Sobrevivencia del más apto Modelos generativos compactos de IA son el futuro para una IA a gran escala rentable
Compact generative AI models are the future for profitable large-scale AI.

El caso de los modelos ágiles, dirigidos y basados en recuperación como la mejor solución para aplicaciones de IA generativa implementadas a gran escala.
Después de una década de rápido crecimiento en la complejidad y capacidad de cómputo de los modelos de inteligencia artificial (IA), el año 2023 marca un cambio de enfoque hacia la eficiencia y la amplia aplicación de la IA generativa (GenAI). Como resultado, una nueva generación de modelos con menos de 15 mil millones de parámetros, llamados IA ágil, puede igualar de cerca las capacidades de los modelos gigantes estilo ChatGPT que contienen más de 100 mil millones de parámetros, especialmente cuando se orientan a dominios específicos. Si bien GenAI ya se está implementando en diversas industrias para una amplia gama de usos empresariales, el uso de modelos compactos pero altamente inteligentes está en aumento. En un futuro cercano, creo que habrá un número reducido de modelos gigantes y un número gigante de modelos de IA más ágiles integrados en innumerables aplicaciones.
Aunque ha habido un gran avance con modelos más grandes, más grande definitivamente no es mejor cuando se trata de costos de entrenamiento y medioambientales. TrendForce estima que solo el entrenamiento de ChatGPT para GPT-4 supuestamente cuesta más de $100 millones, mientras que los costos de preentrenamiento de modelos ágiles son mucho más bajos (por ejemplo, se citan aproximadamente $200,000 para el MPT-7B de MosaicML). La mayoría de los costos de cómputo se producen durante la ejecución continua de inferencia, pero esto plantea un desafío similar para modelos más grandes que requieren un cómputo costoso. Además, los modelos gigantes alojados en entornos de terceros plantean desafíos de seguridad y privacidad. Los modelos ágiles son considerablemente más económicos de ejecutar y ofrecen una serie de beneficios adicionales, como adaptabilidad, flexibilidad de hardware, integración en aplicaciones más grandes, seguridad y privacidad, explicabilidad y más (ver Figura 1). También está cambiando la percepción de que los modelos más pequeños no funcionan tan bien como los modelos más grandes. Los modelos más pequeños y dirigidos no son menos inteligentes, pueden ofrecer un rendimiento equivalente o superior para dominios empresariales, de consumo y científicos, aumentando su valor al tiempo que reducen la inversión de tiempo y costos.
Un número creciente de estos modelos ágiles se asemejan aproximadamente al rendimiento de los modelos gigantes de nivel ChatGPT-3.5 y continúan mejorando rápidamente en rendimiento y alcance. Y cuando los modelos ágiles están equipados con la recuperación dinámica de datos privados específicos del dominio y la recuperación dirigida de contenido web basado en una consulta, se vuelven más precisos y más rentables que los modelos gigantes que memorizan un conjunto de datos de amplio alcance.

A medida que los modelos ágiles de código abierto de GenAI avanzan para impulsar la rápida progresión del campo, este “momento iPhone”, cuando una tecnología revolucionaria se vuelve mainstream, está siendo desafiado por una “revolución Android” a medida que una sólida comunidad de investigadores y desarrolladores construye sobre los esfuerzos de código abierto de los demás para crear modelos ágiles cada vez más capaces.
- Ajusta tu propio modelo de Llama 2 en un cuaderno de Colab
- Muybridge Derby Dando vida a las fotografías de locomoción animal con IA
- Conoce a Brain2Music Un método de IA para reconstruir música a partir de la actividad cerebral capturada mediante Resonancia Magnética Funcional (fMRI).
