Trabajando con Big Data Herramientas y Técnicas
Big Data Herramientas y Técnicas

Ya han pasado los tiempos en los negocios en los que todos los datos que necesitabas estaban en tu ‘libreta negra’. En esta era de la revolución digital, ni siquiera las bases de datos clásicas son suficientes.
El manejo de big data se convirtió en una habilidad crítica para las empresas y, con ellas, para los científicos de datos. El big data se caracteriza por su volumen, velocidad y variedad, ofreciendo una visión sin precedentes de patrones y tendencias.
Para manejar este tipo de datos de manera efectiva, se requiere el uso de herramientas y técnicas especializadas.
- Investigadores de Sony proponen BigVSAN Revolucionando la calidad de audio con el uso de Slicing Adversarial Networks en vocoders basados en GAN.
- Conoce ResFields Un enfoque novedoso de IA para superar las limitaciones de los campos neurales espaciotemporales en la modelización efectiva de señales temporales largas y complejas.
- Descubriendo los secretos del rendimiento catalítico con Deep Learning Un estudio en profundidad de la Red Neuronal Convolucional ‘Global + Local’ para la detección de alta precisión de catalizadores heterogéneos
¿Qué es el Big Data?
No, simplemente no es gran cantidad de datos.
El big data se caracteriza más comúnmente por las tres V:
- Volumen: Sí, el tamaño de los datos generados y almacenados es una de las características. Para ser considerado como big data, el tamaño de los datos debe medirse en petabytes (1,024 terabytes) y exabytes (1,024 petabytes).
- Variedad: El big data no consiste solo en datos estructurados, sino también en datos semi-estructurados (JSON, XML, YAML, correos electrónicos, archivos de registro, hojas de cálculo) y datos no estructurados (archivos de texto, imágenes y videos, archivos de audio, publicaciones en redes sociales, páginas web, datos científicos como imágenes de satélite, datos de formas de onda sísmicas o datos experimentales sin procesar), centrándose en los datos no estructurados.
- Velocidad: La rapidez con la que se generan y procesan los datos.
Herramientas y Técnicas de Big Data
Todas las características del big data mencionadas impactan en las herramientas y técnicas que utilizamos para manejar el big data.
Cuando hablamos de técnicas de big data, nos referimos simplemente a los métodos, algoritmos y enfoques que utilizamos para procesar, analizar y gestionar el big data. En apariencia, son los mismos que se utilizan en los datos regulares. Sin embargo, las características del big data que discutimos requieren enfoques y herramientas diferentes.
Aquí hay algunas herramientas y técnicas destacadas utilizadas en el ámbito del big data.
1. Procesamiento de Big Data
¿Qué es?: El procesamiento de datos se refiere a las operaciones y actividades que transforman los datos en bruto en información significativa. Incluye tareas desde limpiar y estructurar datos hasta ejecutar algoritmos y análisis complejos.
El big data a veces se procesa en lotes, pero es más común el procesamiento en tiempo real.
Características clave:
- Procesamiento paralelo: Distribuir tareas en múltiples nodos o servidores para procesar datos de forma concurrente, acelerando los cálculos.
- Procesamiento en tiempo real vs. en lotes: Los datos pueden procesarse en tiempo real (a medida que se generan) o en lotes (procesando fragmentos de datos en intervalos programados).
- Escalabilidad: Las herramientas de big data manejan grandes volúmenes de datos mediante la adición de más recursos o nodos.
- Tolerancia a fallos: Si un nodo falla, los sistemas continuarán procesando, asegurando la integridad y disponibilidad de los datos.
- Diversidad de fuentes de datos: El big data proviene de muchas fuentes, ya sean bases de datos estructuradas, registros, flujos de datos o repositorios de datos no estructurados.
