Encontrar agujas en un pajar índices de búsqueda para la similitud de Jaccard
Buscar similitud de Jaccard en índices
De conceptos básicos a índices exactos y aproximados

Las bases de datos vectoriales están en las noticias por ser la memoria externa de los modelos de lenguaje grandes (LLMs, por sus siglas en inglés). Las bases de datos vectoriales de hoy en día son sistemas nuevos construidos sobre investigaciones de hace una década llamadas índices de vecinos más cercanos aproximados (ANN, por sus siglas en inglés). Estos algoritmos de indexación toman muchos vectores de alta dimensión (por ejemplo, float32[]) y construyen una estructura de datos que permite encontrar los vecinos aproximados de un vector de consulta en el espacio de alta dimensión. Es como si Google Maps encontrara las casas de tus vecinos dadas la latitud y longitud de tu casa, excepto que los índices ANN operan en un espacio de dimensión mucho más alta.
Esta línea de investigación tiene una historia que se remonta décadas atrás. A finales de los años 90, los investigadores de aprendizaje automático creaban manualmente características numéricas para datos multimedia como imágenes y audio. La búsqueda de similitud basada en estos vectores de características se convirtió en un problema natural. Durante un tiempo, los investigadores se centraron en esta área. Esta burbuja académica estalló cuando un artículo seminal, ¿Cuándo es “Vecino más Cercano” Significativo?, básicamente les dijo a todos que dejaran de perder el tiempo porque el vecino más cercano en el espacio de alta dimensión de características creadas manualmente no es en su mayoría significativo, un tema interesante para otro artículo. Aún hoy en día, sigo viendo artículos de investigación y pruebas de rendimiento de bases de datos vectoriales que publican números de rendimiento en el conjunto de datos SIFT-128, que consiste exactamente en vectores de características creadas manualmente con similitud sin sentido.
A pesar del ruido en torno a las características creadas manualmente, ha habido una línea de investigación fructífera centrada en un tipo de datos de alta dimensión con similitud significativa: conjuntos y Jaccard.
En esta publicación, cubriré los índices de búsqueda para la similitud de Jaccard en conjuntos. Comenzaré con los conceptos básicos y luego pasaré a los índices exactos y aproximados.
- Cómo crear atractivas clasificaciones de países utilizando Python y Matplotlib
- La Associated Press y otras organizaciones de noticias desarrollan estándares para la inteligencia artificial en la sala de redacción
- Función de Llamada Integra tu Chatbot GPT con cualquier cosa
Conjuntos y Jaccard
Un conjunto es simplemente una colección de elementos distintos. Las canciones que te gustaron en Spotify son un conjunto; los tweets que retuiteaste la semana pasada son un conjunto; y los tokens distintos extraídos de esta publicación de blog también forman un conjunto. El conjunto es una forma natural de representar puntos de datos en escenarios de aplicaciones como recomendación de música, redes sociales y detección de plagio.
Supongamos que en Spotify, sigo a estos artistas:
[the weekend, taylor swift, wasia project]
y mi hija sigue a estos artistas:
[the weekend, miley cyrus, sza]
Una forma razonable de medir la similitud de nuestros gustos musicales es ver cuántos artistas seguimos ambos, es decir, el tamaño de la intersección. En este caso, ambos seguimos a the weekend, por lo que el tamaño de la intersección es 1.
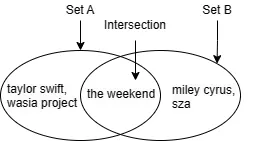
Sin embargo, podrías imaginar otro par de usuarios que siguen a 100 artistas cada uno, y el tamaño de la intersección también es 1, pero la similitud en sus gustos debería ser mucho menor que la similitud entre los gustos de mi hija y los míos. Para hacer que la medida sea comparable entre diferentes pares de usuarios, normalizamos el tamaño de la intersección con el tamaño de la unión. De esta manera, la similitud entre los seguidores de mi hija y los míos es 1 / 5 = 0.2, y la similitud entre los seguidores del otro par de usuarios es 1 / 199 ~= 0.005. Esto se llama similitud de Jaccard.
