AWS Inferentia2 se basa en AWS Inferentia1 ofreciendo un rendimiento 4 veces mayor y una latencia 10 veces menor.
AWS Inferentia2 offers 4 times higher performance and 10 times lower latency compared to AWS Inferentia1.
El tamaño de los modelos de aprendizaje automático (ML) – grandes modelos de lenguaje (LLMs) y modelos fundamentales (FMs) – está creciendo rápidamente año tras año, y estos modelos necesitan aceleradores más rápidos y potentes, especialmente para la IA generativa. AWS Inferentia2 fue diseñado desde cero para ofrecer un mayor rendimiento al tiempo que se reduce el costo de LLMs e inferencia de IA generativa.
En esta publicación, mostramos cómo la segunda generación de AWS Inferentia se basa en las capacidades introducidas con AWS Inferentia1 y cumple con las demandas únicas de implementar y ejecutar LLMs y FMs.
La primera generación de AWS Inferentia, un acelerador diseñado específicamente lanzado en 2019, está optimizado para acelerar la inferencia de aprendizaje profundo. AWS Inferentia ayudó a los usuarios de ML a reducir sus costos de inferencia y mejorar su rendimiento y latencia de predicción. Con AWS Inferentia1, los clientes vieron hasta 2.3 veces más rendimiento y hasta un 70% menos de costo por inferencia que las instancias de Amazon Elastic Compute Cloud (Amazon EC2) optimizadas para la inferencia comparables.
AWS Inferentia2, presentado en las nuevas instancias de Amazon EC2 Inf2 y compatible con Amazon SageMaker, está optimizado para la inferencia de IA generativa a gran escala y es la primera instancia centrada en la inferencia de AWS que está optimizada para la inferencia distribuida, con conectividad de alta velocidad y baja latencia entre aceleradores.
- Generador de subtítulos de inteligencia artificial (para contenido de formato corto)
- Los 5 Mejores Plugins de SEO de ChatGPT
- Herramienta gratuita de fotografía de productos de inteligencia artificial.
Ahora puede implementar eficientemente un modelo de 175 mil millones de parámetros para la inferencia en varios aceleradores en una sola instancia de Inf2 sin requerir instancias de entrenamiento costosas. Hasta ahora, los clientes que tenían modelos grandes solo podían usar instancias que estaban diseñadas para el entrenamiento, pero esto es un desperdicio de recursos, ya que son más caras, consumen más energía y su carga de trabajo no aprovecha todos los recursos disponibles (como una red y almacenamiento más rápidos). Con AWS Inferentia2, puede lograr hasta 4 veces más rendimiento y hasta 10 veces menos latencia en comparación con AWS Inferentia1. Además, la segunda generación de AWS Inferentia agrega soporte mejorado para más tipos de datos, operadores personalizados, tensores dinámicos y más.
AWS Inferentia2 tiene 4 veces más capacidad de memoria, 16,4 veces mayor ancho de banda de memoria que AWS Inferentia1 y soporte nativo para dividir modelos grandes en múltiples aceleradores. Los aceleradores utilizan NeuronLink y Neuron Collective Communication para maximizar la velocidad de transferencia de datos entre ellos o entre un acelerador y el adaptador de red. AWS Inferentia2 es más adecuado para modelos más grandes, que requieren división en múltiples aceleradores, aunque AWS Inferentia1 sigue siendo una excelente opción para modelos más pequeños porque proporciona un mejor rendimiento de costo en comparación con otras alternativas.
Evolución de la arquitectura
Para comparar ambas generaciones de AWS Inferentia, revisemos la arquitectura de AWS Inferentia1. Tiene cuatro NeuronCores v1 por chip, como se muestra en el siguiente diagrama.

Especificaciones por chip:
- Computación – Cuatro núcleos que entregan un total de 128 INT8 TOPS y 64 FP16/BF16 TFLOPS
- Memoria – 8 GB de DRAM (50 GB/seg de ancho de banda), compartidos por los cuatro núcleos
- NeuronLink – Enlace entre núcleos para dividir modelos en dos o más núcleos
Veamos cómo está organizado AWS Inferentia2. Cada chip de AWS Inferentia2 tiene dos núcleos mejorados basados en la arquitectura NeuronCore-v2. Al igual que con AWS Inferentia1, se pueden ejecutar diferentes modelos en cada NeuronCore o combinar múltiples núcleos para dividir modelos grandes.