Pensar, Hacer, Saber: Los modelos ágiles con dominios específicos pueden rendir como modelos gigantes
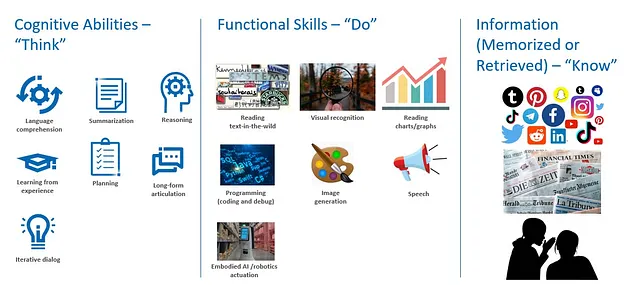
Para comprender mejor cuándo y cómo un modelo más pequeño puede ofrecer resultados altamente competitivos para la IA generativa, es importante observar que tanto los modelos ágiles como los gigantes de GenAI necesitan tres clases de competencias para funcionar:
- Habilidades cognitivas para pensar: Incluyendo comprensión del lenguaje, resumen, razonamiento, planificación, aprendizaje a partir de la experiencia, articulación de largo alcance y diálogo interactivo.
- Habilidades funcionales para hacer: Por ejemplo, leer texto en situaciones reales, leer gráficos/tablas, reconocimiento visual, programación (codificación y depuración), generación de imágenes y habla.
- Información (memorizada o recuperada) para saber: Contenido web, incluyendo redes sociales, noticias, investigación y otro contenido general, y/o contenido específico del dominio seleccionado, como datos médicos, financieros y empresariales.
Habilidades cognitivas para pensar. Basado en sus habilidades cognitivas, el modelo puede “pensar” y comprender, resumir, sintetizar, razonar y componer lenguaje y otras representaciones simbólicas. Tanto los modelos ágiles como los gigantes pueden desempeñarse bien en estas tareas cognitivas y no está claro si esas capacidades centrales requieren tamaños de modelo masivos. Por ejemplo, modelos ágiles como Orca de Microsoft Research están mostrando habilidades de comprensión, lógica y razonamiento que ya igualan o superan las de ChatGPT en múltiples referencias. Además, Orca también demuestra que las habilidades de razonamiento se pueden destilar de modelos más grandes utilizados como profesores. Sin embargo, los benchmarks actuales utilizados para evaluar las habilidades cognitivas de los modelos aún son rudimentarios. Se requiere más investigación y benchmarking para validar que los modelos ágiles pueden ser pre-entrenados o afinados para igualar completamente la fuerza de “pensamiento” de los modelos gigantes.
Habilidades funcionales para realizar. Es probable que los modelos más grandes tengan más habilidades funcionales e información dada su atención general como modelos todo en uno. Sin embargo, para la mayoría de los usos empresariales, hay un rango particular de habilidades funcionales necesarias para cualquier aplicación que se implemente. Un modelo utilizado en una aplicación empresarial debe tener flexibilidad y margen de crecimiento y variación de uso, pero rara vez necesita un conjunto ilimitado de habilidades funcionales. GPT-4 puede generar texto, código e imágenes en varios idiomas, pero hablar cientos de idiomas no significa necesariamente que esos modelos gigantes tengan competencias cognitivas subyacentes inherentemente más amplias, principalmente brinda al modelo habilidades funcionales adicionales para hacer más. Además, los motores especializados funcionalmente se vincularán a los modelos GenAI y se utilizarán cuando se necesite esa funcionalidad, como agregar “superpoderes matemáticos de Wolfram” a ChatGPT modularmente podría proporcionar funcionalidad de primer nivel sin sobrecargar el modelo con una escala innecesaria. Por ejemplo, GPT-4 está implementando complementos que utilizan modelos más pequeños para funciones adicionales. También se rumorea que el propio modelo GPT-4 es una colección de múltiples modelos gigantes (con menos de 100B de parámetros) “mezcla de expertos” entrenados en diferentes datos y distribuciones de tareas en lugar de un modelo denso monolítico como GPT-3.5. Para obtener la mejor combinación de capacidades y eficiencias del modelo, es probable que los futuros modelos multifuncionales utilicen modelos de mezcla de expertos más pequeños y más enfocados, cada uno con menos de 15B de parámetros.
