Clasificación Multietiqueta Una Introducción con Scikit-Learn de Python
Clasificación Multietiqueta con Scikit-Learn de Python

En tareas de aprendizaje automático, la clasificación es un método de aprendizaje supervisado para predecir la etiqueta dada la entrada de datos. Por ejemplo, queremos predecir si alguien está interesado en la oferta de ventas utilizando sus características históricas. Al entrenar el modelo de aprendizaje automático utilizando datos de entrenamiento disponibles, podemos realizar tareas de clasificación en los datos entrantes.
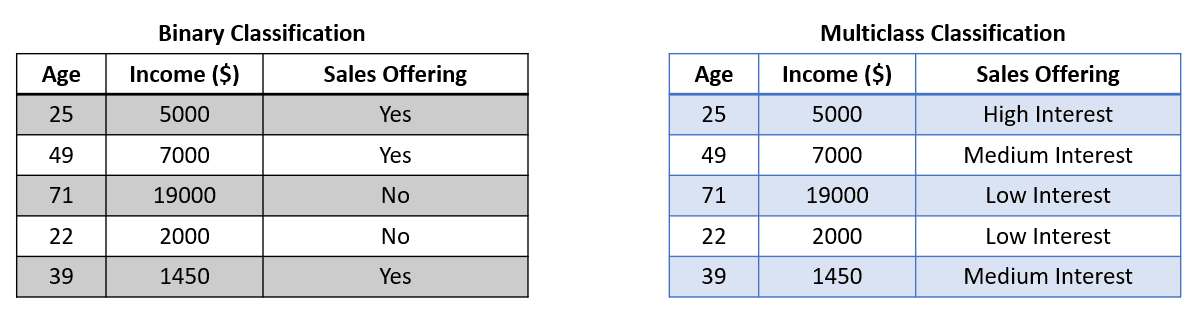
A menudo nos encontramos con tareas clásicas de clasificación como la clasificación binaria (dos etiquetas) y la clasificación multiclase (más de dos etiquetas). En este caso, entrenaríamos el clasificador y el modelo intentaría predecir una de las etiquetas de todas las etiquetas disponibles. El conjunto de datos utilizado para la clasificación es similar a la imagen a continuación.
- Fraude impulsado por IA ‘Deepfake’ La batalla continua de Kerala contra los estafadores
- Principales herramientas de IA para contabilidad 2023
- Conoce a BeLFusion Un enfoque de espacio latente de comportamiento para la predicción de movimiento humano estocástico realista y diverso utilizando difusión latente
La imagen de arriba muestra que el objetivo (Oferta de ventas) contiene dos etiquetas en la Clasificación binaria y tres en la Clasificación multiclase. El modelo se entrenaría a partir de las características disponibles y luego solo produciría una etiqueta.
La clasificación multietiqueta es diferente de la clasificación binaria o multiclase. En la clasificación multietiqueta, no intentamos predecir solo con una etiqueta de salida. En cambio, la clasificación multietiqueta intentaría predecir datos con tantas etiquetas como sea posible que se apliquen a los datos de entrada. La salida podría ser desde ninguna etiqueta hasta el número máximo de etiquetas disponibles.
La clasificación multietiqueta se utiliza a menudo en la tarea de clasificación de datos de texto. Por ejemplo, aquí hay un conjunto de datos de ejemplo para la clasificación multietiqueta.
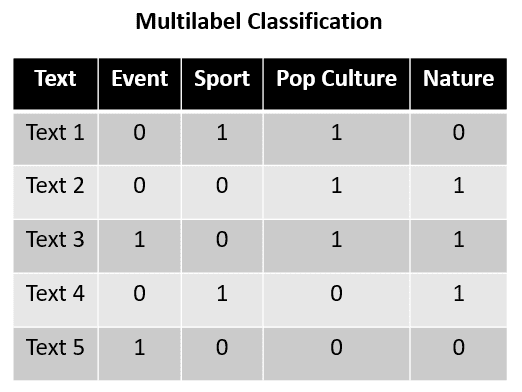
En el ejemplo anterior, imaginemos que Texto 1 a Texto 5 es una oración que se puede categorizar en cuatro categorías: Evento, Deporte, Cultura Popular y Naturaleza. Con los datos de entrenamiento anteriores, la tarea de clasificación multietiqueta predice qué etiqueta se aplica a la oración dada. Cada categoría no está en contra de las demás, ya que no son mutuamente excluyentes; cada etiqueta se puede considerar independiente.