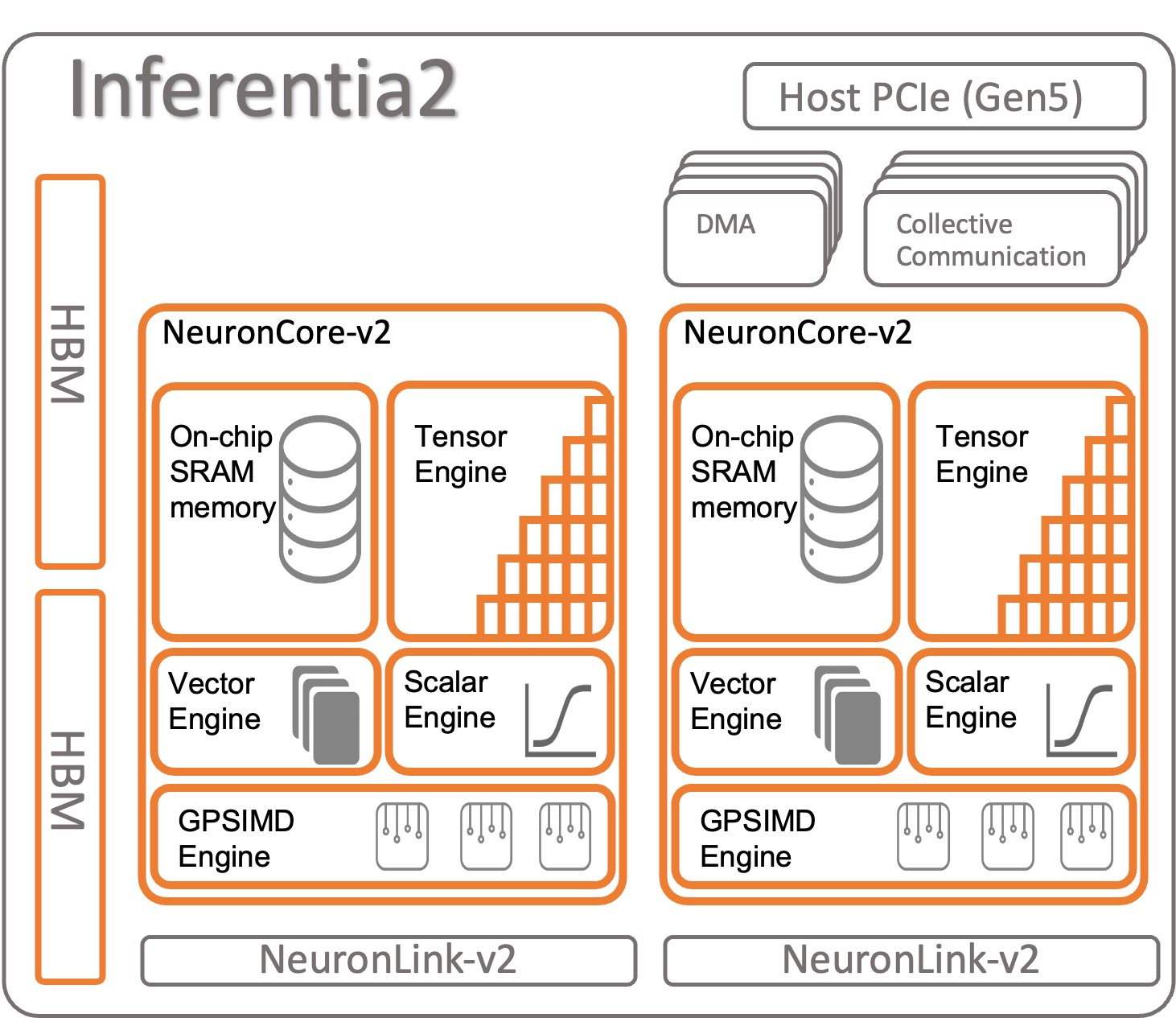
Especificaciones por chip:
- Computación – Dos núcleos que entregan un total de 380 INT8 TOPS, 190 FP16/BF16/cFP8/TF32 TFLOPS y 47,5 FP32 TFLOPS
- Memoria – 32 GB de HBM, compartidos por ambos núcleos
- NeuronLink – Enlace entre chips (384 GB/seg por dispositivo) para dividir modelos en dos o más núcleos
NeuronCore-v2 tiene un diseño modular con cuatro motores independientes:
- ScalarEngine (3 veces más rápido que v1) – Opera en números de punto flotante – 1600 (BF16/FP16) FLOPS
- VectorEngine (10 veces más rápido que v1) – Opera en vectores de números con una sola operación para cálculos como normalización, agrupación y otros.