Información (memorizada o recuperada) para conocer. Los modelos gigantes “saben” más al memorizar vastas cantidades de datos dentro de la memoria paramétrica, pero esto no necesariamente los hace más inteligentes. Simplemente tienen un conocimiento general más amplio que los modelos más pequeños. Los modelos gigantes tienen un alto valor en entornos de cero disparo para nuevos casos de uso, ofreciendo una base de consumidores general cuando no hay necesidad de orientación y actuando como un modelo de enseñanza al destilar y afinar modelos ágiles como Orca. Sin embargo, los modelos ágiles dirigidos pueden ser entrenados o afinados para dominios específicos, proporcionando habilidades más precisas para las capacidades necesarias.
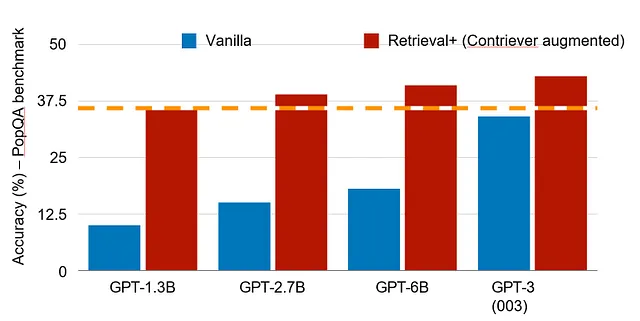
Por ejemplo, un modelo orientado a la programación puede enfocarse en un conjunto diferente de capacidades que un sistema de inteligencia artificial en el campo de la salud. Además, al utilizar la recuperación sobre un conjunto seleccionado de datos internos y externos, se puede mejorar en gran medida la precisión y puntualidad del modelo. Un estudio reciente mostró que en el benchmark PopQA, modelos con tan solo 1,3B de parámetros y recuperación pueden desempeñarse tan bien como un modelo más de cien veces su tamaño con 175B de parámetros (ver Figura 4). En ese sentido, el conocimiento relevante de un sistema objetivo con datos accesibles indexados de alta calidad puede ser mucho más extenso que un sistema general todo en uno. Esto puede ser más importante para la mayoría de las aplicaciones empresariales que requieren datos específicos de casos de uso o aplicaciones, y en muchos casos, conocimiento local en lugar de un conocimiento general vasto. Aquí es donde se realizará el valor de los modelos ágiles en el futuro.
Tres aspectos que contribuyen al crecimiento explosivo de los modelos ágiles
Existen tres aspectos a considerar al evaluar los beneficios y el valor de los modelos ágiles:
- Alta eficiencia en tamaños de modelo modestos.
- Licencias de código abierto o propietarias.
- Especialización del modelo como propósito general o específico, incluyendo la recuperación.
En cuanto al tamaño, los modelos ágiles de propósito general, como el LLaMA-7B y -13B de Meta o los modelos de código abierto Falcon 7B del Technology Innovation Institute, y los modelos propietarios como el MPT-7B de MosaicML, el Orca-13B de Microsoft Research y el XGen-7B de Saleforce AI Research, están mejorando en rápida sucesión (ver Figura 6). Tener la opción de modelos de alto rendimiento y de menor tamaño tiene implicaciones significativas en el costo de operación, así como en la elección de entornos informáticos. El modelo de 175 mil millones de parámetros de ChatGPT y los aproximadamente 1.8 billones de parámetros estimados para GPT-4 requieren una instalación masiva de aceleradores como GPUs con suficiente potencia de cálculo para manejar la carga de entrenamiento y ajuste fino. En cambio, los modelos ágiles generalmente pueden ejecutar inferencias en cualquier hardware, desde una CPU de un solo socket, pasando por GPUs de nivel de entrada, hasta los racks de aceleración más grandes. La definición actual de IA ágil se ha establecido en 15 mil millones de parámetros, basada empíricamente en los resultados sobresalientes de los modelos de tamaño 13B o más pequeños. En general, los modelos ágiles ofrecen un enfoque más rentable y escalable para manejar nuevos casos de uso (ver la sección sobre ventajas y desventajas de los modelos ágiles).
El segundo aspecto de las licencias de código abierto permite a las universidades y empresas iterar en los modelos de otros, impulsando un auge de innovaciones creativas. Los modelos de código abierto permiten el increíble progreso de las capacidades de los modelos pequeños, como se demuestra en la Figura 5.
