Cómo ajustar modelos de lenguaje grandes en memoria pequeña cuantización
Como ajustar modelos de lenguaje grandes en memoria pequeña cuantización
Los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) se pueden utilizar para la generación de texto, traducción, tareas de pregunta-respuesta, etc. Sin embargo, los LLMs también son muy grandes (obviamente, Modelos de Lenguaje Grandes) y requieren mucha memoria. Esto puede dificultar su uso en dispositivos pequeños como teléfonos y tabletas.
Multiplica los parámetros por el tamaño de precisión elegido para determinar el tamaño del modelo en bytes. Supongamos que la precisión que hemos elegido es float16 (16 bits = 2 bytes). Digamos que queremos usar el modelo BLOOM-176B. ¡Necesitamos 176 mil millones de parámetros * 2 bytes = 352GB para cargar el modelo!
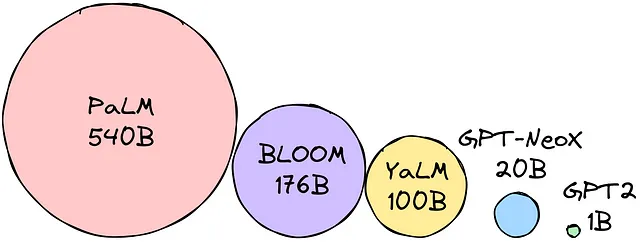
En otras palabras, ¡para cargar todos los pesos de los parámetros, necesitamos 12(!) máquinas de 32GB! Esto es demasiado si queremos hacer que los LLMs sean portátiles. Se han desarrollado técnicas para reducir la huella de memoria de los LLMs para superar esta dificultad. Las técnicas más populares son:
- Cuantización: implica convertir los pesos de los LLMs a un formato de menor precisión, reduciendo la memoria requerida para almacenarlos.
- Destilación de conocimiento: implica entrenar un LLM más pequeño para imitar el comportamiento de un LLM más grande. Esto se puede hacer transfiriendo el conocimiento del LLM más grande al LLM más pequeño.
Estas técnicas han hecho posible que los LLMs se ajusten en memoria pequeña. Esto ha abierto nuevas posibilidades para el uso de LLMs en varios dispositivos. Hoy hablaremos sobre cuantización (manténgase atento para la destilación de conocimiento).
- Usando SQL para entender las tendencias de carrera en Ciencia de Datos
- Industria 4.0 Metaverso Desbloqueado Cómo la Tecnología AR/VR, AI y 3D están Impulsando la Próxima Revolución Industrial
- Generación de música a partir de texto Stability Audio, MusicLM de Google y más
Cuantización
Comencemos con un ejemplo sencillo. Necesitaremos transformar 2023 a binario:
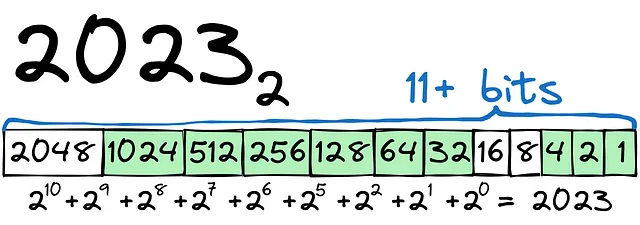
Como puedes ver, el proceso es relativamente sencillo. Para almacenar el número 2023, necesitaremos al menos 12 bits (1 bit para el signo + o —). Para el número, podríamos usar el tipo int16.
Hay una gran diferencia entre almacenar un entero como binario y almacenar un número decimal como binario. Intentemos convertir 20.23 a binario:
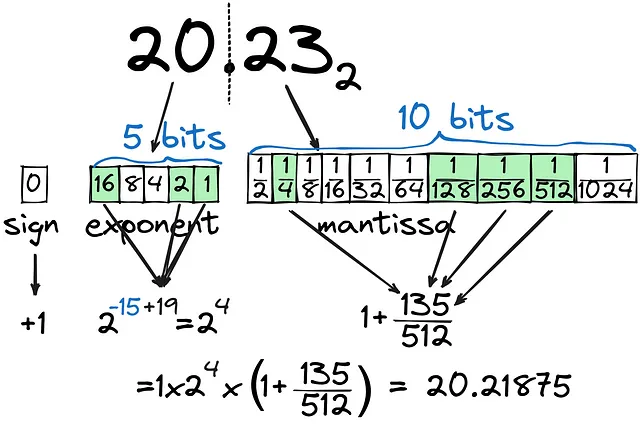
Como se puede ver, la parte decimal (mantisa) se calcula como la combinación de 1/2^n y no se puede calcular con mucha precisión, incluso con 10 bits dedicados a la parte decimal. La parte entera (exponente) se establece en 5 bits, cubriendo todos los números hasta 32. En total, estamos utilizando 16 bits (FP16) para almacenar lo más cercano que podemos a 20.23, pero ¿es la forma más efectiva de guardar números decimales? ¿Qué pasa si la parte entera del número es mucho mayor, digamos 202.3?
