Entendiendo las métricas de clasificación tu guía para evaluar la precisión del modelo
Comprendiendo las métricas de clasificación tu guía para evaluar la precisión del modelo

Motivación
Las métricas de evaluación son como las herramientas de medición que utilizamos para entender qué tan bien está haciendo su trabajo un modelo de aprendizaje automático. Nos ayudan a comparar diferentes modelos y descubrir cuál funciona mejor para una tarea específica. En el mundo de los problemas de clasificación, existen métricas comúnmente utilizadas para evaluar qué tan bueno es un modelo, y es esencial saber qué métrica es adecuada para nuestro problema específico. Cuando entendemos los detalles de cada métrica, se vuelve más fácil decidir cuál se adapta a las necesidades de nuestra tarea.
- Un cambio de paradigma en el desarrollo de software los agentes de inteligencia artificial AI de GPTConsole abren nuevos horizontes
- Nuevas formas en las que estamos ayudando a reducir las emisiones de transporte y energía
- Agregando filtros de realidad aumentada a las videollamadas usando DeepAR y Dyte
En este artículo, exploraremos las métricas de evaluación básicas utilizadas en tareas de clasificación y examinaremos situaciones en las que una métrica puede ser más relevante que otras.
Términos Básicos
Antes de profundizar en las métricas de evaluación, es fundamental entender la terminología básica asociada a un problema de clasificación.
Etiquetas de la verdad absoluta: Se refieren a las etiquetas reales correspondientes a cada ejemplo en nuestro conjunto de datos. Estas son la base de toda evaluación y se comparan las predicciones con estos valores.
Etiquetas predichas: Son las etiquetas de clase predichas utilizando el modelo de aprendizaje automático para cada ejemplo en nuestro conjunto de datos. Comparamos estas predicciones con las etiquetas de la verdad absoluta utilizando diversas métricas de evaluación para calcular si el modelo pudo aprender las representaciones en nuestros datos.
Ahora, supongamos solamente un problema de clasificación binaria para una comprensión más sencilla. Con solo dos clases diferentes en nuestro conjunto de datos, comparar las etiquetas de la verdad absoluta con las etiquetas predichas puede resultar en uno de los siguientes cuatro resultados, como se ilustra en el diagrama. 
Verdaderos Positivos: El modelo predice una etiqueta de clase positiva cuando la verdad absoluta también es positiva. Este es el comportamiento deseado, ya que el modelo puede predecir correctamente una etiqueta positiva.
Falsos Positivos: El modelo predice una etiqueta de clase positiva cuando la etiqueta de la verdad absoluta es negativa. El modelo identifica erróneamente una muestra de datos como positiva.
Falsos Negativos: El modelo predice una etiqueta de clase negativa para un ejemplo positivo. El modelo identifica erróneamente una muestra de datos como negativa.
Verdaderos Negativos: También es un comportamiento deseado. El modelo identifica correctamente una muestra de datos negativa, prediciendo 0 para una muestra que tiene una etiqueta de la verdad absoluta de 0.
Ahora, podemos basarnos en estos términos para comprender cómo funcionan las métricas de evaluación comunes.
Precisión
Esta es la forma más simple pero intuitiva de evaluar el rendimiento de un modelo para problemas de clasificación. Mide la proporción de etiquetas totales que el modelo predijo correctamente.
Por lo tanto, la precisión se puede calcular de la siguiente manera:
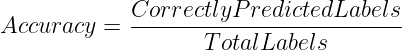
o
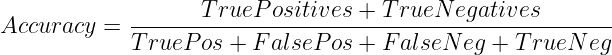
Cuándo Usar
- Evaluación Inicial del Modelo
Dada su simplicidad, la precisión es una métrica ampliamente utilizada. Proporciona un buen punto de partida para verificar si el modelo puede aprender correctamente antes de usar métricas específicas de nuestro dominio de problema.
- Conjuntos de Datos Equilibrados
La precisión solo es adecuada para conjuntos de datos equilibrados, donde todas las etiquetas de clase están en proporciones similares. Si ese no es el caso y una etiqueta de clase supera significativamente a las demás, el modelo aún puede lograr una alta precisión al predecir siempre la clase mayoritaria. La métrica de precisión penaliza de manera equitativa las predicciones incorrectas para cada clase, lo que la hace inadecuada para conjuntos de datos desequilibrados.
- Cuando los costos de clasificación errónea son iguales
La precisión es adecuada para casos en los que Falsos Positivos o Falsos Negativos son igualmente malos. Por ejemplo, para un problema de análisis de sentimientos, es igualmente malo clasificar un texto negativo como positivo o un texto positivo como negativo. Para este tipo de escenarios, la precisión es una buena métrica.
Precisión
La precisión se enfoca en asegurarse de que todas las predicciones positivas sean correctas. Mide qué fracción de las predicciones positivas fueron realmente positivas.
Matemáticamente, se representa como
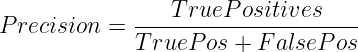
Cuándo usarlo
- Alto costo de falsos positivos
Considera un escenario en el que estamos entrenando un modelo para detectar el cáncer. Será más importante no clasificar incorrectamente a un paciente que no tiene cáncer, es decir, un falso positivo. Queremos tener confianza cuando hacemos una predicción positiva, ya que clasificar incorrectamente a una persona como positiva para el cáncer puede generar estrés y gastos innecesarios. Por lo tanto, valoramos mucho predecir una etiqueta positiva solo cuando la etiqueta actual es positiva.