Para un conjunto A y un conjunto B, la fórmula para la similitud de Jaccard es:
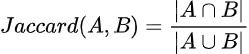
¿Por qué se define un tipo de datos de alta dimensionalidad para un conjunto? Un conjunto se puede codificar como un vector “one-hot”, cuyas dimensiones se mapean uno a uno con todos los posibles elementos (por ejemplo, todos los artistas en Spotify). Una dimensión en este vector tiene un valor de 1 si el conjunto contiene el elemento correspondiente a esta dimensión, y 0 en caso contrario. Por lo tanto, el conjunto vectorizado de los artistas que sigo se ve así:
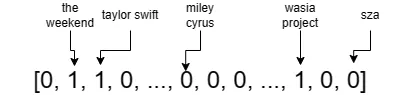
donde las segundas, terceras y terceras desde el final dimensiones son the weekend, taylor swift y wasia project. Hay más de 10 millones de artistas en Spotify, por lo que un vector como este es extremadamente de alta dimensionalidad y muy disperso, la mayoría de las dimensiones son 0s.
Índices inversos para búsqueda Jaccard
La gente quiere encontrar cosas rápidamente, por lo que los científicos de la computación inventaron estructuras de datos llamadas índices para hacer que el rendimiento de búsqueda sea satisfactorio para las aplicaciones de software. Específicamente, un índice de búsqueda Jaccard se construye sobre una colección de conjuntos, dados un conjunto de consulta, devuelve k conjuntos que tienen el mayor Jaccard con el conjunto de consulta.
El índice de búsqueda Jaccard se basa en una estructura de datos llamada índice invertido. Un índice invertido tiene una interfaz extremadamente simple: se introduce un elemento del conjunto, digamos the weekend, devuelve una lista de IDs de conjuntos que contienen el elemento de entrada, por ejemplo, [ 32, 231, 432, 1322, ...]. El índice invertido es esencialmente una tabla de búsqueda cuyas claves son todos los posibles elementos del conjunto, y los valores son listas de IDs de conjuntos. En este ejemplo, cada lista en el índice invertido representa los IDs de los seguidores de un artista.
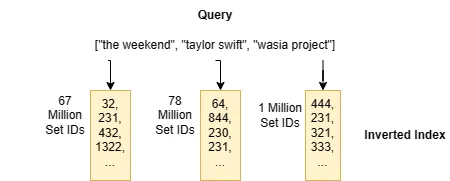

Puedes ver la razón por la que esto se llama “índice invertido”: te permite ir desde un elemento del conjunto para encontrar conjuntos que contienen el elemento.
Algoritmo de búsqueda exacta
El índice invertido es una estructura de datos increíblemente poderosa para acelerar la búsqueda. Usando el índice invertido, en lugar de recorrer todos los conjuntos y comparar cada uno con el conjunto de consulta (muy costoso si tienes millones de conjuntos), solo necesitas procesar los IDs de los conjuntos que comparten al menos un elemento con el conjunto de consulta. Puedes obtener los IDs de los conjuntos directamente de las listas del índice invertido.
Esta idea se implementa mediante el siguiente algoritmo de búsqueda:
def search_top_k_merge_list(index, sets, q, k): """Búsqueda Jaccard top-k utilizando índice invertido. Args: index: un índice invertido, la clave es un elemento del conjunto sets: una tabla de búsqueda para conjuntos, la clave es el ID del conjunto q: un conjunto de consulta k: parámetro de búsqueda k Returns: lista: como máximo k IDs de conjuntos. """ # Inicializar una tabla de búsqueda vacía para candidatos. candidates = defaultdict(0) # Iterar sobre los elementos del conjunto en q. for x in q: ids = index[x] # Obtener una lista de IDs de conjuntos del índice. for id in ids: candidates[id] += 1 # Incrementar el contador para el tamaño de intersección. # Ahora candidates[id] almacena el tamaño de intersección del conjunto con el ID id. # Un procedimiento simple para calcular Jaccard utilizando el tamaño de intersección y # tamaños de conjuntos, basado en el principio de inclusión-exclusión. jaccard = lambda id: candidates[id] / (len(q) + len(sets(id) - candidates[id])) # Encuentra los candidatos principales k ordenados por Jaccard. return sorted(list(candidates.keys()), key=jaccard, reverse=True)[:k]En inglés sencillo, el algoritmo recorre cada lista de índices invertidos que coinciden con los elementos del conjunto de consultas y utiliza una tabla de candidatos para realizar un seguimiento del número de veces que aparece cada ID de conjunto. Si un ID de conjunto aparece n veces, el conjunto indexado tiene n elementos superpuestos con el conjunto de consultas. Al final, el algoritmo utiliza toda la información en la tabla de candidatos para calcular las similitudes de Jaccard y luego devuelve los IDs de los conjuntos más similares a los k mejores.