Herramientas de Big Data utilizadas: Apache Hadoop MapReduce, Apache Spark, Apache Tez, Apache Kafka, Apache Storm, Apache Flink, Amazon Kinesis, IBM Streams, Google Cloud Dataflow
Descripción de las herramientas: 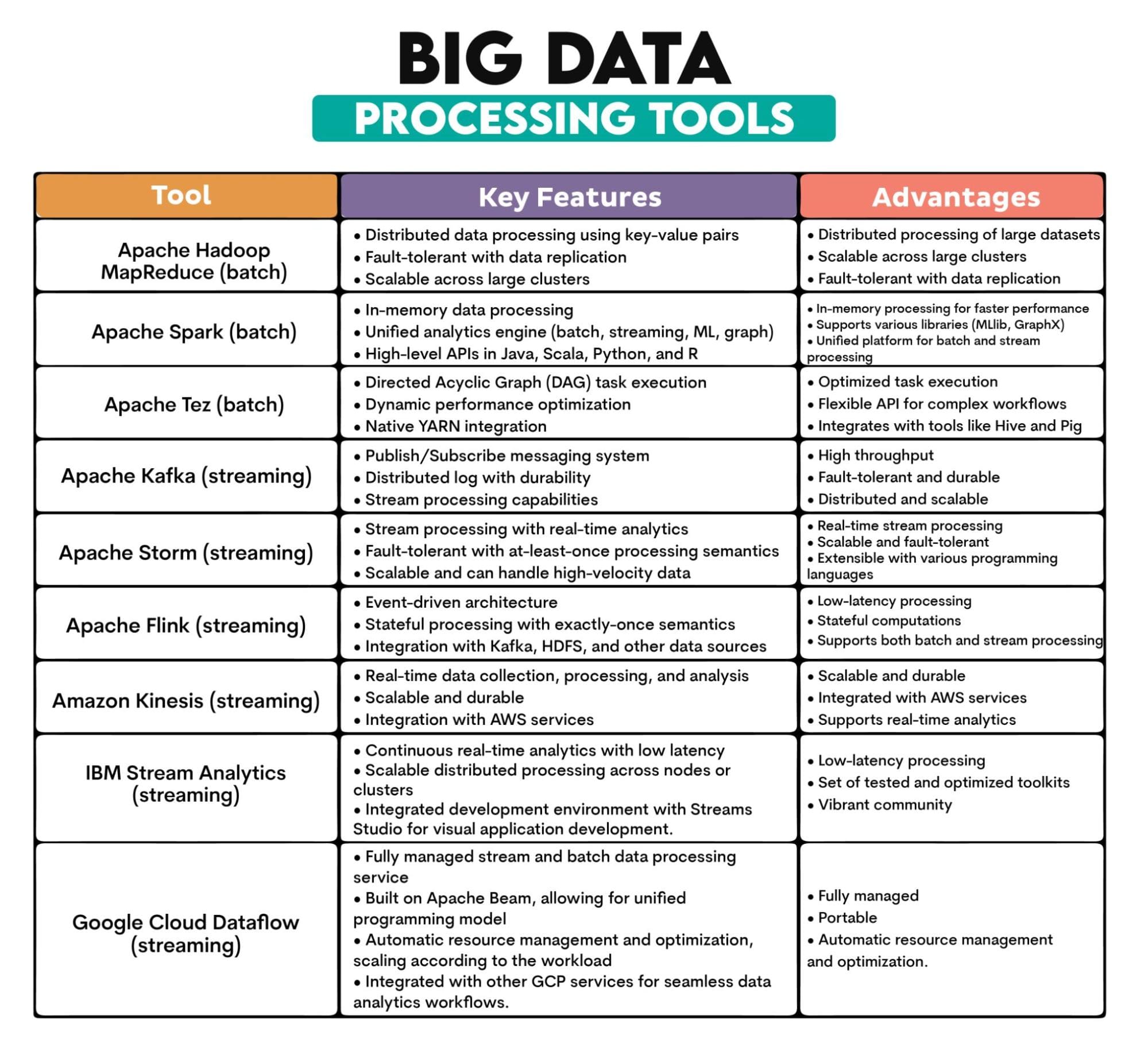
2. ETL de Big Data
¿Qué es?: ETL es la extracción de datos de diversas fuentes, la transformación de estos en un formato estructurado y utilizable, y la carga en un sistema de almacenamiento de datos para su análisis u otros fines.
Las características del big data significan que el proceso ETL necesita manejar más datos de más fuentes. Los datos suelen ser semi-estructurados o no estructurados, lo que implica una transformación y almacenamiento diferente a los datos estructurados.
El ETL en el big data también suele necesitar procesar datos en tiempo real.
Características clave:
- Extracción de datos: Los datos se obtienen de diversas fuentes heterogéneas, incluyendo bases de datos, registros, APIs y archivos planos.