- Calidad sobre cantidad
Considera otro escenario en el que estamos construyendo un motor de búsqueda que coincide las consultas de los usuarios con un conjunto de datos. En estos casos, valoramos que los resultados de búsqueda se ajusten de cerca a la consulta del usuario. No queremos devolver ningún documento irrelevante para el usuario, es decir, un falso positivo. Por lo tanto, solo predecimos de manera positiva para los documentos que se ajustan estrechamente a la consulta del usuario. Valoramos la calidad sobre la cantidad, ya que preferimos un pequeño número de resultados estrechamente relacionados en lugar de un alto número de resultados que pueden o no ser relevantes para el usuario. Para estos escenarios, deseamos una alta precisión.
Recuperación
La recuperación, también conocida como Sensibilidad, mide qué tan bien un modelo puede recordar las etiquetas positivas en el conjunto de datos. Mide qué fracción de las etiquetas positivas en nuestro conjunto de datos el modelo predice como positivas.
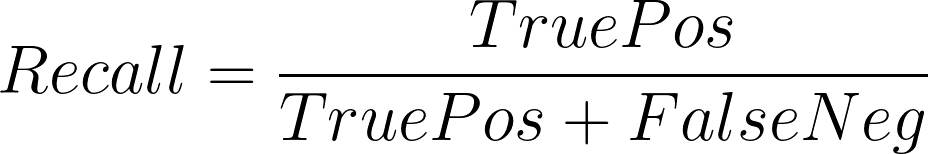
Un mayor recuperación significa que el modelo es mejor recordando qué datos tienen etiquetas positivas.
Cuándo usarlo
- Alto costo de falsos negativos
Usamos la recuperación cuando perder una etiqueta positiva puede tener consecuencias graves. Considera un escenario en el que estamos utilizando un modelo de aprendizaje automático para detectar fraude con tarjetas de crédito. En estos casos, la detección temprana de problemas es esencial. No queremos perder una transacción fraudulenta, ya que puede aumentar las pérdidas. Por lo tanto, valoramos la recuperación sobre la precisión, donde la clasificación incorrecta de una transacción como engañosa puede ser fácil de verificar y podemos permitir algunos falsos positivos en lugar de falsos negativos.
Puntuación F1
Es la media armónica de la precisión y la recuperación. Penaliza a los modelos que tienen un desequilibrio significativo entre una de las métricas.
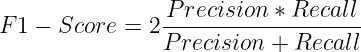
Se utiliza ampliamente en escenarios donde tanto la precisión como la recuperación son importantes y permite lograr un equilibrio entre ambas.
Cuándo usarlo
- Conjuntos de datos desequilibrados
A diferencia de la precisión, la puntuación F1 es adecuada para evaluar conjuntos de datos desequilibrados, ya que estamos evaluando el rendimiento basado en la capacidad del modelo para recordar la clase minoritaria mientras mantiene una alta precisión en general.
- Compromiso entre precisión y recuperación
Ambas métricas son opuestas entre sí. Empíricamente, mejorar una métrica a menudo conduce a un deterioro en la otra. La puntuación F1 ayuda a equilibrar ambas métricas y es útil en escenarios donde tanto la recuperación como la precisión son igualmente importantes. Teniendo en cuenta ambas métricas para el cálculo, la puntuación F1 es una métrica ampliamente utilizada para evaluar modelos de clasificación.
Conclusiones clave
Hemos aprendido que diferentes métricas de evaluación tienen trabajos específicos. Conocer estas métricas nos ayuda a elegir la correcta para nuestra tarea. En la vida real, no solo se trata de tener buenos modelos; se trata de tener modelos que se ajusten perfectamente a nuestras necesidades comerciales. Por lo tanto, elegir la métrica adecuada es como elegir la herramienta adecuada para asegurarnos de que nuestro modelo funcione bien donde más importa.
¿Sigues confundido acerca de qué métrica utilizar? Comenzar con la precisión es un buen primer paso. Proporciona una comprensión básica del rendimiento de tu modelo. A partir de ahí, puedes adaptar tu evaluación en función de tus requisitos específicos. Alternativamente, considera el F1-Score, que es una métrica versátil y equilibrada entre la precisión y el recuerdo, lo que la hace adecuada para diversos escenarios. Puede ser tu herramienta principal para una evaluación exhaustiva de la clasificación. Muhammad Arham es un Ingeniero de Aprendizaje Profundo que trabaja en Visión por Computadora y Procesamiento del Lenguaje Natural. Ha trabajado en la implementación y optimización de varias aplicaciones de IA generativa que han alcanzado los primeros puestos a nivel global en Vyro.AI. Está interesado en construir y optimizar modelos de aprendizaje automático para sistemas inteligentes y cree en la mejora continua.
Muhammad Arham es un Ingeniero de Aprendizaje Profundo que trabaja en Visión por Computadora y Procesamiento del Lenguaje Natural. Ha trabajado en la implementación y optimización de varias aplicaciones de IA generativa que han alcanzado los primeros puestos a nivel global en Vyro.AI. Está interesado en construir y optimizar modelos de aprendizaje automático para sistemas inteligentes y cree en la mejora continua.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprovechando la IA para prevenir la falta de vivienda Un cambio radical en Los Angeles
- Investigadores de Google y Cornell presentan DynIBaR Revolucionando la reconstrucción dinámica de escenas con IA
- Explorando los Iteradores Infinitos en itertools de Python
- Ajuste fino de LLM con técnicas PEFT
- Los modelos de base Mistral 7B de Mistral AI ahora están disponibles en Amazon SageMaker JumpStart.
- Los 10 Mejores Generadores de Objetos 3D con IA Generativa
- DeepMind de Google está revolucionando la robótica