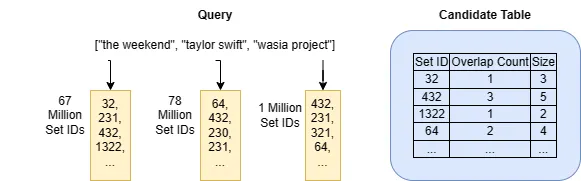
El algoritmo search_top_k_merge_list puede ser rápido cuando: (1) el número de elementos en el conjunto de consultas es pequeño y (2) el número de IDs en las listas de índices invertidos para los elementos de la consulta es pequeño. En el escenario de Spotify, esto podría ser cierto si la mayoría de las personas siguen a unos pocos artistas (probablemente cierto) y todos los artistas tienen más o menos el mismo número de seguidores (no es cierto). Todos sabemos que es un hecho que unos pocos artistas principales son seguidos por la mayoría de las personas y la mayoría de los artistas tienen pocos seguidores. Después de todo, la industria de la música sigue la Distribución de Pareto.
Taylor Swift tiene 78 millones de seguidores en Spotify y The Weekend tiene 67 millones. Tenerlos en mi lista de seguidos significa que el algoritmo search_top_k_merge_list tendrá que recorrer al menos 145 millones de IDs de conjuntos y la tabla de candidatos candidates crecerá hasta este tamaño astronómico. A pesar de que las computadoras de hoy en día son rápidas y potentes, en mi máquina Intel i7, crear una tabla de este tamaño aún lleva al menos 30 segundos (Python) y asigna dinámicamente 2.5 GB de memoria.
La mayoría de las personas siguen a algunos de estos artistas superestrella. Entonces, si usas este algoritmo en tu aplicación de búsqueda, seguramente obtendrás una factura de alojamiento en la nube gigantesca por el uso de recursos grandes y una experiencia de usuario terrible debido a la alta latencia de búsqueda.
Optimización de ramificación y acotación
Intuitivamente, el algoritmo anterior search_top_k_merge_list procesa todos los candidatos potenciales de manera exhaustiva porque solo utiliza el índice invertido para calcular la intersección. Este algoritmo tiene un rendimiento deficiente debido a los artistas superestrella con millones de seguidores.
Otro enfoque es ser más selectivo acerca de los candidatos potenciales. Imagina que estás entrevistando candidatos para un trabajo y eres el gerente de contratación. No puedes permitirte entrevistar a todos los candidatos potenciales que te envían CV, por lo que clasificas a los candidatos en grupos según tus criterios de trabajo y comienzas a entrevistar a los candidatos que cumplen con los criterios que más te importan. A medida que los entrevistas uno por uno, evalúas si cada uno realmente cumple con todos o la mayoría de tus criterios y dejas de entrevistar cuando encuentras a alguien.
Este enfoque también funciona cuando se trata de encontrar conjuntos similares de artistas seguidos. La idea es que quieres comenzar desde el artista con el menor número de seguidores en tu conjunto de consultas. ¿Por qué? Simplemente porque esos artistas te dan menos conjuntos de candidatos con los que trabajar, para que puedas procesar menos listas de artistas del índice invertido y encontrar tus mejores candidatos k más rápidamente. En mi lista de seguidos de Spotify, wasian project solo tiene 1 millón de seguidores, mucho menos que taylor swift. Ese número mucho menor de personas que siguen a wasian project tiene el mismo potencial para estar entre los mejores candidatos k que ese número mucho mayor de personas que siguen a taylor swift.
