Enchufes de difusión en el dispositivo para la generación condicionada de texto a imagen
'Broadcast plugs on the device for conditioned text-to-image generation'
Publicado por Yang Zhao y Tingbo Hou, Ingenieros de Software, Core ML
En los últimos años, los modelos de difusión han mostrado un gran éxito en la generación de texto a imagen, logrando una alta calidad de imagen, un rendimiento de inferencia mejorado y expandiendo nuestra inspiración creativa. Sin embargo, sigue siendo un desafío controlar eficientemente la generación, especialmente con condiciones que son difíciles de describir con texto.
Hoy anunciamos los complementos de difusión de MediaPipe, que permiten ejecutar la generación de texto a imagen controlable en el dispositivo. Ampliando nuestro trabajo previo en inferencia de GPU para modelos generativos grandes en el dispositivo, presentamos nuevas soluciones de bajo costo para la generación de texto a imagen controlable que se pueden integrar en modelos de difusión existentes y sus variantes de adaptación de rango bajo (LoRA).
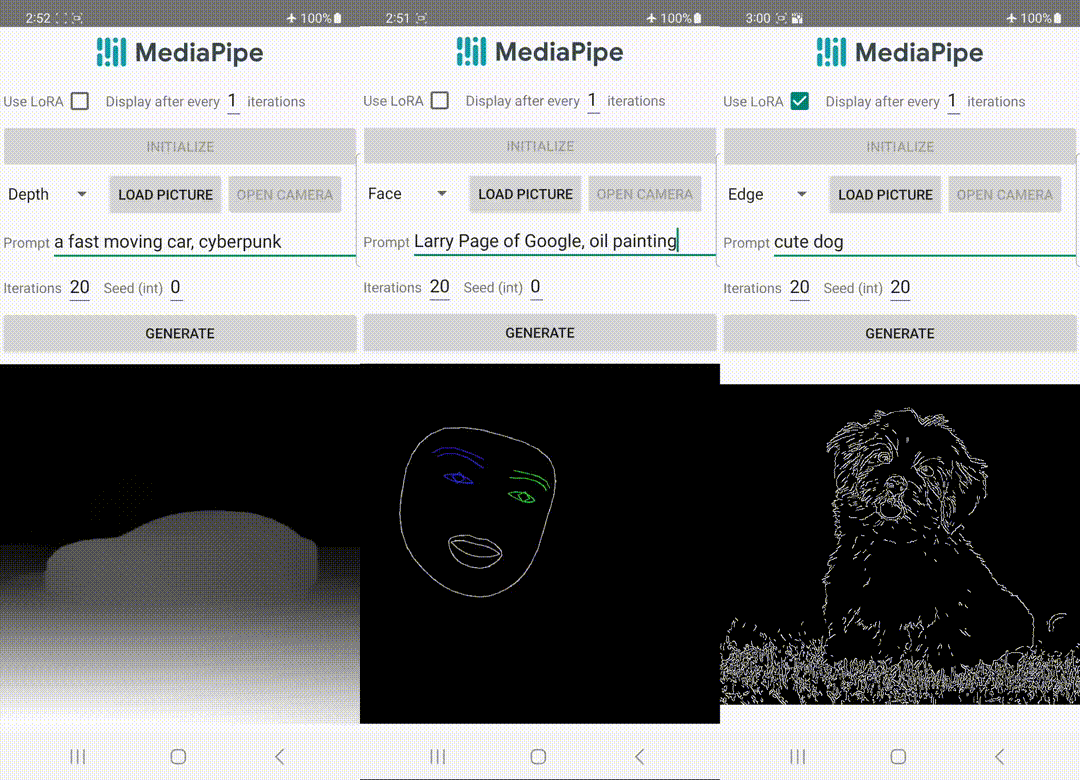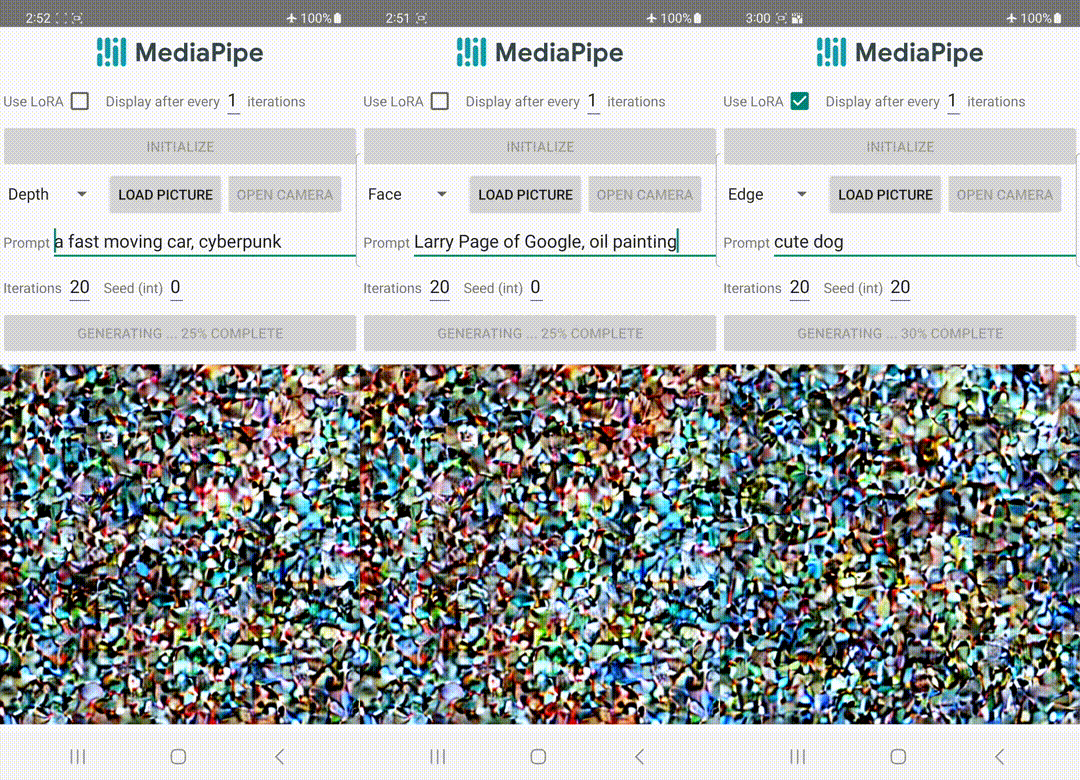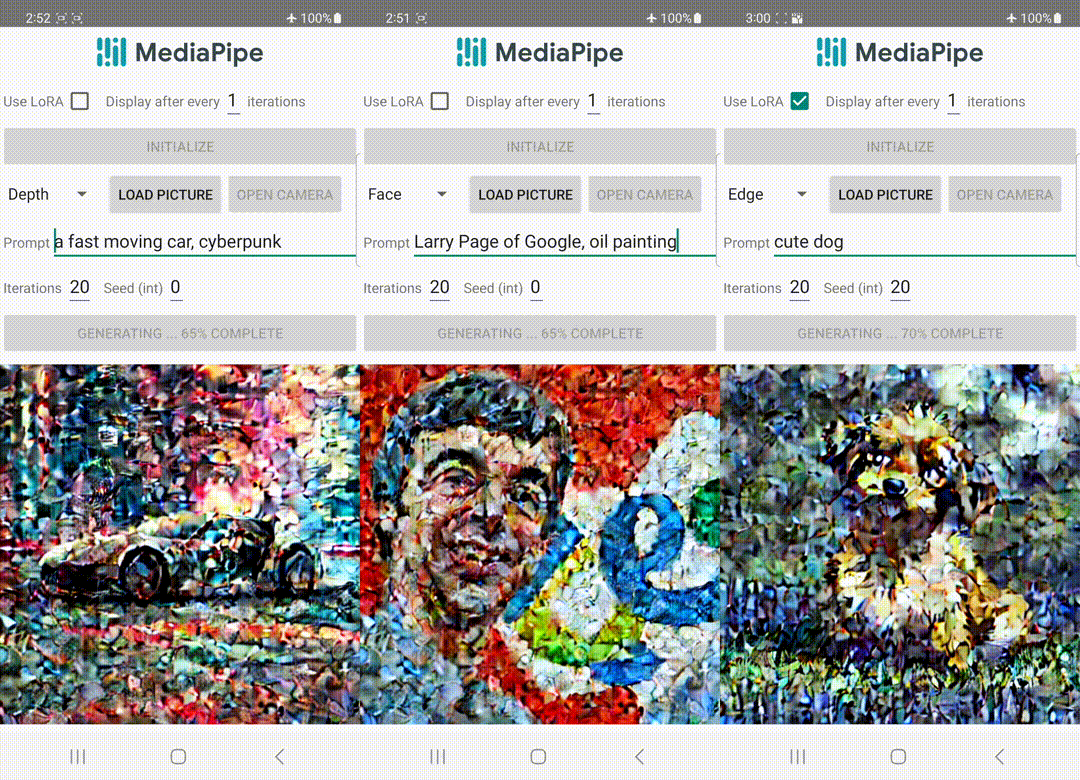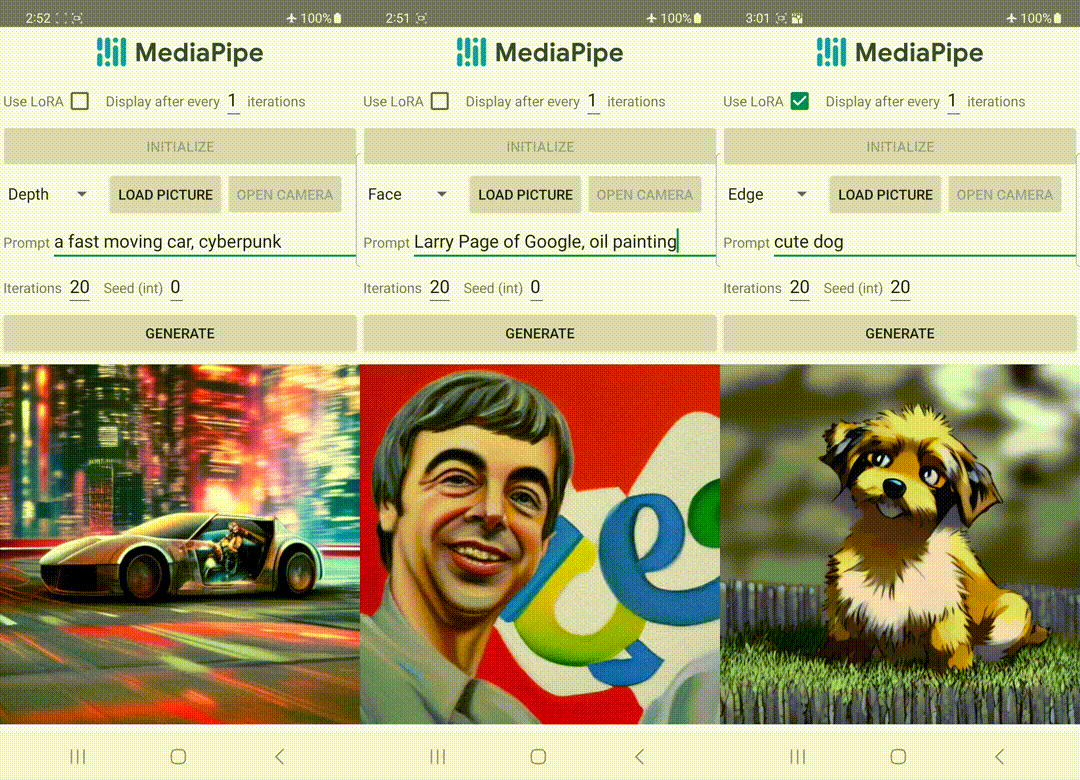 |