- Transformación de datos: Conversión de los datos extraídos en un formato adecuado para consultas, análisis o informes. Implica limpiar, enriquecer, agregar y reformatear los datos.
- Carga de datos: Almacenamiento de los datos transformados en un sistema de destino, por ejemplo, un almacén de datos, un lago de datos o una base de datos.
- Procesamiento por lotes o en tiempo real: Los procesos ETL en tiempo real son más comunes en big data que el procesamiento por lotes.
- Integración de datos: ETL integra datos de fuentes dispares, garantizando una vista unificada de los datos en toda una organización.
Herramientas de Big Data utilizadas: Apache NiFi, Apache Sqoop, Apache Flume, Talend
Descripción de las herramientas:
| Herramientas de ETL para Big Data | ||
| Herramienta | Características clave | Ventajas |
| Apache NiFi |
• Diseño de flujo de datos mediante una interfaz web • Seguimiento de la procedencia de los datos • Arquitectura extensible con procesadores |
• Interfaz visual: Fácil diseño de flujos de datos • Soporta la procedencia de los datos • Extensible con una amplia gama de procesadores |
| Apache Sqoop |
• Transferencia masiva de datos entre Hadoop y bases de datos • Importación/exportación paralela • Compresión e importación directa |
• Transferencia eficiente de datos entre Hadoop y bases de datos relacionales • Importación/exportación paralela • Capacidades de transferencia de datos incrementales |
| Apache Flume |
• Arquitectura basada en eventos y configurable • Entrega de datos confiable y duradera • Integración nativa con el ecosistema Hadoop |
• Escalable y distribuido • Arquitectura tolerante a fallos • Extensible con fuentes, canales y destinos personalizados |
| Talend |
• Interfaz de diseño visual • Amplia conectividad con bases de datos, aplicaciones y más • Herramientas de calidad y perfilado de datos |
• Amplia gama de conectores para diversas fuentes de datos • Interfaz gráfica para diseñar procesos de integración de datos • Soporta calidad de datos y gestión de datos maestros |
3. Almacenamiento de Big Data
¿Qué es?: El almacenamiento de big data debe almacenar vastas cantidades de datos generados a altas velocidades y en diversos formatos.
Las tres formas más distintas de almacenar big data son las bases de datos NoSQL, los lagos de datos y los almacenes de datos.
Las bases de datos NoSQL están diseñadas para manejar grandes volúmenes de datos estructurados y no estructurados sin un esquema fijo (NoSQL – Not Only SQL). Esto los hace adaptables a la estructura de datos en constante evolución.
A diferencia de las bases de datos tradicionales escalables verticalmente, las bases de datos NoSQL son escalables horizontalmente, lo que significa que pueden distribuir datos en múltiples servidores. La escalabilidad se facilita añadiendo más máquinas al sistema. Son tolerantes a fallos, tienen baja latencia (apreciada en aplicaciones que requieren acceso a datos en tiempo real) y son eficientes en costos a gran escala.
Los lagos de datos son repositorios de almacenamiento que almacenan vastas cantidades de datos en bruto en su formato nativo. Esto simplifica el acceso y el análisis de datos, ya que todos los datos se encuentran en un solo lugar.
Los lagos de datos son escalables y eficientes en costos. Proporcionan flexibilidad (los datos se ingieren en su forma original y la estructura se define al leer los datos para su análisis), admiten el procesamiento de datos por lotes y en tiempo real, y se pueden integrar con herramientas de calidad de datos, lo que lleva a análisis más avanzados e información más rica.
Un almacén de datos es un repositorio centralizado optimizado para el procesamiento analítico que almacena datos de múltiples fuentes, transformándolos en un formato adecuado para el análisis y la generación de informes.
Está diseñado para almacenar grandes cantidades de datos, integrarlos desde diversas fuentes y permitir el análisis histórico ya que los datos se almacenan con una dimensión temporal.
Características clave:
- Escalabilidad: Diseñado para crecer agregando más nodos o unidades.
- Arquitectura distribuida: Los datos se suelen almacenar en varios nodos o servidores, asegurando una alta disponibilidad y tolerancia a fallos.
- Variedad de formatos de datos: Puede manejar datos estructurados, semi-estructurados y no estructurados.