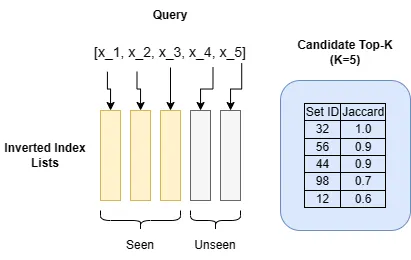
La idea clave aquí es que no queremos procesar todas las listas de candidatos potenciales, sino detenernos cuando hayamos procesado lo suficiente. La parte complicada es saber cuándo detenerse. A continuación se muestra una versión modificada del algoritmo anterior que implementa la idea.
import heapqdef search_top_k_probe_set(index, sets, q, k): # Inicializa una cola de prioridad para almacenar los candidatos actuales mejores k. heap = [] # Inicializa un conjunto para realizar un seguimiento de los candidatos sondeados. seen_ids = set() # Itera sobre los elementos en q de menor a mayor frecuencia según las longitudes de sus listas en el índice invertido. for i, x in enumerate(sorted(q, key=lambda x: len(index[x]))): ids = index[x] # Obtiene una lista de IDs de conjunto del índice. for id in ids: if id in seen_ids: continue # Omite el candidato visto. s = sets[id] intersect_size = len(q.intersection(s)) jaccard = intersect_size / (len(q) + len(s) - intersect_size) # Agrega el candidato a la cola de prioridad. if len(heap) < k: heapq.heappush(heap, (jaccard, id)) else: # Solo se agregarán candidatos con un Jaccard mayor que el k-ésimo # candidato actual en esta operación. heapq.heappushpop(heap, (jaccard, id)) seen_ids.add(id) # Si algún nuevo candidato de las listas restantes no puede tener un Jaccard mayor que cualquiera de los k mejores candidatos actuales, no necesitamos hacer más trabajo. if (len(q) - i - 1) / len(q) (<= min(heap)[0]: break # Devuelve los mejores k candidatos. return [id for _, id in heapq.nlargest(k, heap)]El algoritmo search_top_k_probe_set calcula la similitud de Jaccard para cada nuevo candidato que encuentra. Realiza un seguimiento de los k mejores candidatos en todo momento y se detiene cuando el límite superior de Jaccard de cualquier nuevo candidato no es mayor que el Jaccard mínimo de los k mejores candidatos actuales.
¿Cómo se calcula el límite superior de Jaccard? Después de procesar n listas de candidatos, para cualquier candidato no visto, su intersección máxima con el conjunto de consulta es a lo sumo igual al número de listas no procesadas restantes: |Q|-n. Le estamos dando el beneficio de la duda al decir que dicho candidato puede aparecer en cada una de las |Q|-n listas restantes. Ahora podemos usar matemáticas simples para derivar el límite superior de Jaccard de dicho candidato X.
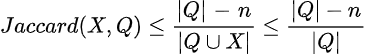
Esta técnica ingeniosa se llama Filtro de Prefijo en la literatura de investigación de búsqueda de similitud de conjuntos. Escribí un artículo al respecto que profundiza mucho más en los detalles y en las optimizaciones algorítmicas adicionales. También creé una biblioteca de Python llamada SetSimilaritySearch que implementa una versión mucho más optimizada del algoritmo search_top_k_probe_set que también admite medidas de similitud de coseno y contención.
Índice Aproximado para la Búsqueda de Jaccard
En la última sección, expliqué dos algoritmos de búsqueda que funcionan en un índice invertido. Estos algoritmos son exactos, lo que significa que los k mejores candidatos que devuelven son los verdaderos k mejores candidatos. ¿Suena trivial? Bueno, esta es una pregunta que debemos hacernos siempre que diseñemos algoritmos de búsqueda en datos a gran escala, porque en muchos escenarios no es necesario obtener los verdaderos k mejores candidatos.
Piensa de nuevo en el ejemplo de Spotify: ¿realmente te importa si el resultado de una búsqueda puede perder a algunas personas con gustos similares a los tuyos? La mayoría de las personas entienden que en aplicaciones cotidianas (Google, Spotify, Twitter, etc.), la búsqueda nunca es exhaustiva o exacta. Estas aplicaciones no son lo suficientemente críticas como para justificar una búsqueda exacta. Por eso, los algoritmos de búsqueda más utilizados son aproximados.
