Una comparación de los métodos Temporal-Difference (0) y Constant-α Monte Carlo en la tarea de Random Walk
Comparing Temporal-Difference (0) and Constant-α Monte Carlo methods in the Random Walk task
![Imagen generada por Midjourney con una suscripción paga, que cumple con los términos comerciales generales [1].](https://miro.medium.com/v2/resize:fit:640/format:webp/1*5oytNad_PJHFQzWAIBrgoQ.png)
Introducción
Los métodos de Monte Carlo (MC) y Temporal-Difference (TD) son ambas técnicas fundamentales en el campo del aprendizaje por refuerzo; resuelven el problema de predicción basado en las experiencias de interactuar con el entorno en lugar del modelo del entorno. Sin embargo, el método TD es una combinación de los métodos MC y Programación Dinámica (DP), lo que lo diferencia del método MC en los aspectos de la regla de actualización, el bootstrap y el sesgo/varianza. Los métodos TD también han demostrado tener un mejor rendimiento y una convergencia más rápida en la mayoría de los casos en comparación con el método MC.
En esta publicación, compararemos TD y MC, o más específicamente, los métodos TD(0) y MC con α constante, en un entorno de cuadrícula simple y en un entorno de Caminata Aleatoria más completo [2]. Esperamos que esta publicación ayude a los lectores interesados en el Aprendizaje por Refuerzo a comprender mejor cómo cada método actualiza la función de valor del estado y cómo difiere su rendimiento en el mismo entorno de prueba.
Implementaremos los algoritmos y comparaciones en Python, y las bibliotecas utilizadas en esta publicación son las siguientes:
python==3.9.16numpy==1.24.3matplotlib==3.7.1La diferencia entre TD y MC
La introducción de TD(0) y MC con α constante
El método MC con α constante es un método MC regular con un parámetro α de tamaño de paso constante, y este parámetro constante ayuda a que la estimación de valor sea más sensible a la experiencia reciente. En la práctica, la elección del valor α depende de un equilibrio entre estabilidad y adaptabilidad. La siguiente es la ecuación del método MC para actualizar la función de valor del estado en el tiempo t:
- Comparando y explicando los modelos de difusión en los Difusores de HuggingFace
- GPT-4 8 Modelos en Uno; El Secreto ha Sido Revelado
- El informe de ganancias de NVIDIA revela dominio en la revolución de la IA
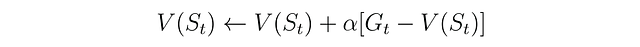
El TD(0) es un caso especial de TD(λ) que solo mira un paso hacia adelante y es la forma más simple de aprendizaje TD. Este método actualiza la función de valor del estado con el error TD, la diferencia entre el valor estimado del estado y la recompensa más el valor estimado del siguiente estado. Un parámetro α de tamaño de paso constante funciona de la misma manera que en el método MC anterior. La siguiente es la ecuación de TD(0) para actualizar la función de valor del estado en el tiempo t:
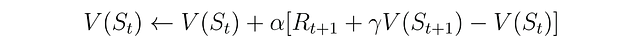
En general, la diferencia entre los métodos MC y TD ocurre en tres aspectos:
- Regla de actualización: Los métodos MC actualizan los valores solo después de que finaliza el episodio; esto puede ser problemático si el episodio es muy largo, lo que ralentiza el programa, o en la tarea continua que no tiene episodios en absoluto. En cambio, el método TD actualiza las estimaciones de valor en cada paso de tiempo; esto es aprendizaje en línea y puede ser particularmente útil en tareas continuas.
- Bootstrap: El término “bootstrap” en el aprendizaje por refuerzo se refiere a la actualización de las estimaciones de valor basadas en otras estimaciones de valor. El método TD(0) se basa en la actualización del valor del siguiente estado, por lo que es un método de bootstrap; en cambio, el MC no utiliza bootstrap ya que actualiza el valor directamente a partir de los retornos (G).
- Sesgo/Varianza: Los métodos MC son imparciales ya que estiman el valor ponderando los retornos reales observados sin hacer estimaciones durante el episodio; sin embargo, los métodos MC tienen una alta varianza, especialmente cuando el número de muestras es bajo. En cambio, los métodos TD tienen sesgos porque utilizan bootstrap, y el sesgo puede variar según la implementación real; los métodos TD tienen baja varianza porque utilizan la recompensa inmediata más la estimación del siguiente estado, lo que suaviza la fluctuación que surge de la aleatoriedad en las recompensas y acciones.
