ChatGPT con Ojos y Oídos BuboGPT es un Enfoque de IA que Permite la Fundamentación Visual en LLMs Multi-Modales
ChatGPT con Ojos y Oídos BuboGPT Enfoque de IA para Fundamentación Visual en LLMs Multi-Modales
I had trouble accessing your link so I’m going to try to continue without it.


Los Modelos de Lenguaje Grandes (LLMs) han surgido como agentes de cambio en el campo del procesamiento del lenguaje natural. Se están convirtiendo en una parte clave de nuestra vida diaria. El ejemplo más famoso de un LLM es ChatGPT, y es seguro asumir que casi todos conocen sobre él en este punto, y la mayoría de nosotros lo usamos a diario.
Los LLMs se caracterizan por su gran tamaño y capacidad para aprender de vastas cantidades de datos de texto. Esto les permite generar texto coherente y relevante en contexto, similar al texto generado por humanos. Estos modelos se construyen sobre arquitecturas de aprendizaje profundo, como GPT (Generative Pre-trained Transformer) y BERT (Bidirectional Encoder Representations from Transformers), que utilizan mecanismos de atención para capturar dependencias a largo plazo en un lenguaje.
- Explorando los marcos de aprendizaje automático para desarrolladores de software
- Amazon presenta resúmenes de reseñas generados por inteligencia artificial
- Solucionando el desafío de promoción de imágenes en múltiples entornos con ArgoCD
Aprovechando el pre-entrenamiento en conjuntos de datos a gran escala y el ajuste fino en tareas específicas, los LLMs han demostrado un rendimiento notable en diversas tareas relacionadas con el lenguaje, incluyendo generación de texto, análisis de sentimientos, traducción automática y respuesta a preguntas. A medida que los LLMs continúan mejorando, tienen un inmenso potencial para revolucionar la comprensión y generación del lenguaje natural, cerrando la brecha entre las máquinas y el procesamiento del lenguaje similar al humano.
Por otro lado, algunas personas pensaron que los LLMs no estaban utilizando todo su potencial ya que estaban limitados solo a la entrada de texto. Han estado trabajando en ampliar el potencial de los LLMs más allá del lenguaje. Algunos estudios han integrado con éxito los LLMs con diversas señales de entrada, como imágenes, videos, voz y audio, para construir chatbots multimodales poderosos.
Aunque todavía queda un largo camino por recorrer, ya que la mayoría de estos modelos carecen de la comprensión de las relaciones entre los objetos visuales y otras modalidades. Si bien los LLMs mejorados visualmente pueden generar descripciones de alta calidad, lo hacen de manera opaca sin relacionarse explícitamente con el contexto visual.
Establecer una correspondencia explícita e informativa entre el texto y otras modalidades en los LLMs multimodales puede mejorar la experiencia del usuario y permitir un nuevo conjunto de aplicaciones para estos modelos. Conozcamos a BuboGPT, que aborda esta limitación.
BuboGPT es el primer intento de incorporar fundamentos visuales en los LLMs conectando objetos visuales con otras modalidades. BuboGPT permite la comprensión y conversación multimodal conjunta para texto, visión y audio mediante el aprendizaje de un espacio de representación compartido que se alinea bien con los LLMs pre-entrenados.