Si observamos los tipos de datos de punto flotante estándar, notaremos que para almacenar 202.3, necesitaremos usar FP32, lo cual, desde una perspectiva computacional, está lejos de ser razonable. En cambio, podemos usar un bfloat16 para guardar el rango (exponente) en 8 bits y 7 bits para la precisión (mantisa). Esto nos permite ampliar el alcance de los decimales posibles sin perder mucha precisión.
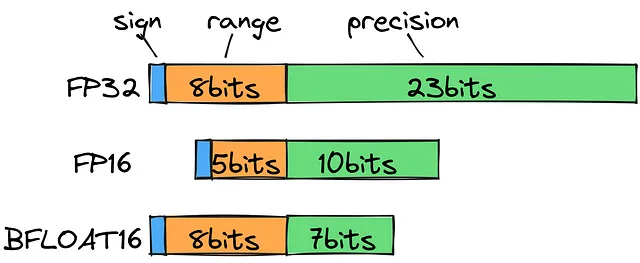
Para ser claros, durante el entrenamiento, necesitamos toda la precisión posible. Pero priorizar la velocidad y el tamaño por encima del sexto decimal tiene sentido para la inferencia.
¿Podemos reducir el uso de memoria de bfloat16 a, digamos, int8?
Cuantización de punto cero y abs-max
De hecho, podemos hacerlo, y hay varios enfoques para tal cuantización:
- La cuantización de punto cero ahorra la mitad de la memoria al convertir un rango fijo (-1, 1) a int8 (-127, 127), seguido de la conversión de int8 a bfloat16.
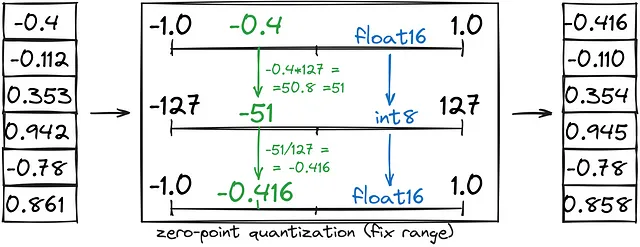
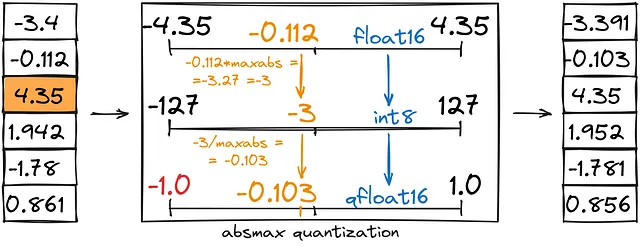
- La cuantización de valor absoluto máximo es similar a la cuantización de punto cero, pero en lugar de establecer un rango personalizado (-1,1), lo establecemos como (-abs(máximo), abs(máximo)).
Echemos un vistazo a cómo se utilizan estas prácticas en un ejemplo de multiplicación de matrices:
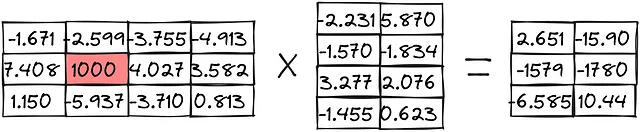
Cuantización de punto cero:

Cuantización de valor absoluto máximo:
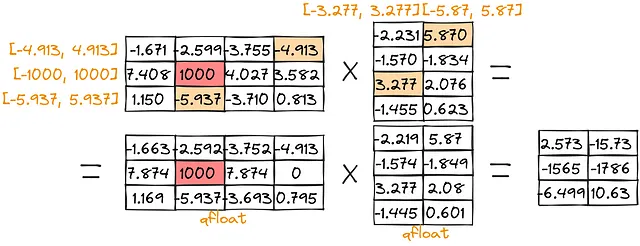
Como se puede observar, la puntuación para los valores grandes [-1579, -1780] es bastante baja ([-1579, -1752] para punto cero y [-1565,-1786] para valor absoluto máximo). Para superar estos problemas, podemos separar la multiplicación de valores atípicos:

Como se puede ver, los resultados están mucho más cerca de los valores reales.
Pero ¿hay alguna forma de usar incluso menos espacio sin perder mucha calidad?
