Boletín de Ética y Sociedad #3 Apertura Ética en Hugging Face
Boletín Ética y Sociedad #3 Apertura Ética en Hugging Face.
Misión: Aprendizaje Automático (ML) Abierto y Bueno
En nuestra misión de democratizar el buen aprendizaje automático (ML), examinamos cómo el apoyo al trabajo de la comunidad de ML también fortalece el examen y la prevención de posibles daños. El desarrollo y la ciencia abierta descentralizan el poder para que muchas personas puedan trabajar colectivamente en IA que refleje sus necesidades y valores. Si bien la apertura permite que perspectivas más amplias contribuyan a la investigación y a la IA en general, enfrenta la tensión de un control de riesgos menor.
La moderación de los artefactos de ML presenta desafíos únicos debido a la naturaleza dinámica y en constante evolución de estos sistemas. De hecho, a medida que los modelos de ML se vuelven más avanzados y capaces de producir contenido cada vez más diverso, aumenta el potencial de resultados dañinos o no deseados, lo que requiere el desarrollo de estrategias sólidas de moderación y evaluación. Además, la complejidad de los modelos de ML y la gran cantidad de datos que procesan agravan el desafío de identificar y abordar posibles sesgos y preocupaciones éticas.
Como anfitriones, reconocemos la responsabilidad que conlleva amplificar posibles daños a nuestros usuarios y al mundo en general. A menudo, estos daños afectan de manera dispar a las comunidades minoritarias de manera dependiente del contexto. Hemos adoptado el enfoque de analizar las tensiones en juego para cada contexto, abierto a la discusión en toda la empresa y en la comunidad de Hugging Face. Si bien muchos modelos pueden amplificar el daño, especialmente el contenido discriminatorio, estamos tomando una serie de medidas para identificar los modelos de mayor riesgo y qué acciones tomar. Es importante contar con perspectivas activas de diversos orígenes para comprender, medir y mitigar los posibles daños que afectan a diferentes grupos de personas.
Estamos creando herramientas y salvaguardias, además de mejorar nuestras prácticas de documentación, para garantizar que la ciencia de código abierto capacite a las personas y continúe minimizando los posibles daños.
- StackLLaMA Una guía práctica para entrenar LLaMA con RLHF
- Acelerando Hugging Face Transformers con AWS Inferentia2
- Ejecutando IF con difusores 🧨 en un Google Colab de nivel gratuito
Categorías Éticas
El primer aspecto principal de nuestro trabajo para fomentar un buen ML abierto consiste en promover las herramientas y ejemplos positivos de desarrollo de ML que priorizan los valores y la consideración de sus partes interesadas. Esto ayuda a los usuarios a tomar medidas concretas para abordar problemas pendientes y presentar alternativas plausibles a prácticas dañinas de facto en el desarrollo de ML.
Para ayudar a nuestros usuarios a descubrir y participar en trabajos de ML relacionados con la ética, hemos compilado un conjunto de etiquetas. Estas 6 categorías de alto nivel se basan en nuestro análisis de los Espacios a los que los miembros de la comunidad han contribuido. Están diseñadas para brindarle una forma libre de jerga de pensar en tecnología ética:
- El trabajo riguroso presta especial atención al desarrollo teniendo en cuenta las mejores prácticas. En ML, esto puede significar examinar casos de fracaso (incluida la realización de auditorías de sesgo e imparcialidad), proteger la privacidad mediante medidas de seguridad y garantizar que los posibles usuarios (técnicos y no técnicos) estén informados sobre las limitaciones del proyecto.
- El trabajo consentido respalda la autodeterminación de las personas que utilizan y se ven afectadas por estas tecnologías.
- El trabajo socialmente consciente nos muestra cómo la tecnología puede respaldar los esfuerzos sociales, ambientales y científicos.
- El trabajo sostenible destaca y explora técnicas para hacer que el aprendizaje automático sea ecológicamente sostenible.
- El trabajo inclusivo amplía el alcance de quién construye y se beneficia en el mundo del aprendizaje automático.
- El trabajo inquisitivo pone de manifiesto las desigualdades y las estructuras de poder que desafían a la comunidad a repensar su relación con la tecnología.
Lea más en https://huggingface.co/ethics
Busque estos términos, ya que utilizaremos estas etiquetas y las actualizaremos en función de las contribuciones de la comunidad, en algunos nuevos proyectos en el Hub.
Salvaguardias
Tener una visión de “todo o nada” de las versiones abiertas ignora la amplia variedad de contextos que determinan los impactos positivos o negativos de un artefacto de ML. Tener más palancas de control sobre cómo se comparten y reutilizan los sistemas de ML respalda el desarrollo y análisis colaborativos con menos riesgo de promover usos o abusos dañinos, lo que permite una mayor apertura y participación en la innovación en beneficio compartido.