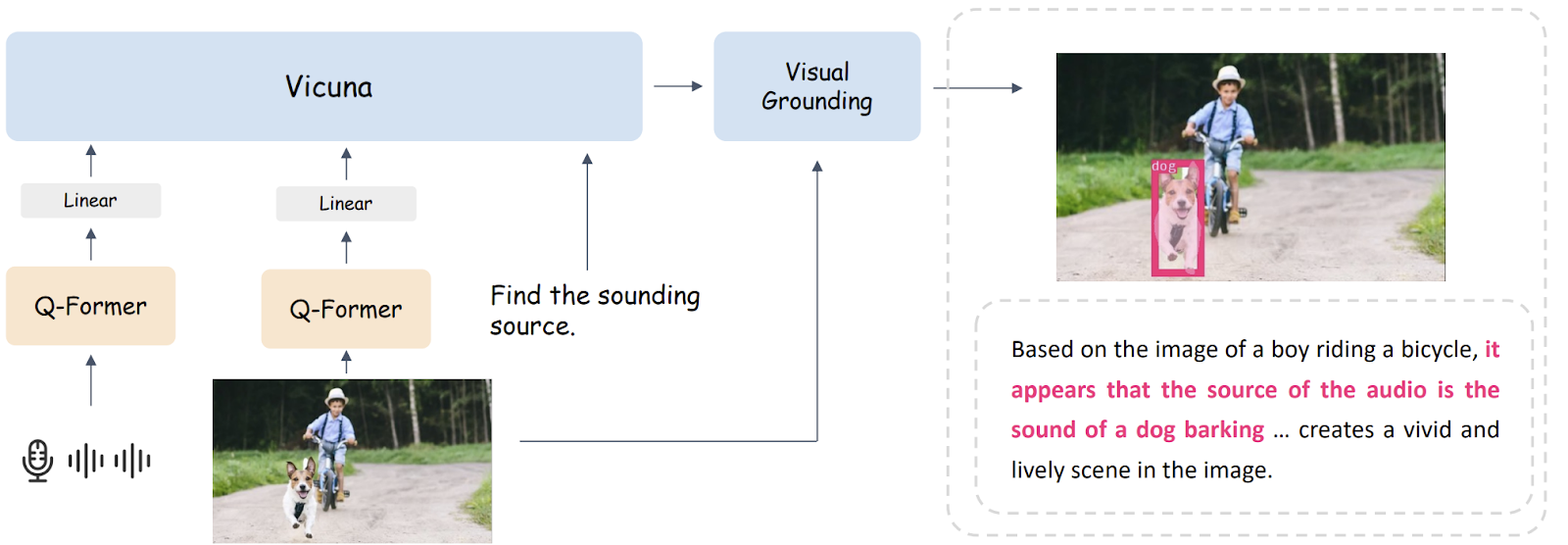
La fundamentación visual no es una tarea fácil de lograr, por lo que juega un papel crucial en el proceso de BuboGPT. Para lograr esto, BuboGPT construye un proceso basado en un mecanismo de autoatención. Este mecanismo establece relaciones detalladas entre los objetos visuales y las modalidades.
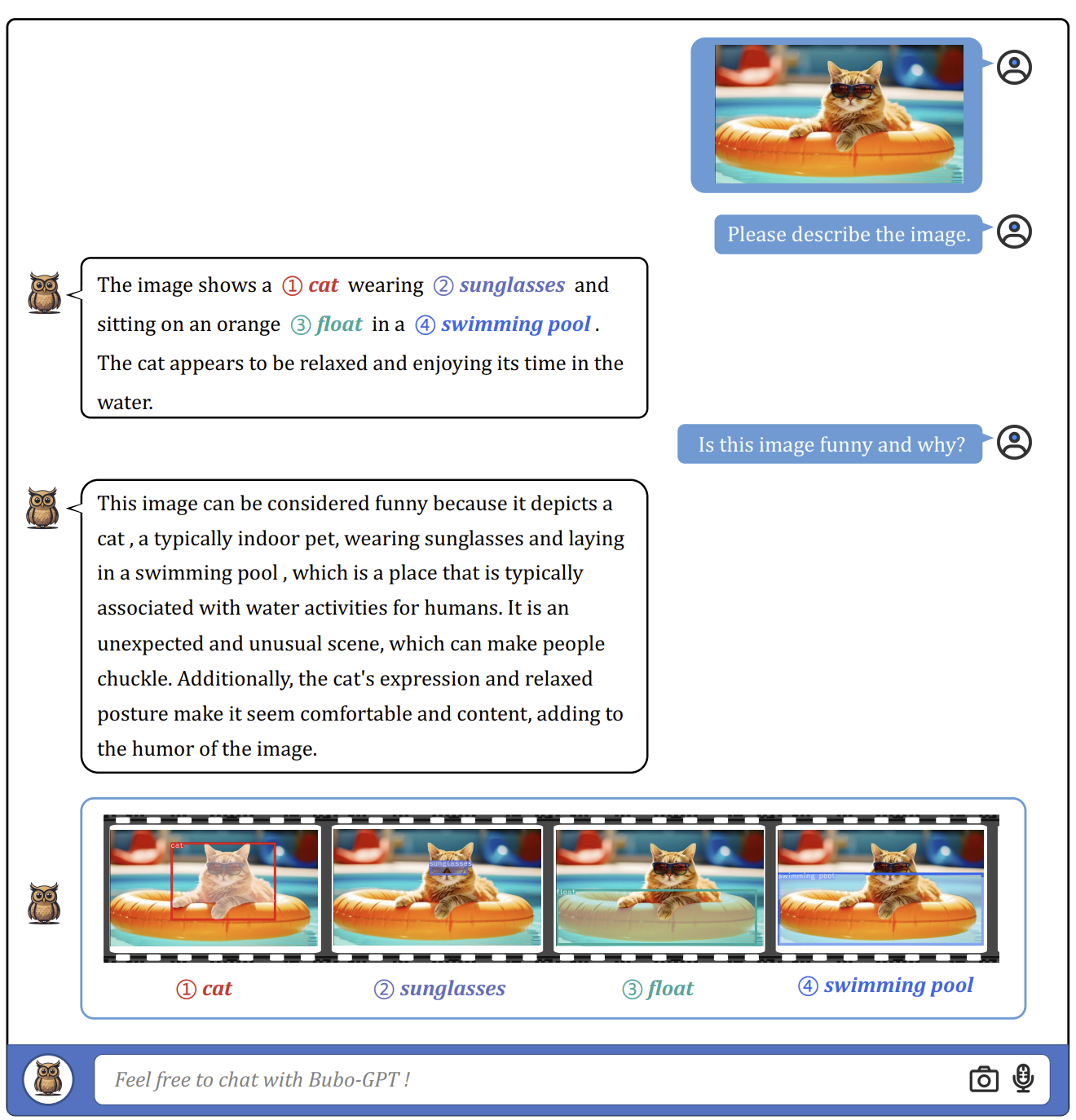
El proceso incluye tres módulos: un módulo de etiquetado, un módulo de fundamentación y un módulo de coincidencia de entidades. El módulo de etiquetado genera etiquetas/texto relevante para la imagen de entrada, el módulo de fundamentación localiza máscaras o cajas semánticas para cada etiqueta, y el módulo de coincidencia de entidades utiliza el razonamiento de los LLMs para recuperar entidades coincidentes de las etiquetas y descripciones de la imagen. Al conectar objetos visuales y otras modalidades a través del lenguaje, BuboGPT mejora la comprensión de las entradas multimodales.
Para habilitar una comprensión multimodal de combinaciones arbitrarias de entradas, BuboGPT utiliza un esquema de entrenamiento de dos etapas similar a Mini-GPT4. En la primera etapa, utiliza ImageBind como codificador de audio, BLIP-2 como codificador de visión, y Vicuna como LLM para aprender un Q-former que alinee características de visión o audio con el lenguaje. En la segunda etapa, realiza una sintonización instruccional multimodal en un conjunto de datos de seguimiento de instrucciones de alta calidad.
La construcción de este conjunto de datos es crucial para que el LLM reconozca las modalidades proporcionadas y si las entradas están bien emparejadas. Por lo tanto, BuboGPT construye un nuevo conjunto de datos de alta calidad con subconjuntos para instrucción de visión, instrucción de audio, localización de sonido con pares imagen-audio positivos, y subtitulado de imagen-audio con pares negativos para razonamiento semántico. Al introducir pares imagen-audio negativos, BuboGPT aprende una mejor alineación multimodal y muestra capacidades de comprensión conjunta más fuertes.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conjunto de clasificadores Clasificador de votación
- Protege tus proyectos de Python Evita la invocación directa de setup.py para una máxima protección del código.
- Revelando el poder del ajuste de sesgo mejorando la precisión predictiva en conjuntos de datos desequilibrados
- Adobe Express mejora la experiencia del usuario con Firefly Generative AI
- Redes convolucionales de grafos Introducción a las GNN
- Los Conjuntos de Estímulos Hacen que los LLMs Sean Más Confiables
- Difusión Estable El AI de la Comunidad