- Durabilidad: Una vez almacenados, los datos permanecen intactos y disponibles, incluso ante fallos de hardware.
- Eficiencia en costos: Muchas soluciones de almacenamiento de big data están diseñadas para funcionar en hardware de consumo, lo que las hace más asequibles a gran escala.
Herramientas utilizadas en Big Data: MongoDB (basado en documentos), Cassandra (basado en columnas), Apache HBase (basado en columnas), Neo4j (basado en grafos), Redis (almacenamiento clave-valor), Amazon S3, Azure Data Lake, Hadoop Distributed File System (HDFS), Google Big Lake, Amazon Redshift, BigQuery
Descripción de las herramientas: 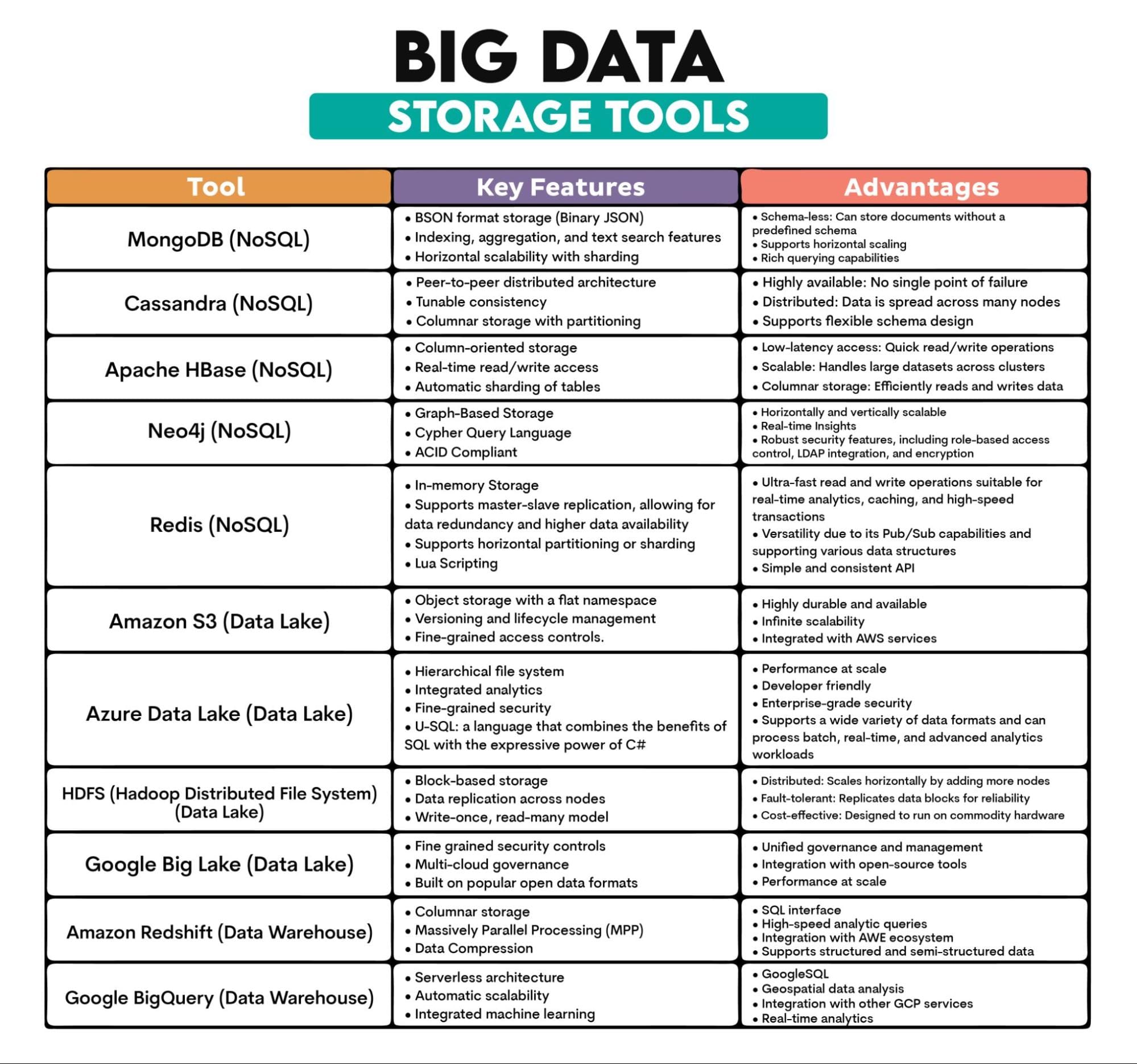
4. Minería de datos masiva
¿Qué es?: Es el descubrimiento de patrones, correlaciones, anomalías y relaciones estadísticas en conjuntos de datos grandes. Involucra disciplinas como el aprendizaje automático, la estadística y el uso de sistemas de bases de datos para extraer conocimientos de los datos.
