CatBoost Regresión Explícamelo detalladamente
CatBoost Regresión Explícamelo detalladamente' can be condensed to 'Explícame CatBoost Regresión en detalle'.
Una desglose completa (e ilustrada) de las entrañas de CatBoost
CatBoost, abreviatura de Categorical Boosting, es un poderoso algoritmo de aprendizaje automático que se destaca en el manejo de características categóricas y en la producción de predicciones precisas. Tradicionalmente, lidiar con datos categóricos es bastante complicado, requiriendo codificación one-hot, codificación de etiquetas o alguna otra técnica de preprocesamiento que puede distorsionar la estructura inherente de los datos. Para abordar este problema, CatBoost utiliza su propio sistema de codificación incorporado llamado Codificación Objetivo Ordenada.
Vamos a ver cómo trabaja CatBoost en la práctica construyendo un modelo para predecir cómo alguien podría calificar el libro “Murder, She Texted” en función de su calificación promedio de libros en Goodreads y su género favorito.
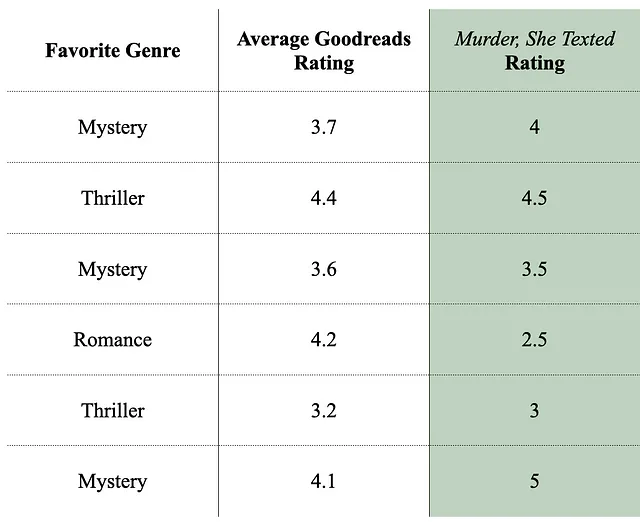
Pedimos a 6 personas que calificaran el libro “Murder, She Texted” y recopilamos otra información relevante sobre ellas.
- ¿La implementación del Momentum de Nesterov en PyTorch está equivocada?
- El problema de percepción pública del Aprendizaje Automático
- La guía definitiva para entrenar BERT desde cero Introducción
Este es nuestro conjunto de entrenamiento actual, que utilizaremos para entrenar (obvio) los datos.
Paso 1: Mezclar el conjunto de datos y Codificar los Datos Categóricos Usando Codificación Objetivo Ordenada
La forma en que preprocesamos los datos categóricos es fundamental para el algoritmo CatBoost. En este caso, solo tenemos una columna categórica: Género Favorito. Esta columna se codifica (es decir, se convierte en un entero discreto) y la forma en que se hace varía según si es un problema de Regresión o Clasificación. Dado que estamos tratando con un problema de Regresión (porque la variable que queremos predecir, Murder, She Texted Rating, es continua), seguimos los siguientes pasos.
1 – Mezclar el conjunto de datos:
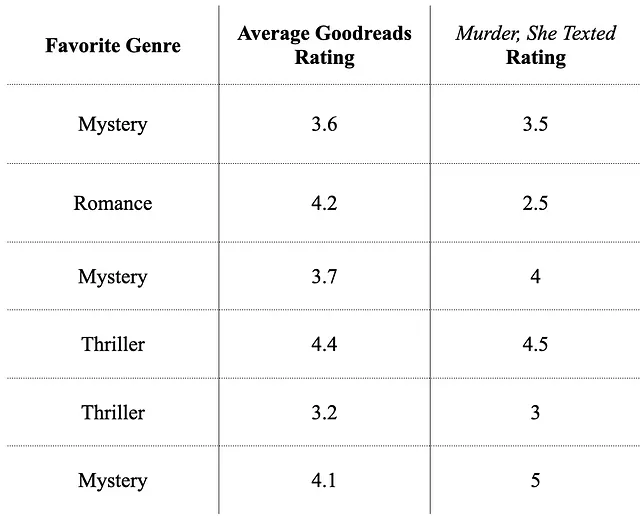
2 – Colocar la variable objetivo continua en intervalos discretos: Dado que tenemos muy pocos datos aquí, crearemos 2 intervalos del mismo tamaño para categorizar la variable objetivo. (Aprende más sobre cómo crear intervalos aquí).
Colocamos los 3 valores más pequeños de Murder, She Texted Rating en el intervalo 0 y el resto en el intervalo 1.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo crear un gráfico de barras de labios con Matplotlib
- Cómo los profesores aprovechan el potencial de ChatGPT en el aula
- Herramientas de Inpainting basadas en IA para Arte
- Investigadores de Microsoft proponen Síntesis Visual Responsable de Vocabulario Abierto (ORES) con el Marco de Intervención de Dos Etapas
- Mejorando la eficiencia 10 decoradores que uso a diario como MLE técnico
- Fundamentos de Python Sintaxis, Tipos de Datos y Estructuras de Control
- Investigadores de A12 presentan Satlas una nueva plataforma de inteligencia artificial para explorar datos geoespaciales globales generados por inteligencia artificial a partir de imágenes satelitales.