Hay principalmente dos beneficios de utilizar algoritmos de búsqueda aproximados:
- Más rápido. Puedes tomar atajos si ya no necesitas resultados exactos.
- Consumo de recursos predecible. Este es menos obvio, pero para varios algoritmos aproximados, su uso de recursos (por ejemplo, memoria) se puede configurar de antemano independientemente de la distribución de datos.
En esta publicación, escribo sobre el índice aproximado más utilizado para Jaccard: Minwise Locality Sensitive Hashing (MinHash LSH).
¿Qué es LSH?
Los índices de Hashing Sensible a la Localidad son verdaderas maravillas en la ciencia de la computación. Son magia algorítmica impulsada por la teoría de números. En la literatura de aprendizaje automático, son modelos de k-NN, pero a diferencia de los modelos típicos de aprendizaje automático, los índices LSH no dependen de los datos, por lo que su precisión condicionada a la similitud se puede determinar de antemano antes de ingresar nuevos puntos de datos o cambiar la distribución de datos. Por lo tanto, son más similares a los índices invertidos que a un modelo.
Un índice LSH es esencialmente un conjunto de tablas hash, cada una con una función de hash diferente. Al igual que una tabla hash típica, la función de hash de un índice LSH toma un punto de datos (por ejemplo, un conjunto, un vector de características o un vector de incrustación) como entrada y produce una clave de hash binaria. Excepto por esto, no podrían ser más diferentes.
Una función de hash típica produce claves que están pseudoaleatoriamente y uniformemente distribuidas en todo el espacio de claves para cualquier dato de entrada. Por ejemplo, MurmurHash es una función de hash bien conocida que produce resultados casi uniformemente y de forma aleatoria en un espacio de claves de 32 bits. Esto significa que para cualquier par de entradas, como abcdefg y abcefg, siempre y cuando sean diferentes, sus claves de MurmurHash no deberían estar correlacionadas y deberían tener la misma probabilidad de ser cualquiera de las claves en todo el espacio de claves de 32 bits. Esta es una propiedad deseada de una función de hash, porque se desea una distribución uniforme de las claves en los cubos de hash para evitar el encadenamiento o el cambio constante de tamaño de la tabla hash.
La función de hash de un LSH hace algo opuesto: para un par de entradas similares, con similitud definida a través de alguna medida de espacio métrico, sus claves de hash deberían tener más probabilidades de ser iguales que otro par de claves de hash de entradas no similares.
¿Qué significa esto? Significa que una función de hash LSH tiene una mayor probabilidad de colisión de claves de hash para puntos de datos que son más similares. En efecto, estamos utilizando esta mayor probabilidad de colisión para la recuperación basada en la similitud.
LSH MinHash
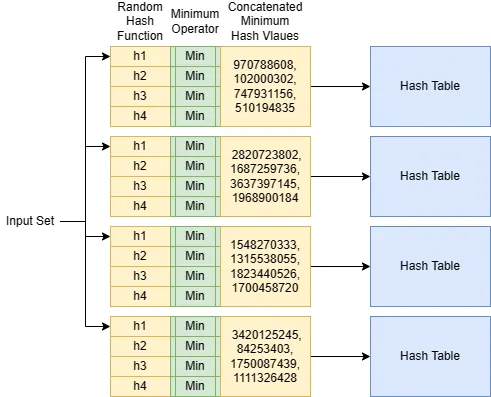
Para cada métrica de similitud/distancia, hay una función de hash LSH. Para Jaccard, la función se llama Función de Hash Minwise o función MinHash. Dada un conjunto de entrada, una función MinHash consume todos los elementos con una función de hash aleatoria y realiza un seguimiento del valor de hash mínimo observado. Puedes construir un índice LSH utilizando una única función MinHash. Mira el diagrama a continuación.

La teoría matemática detrás de la función MinHash establece que la probabilidad de que dos conjuntos tengan el mismo valor de hash mínimo (es decir, colisión de claves de hash) es la misma que su coeficiente de Jaccard.
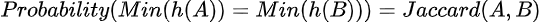
Es un resultado mágico, pero la prueba es bastante simple.