La cantidad de datos extraídos es vasta y el volumen en sí puede revelar patrones que no serían evidentes en conjuntos de datos más pequeños. Los datos masivos suelen provenir de diversas fuentes y a menudo son semi-estructurados o no estructurados. Esto requiere técnicas de preprocesamiento e integración más sofisticadas. A diferencia de los datos regulares, los datos masivos suelen procesarse en tiempo real.
Las herramientas utilizadas para la minería de datos masiva deben manejar todo esto. Para hacerlo, aplican cómputo distribuido, es decir, el procesamiento de datos se distribuye en varios equipos.
Algunos algoritmos pueden no ser adecuados para la minería de datos masiva, ya que requiere algoritmos escalables de procesamiento paralelo, como SVM, SGD o Gradient Boosting.
La minería de datos masiva también ha adoptado técnicas de Análisis Exploratorio de Datos (EDA). El EDA analiza conjuntos de datos para resumir sus características principales, a menudo utilizando gráficos estadísticos, gráficos e información en tablas. Debido a esto, hablaremos sobre la minería de datos masiva y las herramientas de EDA juntas.
Características clave:
- Reconocimiento de patrones: Identificar regularidades o tendencias en conjuntos de datos grandes.
- Agrupamiento y clasificación: Agrupar puntos de datos en base a similitudes o criterios predefinidos.
- Análisis de asociación: Descubrir relaciones entre variables en bases de datos grandes.
- Análisis de regresión: Comprender y modelar la relación entre variables.