Nos involucramos directamente con los colaboradores y hemos abordado problemas urgentes. Para llevar esto al siguiente nivel, estamos construyendo procesos basados en la comunidad. Este enfoque capacita tanto a los colaboradores de Hugging Face como a aquellos afectados por las contribuciones para informar sobre las limitaciones, el intercambio y los mecanismos adicionales necesarios para los modelos y datos disponibles en nuestra plataforma. Los tres aspectos principales a los que prestaremos atención son: el origen del artefacto, cómo los desarrolladores manejan el artefacto y cómo se ha utilizado. En ese sentido:
- lanzamos una función de señalización para que nuestra comunidad determine si los artefactos de ML o el contenido de la comunidad (modelo, conjunto de datos, espacio o discusión) violan nuestras pautas de contenido,
- monitoreamos nuestros foros de discusión comunitarios para asegurarnos de que los usuarios de Hub cumplan con el código de conducta,
- documentamos de manera sólida nuestros modelos más descargados con tarjetas de modelo que detallan los impactos sociales, los sesgos y los casos de uso previstos y fuera de alcance,
- creamos etiquetas orientadas al público, como la etiqueta “No para todas las audiencias”, que se puede agregar a los metadatos de la tarjeta del repositorio para evitar contenido violento y sexual no solicitado,
- promovemos el uso de Licencias de IA Responsable Abierta (RAIL) para modelos, como con LLMs (BLOOM, BigCode),
- realizamos investigaciones que analizan qué modelos y conjuntos de datos tienen el mayor potencial o historial de uso indebido y malicioso.
Cómo utilizar la función de marcado: Haz clic en el icono de la bandera en cualquier Modelo, Conjunto de datos, Espacio o Discusión:
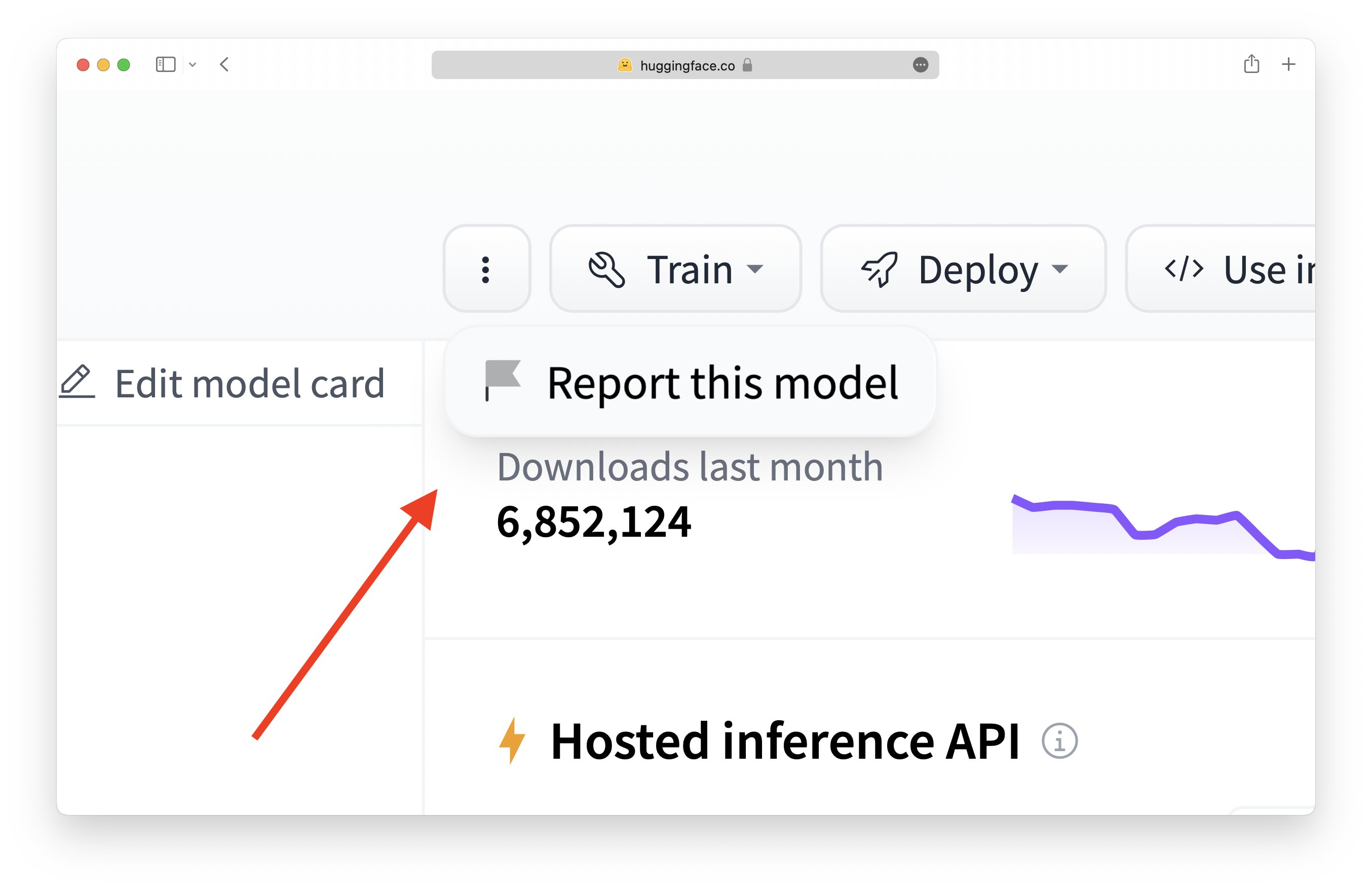 Mientras estés conectado, puedes hacer clic en el botón de “tres puntos” para desplegar la opción de reportar (o marcar) un repositorio. Esto abrirá una conversación en la pestaña de comunidad del repositorio.
Mientras estés conectado, puedes hacer clic en el botón de “tres puntos” para desplegar la opción de reportar (o marcar) un repositorio. Esto abrirá una conversación en la pestaña de comunidad del repositorio.
Explica por qué has marcado este elemento:
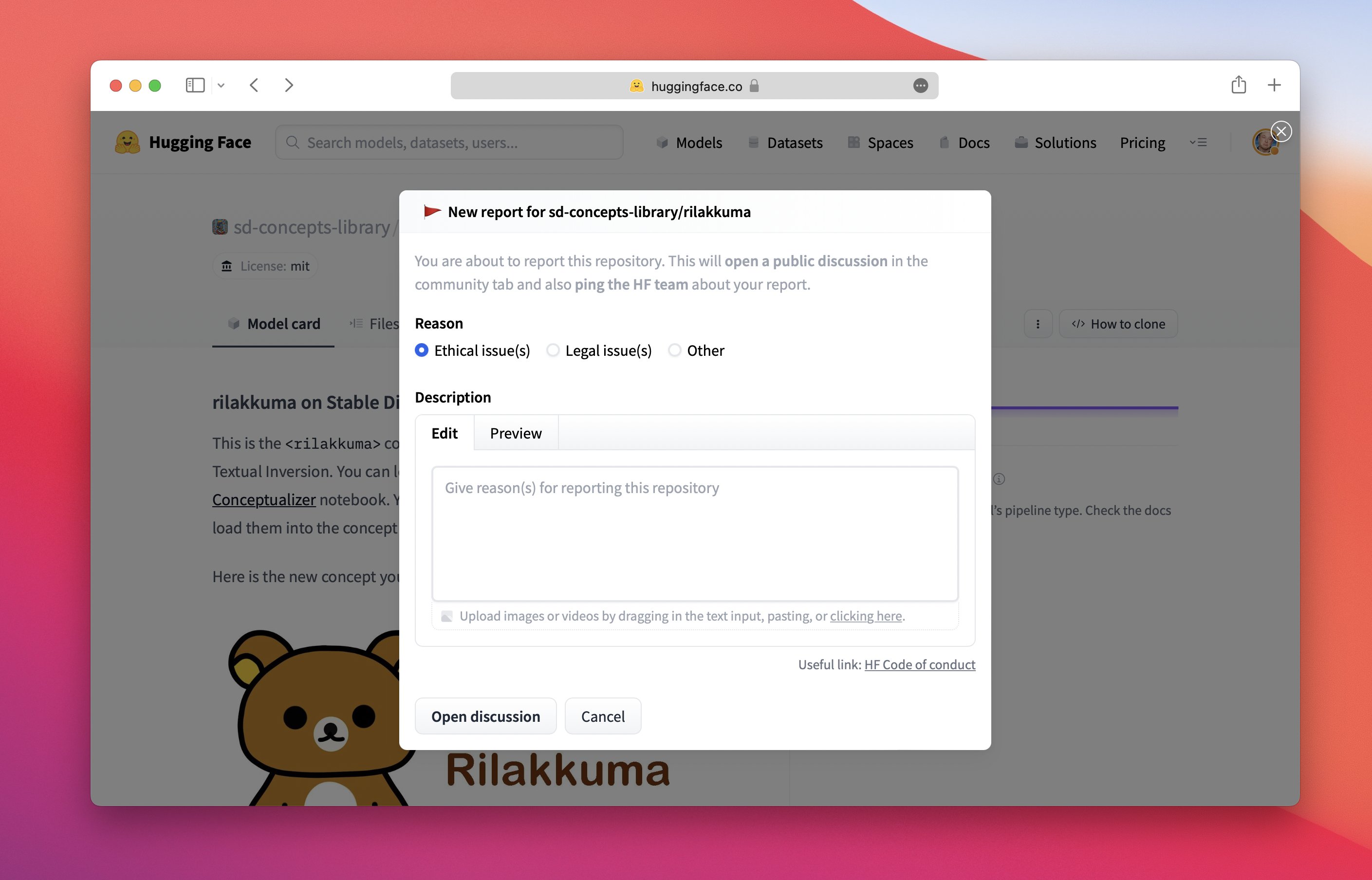 ¡Añade toda la información relevante posible en tu reporte! Esto facilitará que el propietario del repositorio y el equipo de HF tomen medidas.