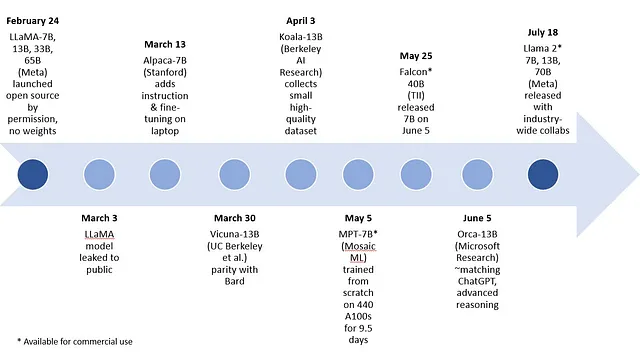
Existen múltiples ejemplos de principios de 2023 de modelos ágiles generativos de IA general, comenzando con LLaMA de Meta, que tiene modelos con 7B, 13B, 33B y 65B de parámetros. Los siguientes modelos en el rango de parámetros de 7B y 13B fueron creados mediante ajuste fino de LLaMA: Alpaca de la Universidad de Stanford, Koala de Berkeley AI Research y Vicuna creado por investigadores de UC Berkeley, Carnegie Mellon University, Stanford, UC San Diego y MBZUAI. Recientemente, Microsoft Research publicó un artículo sobre el modelo Orca, basado en LLaMA y con 13B de parámetros, que imita el proceso de razonamiento de los modelos gigantes con resultados impresionantes antes de dirigirse o ajustarse fino a un dominio específico.
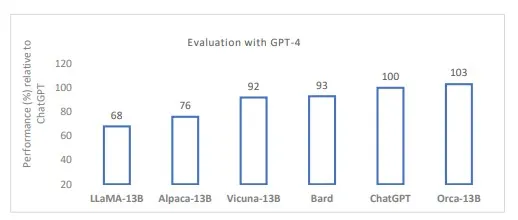
Vicuna podría ser una buena referencia para los modelos ágiles de código abierto recientes que se derivaron de LLaMA como modelo base. Vicuna-13B es un chatbot creado por una colaboración universitaria que se ha “desarrollado para abordar la falta de detalles de entrenamiento y arquitectura en modelos existentes como ChatGPT”. Después de ajustarse finamente en conversaciones compartidas por los usuarios de ShareGPT, la calidad de respuesta de Vicuna es superior al 90% en comparación con ChatGPT y Google Bard cuando se utiliza GPT-4 como juez. Sin embargo, estos modelos de código abierto tempranos no están disponibles para uso comercial. Los modelos de código abierto comercialmente utilizables MPT-7B de MosaicML y Falcon 7B del Technology Innovation Institute son supuestamente de igual calidad que LLaMA-7B.
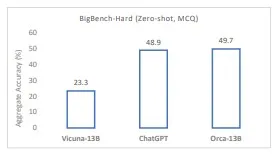
Orca “supera a los modelos de instrucción convencionales como Vicuna-13B en más del 100% en pruebas de razonamiento de cero disparo complejas como Big-Bench Hard (BBH). Alcanza la paridad con ChatGPT-3.5 en la prueba BBH”, según los investigadores. El rendimiento superior de Orca-13B sobre otros modelos generales refuerza la noción de que el tamaño grande de los modelos gigantes puede resultar de modelos tempranos de fuerza bruta. La escala de los modelos gigantes puede ser importante para algunos modelos más pequeños como Orca-13B para destilar conocimiento y métodos, pero el tamaño no es necesariamente requerido para la inferencia, incluso para el caso general. Una palabra de precaución: una evaluación completa de las capacidades cognitivas, habilidades funcionales y memorización de conocimientos del modelo solo será posible cuando se implemente y se ejecute ampliamente.