Evaluación de TD(0) y MC con α constante en una configuración de cuadrícula simple
Para hacer su diferencia más clara, podemos configurar un entorno de prueba Gridworld simple con dos trayectorias fijas, ejecutar ambos algoritmos en la configuración hasta que converjan y verificar cómo actualizan los valores de manera diferente.
Primero podemos configurar el entorno de prueba con los siguientes códigos:
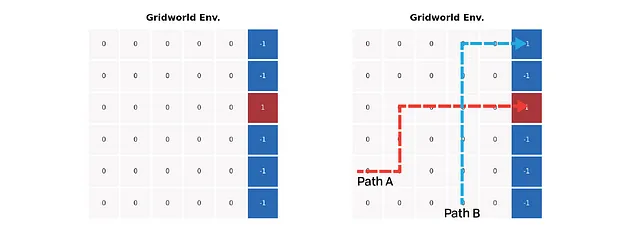
La figura de la izquierda muestra una configuración simple del entorno de Gridworld. Todas las celdas de colores representan estados terminales; el agente obtiene una recompensa +1 al entrar en la celda roja pero obtiene una recompensa -1 al entrar en las celdas azules. Todos los demás pasos en la cuadrícula devuelven una recompensa de cero. La figura de la derecha marca dos rutas predefinidas: una llega a la celda azul mientras que otra se detiene en la celda roja; la intersección de las rutas ayuda a maximizar la diferencia de valor entre los dos métodos.
Luego podemos usar las ecuaciones de la sección anterior para evaluar el entorno. No descontamos el retorno ni la estimación, y configuramos el α con un valor pequeño de 1e-3. Cuando la suma absoluta de los incrementos de valor es menor que un umbral de 1e-3, consideramos que los valores han convergido.
El resultado de la evaluación es el siguiente:
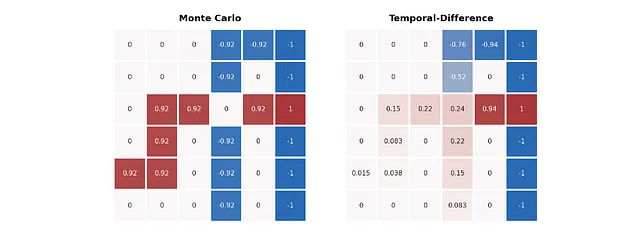
Las diferentes formas de estimar valores de los dos algoritmos se vuelven bastante evidentes en la imagen anterior. El método MC es leal a los retornos de la ruta, por lo que los valores en cada ruta representan directamente cómo termina. Sin embargo, el método TD proporciona una mejor predicción, especialmente en la ruta azul: los valores en la ruta azul antes de la intersección también indican la posibilidad de llegar a la celda roja.
Con este caso mínimo en mente, estamos listos para pasar a un ejemplo mucho más complicado y tratar de descubrir la diferencia en el rendimiento entre los dos métodos.
La tarea de Random Walk
La tarea de Random Walk es un proceso de recompensa de Markov simple propuesto por Sutton et al. para propósitos de predicción TD y MC[2], como muestran las imágenes a continuación. En esta tarea, el agente comienza desde el nodo central C. El agente da un paso hacia la derecha o hacia la izquierda con igual probabilidad en cada nodo. Hay dos estados terminales en ambos extremos de la cadena. La recompensa de entrar en el extremo izquierdo es 0 y la de entrar en el extremo derecho es +1. Todos los pasos antes de la terminación generan una recompensa de 0.

Y podemos usar el siguiente código para crear el entorno de Random Walk:
=====Prueba: verificación de la configuración del entorno=====Enlaces: Ninguno ← Nodo A → Nodo BReward: 0 ← Nodo A → 0Enlaces: Nodo A ← Nodo B → Nodo CReward: 0 ← Nodo B → 0Enlaces: Nodo B ← Nodo C → Nodo DReward: 0 ← Nodo C → 0Enlaces: Nodo C ← Nodo D → Nodo EReward: 0 ← Nodo D → 0Enlaces: Nodo D ← Nodo E → NingunoReward: 0 ← Nodo E → 1El valor verdadero para cada nodo del entorno bajo una política aleatoria es [1/6, 2/6, 3/6, 4/6, 5/6]. El valor fue calculado mediante la evaluación de la política con la ecuación de Bellman:
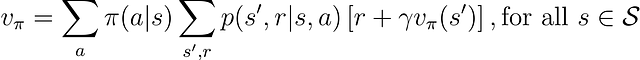
Nuestra tarea aquí es encontrar qué tan cerca están los valores estimados por ambos algoritmos al valor verdadero; podemos asumir arbitrariamente que el algoritmo produce una función de valor más cercana a la función de valor verdadera, medida por el error cuadrático medio raíz promedio (RMS) promediado, lo que indica un mejor rendimiento.