¡Añade toda la información relevante posible en tu reporte! Esto facilitará que el propietario del repositorio y el equipo de HF tomen medidas.
Al priorizar la ciencia abierta, examinamos el posible daño caso por caso y brindamos la oportunidad de aprendizaje colaborativo y responsabilidad compartida. Cuando los usuarios marcan un sistema, los desarrolladores pueden responder directamente y de manera transparente a las preocupaciones. En este sentido, pedimos a los propietarios del repositorio que hagan esfuerzos razonables para abordar los informes, especialmente cuando los reporteros se toman el tiempo de proporcionar una descripción del problema. También destacamos que los informes y las discusiones están sujetos a las mismas normas de comunicación que el resto de la plataforma. Los moderadores pueden desvincularse o cerrar las discusiones si el comportamiento se vuelve odioso y/o abusivo (ver código de conducta).
Si un modelo específico es marcado como alto riesgo por nuestra comunidad, consideramos:
- Reducir la visibilidad del artefacto de ML en el Hub en la pestaña de tendencias y en los feeds,
- Solicitar que se habilite la función de control para gestionar el acceso a los artefactos de ML (ver documentación para modelos y conjuntos de datos),
- Solicitar que los modelos se hagan privados,
- Desactivar el acceso.
Cómo agregar la etiqueta “No apto para todos los públicos”:
Edita la tarjeta del modelo/datos → añade not-for-all-audiences en la sección de etiquetas → abre la solicitud de extracción y espera a que los autores la fusionen. Una vez fusionada, la siguiente etiqueta se mostrará en el repositorio:

Cualquier repositorio etiquetado como not-for-all-audiences mostrará el siguiente mensaje emergente al visitarlo:
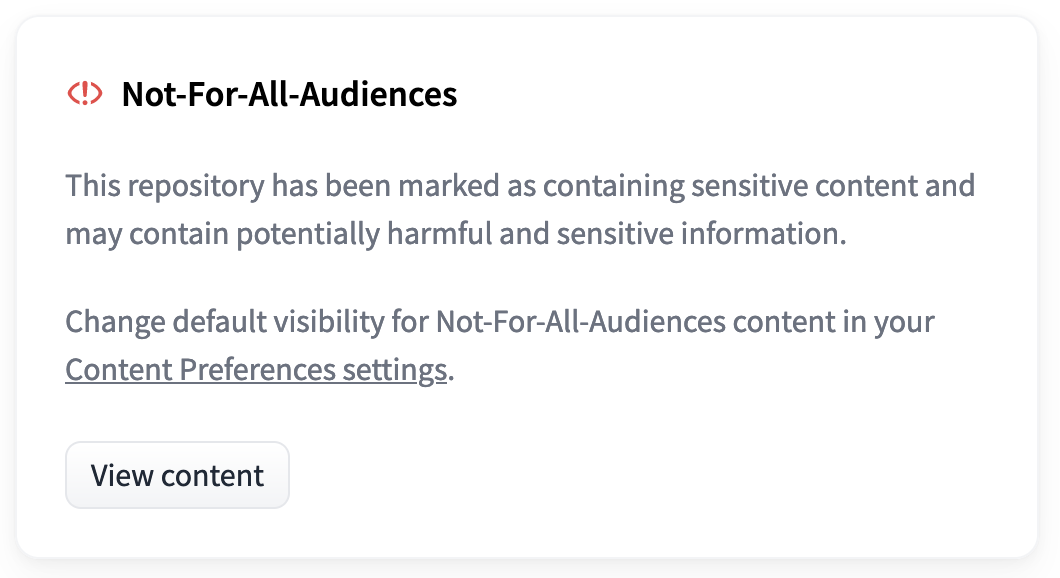
Haciendo clic en “Ver contenido” podrás ver el repositorio como de costumbre. Si deseas ver siempre los repositorios etiquetados como not-for-all-audiences sin el mensaje emergente, esta configuración se puede cambiar en las Preferencias de contenido del usuario
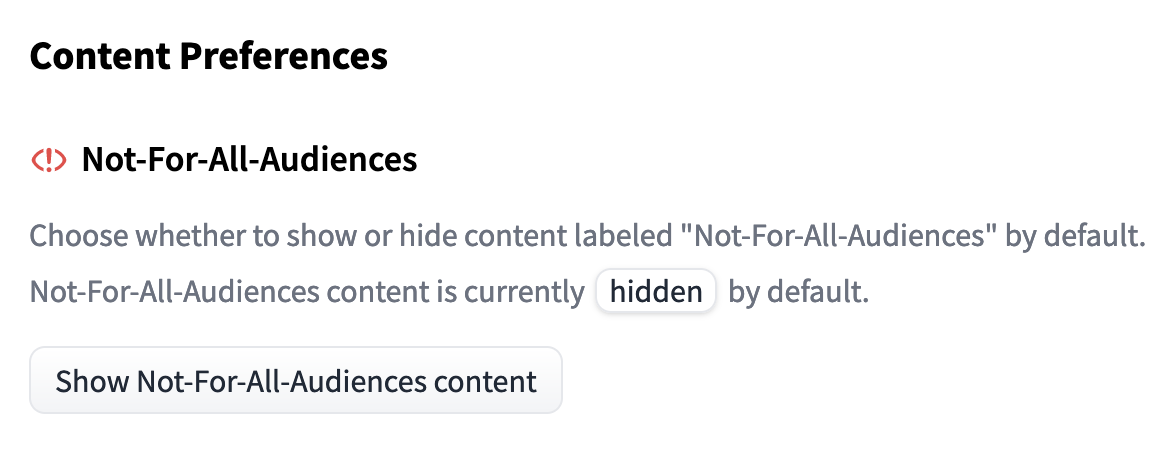