- TensorEngine (6 veces más rápido que v1) – Realiza cálculos de tensor como Conv, Reshape, Transpose y otros.
- GPSIMD-Engine – Tiene ocho procesadores programables completamente personalizables de 512 bits de ancho para crear sus propios operadores con la API de operadores C++ personalizados estándar de PyTorch. Esta es una nueva característica introducida en NeuronCore-v2.
AWS Inferentia2 NeuronCore-v2 es más rápido y optimizado. Además, es capaz de acelerar diferentes tipos y tamaños de modelos, desde modelos simples como ResNet 50 hasta modelos de lenguaje grandes o modelos fundamentales con miles de millones de parámetros como GPT-3 (175 mil millones de parámetros). AWS Inferentia2 también tiene una memoria interna más grande y más rápida en comparación con AWS Inferentia1, como se muestra en la siguiente tabla.
| Chip | Neuron Cores | Tipo de memoria | Tamaño de memoria | Ancho de banda de memoria |
| AWS Inferentia | x4 (v1) | DDR4 | 8GB | 50GB/S |
| AWS Inferentia 2 | x2 (v2) | HBM | 32GB | 820GB/S |
La memoria que se encuentra en AWS Inferentia2 es del tipo Memoria de Alta Ancho de Banda (HBM). Cada chip AWS Inferentia2 tiene 32 GB y puede combinarse con otros chips para distribuir modelos muy grandes utilizando NeuronLink (interconexión de dispositivo a dispositivo). Un inf2.48xlarge, por ejemplo, tiene 12 aceleradores AWS Inferentia2 con un total de 384 GB de memoria acelerada. La velocidad de la memoria AWS Inferentia2 es 16,4 veces más rápida que AWS Inferentia1, como se muestra en la tabla anterior.
Otras características
AWS Inferentia2 ofrece las siguientes características adicionales:
- Soporte de hardware – cFP8 (nuevo, FP8 configurable), FP16, BF16, TF32, FP32, INT8, INT16 e INT32. Para obtener más información, consulte Tipos de datos.
- Inferencia de tensor perezoso – Discutimos la Inferencia de tensor perezoso más adelante en esta publicación.
- Operadores personalizados – Los desarrolladores pueden utilizar las interfaces de programación de operadores personalizados estándar de PyTorch para utilizar la función de operadores C++ personalizados. Un operador personalizado se compone de primitivas de bajo nivel disponibles en las funciones de fábrica de tensor y se acelera mediante GPSIMD-Engine.
- Flujo de control (próximamente) – Esto es para el flujo de control del lenguaje de programación nativo dentro del modelo para eventualmente preprocesar y postprocesar datos de una capa a otra.
- Formas dinámicas (próximamente) – Esto es útil cuando su modelo cambia la forma de la salida de cualquier capa interna de manera dinámica. Por ejemplo: un filtro que reduce el tamaño o la forma del tensor de salida dentro del modelo, según los datos de entrada.
Acelerando modelos en AWS Inferentia1 y AWS Inferentia2
El SDK de Neuron de AWS se utiliza para compilar y ejecutar su modelo. Está integrado nativamente con PyTorch y TensorFlow. De esta manera, no es necesario ejecutar una herramienta adicional. Utilice su código original, escrito en uno de estos marcos de ML, y con unos pocos cambios de líneas de código, ya está listo para funcionar con AWS Inferentia.