Para más detalles, podemos ver que Texto 1 tiene las etiquetas Deporte y Cultura Popular, mientras que Texto 2 tiene las etiquetas Cultura Popular y Naturaleza. Esto muestra que cada etiqueta era mutuamente excluyente y que la clasificación multietiqueta puede tener una salida de predicción que no tenga ninguna etiqueta o todas las etiquetas simultáneamente.
Con esa introducción, intentemos construir un clasificador multiclase con Scikit-Learn.
Clasificación multietiqueta con Scikit-Learn
Este tutorial utilizará el conjunto de datos de Clasificación multietiqueta de Biomedical PubMed disponible públicamente en Kaggle. El conjunto de datos contendrá varias características, pero solo utilizaremos la característica abstractText con su clasificación MeSH (A: Anatomía, B: Organismo, C: Enfermedades, etc.). Los datos de muestra se muestran en la imagen a continuación.
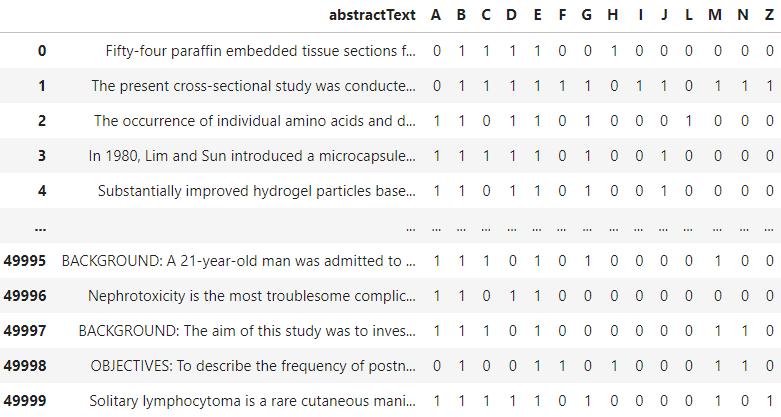
El conjunto de datos anterior muestra que cada artículo se puede clasificar en más de una categoría, lo que corresponde a casos de clasificación multietiqueta. Con este conjunto de datos, podemos construir un clasificador multietiqueta con Scikit-Learn. Preparemos el conjunto de datos antes de entrenar el modelo.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Text Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.fit(X)
En el código anterior, transformamos los datos de texto en una representación TF-IDF para que nuestro modelo de Scikit-Learn pueda aceptar los datos de entrenamiento. También estoy omitiendo los pasos de preprocesamiento de datos, como la eliminación de palabras vacías, para simplificar el tutorial.
Después de la transformación de datos, dividimos el conjunto de datos en conjuntos de entrenamiento y prueba.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
Después de toda la preparación, comenzaríamos a entrenar nuestro clasificador multietiqueta. En Scikit-Learn, usaríamos el objeto MultiOutputClassifier para entrenar el modelo del clasificador multietiqueta. La estrategia detrás de este modelo es entrenar un clasificador por etiqueta. Básicamente, cada etiqueta tiene su propio clasificador.
En este ejemplo, usaríamos Regresión Logística y MultiOutputClassifier las extendería a todas las etiquetas.
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).fit(X_train_tfidf, y_train)
Podemos cambiar el modelo y ajustar los parámetros del modelo que se pasan a MultiOutputClassifier, así que ajústelos según sus necesidades. Después del entrenamiento, usemos el modelo para predecir los datos de prueba.
prediction = clf.predict(X_test_tfidf)
prediction
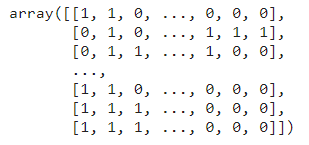
El resultado de la predicción es una matriz de etiquetas para cada categoría de MeSH. Cada fila representa la oración y cada columna representa la etiqueta.