| Generación de texto a imagen con complementos de control ejecutándose en el dispositivo. |
Antecedentes
Con los modelos de difusión, la generación de imágenes se modela como un proceso iterativo de eliminación de ruido. Partiendo de una imagen de ruido, en cada paso, el modelo de difusión elimina gradualmente el ruido de la imagen para revelar una imagen del concepto objetivo. La investigación muestra que aprovechar la comprensión del lenguaje a través de indicaciones de texto puede mejorar en gran medida la generación de imágenes. Para la generación de texto a imagen, la incrustación de texto se conecta al modelo a través de capas de atención cruzada. Sin embargo, alguna información es difícil de describir mediante indicaciones de texto, por ejemplo, la posición y la pose de un objeto. Para abordar este problema, los investigadores añaden modelos adicionales a la difusión para inyectar información de control desde una imagen de condición.
- Google DeepMind está trabajando en un algoritmo para superar a ChatGPT.
- Ajusta de forma interactiva Falcon-40B y otros LLMs en los cuadernos de Amazon SageMaker Studio utilizando QLoRA.
- Difusión estable Intuición básica detrás de la IA generativa
Los enfoques comunes para la generación controlada de texto a imagen incluyen Plug-and-Play, ControlNet y T2I Adapter. Plug-and-Play aplica un enfoque de inversión de modelo de difusión de desenfoque implícito ampliamente utilizado (DDIM) que revierte el proceso de generación a partir de una imagen de entrada para derivar una entrada de ruido inicial, y luego utiliza una copia del modelo de difusión (860M parámetros para Stable Diffusion 1.5) para codificar la condición a partir de una imagen de entrada. Plug-and-Play extrae características espaciales con autoatención de la difusión copiada y las inyecta en la difusión de texto a imagen. ControlNet crea una copia entrenable del codificador de un modelo de difusión, que se conecta a través de una capa de convolución con parámetros inicializados en cero para codificar información de condicionamiento que se transmite a las capas del decodificador. Sin embargo, como resultado, el tamaño es grande, la mitad del modelo de difusión (430M parámetros para Stable Diffusion 1.5). T2I Adapter es una red más pequeña (77M parámetros) y logra efectos similares en la generación controlable. T2I Adapter solo toma la imagen de condición como entrada y su salida se comparte en todas las iteraciones de difusión. Sin embargo, el modelo de adaptador no está diseñado para dispositivos portátiles.