¡Para mi sorpresa, hay una forma! ¿Qué pasaría si, en lugar de convertir cada número de forma independiente a un tipo inferior, tuviéramos en cuenta el error y lo usáramos para realizar ajustes? Esta técnica se llama GPTQ.
Al igual que en la cuantización anterior, encontramos la coincidencia más cercana para los decimales que podemos, manteniendo el error de conversión total lo más cercano posible a cero.
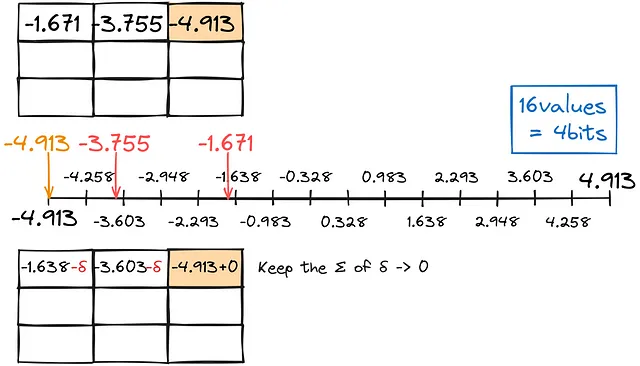
Llenamos la matriz de fila en fila de esta manera.
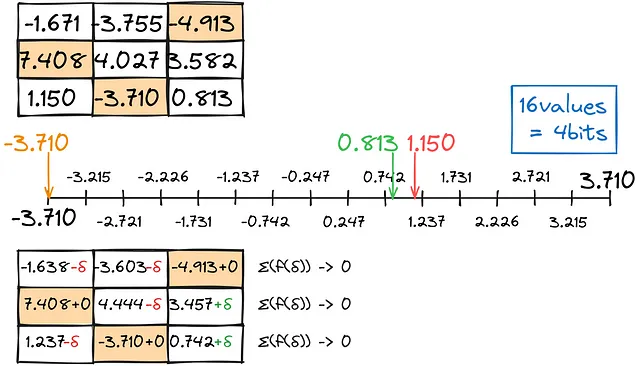
El resultado, combinado con cálculos separados de anomalías, proporciona resultados bastante aceptables:
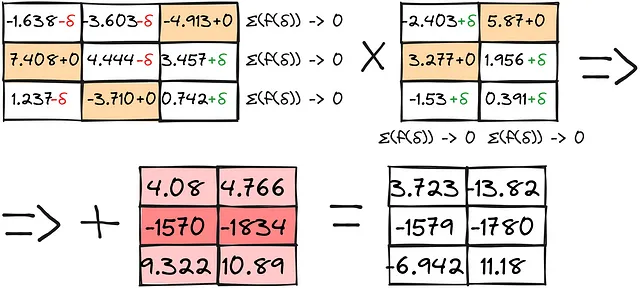
Ahora podemos comparar todos los métodos:

¡Los métodos LLM.int8() funcionan bastante bien! El enfoque GPTQ pierde calidad pero permite usar el doble de memoria de GPU que el método int8.
En el código, es posible encontrar algo similar a lo siguiente:
from transformers import BitsAndBytesConfig# Configurar BitsAndBytesConfig para cuantización de 4 bitsbnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16,)# Cargar el modelo en la configuración preestablecidamodelo_preentrenado = AutoModelForCausalLM.from_pretrained( id_del_modelo, quantization_config=bnb_config,)La bandera load_in_4bit especifica que el modelo se debe cargar con una precisión de 4 bits. La bandera bnb_4bit_use_double_quant especifica que se debe usar una doble cuantización. La bandera bnb_4bit_quant_type especifica el tipo de cuantización. La bandera bnb_4bit_compute_dtype especifica el tipo de cálculo.
En resumen, hemos aprendido cómo se almacenan los decimales en memoria, cómo reducir el consumo de memoria con cierta pérdida de precisión y cómo ejecutar modelos seleccionados con cuantización de 4 bits.

El artículo original fue publicado en mi página de LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La diferencia entre los modelos de código abierto y las APIs comerciales de IA/ML
- Encontrando conocimientos sobre los clientes con ChatGPT
- Mejorando el análisis de retroalimentación de encuestas de clientes con grandes modelos de lenguaje
- 30 Años de Ciencia de Datos Una Revisión Desde la Perspectiva de un Profesional de la Ciencia de Datos
- Grandes modelos de lenguaje RoBERTa – Un enfoque robustamente optimizado de BERT
- Cuantificando las Regresiones Ocultas de GPT-4 a lo largo del tiempo
- You.com lanza YouAgent un agente de IA con ejecución de código para respuestas más precisas a preguntas complejas de matemáticas y ciencias.