La ciencia abierta requiere salvaguardias, y uno de nuestros objetivos es crear un entorno informado por los compromisos con diferentes valores. Alojar y proporcionar acceso a modelos, además de fomentar la comunidad y la discusión, capacita a grupos diversos para evaluar las implicaciones sociales y guiar lo que es un buen aprendizaje automático.
¿Estás trabajando en salvaguardias? ¡Compártelas en Hugging Face Hub!
La parte más importante de Hugging Face es nuestra comunidad. Si eres un investigador que trabaja en hacer que el aprendizaje automático sea más seguro de usar, especialmente para la ciencia abierta, ¡queremos apoyar y mostrar tu trabajo!
Aquí tienes algunas demostraciones y herramientas recientes de investigadores de la comunidad de Hugging Face:
- Una marca de agua para LLMs por John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein ( artículo )
- Herramienta para generar tarjetas de modelos por el equipo de Hugging Face
- Photoguard para proteger las imágenes contra la manipulación por Ram Ananth
¡Gracias por leer! 🤗
~ Irene, Nima, Giada, Yacine y Elizabeth, en nombre de los habituales de Ética y Sociedad
Si deseas citar esta publicación de blog, utiliza lo siguiente (en orden descendente de contribución):
@misc{hf_ethics_soc_blog_3,
author = {Irene Solaiman y
Giada Pistilli y
Nima Boscarino y
Yacine Jernite y
Elizabeth Allendorf y
Margaret Mitchell y
Carlos Muñoz Ferrandis y
Nathan Lambert y
Alexandra Sasha Luccioni
},
title = {Hugging Face Ética y Sociedad Boletín 3: Apertura Ética en Hugging Face},
booktitle = {Hugging Face Blog},
year = {2023},
url = {https://doi.org/10.57967/hf/0487},
doi = {10.57967/hf/0487}
}We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo instalar y usar la API de Unity de Hugging Face
- StarCoder Un LLM de última generación para el código
- Generación Asistida una nueva dirección hacia la generación de texto de baja latencia
- Presentando RWKV – Una RNN con las ventajas de un transformador
- Más pequeño es mejor Q8-Chat, una experiencia eficiente de IA generativa en Xeon
- Deduplicación a gran escala detrás de BigCode
- 🐶Safetensors auditados como realmente seguros y convirtiéndose en la opción predeterminada