Los complementos de difusión de MediaPipe
Para hacer que la generación condicionada sea eficiente, personalizable y escalable, diseñamos el complemento de difusión de MediaPipe como una red separada que es:
- Enchufable: Se puede conectar fácilmente a un modelo base pre-entrenado.
- Entrenado desde cero: No utiliza pesos pre-entrenados del modelo base.
- Portátil: Se ejecuta fuera del modelo base en dispositivos móviles, con un costo insignificante en comparación con la inferencia del modelo base.
| Método | Tamaño de Parámetros | Enchufable | Desde Cero | Portátil | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| Complemento de MediaPipe | 6M | ✔️ | ✔️ | ✔️ |
| Comparación de Plug-and-Play, ControlNet, Adaptador T2I y el complemento de difusión de MediaPipe. * El número varía dependiendo de los detalles del modelo de difusión. |
El complemento de difusión de MediaPipe es un modelo portátil en el dispositivo para la generación de texto a imagen. Extrae características de múltiples escalas de una imagen de condicionamiento, las cuales se agregan al codificador de un modelo de difusión en niveles correspondientes. Al conectarse a un modelo de difusión de texto a imagen, el modelo del complemento puede proporcionar una señal de condicionamiento adicional para la generación de imágenes. Diseñamos la red del complemento para que sea un modelo liviano con solo 6M de parámetros. Utiliza convoluciones de profundidad y cuellos de botella invertidos de MobileNetv2 para una inferencia rápida en dispositivos móviles.
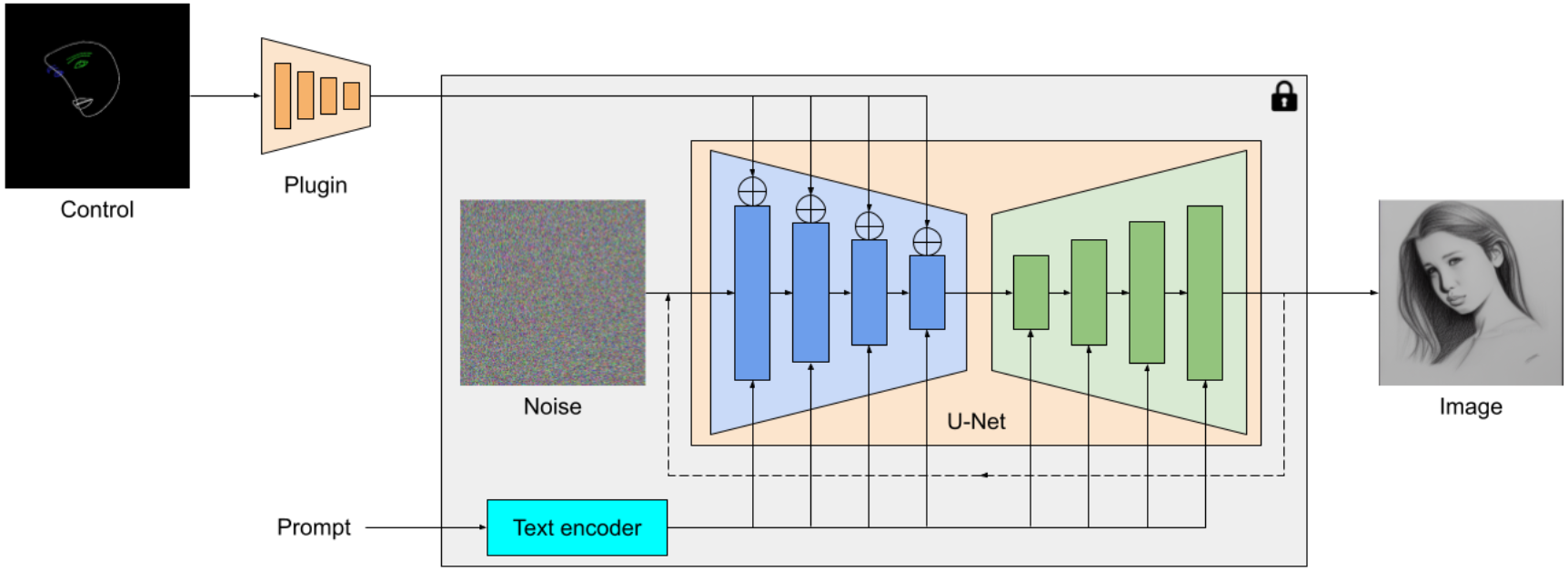 |
| Visión general del complemento del modelo de difusión de MediaPipe. El complemento es una red separada, cuya salida se puede conectar a un modelo pre-entrenado de generación de texto a imagen. Las características extraídas por el complemento se aplican a la capa de muestreo descendente asociada del modelo de difusión (azul). |
A diferencia de ControlNet, inyectamos las mismas características de control en todas las iteraciones de difusión. Es decir, solo ejecutamos el complemento una vez para una generación de imagen, lo que ahorra cálculos. Ilustramos algunos resultados intermedios de un proceso de difusión a continuación. El control es efectivo en cada paso de difusión y permite una generación controlada incluso en los primeros pasos. Más iteraciones mejoran la alineación de la imagen con la indicación de texto y generan más detalles.
