Elegir el camino correcto Modelos de Churn vs. Modelos de Uplift
Choosing the right path Churn Models vs. Uplift Models.
¿Realmente necesitamos modelos de abandono? ¿Quizás el modelado de aumento pueda darnos una respuesta más completa?
Imaginemos que trabajamos en comercio electrónico y el gerente de producto nos pide que construyamos un modelo de abandono.
Pero, ¿qué es lo que realmente nos pide?
¿Qué nos puede dar el modelo de abandono?
Bueno, todo se trata de comprender la probabilidad de que un cliente específico nos abandone. Nuestros próximos pasos están impulsados por una heurística:
- Plotly y Python Creando Mapas de Calor Interactivos para Datos Petrofísicos y Geológicos
- PyLogik para la Desidentificación de Datos de Imágenes Médicas
- Modelado de Señales EEG utilizando Regresión Polinómica en R
Si ofrecemos un descuento a los clientes que probablemente abandonen, entonces se quedarán.
Sin embargo, nuestro objetivo es un poco diferente. Imaginemos que solo podemos hacer dos cosas: dar un tratamiento o no dar un tratamiento, en nuestro caso va a ser un descuento. Hay 4 resultados posibles.

- Regalo del margen. Ofrecimos un descuento, el usuario lo usó y compró un artículo, pero el usuario habría realizado la compra incluso sin el descuento. Es un resultado negativo porque se ha regalado margen.
- Costos del tratamiento. Ofrecimos un descuento, pero los usuarios no lo han usado y no han realizado ninguna compra. Esto también se considera un resultado negativo porque incurrimos en costos por tratamientos como enviar mensajes de texto, especialmente cuando se trata de una gran base de usuarios.
- Éxito. Ofrecimos un descuento, el usuario lo usó y realizó una compra únicamente debido a la oferta. Este es el resultado deseado al que apuntamos.
- Cliente perdido. Ofrecimos un descuento, pero el usuario terminó abandonándonos. Por ejemplo, en el caso de un servicio de suscripción, el usuario recibió una notificación con un descuento, solo para darse cuenta de que había estado pagando la suscripción durante los últimos 6 meses y decidió cancelar. Este es el resultado más negativo que podemos encontrar.
Nuestro verdadero objetivo no es estimar la probabilidad de abandono, sino aplicar el tratamiento más apropiado a cada usuario.
¿Cómo empezamos a alcanzar este objetivo?
Para empezar, es crucial realizar una simple prueba AB. Esto implica proporcionar un descuento a un grupo mientras se mantiene un grupo de control sin ningún descuento.
Después del experimento, tenemos tres enfoques principales.
Enfoque de dos modelos
El primer enfoque implica construir dos modelos separados: uno para el grupo de control (sin ningún descuento) y otro para el grupo de tratamiento (con un descuento). Para construir estos modelos separados, podemos elegir cualquier tipo de modelo de ML.
Al ejecutar a cada cliente a través de ambos modelos, podemos calcular el aumento como la diferencia entre los resultados predichos.
Pros:
- Es fácil de implementar.
Contras:
- No predice directamente el aumento. Estimamos la probabilidad de la acción de los usuarios (compra).
- La configuración de dos modelos introduce la modelización de doble error, ya que ambos modelos tienen sus propios errores, lo que conduce a errores generales más grandes.
Transformación del objetivo
El segundo enfoque gira en torno a la transformación de la variable objetivo en sí misma. Al crear un nuevo objetivo que representa el aumento, podemos calcular el resultado deseado directamente.
Introducimos una nueva variable objetivo utilizando la siguiente fórmula:
Aquí, Y representa la variable objetivo original, y W indica si se aplicó o no el tratamiento objetivo. En otras palabras, Y representa si se dio o no el descuento, y W indica si se realizó o no una compra.
La variable transformada Z toma el valor de 1 en dos casos:
- El usuario pertenece al grupo objetivo (W = 1) y Y = 1 (se le otorgó el descuento al usuario y ha comprado).
- El usuario pertenece al grupo de control (W = 0) y Y = 0 (no se le otorgó el descuento al usuario y el usuario no ha comprado).
Luego solo necesitamos entrenar el modelo (por ejemplo, regresión logística) con un nuevo objetivo.
Para calcular el aumento, podemos utilizar la siguiente fórmula:
Pros:
- Todavía es fácil de implementar.