A partir de la redacción de este blog, Meta lanzó su modelo Llama 2 con 7B, 13B y 70B de parámetros. Llegando apenas cuatro meses después de la primera generación, el modelo ofrece mejoras significativas. En el gráfico de comparación, un ágil Llama 2 13B logra resultados similares a modelos más grandes de la generación LLaMA anterior, así como a MPT-30B y Falcon 40B. Llama 2 es de código abierto y gratuito para uso de investigación y comercial. Se presentó en estrecha colaboración con Microsoft y varios otros socios, incluyendo Intel. El compromiso de Meta con los modelos de código abierto y su amplia colaboración seguramente impulsarán aún más los rápidos ciclos de mejora interindustria/academia que estamos viendo para este tipo de modelos.
El tercer aspecto de los modelos ágiles tiene que ver con la especialización. Muchos de los modelos ágiles recién introducidos son de propósito general, como LLaMA, Vicuna y Orca. Los modelos ágiles generales pueden depender únicamente de su memoria paramétrica, utilizando actualizaciones de bajo costo a través de métodos de ajuste fino que incluyen LoRA: Adaptación de Rango Bajo de Modelos de Lenguaje Grandes, así como generación mejorada por recuperación, que extrae conocimiento relevante de un corpus curado sobre la marcha durante el tiempo de inferencia. Las soluciones de recuperación mejoradas se están estableciendo y mejorando continuamente con los marcos de GenAI, como LangChain y Haystack. Estos marcos permiten una integración fácil y flexible de la indexación y el acceso efectivo a grandes corpus para la recuperación basada en semántica.
La mayoría de los usuarios empresariales prefieren modelos específicos adaptados a su dominio de interés. Estos modelos específicos también tienden a ser de recuperación para utilizar todos los activos clave de información. Por ejemplo, los usuarios del sector de la salud pueden querer automatizar las comunicaciones con los pacientes.
Los modelos específicos utilizan dos métodos:
- Especialización del propio modelo para las tareas y el tipo de datos requeridos para los casos de uso específicos. Esto se puede hacer de varias formas, incluyendo el preentrenamiento de un modelo en conocimientos específicos del dominio (como cuando phi-1 se preentrena en datos de calidad de libro de texto de la web), el ajuste fino de un modelo base de propósito general del mismo tamaño (como cuando Clinical Camel ajusta finamente LLaMA-13B) o la destilación y el aprendizaje de un modelo gigante en un modelo ágil de estudiante (como cuando Orca aprende a imitar el proceso de razonamiento de GPT-4, incluyendo trazas de explicación, procesos de pensamiento paso a paso y otras instrucciones complejas).
- Curación e indexación de datos relevantes para la recuperación sobre la marcha, que puede ser un volumen grande, pero aún dentro del alcance/espacio del caso de uso específico. Los modelos pueden recuperar contenido de la web pública y de consumidores o empresas privadas que se actualiza continuamente. Los usuarios determinan qué fuentes indexar, lo que permite elegir recursos de alta calidad de la web y recursos más completos como datos privados de un individuo o datos empresariales de una empresa. Si bien la recuperación ahora está integrada en sistemas gigantes y ágiles, desempeña un papel crucial en los modelos más pequeños, ya que proporciona toda la información necesaria para el rendimiento del modelo. También permite a las empresas poner a disposición de un modelo ágil toda su información privada y local que se ejecuta en su entorno informático.
Ventajas y desventajas del modelo AI Generativo Ágil
En el futuro, el tamaño de los modelos compactos podría aumentar a 20B o 25B de parámetros, pero aún se mantendría muy por debajo del alcance de los 100B de parámetros. También existe una variedad de modelos de tamaños intermedios como MPT-30B, Falcon 40B y Llama 2 70B. Si bien se espera que funcionen mejor que los modelos más pequeños en cero disparo, no esperaría que tengan un rendimiento sustancialmente mejor para cualquier conjunto definido de funcionalidades que los modelos ágiles, específicos y basados en recuperación.
En comparación con los modelos gigantes, hay muchas ventajas de los modelos ágiles, que se ven reforzadas cuando el modelo es específico y basado en recuperación. Estos beneficios incluyen:
- Modelos sostenibles y de menor costo: Modelos con costos de capacitación e inferencia considerablemente más bajos. Los costos de tiempo de ejecución de inferencia pueden ser el factor determinante para la viabilidad de modelos orientados a negocios integrados en usos 24×7, y el impacto ambiental mucho reducido también es significativo cuando se considera en conjunto en despliegues amplios. Por último, con sus sistemas sostenibles, específicos y orientados funcionalmente, los modelos ágiles no intentan abordar objetivos ambiciosos de inteligencia artificial general (AGI) y, por lo tanto, están menos involucrados en el debate público y regulatorio relacionado con este último.