El rendimiento de TD(0) y MC con constante-a en el Random Walk
Algoritmos
Con el entorno listo, podemos comenzar a ejecutar ambos métodos en el entorno de Random Walk y comparar su rendimiento. Primero veamos ambos algoritmos:


Como se mencionó anteriormente, el método MC debe esperar hasta que el episodio termine para actualizar los valores desde el final de la trayectoria, mientras que el método TD actualiza los valores de forma incremental. Esta diferencia trae un truco al inicializar la función de valor-estado: en MC, la función de valor-estado no incluye los estados terminales, mientras que en TD(0), la función debe incluir el estado terminal con el valor de 0 porque el método TD(0) siempre mira un paso hacia adelante antes de que termine el episodio.
Implementación
La selección del parámetro α en esta implementación hace referencia a la propuesta en el libro [2]; los parámetros para el método MC son [0.01, 0.02, 0.03, 0.04], mientras que los del método TD son [0.05, 0.10, 0.15]. Me pregunté por qué el autor no eligió el mismo conjunto de parámetros en ambos algoritmos hasta que ejecuté el método MC con los parámetros para TD: los parámetros de TD son demasiado altos para el método MC y, por lo tanto, no pueden revelar el mejor rendimiento de MC. Por lo tanto, nos quedaremos con la configuración del libro en la búsqueda de parámetros. Ahora, ejecutemos ambos algoritmos para descubrir su rendimiento en la configuración de Random Walk.
Resultado
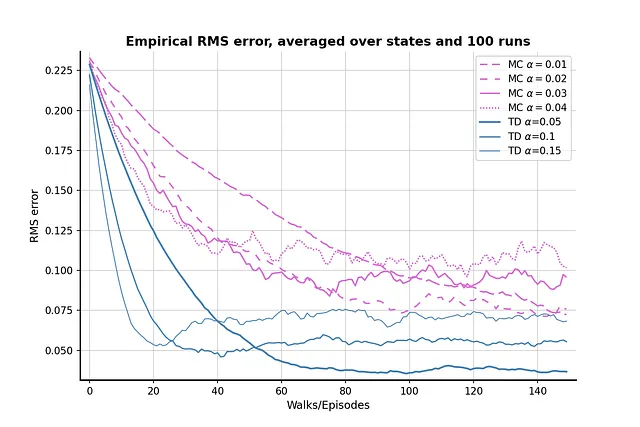
El resultado después de 100 ejecuciones de comparación es como muestra la imagen anterior. El método TD generalmente produce estimaciones de valor mejor que los métodos MC, y el TD con α = 0.05 puede acercarse mucho al valor verdadero. El gráfico también muestra que el método MC tiene una mayor varianza en comparación con los métodos TD, ya que las líneas color orquídea fluctúan más que las líneas azul acero.
Vale la pena destacar que para ambos algoritmos, cuando α es (relativamente) alto, la pérdida RMS primero disminuye y luego aumenta nuevamente. Este fenómeno se debe al efecto combinado de la inicialización de valor y el valor α. Inicializamos un valor relativamente alto de 0.5, que es mayor que el valor verdadero de los nodos A y B. Como la política aleatoria tiene un 50% de probabilidad de elegir un paso “incorrecto”, que aleja al agente del estado terminal correcto, un valor α más alto también enfatizará los pasos incorrectos y alejará el resultado del valor verdadero.
Ahora intentemos reducir el valor inicial a 0.1 y ejecutemos la comparación nuevamente, para ver si el problema se alivia:
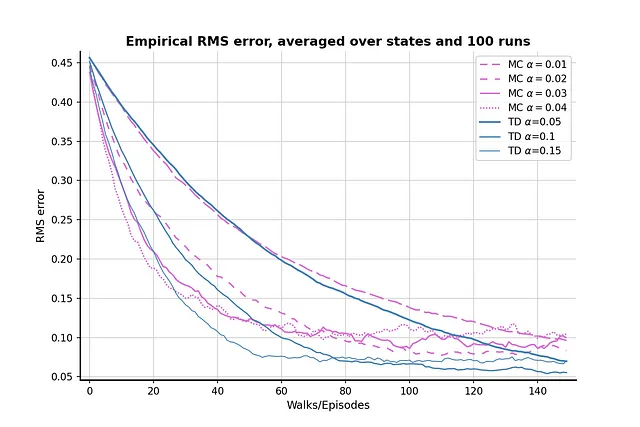
El valor inicial más bajo aparentemente ayuda a aliviar el problema; no hay efectos notables de “descender y luego subir”. Sin embargo, el efecto secundario de un valor inicial más bajo es que el aprendizaje es menos eficiente, ya que la pérdida RMS nunca baja de 0.05 después de 150 episodios. Por lo tanto, hay un compromiso entre el valor inicial, el parámetro y el rendimiento del algoritmo.