Un índice LSH MinHash con una sola función MinHash no te da una precisión satisfactoria porque la probabilidad de colisión es linealmente proporcional al coeficiente de Jaccard. Mira el siguiente gráfico para entender por qué.
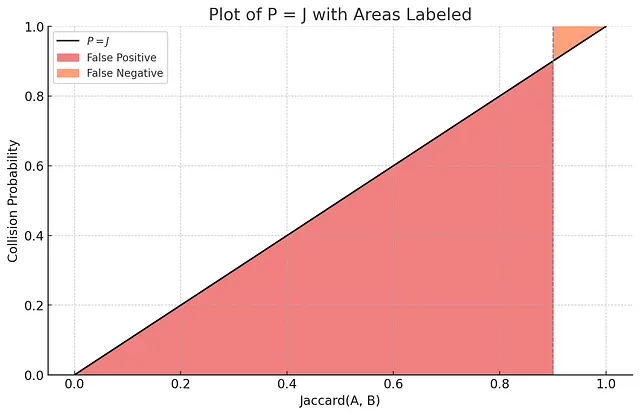
Imagina que trazamos un umbral en Jaccard = 0.9: los resultados con un Jaccard mayor que 0.9 con el conjunto de consulta son relevantes, mientras que los resultados con un Jaccard menor que 0.9 son irrelevantes. En el contexto de la búsqueda, la noción de “falso positivo” significa que se devuelven resultados irrelevantes, mientras que la noción de “falso negativo” significa que no se devuelven resultados relevantes. Basándonos en la gráfica anterior y observando el área correspondiente a los falsos positivos: si el índice solo utiliza una única función MinHash, va a producir falsos positivos con una probabilidad muy alta.
Mejorando la precisión de MinHash LSH
Por eso necesitamos otro truco de LSH: un proceso llamado boosting. Podemos potenciar el índice para que esté mucho más ajustado al umbral de relevancia especificado.
En lugar de uno solo, utilizamos m funciones MinHash generadas mediante un proceso llamado Universal Hashing, que básicamente son m permutaciones aleatorias de la misma función hash de un entero de 32 bits o 64 bits. Para cada conjunto indexado, generamos m valores mínimos de hash utilizando el hashing universal.
Imagina que enumeras los m valores mínimos de hash para un conjunto indexado. Agrupamos cada r número de valores de hash en una banda de valores de hash, y creamos b bandas de este tipo. Esto requiere que m = b * r.

La probabilidad de que dos conjuntos tengan una “colisión de bandas” —todos los valores de hash en una banda colisionan entre dos conjuntos, o colisiones de hash contiguas r— es Jaccard(A, B)^r. Eso es mucho más pequeño que un solo valor de hash. Sin embargo, la probabilidad de tener al menos una “colisión de bandas” entre dos conjuntos es 1 — (1-Jaccard(A, B)^r)^b.
¿Por qué nos importa 1 — (1-Jaccard(A, B)^r)^b? Porque esta función tiene una forma especial:
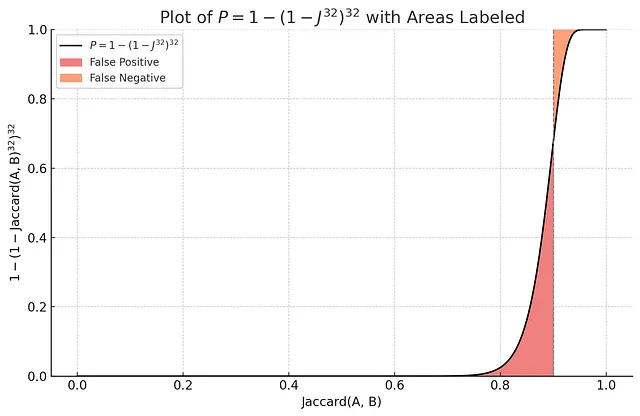
En la gráfica anterior, puedes ver que al usar m funciones MinHash, la probabilidad de “al menos una colisión de bandas” es una función en forma de S con un aumento pronunciado alrededor de Jaccard = 0.9. Suponiendo que el umbral de relevancia es 0.9, la probabilidad de falsos positivos de este índice es mucho menor que el índice que utiliza solo una función hash aleatoria.