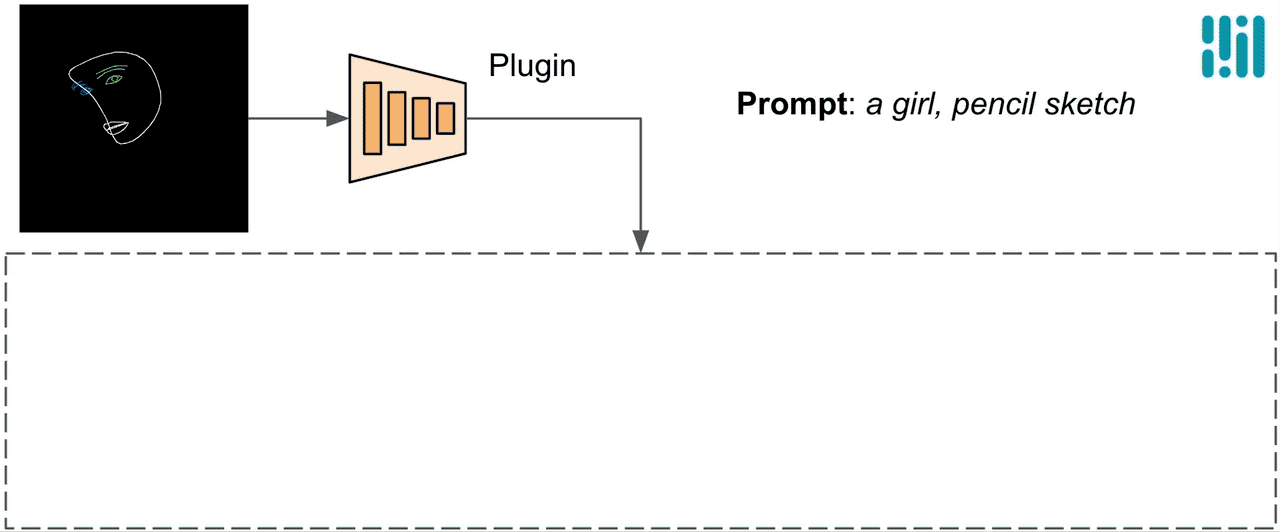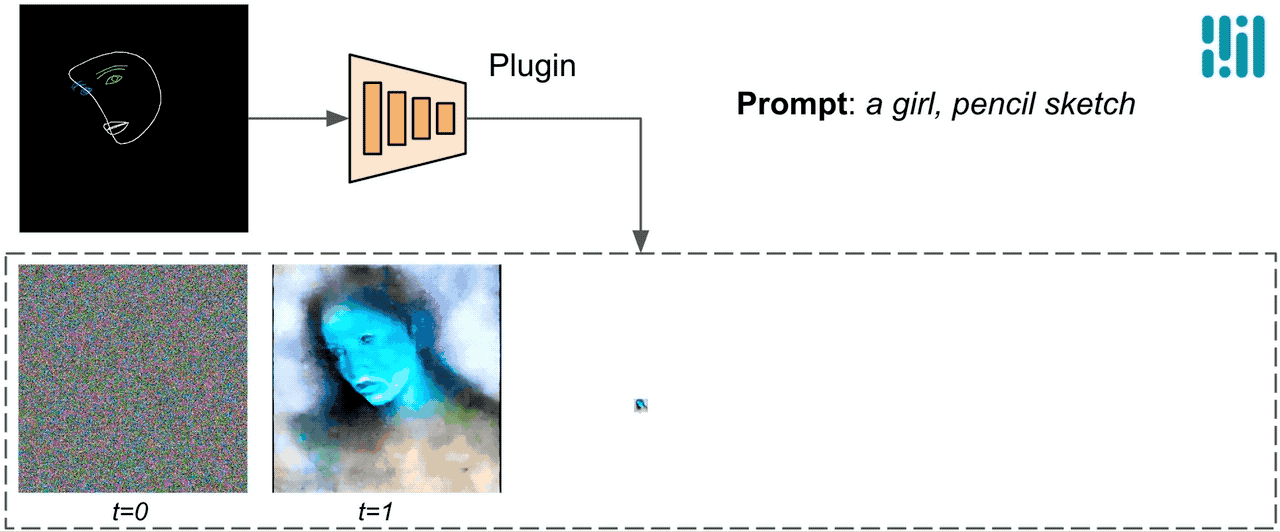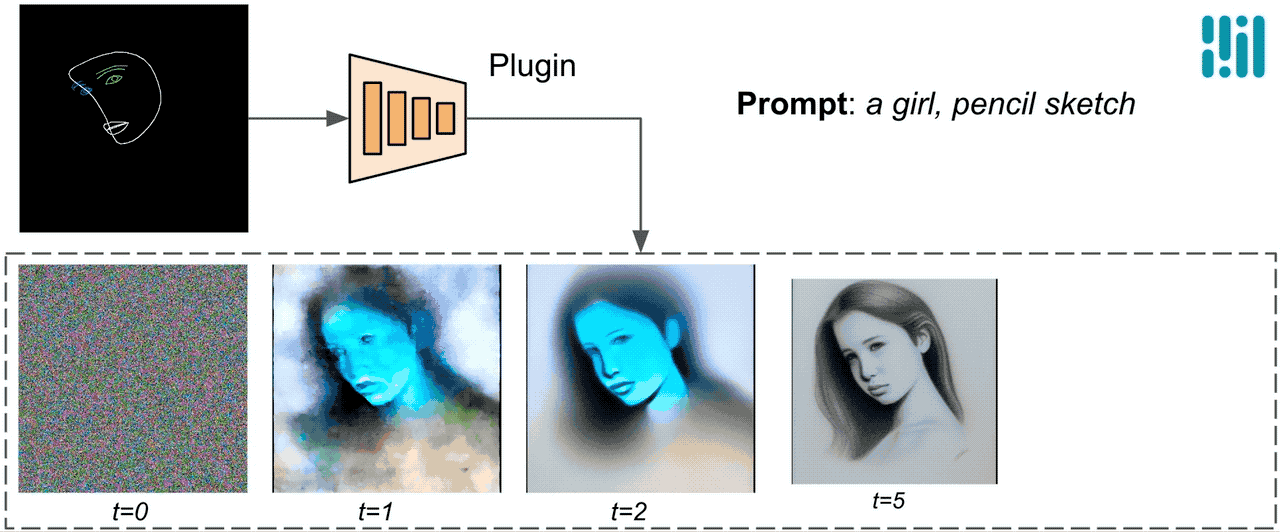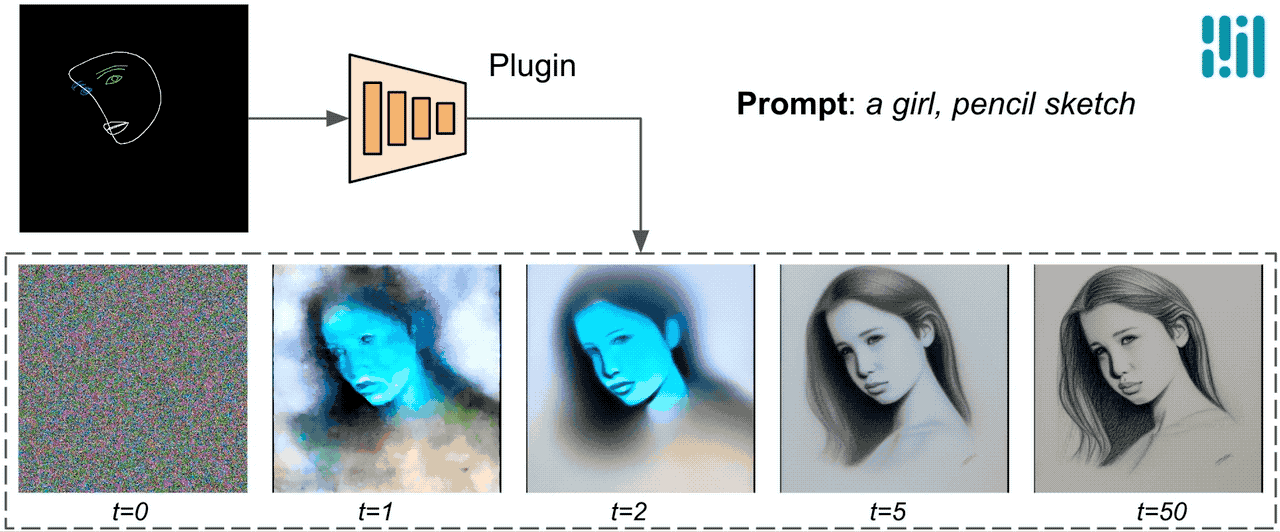 |
| Ilustración del proceso de generación utilizando el complemento de difusión de MediaPipe. |
Ejemplos
En este trabajo, desarrollamos complementos para un modelo de generación de texto a imagen basado en difusión con MediaPipe Face Landmark , MediaPipe Holistic Landmark , mapas de profundidad y bordes de Canny . Para cada tarea, seleccionamos alrededor de 100K imágenes de un conjunto de datos de imágenes y texto a escala web , y calculamos señales de control utilizando soluciones de MediaPipe correspondientes. Utilizamos descripciones refinadas de PaLI para entrenar los complementos.