- Iteraciones de ajuste fino más rápidas: Los modelos más pequeños se pueden ajustar finamente en unas pocas horas (o menos), agregando nueva información o funcionalidad al modelo a través de métodos de adaptación como LoRA, que son altamente efectivos en modelos ágiles. Esto permite ciclos de mejora más frecuentes, manteniendo el modelo continuamente actualizado según sus necesidades de uso.
- Beneficios del modelo basado en recuperación: Los sistemas de recuperación refactorizan el conocimiento, haciendo referencia a la mayor parte de la información de las fuentes directas en lugar de la memoria paramétrica del modelo. Esto mejora lo siguiente:– Explicabilidad: Los modelos de recuperación utilizan atribución de fuente, proporcionando procedencia o la capacidad de rastrear hasta la fuente de información para brindar credibilidad.– Oportunidad: Una vez que se indexa una fuente actualizada, está disponible de inmediato para su uso por parte del modelo sin necesidad de entrenamiento o ajuste fino. Esto permite agregar o actualizar continuamente información relevante en tiempo real.– Alcance de los datos: La información indexada para la recuperación según la necesidad puede ser muy amplia y detallada. Cuando se centra en sus dominios objetivo, el modelo puede cubrir un amplio alcance y profundidad de datos privados y públicos. Puede incluir más volumen y detalles en su espacio objetivo que un conjunto de entrenamiento de modelo de fundación gigante.– Precisión: El acceso directo a los datos en su forma original, detalle y contexto puede reducir las alucinaciones y las aproximaciones de datos. Puede proporcionar respuestas confiables y completas siempre que estén en el espacio de recuperación. Con modelos más pequeños, también hay menos conflictos entre la información curada rastreable recuperada según la necesidad y la información memorizada (como en los modelos gigantes) que puede estar desactualizada, ser parcial y no atribuible a fuentes.
- Elección de hardware: La inferencia de modelos ágiles se puede realizar prácticamente en cualquier hardware, incluidas soluciones ubicuas que podrían formar parte del entorno informático. Por ejemplo, los modelos ágiles Llama 2 de Meta (7B y 13B de parámetros) se ejecutan bien en los productos de centro de datos de Intel, incluidos Xeon, Gaudi2 e Intel Data Center GPU Max Series.
- Integración, seguridad y privacidad: Los modelos de GenAI como ChatGPT y otros modelos gigantes son modelos independientes que generalmente se ejecutan en instalaciones de aceleradores grandes en una plataforma de terceros y se acceden a través de interfaces. Los modelos de IA ágiles pueden funcionar como un motor integrado en una aplicación empresarial más grande y se pueden integrar completamente en el entorno informático local. Esto tiene importantes implicaciones para la seguridad y privacidad, ya que no es necesario intercambiar/exponer información con modelos y entornos informáticos de terceros, y todos los mecanismos de seguridad de la aplicación más amplia se pueden aplicar al motor de GenAI.
- Optimización y reducción de modelos: Las técnicas de optimización y reducción de modelos como la cuantificación, que reduce las demandas comput
Algunos desafíos de los modelos ágiles aún merecen ser mencionados:
- Rango reducido de tareas: Los modelos gigantes de propósito general tienen una versatilidad sobresaliente y destacan especialmente en nuevos usos sin necesidad de entrenamiento previo que no se consideraron anteriormente. La amplitud y el alcance que se pueden lograr con los sistemas ágiles aún se están evaluando, pero parece estar mejorando con los modelos recientes. Los modelos dirigidos asumen que el rango de tareas se conoce y define durante el preentrenamiento y/o el ajuste fino, por lo que la reducción en el alcance no debería afectar ninguna capacidad relevante. Los modelos dirigidos no son de una sola tarea, sino más bien una familia de capacidades relacionadas. Esto puede llevar a la fragmentación como resultado de modelos ágiles específicos de tareas o negocios.