Veamos cómo compilar y ejecutar un modelo en AWS Inferentia1 y AWS Inferentia2 usando PyTorch.
Cargar un modelo pre-entrenado (ResNet 50) desde torchvision
Cargue un modelo pre-entrenado y ejecútelo una vez para calentarlo:
import torch
import torchvision
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
x = torch.rand(1,3,224,224).float().cpu() # entrada ficticia
y = model(x) # calentar el modeloRastrear e implementar el modelo acelerado en Inferentia1
Para rastrear el modelo en AWS Inferentia, importe torch_neuron e invoque la función de rastreo. Tenga en cuenta que el modelo necesita ser rastreable por PyTorch Jit para funcionar.
Al final del proceso de rastreo, guarde el modelo como un modelo normal de PyTorch. Compile el modelo una vez y cárguelo tantas veces como sea necesario. El tiempo de ejecución del SDK Neuron ya está integrado en PyTorch y es responsable de enviar automáticamente los operadores al chip AWS Inferentia1 para acelerar su modelo.
En su código de inferencia, siempre debe importar torch_neuron para activar el tiempo de ejecución integrado.
Puede pasar parámetros adicionales al compilador para personalizar la forma en que optimiza el modelo o para habilitar características especiales como neuron-pipeline-cores. Divida su modelo en varios núcleos para aumentar el rendimiento.
import torch_neuron
# Rastreo del modelo usando AWS NeuronSDK
neuron_model = torch_neuron.trace(model,x) # rastrear modelo en Inferentia
# Guardar para uso futuro
neuron_model.save('neuron_resnet50.pt')
# La próxima vez que no necesite rastrear el modelo nuevamente
# Simplemente cárguelo y AWS NeuronSDK lo enviará a Inferentia automáticamente
neuron_model = torch.jit.load('neuron_resnet50.pt')
# inferencia acelerada en Inferentia
y = neuron_model(x)Rastreo e implementación del modelo acelerado en Inferentia2
Para AWS Inferentia2, el proceso es similar. La única diferencia es que el paquete que importa termina con x: torch_neuronx. El SDK Neuron se encarga de la compilación y ejecución del modelo de forma transparente. También puede pasar parámetros adicionales al compilador para ajustar la operación o activar funcionalidades específicas.
import torch_neuronx
# Rastreo del modelo usando NeuronSDK
neuron_model = torch_neuronx.trace(model,x) # rastrear modelo en Inferentia
# Guardar para uso futuro
neuron_model.save('neuron_resnet50.pt')
# La próxima vez que no necesite rastrear el modelo nuevamente
# Simplemente cárguelo y NeuronSDK lo enviará a Inferentia automáticamente
neuron_model = torch.jit.load('neuron_resnet50.pt')
# inferencia acelerada en Inferentia
y = neuron_model(x)AWS Inferentia2 también ofrece un segundo enfoque para ejecutar un modelo llamado inferencia perezosa de tensor. En este modo, no rastrea ni compila el modelo previamente; en su lugar, el compilador se ejecuta sobre la marcha cada vez que ejecuta su código. No se recomienda para producción, dado que el modo rastreado tiene muchas ventajas sobre la inferencia perezosa de tensor. Sin embargo, si aún está desarrollando su modelo y necesita probarlo más rápido, la inferencia perezosa de tensor puede ser una buena alternativa. Así es como se compila y ejecuta un modelo usando Lazy Tensor:
import torch
import torchvision
import torch_neuronx
import torch_xla.core.xla_model as xm
device = xm.xla_device() # Crear dispositivo XLA
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
model.to(device)
x = torch.rand((1,3,224,224), device=device) # entrada ficticia
with torch.no_grad():
y = model(x)
xm.mark_step() # La compilación ocurre aquíAhora que está familiarizado con AWS Inferentia2, un buen próximo paso es comenzar con PyTorch o Tensorflow y aprender cómo configurar un entorno de desarrollo y ejecutar tutoriales y ejemplos. Además, consulte el repositorio de AWS Neuron Samples GitHub, donde puede encontrar varios ejemplos de cómo preparar modelos para ejecutarse en Inf2, Inf1 y Trn1.