- Detección de anomalías: Identificar patrones inusuales.
Herramientas utilizadas en Big Data: Weka, KNIME, RapidMiner, Apache Hive, Apache Pig, Apache Drill, Presto
Descripción de las herramientas: 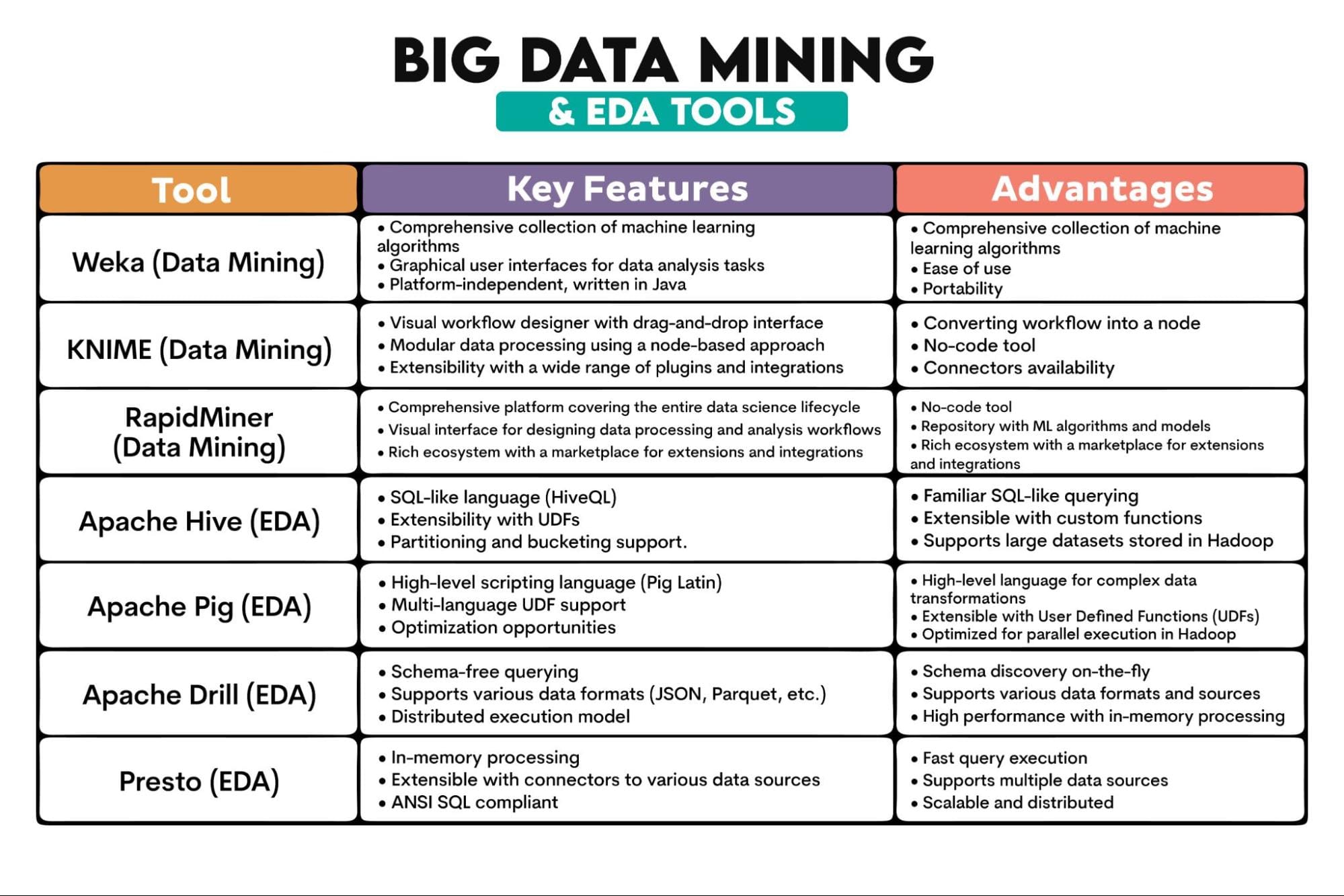
5. Visualización de datos masivos
¿Qué es?: Es una representación gráfica de información y datos extraídos de conjuntos de datos vastos. Utilizando elementos visuales como gráficos y mapas, las herramientas de visualización de datos proporcionan una forma accesible de entender patrones, valores atípicos y tendencias en los datos.
Nuevamente, las características de los datos masivos, como el tamaño y la complejidad, los diferencian de la visualización de datos regulares.
Características clave:
- Interactividad: La visualización de datos masivos requiere paneles y informes interactivos que permitan a los usuarios profundizar en detalles específicos y explorar datos de manera dinámica.
- Escalabilidad: Los conjuntos de datos grandes deben manejarse de manera eficiente sin comprometer el rendimiento.
- Diversidad de tipos de visualización: Por ejemplo, mapas de calor, visualizaciones geoespaciales y gráficos de redes complejas.
- Visualización en tiempo real: Muchas aplicaciones de big data requieren transmisión y visualización de datos en tiempo real para monitorear y reaccionar a datos en vivo.
- Integración con plataformas de big data: Las herramientas de visualización suelen integrarse perfectamente con las plataformas de big data.