- Puede mejorar con ajuste fino de pocos ejemplos: Para que un modelo aborde de manera efectiva un espacio específico, no siempre es necesario realizar un ajuste fino, pero puede ayudar a la efectividad de la IA al ajustar el modelo a las tareas e información necesaria para la aplicación. Las técnicas modernas permiten realizar este proceso con un pequeño número de ejemplos y sin la necesidad de tener experiencia en ciencia de datos compleja.
- Los modelos de recuperación necesitan indexar todos los datos de origen: Los modelos obtienen la información necesaria durante la inferencia a través de la asignación de índices, pero existe el riesgo de perder una fuente de información, lo que la hace no disponible para el modelo. Para garantizar la procedencia, la explicabilidad y otras propiedades, los modelos dirigidos basados en la recuperación no deben depender de información detallada almacenada en la memoria paramétrica, sino que deben depender principalmente de información indexada que esté disponible para extraer cuando sea necesario.
Resumen
El gran salto en la IA generativa está permitiendo nuevas capacidades como agentes de IA que conversan en lenguaje natural, la resumenización y generación de texto convincente, la creación de imágenes, la utilización del contexto de iteraciones anteriores y mucho más. Este blog presenta el término “IA ágil” y argumenta por qué será el método predominante en la implementación de la IA generativa a gran escala. En pocas palabras, los modelos de IA ágiles se ejecutan más rápido, se actualizan rápidamente mediante un ajuste fino continuo y son más propensos a ciclos de mejora tecnológica rápida a través de la innovación colectiva de la comunidad de código abierto.
Como se ha demostrado a través de múltiples ejemplos, el rendimiento sobresaliente que surgió a través de la evolución de los modelos gigantes muestra que los modelos ágiles no requieren la misma robustez masiva que los modelos gigantes. Una vez que se han dominado las habilidades cognitivas subyacentes, se ha ajustado la funcionalidad necesaria y se ha puesto a disposición los datos según sea necesario, los modelos ágiles brindan el mayor valor para el mundo empresarial.
Dicho esto, los modelos ágiles no harán que los modelos gigantes se extingan. Se espera que los modelos gigantes sigan funcionando mejor en un entorno “listo para usar” sin necesidad de entrenamiento previo. Estos modelos grandes también podrían ser utilizados como fuente (modelo de profesor) para la destilación en modelos más pequeños y ágiles. Si bien los modelos gigantes tienen un gran volumen de información adicional memorizada para abordar cualquier uso potencial, y están equipados con múltiples habilidades, no se espera que esta generalidad sea necesaria para la mayoría de las aplicaciones de IA generativa. En su lugar, la capacidad de ajustar finamente un modelo a la información y habilidades relevantes para el dominio, además de la capacidad de recuperar información reciente de fuentes locales y globales curadas, sería una propuesta de valor mucho mejor para muchas aplicaciones.
Ver los modelos de IA ágiles y dirigidos como módulos que se pueden incorporar en cualquier aplicación existente ofrece una propuesta de valor muy convincente que incluye:
- Requiere una fracción del costo para implementación y operación.
- Adaptable a tareas y datos privados/empresariales.
- Actualizable durante la noche y se puede ejecutar en cualquier hardware, desde CPU hasta GPU o aceleradores.
- Integrado en el entorno de cómputo y la aplicación actual.
- Funciona en local o en una nube privada.
-
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Nuevo curso técnico de inmersión profunda Fundamentos de IA generativa en AWS
- ¡Fantástico! Artista 3D se sumerge en trabajos oceánicos impulsados por inteligencia artificial esta semana ‘En el Estudio de NVIDIA
- NVIDIA DGX Cloud ahora disponible para impulsar el entrenamiento de IA generativa
- Regs necesarias para la IA de alto riesgo, dice ACM Es el Viejo Oeste
- La Huella de Carbono de la Inteligencia Artificial
- La modelación en 3D se basa en la inteligencia artificial
- Algoritmo para la detección y movimiento robótico