Resumen de comparación de características entre AWS Inferentia1 y AWS Inferentia2
El compilador de AWS Inferentia2 está basado en XLA y AWS forma parte de la iniciativa OpenXLA. Esta es la mayor diferencia respecto a AWS Inferentia1 y es relevante porque PyTorch, TensorFlow y JAX tienen integraciones nativas con XLA. XLA trae muchas mejoras de rendimiento, ya que optimiza el gráfico para calcular los resultados en un solo lanzamiento de kernel. Fusiona operaciones de tensor sucesivas y produce código de máquina óptimo para acelerar las ejecuciones del modelo en AWS Inferentia2. Otras partes del SDK de Neuron también fueron mejoradas en AWS Inferentia2, manteniendo la experiencia del usuario lo más simple posible mientras se rastrean y ejecutan los modelos. La siguiente tabla muestra las características disponibles en ambas versiones del compilador y tiempo de ejecución.
| Característica | torch-neuron | torch-neuronx |
| Tensorboard | Sí | Sí |
| Instancias compatibles | Inf1 | Inf2 y Trn1 |
| Soporte para inferencia | Sí | Sí |
| Soporte para entrenamiento | No | Sí |
| Arquitectura | NeuronCore-v1 | NeuronCore-v2 |
| API de rastreo | torch_neuron.trace() | torch_neuronx.trace() |
| Inferencia distribuida | NeuronCore Pipeline | Comunicaciones Colectivas |
| IR | GraphDef | HLO |
| Compilador | neuron-cc | neuronx-cc |
| Monitoreo | neuron-monitor / monitor-top | neuron-monitor / monitor-top |
Para una comparación más detallada entre torch-neuron (Inf1) y torch-neuronx (Inf2 y Trn1), consulte la Comparación de torch-neuron (Inf1) versus torch-neuronx (Inf2 y Trn1) para inferencia.
Servicio de modelos
Después de rastrear un modelo para implementar en Inf2, tiene muchas opciones de implementación. Puede ejecutar predicciones en tiempo real o en lotes de diferentes formas. Inf2 está disponible porque las instancias de EC2 están integradas de forma nativa a otros servicios de AWS que hacen uso de Contenedores de Aprendizaje Profundo (DLCs) como Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS) y SageMaker.
AWS Inferentia2 es compatible con las tecnologías de implementación más populares. Aquí hay una lista de algunas de las opciones que tiene para implementar modelos utilizando AWS Inferentia2:
- SageMaker: Servicio completamente administrado para preparar datos y construir, entrenar e implementar modelos de ML
- TorchServe: Mecanismo de implementación integrado en PyTorch
- TensorFlow Serving: Mecanismo de implementación integrado en TensorFlow
- Deep Java Library: Mecanismo de código abierto de Java para implementación y entrenamiento de modelos
- Triton: Servicio de código abierto de NVIDIA para implementación de modelos
Benchmarks
La siguiente tabla destaca las mejoras que AWS Inferentia2 ofrece sobre AWS Inferentia1. Específicamente, medimos la latencia (cuán rápido el modelo puede hacer una predicción usando cada acelerador), el rendimiento (cuántas inferencias por segundo) y el costo por inferencia (cuánto cuesta cada inferencia en dólares estadounidenses). Cuanto menor sea la latencia en milisegundos y los costos en dólares estadounidenses, mejor será. Cuanto mayor sea el rendimiento, mejor.
Se utilizaron dos modelos en este proceso, ambos grandes modelos de lenguaje: ELECTRA large discriminator y BERT large uncased. PyTorch (1.13.1) y Hugging Face transformers (v4.7.0), las principales bibliotecas utilizadas en este experimento, se ejecutaron en Python 3.8. Después de compilar los modelos para el tamaño del lote = 1 y 10 (usando el código de la sección anterior como referencia), cada modelo se calentó (invocado una vez para inicializar el contexto) y luego se invocó 10 veces seguidas. La siguiente tabla muestra los números promedio recopilados en este simple benchmark.