Herramientas de Big Data utilizadas: Tableau, PowerBI, D3.js, Kibana
Descripción de las herramientas:
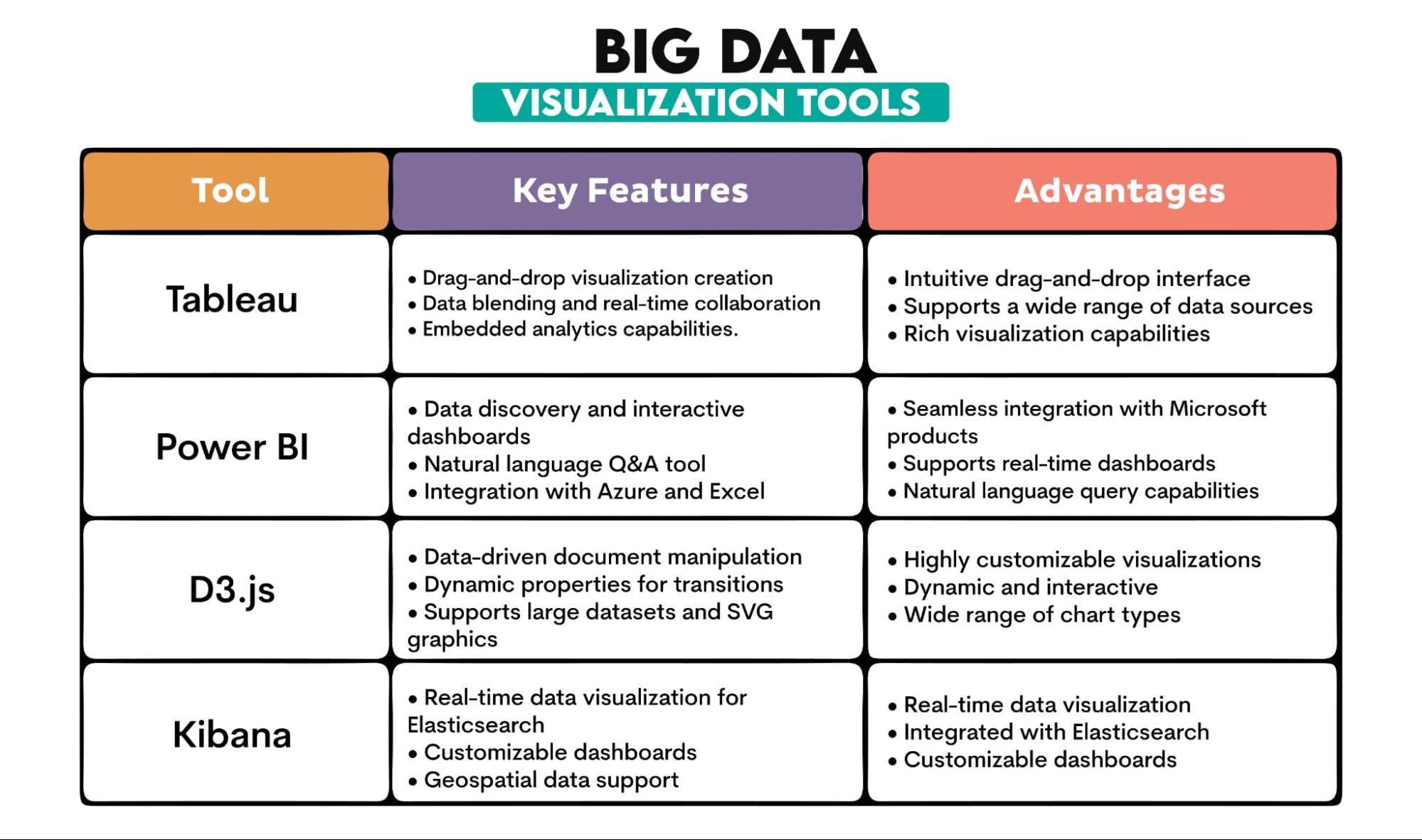
Conclusión
Los datos grandes son similares a los datos regulares, pero también son completamente diferentes. Comparten técnicas para manejar los datos. Sin embargo, debido a las características de los datos grandes, estas técnicas son las mismas solo por su nombre. De lo contrario, requieren enfoques y herramientas completamente diferentes.
Si quieres adentrarte en los datos grandes, tendrás que utilizar varias herramientas de datos grandes. Nuestra descripción general de estas herramientas debería ser un buen punto de partida para ti. Nate Rosidi es un científico de datos y estratega de productos. También es profesor adjunto que enseña análisis de datos y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas reales de las principales empresas. Conéctate con él en Twitter: StrataScratch o LinkedIn.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Una nueva investigación de AI de Apple y Equall AI revela redundancias en la arquitectura de Transformer Cómo optimizar la red de avance de alimentación mejora la eficiencia y la precisión
- 10 Mejores Herramientas de Extracción de Datos (Septiembre 2023)
- Datos de satélite, incendios forestales y IA Protegiendo la industria vitivinícola ante los desafíos climáticos
- Cómo crear gráficos de mapas con Plotly
- Aprendizaje por Reforzamiento una Introducción Sencilla a la Iteración de Valor
- Crea un sistema de comentarios autogestionado con LangChain y OpenAI
- Por qué tus canalizaciones de datos necesitan un control de retroalimentación en bucle cerrado