Face Landmark
La tarea de MediaPipe Face Landmarker calcula 478 landmarks (con atención) de un rostro humano. Utilizamos las utilidades de dibujo en MediaPipe para renderizar un rostro, incluyendo el contorno del rostro, boca, ojos, cejas e iris, con diferentes colores. La siguiente tabla muestra muestras generadas aleatoriamente condicionadas por la malla facial y las indicaciones. Como comparación, tanto ControlNet como el complemento pueden controlar la generación de texto a imagen con condiciones dadas.
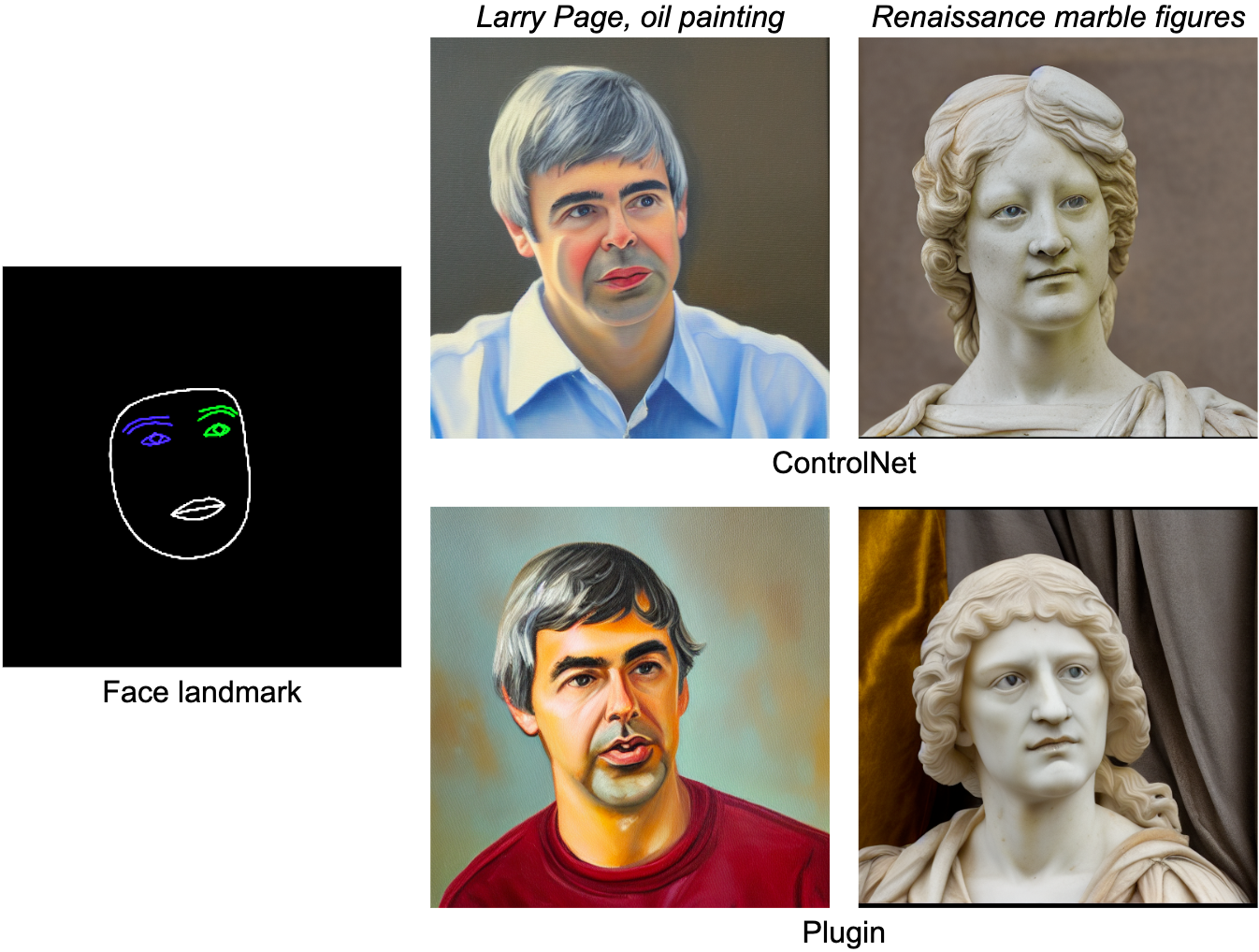 |
| Complemento de landmarks faciales para la generación de texto a imagen, comparado con ControlNet. |
Marcador Holístico
La tarea de Marcador Holístico de MediaPipe incluye puntos de referencia de la postura corporal, las manos y la malla facial. A continuación, generamos diversas imágenes estilizadas condicionadas a las características holísticas.