- Es más robusto y estable que el primer enfoque debido al hecho de que tenemos solo un modelo.
Contras:
- Todavía no predice directamente el aumento. Predecimos la variable transformada.
Modelos basados en árboles
El tercer enfoque se basa en modelos basados en árboles.
El objetivo es identificar las subpoblaciones dentro de un conjunto de datos que son más sensibles al tratamiento, lo que permite intervenciones específicas para obtener el máximo impacto.
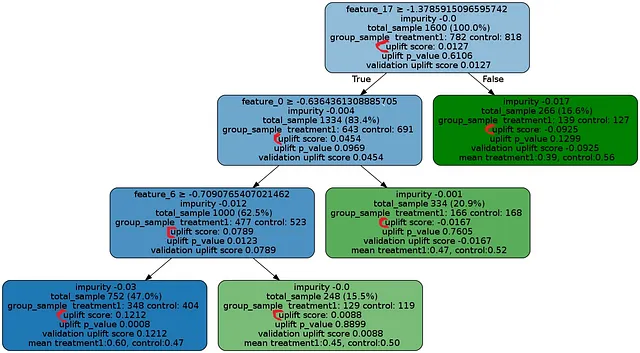
El árbol de decisiones de ejemplo para fines de aumento se muestra en la imagen resaltada anteriormente. El color rojo indica los valores de aumento. Al observar la imagen, podemos concluir que la diferencia general de aumento es de 0.0127 (basada en una métrica aleatoria). Sin embargo, al descender al árbol, observamos ciertas subpoblaciones que exhiben mayores diferencias de aumento.
Estas subpoblaciones se convierten en nuestro objetivo ya que tienen el potencial de ofrecer beneficios máximos.
¿Cómo construir este árbol?
Hay numerosos tutoriales disponibles sobre la construcción de árboles de decisión, pero aquí describiré el enfoque básico.
- Seleccione características e identifique la variable objetivo, que en nuestro caso es el aumento.
- Elige un criterio de división para determinar cómo se dividen los nodos.
- Construya el árbol repitiendo el proceso de división de manera recursiva hasta que se cumpla un criterio de detención.
Vale la pena señalar que hay tres criterios de división comúnmente utilizados para construir árboles de aumento, que se enumeran a continuación en orden de popularidad:
- Divergencia KL
- Chi-cuadrado
- Distancia euclidiana
Pros:
- Uno de los métodos más precisos.
- Tenemos un árbol de decisiones, por lo tanto podemos construir el bosque de árboles y diferentes conjuntos que aumentan la precisión y reducen la varianza.
Contras:
- Es un método de árbol de decisiones, por lo tanto, el algoritmo tiende a sobrestimar las variables categóricas con muchos niveles. Para solucionarlo, podemos utilizar la imputación de la media.
Conclusión
Ahora sabemos que abordar la retención de clientes requiere estrategias que vayan más allá de simplemente estimar la probabilidad de retención. El objetivo final es aplicar el tratamiento más apropiado a cada usuario y ofrecer un impacto comercial en lugar de una probabilidad de retención.
La modelización de aumento, que se puede aplicar a diversos desafíos comerciales más allá de la retención, ofrece una solución potente con un impacto comercial inmediato.
Todavía hay muchas preguntas interesantes sobre la modelización de aumento, como el manejo de múltiples tratamientos, la estimación de diferentes modelos de aumento y la utilización de bandas multinivel para la producción, pero dejaré las respuestas para el próximo post.
¡Gracias por leer y no tener miedo de cometer errores y aprender. ¡Es la única forma de progresar!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Series de tiempo para el cambio climático Pronóstico de demanda origen-destino
- El Desafío de Ver la Imagen Completa de la Inteligencia Artificial
- Conoce AnythingLLM Una Aplicación Full-Stack Que Transforma Tu Contenido en Datos Enriquecidos para Mejorar las Interacciones con Modelos de Lenguaje Amplio (LLMs)
- Teoría de Recursos Donde las Matemáticas se Encuentran con la Industria.
- Funciones de Ventana Un conocimiento imprescindible para ingenieros de datos y científicos de datos.
- Haz que tus gráficos sean excelentes con UTF-8.
- Haz que cada dólar de marketing cuente con la ciencia de datos.