Entrenamiento en Lote
Una última pieza que quiero mencionar en esta publicación es la comparación del entrenamiento en lote en ambos algoritmos.
Consideremos que nos enfrentamos a la siguiente situación: solo hemos acumulado un número limitado de experiencias en la tarea de Random Walk, o solo podemos ejecutar un cierto número de episodios debido a la limitación de tiempo y computación. La idea de la actualización en lote [2] se propuso para lidiar con esta situación utilizando completamente las trayectorias existentes.
La idea del entrenamiento en lote es actualizar los valores en un lote de trayectorias repetidamente hasta que los valores converjan a una respuesta. Los valores solo se actualizarán una vez que todas las experiencias del lote se hayan procesado completamente. Implementemos el entrenamiento en lote para ambos algoritmos en el entorno de Random Walk para ver si el método TD sigue siendo mejor que el método MC.
Resultado
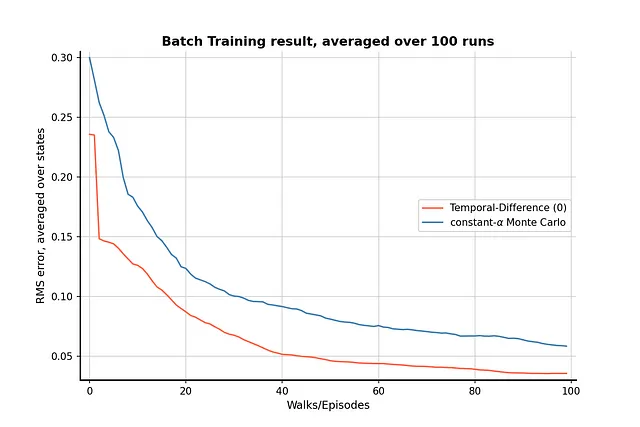
El resultado del entrenamiento en lote muestra que el método TD sigue siendo mejor que el método MC con una experiencia limitada, y la diferencia entre el rendimiento de los dos algoritmos es bastante evidente.
Conclusión
En esta publicación, discutimos la diferencia entre el método MC con constante α y los métodos TD(0) y comparamos su rendimiento en la tarea de Random Walk. El método TD supera a los métodos MC en todas las pruebas de esta publicación, por lo que considerar TD como un método para tareas de aprendizaje por refuerzo es una opción preferible. Sin embargo, esto no significa que TD siempre sea mejor que MC, ya que este último tiene una ventaja muy evidente: no tiene sesgo. Si nos enfrentamos a una tarea que no tolera sesgos, entonces MC podría ser una mejor opción; de lo contrario, TD podría manejar mejor los casos generales.
Referencia
[1] Términos de servicio de Midjourney: https://docs.midjourney.com/docs/terms-of-service
[2] Sutton, Richard S., y Andrew G. Barto. Reinforcement learning: An introduction. MIT Press, 2018.
Mi repositorio de GitHub de esta publicación: [Enlace].
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de Microsoft y la Universidad Bautista de Hong Kong presentan WizardCoder Un Code Evol-Instruct Fine-Tuned Code LLM.
- Microsoft presenta Python en Excel uniendo habilidades analíticas con familiaridad para mejorar la comprensión de los datos.
- Conoce a SeamlessM4T el nuevo modelo base de Meta AI para la traducción de voz
- Cómo el cómputo en la nube mejora los flujos de trabajo de la ciencia de datos
- Aplicaciones de Python | Aprovechando la Multiprocesamiento para Velocidad y Eficiencia
- Investigadores del MIT desarrollaron una técnica de Inteligencia Artificial (IA) que permite a un robot desarrollar planes complejos para manipular un objeto utilizando toda su mano
- Papel de los Contratos de Datos en la Canalización de Datos






