La ejecución del código anterior devuelve un df de pandas con los datos de mayo:
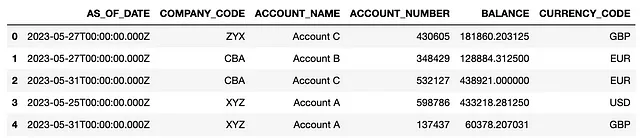
Comparación → AWSWrangler gana
Sí, hay formas de evitar la falta de métodos adecuados en boto3. Sin embargo, awswrangler es una biblioteca concebida para leer objetos de S3 de manera eficiente, por lo que también gana este desafío.
# 7.2 Leyendo objetos (SQL)
Los que lograron leer hasta este punto merecen una recompensa y esa recompensa es leer objetos de S3 usando SQL plano.
Supongamos que deseamos obtener datos del objeto account_balances_may2023.parquet utilizando la consulta a continuación (que filtra datos por AS_OF_DATE):
object_key = 'account_balances_may2023.parquet'query = """SELECT * FROM s3object s WHERE AS_OF_DATE > CAST('2023-05-13T' AS TIMESTAMP)"""
En boto3 esto se puede lograr a través del método select_object_content(). Tenga en cuenta que también debemos especificar los formatos de inputSerialization y OutputSerialization:
# BOTO3client = boto3.client('s3')resp = client.select_object_content( Bucket=bucket, Key=object_key, Expression= query, ExpressionType='SQL', InputSerialization={"Parquet": {}}, OutputSerialization={'JSON': {}},)records = []# Procesar la respuestapor evento en resp['Payload']: if 'Records' in event: records.append(event['Records']['Payload'].decode('utf-8')) # Concatenar los registros JSON en una sola cadenajson_string = ''.join(records)# Cargar los datos JSON en un DataFrame de Pandasdf = pd.read_json(json_string, lines=True)# Imprimir el DataFramedf.head()
Si trabajar con un DataFrame de pandas es una opción, awswrangler también ofrece un método muy útil select_query() que requiere un código mínimo:
# AWS WRANGLERdf = wr.s3.select_query( sql=query, path=f's3://{bucket}/{object_key}', input_serialization="Parquet", input_serialization_params={})df.head()
Para ambas bibliotecas, el DataFrame devuelto se verá así:
Conclusión
En este tutorial exploramos 7 operaciones comunes que se pueden realizar en los buckets de S3 y realizamos un análisis comparativo entre las bibliotecas boto3 y awswrangler.
Ambos enfoques nos permiten interactuar con los buckets de S3, sin embargo, la principal diferencia es que el cliente boto3 proporciona acceso de bajo nivel a los servicios de AWS, mientras que awswrangler ofrece una interfaz simplificada y más de alto nivel para varias tareas de ingeniería de datos.
En general, awswrangler es nuestro ganador con 3 puntos (verificación de existencia de objetos, escritura de objetos, lectura de objetos) frente a los 2 puntos obtenidos por boto3 (listado de objetos, eliminación de objetos). Ambas categorías de carga / descarga de objetos fueron empates y no se asignaron puntos.
A pesar del resultado anterior, la verdad es que ambas bibliotecas dan lo mejor de sí cuando se utilizan de manera intercambiable, para destacar en las tareas para las que han sido construidas.
Fuentes
- Documentación de AWS Wrangler
- Documentación del cliente Boto3 S3
Todas las imágenes, a menos que se indique lo contrario, son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
Usando RAPIDS cuDF para aprovechar la GPU en la ingeniería de características.
-
Desarrollar y probar reglas RLS en Power BI.
-
Power BI vs Tableau Similitudes y Diferencias
-
¿Cómo utilizar la Ciencia de Datos para el Marketing?
-
Conoce a TARDIS Un marco de trabajo de IA que identifica singularidades en espacios complejos y captura estructuras singulares y complejidad geométrica local en datos de imágenes.
-
Predicción de rendimiento de cultivos utilizando Aprendizaje Automático e implementación de Flask.
-
Cómo funciona GPT una explicación metafórica de Clave, Valor, Consulta en Atención, utilizando un cuento de pociones.