- Discriminador grande ELECTRA (334,092,288 parámetros ~593 MB)
- Bert grande sin mayúsculas (335,143,938 parámetros ~580 MB)
- OPT-66B (66 mil millones de parámetros ~124 GB)
| Nombre del modelo | Tamaño de lote | Longitud de la oración | Latencia (ms) | Mejoras Inf2 sobre Inf1 (x veces) | Rendimiento (inferencias por segundo) | Costo por inferencia (EC2 us-east-1) ** | |||
| Inf1 | Inf2 | Inf1 | Inf2 | Inf1 | Inf2 | ||||
| Discriminador grande ELECTRA | 1 | 256 | 35,7 | 8,31 | 4,30 | 28,01 | 120,34 | $0.0000023 | $0.0000018 |
| Discriminador grande ELECTRA | 10 | 256 | 343,7 | 72,9 | 4,71 | 2,91 | 13,72 | $0.0000022 | $0.0000015 |
| Bert grande sin mayúsculas | 1 | 128 | 28,2 | 3,1 | 9,10 | 35,46 | 322,58 | $0.0000018 | $0.0000007 |
| Bert grande sin mayúsculas | 10 | 128 | 121,1 | 23,6 | 5,13 | 8,26 | 42,37 | $0.0000008 | $0.0000005 |
* Se utilizó el tipo de instancia c6a.8xlarge con 32 AMD Epyc 7313 CPU en esta prueba de referencia.
** Precios públicos de EC2 en us-east-1 el 20 de abril: inf2.xlarge: $0.7582/hr; inf1.xlarge: $0.228/hr. El costo por inferencia considera el costo por elemento en un lote. (El costo por inferencia equivale al costo total de la invocación del modelo/tamaño del lote.)
Para obtener información adicional sobre el rendimiento de entrenamiento e inferencia, consulte Trn1/Trn1n Performance.
Conclusión
AWS Inferentia2 es una tecnología potente diseñada para mejorar el rendimiento y reducir los costos de la inferencia de modelos de aprendizaje profundo. Más eficiente que AWS Inferentia1, ofrece hasta 4 veces más rendimiento, hasta 10 veces menos latencia y hasta un 50% mejor rendimiento por vatio que otras instancias de EC2 optimizadas para inferencia comparables. Al final, pagas menos, tienes una aplicación más rápida y cumples tus objetivos de sostenibilidad.
Es fácil y sencillo migrar tu código de inferencia a AWS Inferentia2, que también admite una variedad más amplia de modelos, incluidos los modelos de lenguaje grandes y los modelos fundamentales para la inteligencia artificial generativa.
Puedes empezar siguiendo la documentación del SDK de Neuron de AWS para configurar un entorno de desarrollo y empezar tu proyecto de aprendizaje profundo acelerado. Para ayudarte a empezar, Hugging Face ha añadido soporte de Neuron a su librería Optimum, que optimiza modelos para un entrenamiento e inferencia más rápido, y tiene muchas tareas de ejemplo listas para ejecutar en Inf2. Además, consulta nuestro tutorial Deploy large language models on AWS Inferentia2 using large model inference containers para aprender a desplegar LLM en AWS Inferentia2 usando contenedores de inferencia de modelos. Para obtener ejemplos adicionales, consulta el repositorio de AWS Neuron Samples en GitHub.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Los efectos de ChatGPT en las escuelas y por qué está siendo prohibido.
- Explorando los Beneficios y Desventajas de Integrar ChatGPT en el Cuidado de la Salud
- Arte generado por IA las implicaciones éticas y los debates
- Crear un panel de análisis de ratios de series de tiempo.
- Aumento de personal de TI Cómo la IA está cambiando la industria del desarrollo de software.
- Las 10 mejores herramientas para detectar ChatGPT, GPT-4, Bard y Claude.
- Conviértete en Ingeniero de ML con Declarative ML