Debido a esto, un índice LSH siempre utiliza b bandas de r funciones MinHash para aumentar la precisión. Cada banda es una tabla hash que almacena punteros a conjuntos indexados. Durante la búsqueda, se devuelve cualquier conjunto indexado que colisione con el conjunto de consulta en cualquier banda.
Para construir un índice MinHash LSH, podemos especificar de antemano un umbral de relevancia y probabilidades aceptables de falsos positivos y negativos condicionados a la similitud de Jaccard, y calcular el m, b y r óptimos antes de indexar cualquier punto de datos. Esta es una gran ventaja de usar LSH en comparación con otros índices aproximados.
Puedes encontrar mi implementación de MinHash LSH en el paquete de Python datasketch. También tiene otros algoritmos relacionados con MinHash, como LSH Forest y Weighted MinHash.
Pensamientos Finales
He cubierto muchos temas en esta publicación, pero apenas he rozado la superficie de los índices de búsqueda para la similitud de Jaccard. Si estás interesado en leer más sobre estos temas, tengo una lista de lecturas adicionales para ti:
- Mining of Massive Datasets de Jure Leskovec, Anand Rajaraman y Jeff Ullman. El tercer capítulo profundiza en los detalles de MinHash y LSH. Creo que es un gran capítulo para comprender la intuición de MinHash. Ten en cuenta que la aplicación descrita en el capítulo se centra en la coincidencia de texto basada en n-gramas.
- JOSIE: Búsqueda de similitud de conjuntos de superposición para encontrar tablas unibles en Data Lakes. La sección preliminar de este artículo explica la intuición detrás de los algoritmos
search_top_k_merge_listysearch_top_k_probe_set. La sección principal explica cómo tener en cuenta el costo cuando los conjuntos de entrada son grandes, como una columna de tabla. - Las bibliotecas Datasketch y SetSimilaritySearch implementan respectivamente los índices de búsqueda de similitud de Jaccard aproximada y exacta de última generación. La lista de problemas del proyecto datasketch es una mina de oro de escenarios de aplicación y consideraciones prácticas al aplicar MinHash LSH.
¿Y los embeddings?
En los últimos años, debido a los avances en el aprendizaje de representaciones utilizando redes neuronales profundas como Transformers, la similitud entre vectores de embedding aprendidos es significativa cuando los datos de entrada forman parte del mismo dominio en el que se entrenó el modelo de embedding. Las principales diferencias entre ese escenario y el escenario de búsqueda descrito en esta publicación son:
- Los vectores de embedding son vectores densos con típicamente de 60 a 700 dimensiones. Cada dimensión es distinta de cero. En contraste, los conjuntos, cuando se representan como vectores one-hot, son dispersos: de 10k a millones de dimensiones, pero la mayoría de las dimensiones son cero.
- La similitud del coseno (o el producto punto en vectores normalizados) se utiliza típicamente para vectores de embedding. Para conjuntos, utilizamos la similitud de Jaccard.
- Es difícil especificar un umbral de relevancia en la similitud entre vectores de embedding, porque los vectores son representaciones de caja negra aprendidas de los datos originales, como imágenes o texto. Por otro lado, el umbral de similitud de Jaccard para conjuntos es mucho más fácil de especificar porque los conjuntos son los datos originales.
Debido a las diferencias mencionadas anteriormente, no es sencillo comparar embeddings y conjuntos porque son tipos de datos distintivamente diferentes, aunque se puedan clasificar ambos como de alta dimensionalidad. Son adecuados para diferentes escenarios de aplicación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Herramienta LLM encuentra y remedia vulnerabilidades de software
- 10 Mejores Herramientas Generadoras de Imágenes de IA para Usar en 2023
- William Wu, Fundador y CEO de Artisse – Serie de Entrevistas
- Más allá de Photoshop Cómo Inst-Inpaint está revolucionando la eliminación de objetos con modelos de difusión
- 11 Generadores de Video de IA para Usar en 2023 Transformando Texto en Video
- Investigadores de Ciencias de la Computación crean robots modulares y flexibles
- Generación de Texto a Video Guía paso a paso