Por último, debemos evaluar nuestro clasificador multietiqueta. Podemos usar la métrica de precisión para evaluar el modelo.
from sklearn.metrics import accuracy_score
print('Puntuación de precisión: ', accuracy_score(y_test, prediction))
Puntuación de precisión: 0.145
El resultado de la puntuación de precisión es 0.145, lo que muestra que el modelo solo pudo predecir la combinación exacta de etiquetas menos del 14.5% del tiempo. Sin embargo, la puntuación de precisión tiene debilidades para la evaluación de la predicción multietiqueta. La puntuación de precisión requeriría que cada oración tenga todas las etiquetas presentes en la posición exacta, de lo contrario se consideraría incorrecta.
Por ejemplo, la predicción de la primera fila solo difiere en una etiqueta entre la predicción y los datos de prueba.
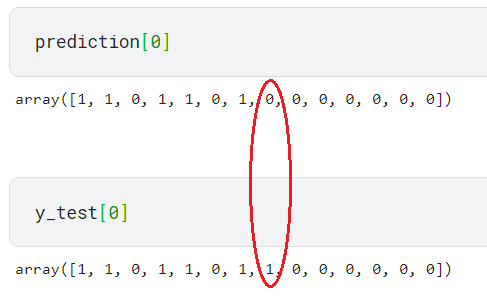
Se consideraría una predicción incorrecta para la puntuación de precisión ya que la combinación de etiquetas es diferente. Por eso nuestro modelo tiene una puntuación de métrica baja.
Para mitigar este problema, debemos evaluar la predicción de las etiquetas en lugar de su combinación. En este caso, podemos confiar en la métrica de pérdida de Hamming. La pérdida de Hamming se calcula tomando una fracción de las predicciones incorrectas con el número total de etiquetas. Como la pérdida de Hamming es una función de pérdida, cuanto menor sea la puntuación, mejor (0 indica que no hay predicciones incorrectas y 1 indica que todas las predicciones son incorrectas).
from sklearn.metrics import hamming_loss
print('Pérdida de Hamming: ', round(hamming_loss(y_test, prediction),2))
Pérdida de Hamming: 0.13
Nuestro modelo de clasificación multietiqueta tiene una pérdida de Hamming de 0.13, lo que significa que nuestro modelo tendría una predicción incorrecta el 13% del tiempo de forma independiente. Esto significa que cada predicción de etiqueta podría ser incorrecta el 13% del tiempo.
Conclusión
La clasificación multietiqueta es una tarea de aprendizaje automático donde la salida puede ser ninguna etiqueta o todas las etiquetas posibles dada la entrada de datos. Es diferente de la clasificación binaria o multiclase, donde la salida de la etiqueta es mutuamente excluyente.
Usando MultiOutputClassifier de Scikit-Learn, podríamos desarrollar un clasificador multietiqueta donde entrenamos un clasificador para cada etiqueta. Para la evaluación del modelo, es mejor usar la métrica de pérdida de Hamming ya que la puntuación de precisión puede no dar una imagen completa correctamente. Cornellius Yudha Wijaya es un gerente asistente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos de Python y datos a través de las redes sociales y los medios de escritura.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Meta presenta AudioCraft una herramienta de IA para convertir texto en audio y música
- La amenaza de la desinformación climática propagada por la tecnología de IA generativa
- Fuga de datos Qué es y por qué causa el fracaso de nuestros sistemas predictivos
- Abacus AI presenta un nuevo modelo de lenguaje grande de contexto largo y abierto (LLM) Conoce a Giraffe
- Ejemplos de Aplicaciones de K-Vecinos Más Cercanos
- ¿Puede (Muy) Simple Matemáticas Informar RLHF Para Modelos de Lenguaje Grandes LLMs? ¡Este artículo de IA dice que sí!
- El Problema de Enrutamiento de Vehículos Soluciones Exactas y Heurísticas