 |
| Plugin de marcador holístico para generación de texto a imagen. |
Profundidad
 |
| Plugin de profundidad para generación de texto a imagen. |
Borde Canny
 |
| Plugin de borde Canny para generación de texto a imagen. |
Evaluación
Realizamos un estudio cuantitativo del plugin de marcador facial para demostrar el rendimiento del modelo. El conjunto de datos de evaluación contiene 5K imágenes humanas. Comparamos la calidad de generación medida por las métricas ampliamente utilizadas, Distancia de Inception Fréchet (FID) y puntuaciones CLIP. El modelo base es un modelo de difusión pre-entrenado de texto a imagen. Aquí utilizamos Stable Diffusion v1.5.
Como se muestra en la siguiente tabla, tanto ControlNet como el plugin de difusión MediaPipe producen una calidad de muestra mucho mejor que el modelo base, en términos de FID y puntuaciones CLIP. A diferencia de ControlNet, que debe ejecutarse en cada paso de difusión, el plugin de MediaPipe solo se ejecuta una vez por cada imagen generada. Medimos el rendimiento de los tres modelos en un servidor (con GPU Nvidia V100) y en un teléfono móvil (Galaxy S23). En el servidor, ejecutamos los tres modelos con 50 pasos de difusión, y en el móvil, ejecutamos 20 pasos de difusión utilizando la aplicación de generación de imágenes de MediaPipe. En comparación con ControlNet, el plugin de MediaPipe muestra una clara ventaja en eficiencia de inferencia al tiempo que conserva la calidad de la muestra.
| Modelo | FID↓ | CLIP↑ | Tiempo de Inferencia (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| Base | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| Base + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| Base + Plugin de MediaPipe | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) |
| Comparación cuantitativa en FID, CLIP y tiempo de inferencia. |
Probamos el rendimiento del complemento en una amplia gama de dispositivos móviles, desde gama media hasta gama alta. Enumeramos los resultados en algunos dispositivos representativos en la siguiente tabla, que abarca tanto Android como iOS.
| Dispositivo | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| Tiempo (ms) | 128 | 68 | 50 | 48 | 73 | 63 |
| Tiempo de inferencia (ms) del complemento en diferentes dispositivos móviles. |
Conclusión
En este trabajo, presentamos MediaPipe, un complemento portátil para la generación condicionada de texto a imagen. Inyecta características extraídas de una imagen de condición en un modelo de difusión y controla la generación de imágenes en consecuencia. Los complementos portátiles se pueden conectar a modelos de difusión preentrenados que se ejecutan en servidores o dispositivos. Al ejecutar la generación de texto a imagen y los complementos completamente en el dispositivo, permitimos aplicaciones más flexibles de IA generativa.
Agradecimientos
Queremos agradecer a todos los miembros del equipo que contribuyeron a este trabajo: Raman Sarokin y Juhyun Lee por la solución de inferencia de GPU; Khanh LeViet, Chuo-Ling Chang, Andrei Kulik y Matthias Grundmann por su liderazgo. Un agradecimiento especial a Jiuqiang Tang, Joe Zou y Lu wang, quienes hicieron posible esta tecnología y todas las demostraciones en el dispositivo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Construyendo Modelos de Lenguaje Una Guía de Implementación Paso a Paso de BERT
- Generar música a partir de texto utilizando Google MusicLM
- LangFlow | Interfaz de usuario para LangChain para desarrollar aplicaciones con LLMs
- Conoce a ChatGLM2-6B la versión de segunda generación del modelo de chat de código abierto bilingüe (chino-inglés) ChatGLM-6B.
- Una Introducción a la Ingeniería de Prompt
- MosaicML acaba de lanzar su MPT-30B bajo la licencia Apache 2.0.
- ¿Qué es Machine Learning como Servicio? Beneficios y principales plataformas de MLaaS.





