Apilando nuestro camino hacia robots más generales
Avanzando hacia robots más versátiles mediante apilamiento
Presentando RGB-Stacking como un nuevo punto de referencia para la manipulación robótica basada en visión
Recoger un palo y equilibrarlo en la parte superior de un tronco o apilar una piedra sobre otra puede parecer acciones simples, y bastante similares, para una persona. Sin embargo, la mayoría de los robots tienen dificultades para manejar más de una tarea de este tipo a la vez. Manipular un palo requiere un conjunto de comportamientos diferentes a apilar piedras, y mucho menos apilar platos diferentes uno encima del otro o ensamblar muebles. Antes de poder enseñar a los robots cómo realizar este tipo de tareas, primero deben aprender a interactuar con una gama mucho mayor de objetos. Como parte de la misión de DeepMind y como un paso hacia la creación de robots más generalizables y útiles, estamos explorando cómo permitir que los robots comprendan mejor las interacciones de los objetos con geometrías diversas.
En un artículo que se presentará en CoRL 2021 (Conferencia sobre Aprendizaje de Robots) y que ya está disponible como preimpresión en OpenReview, presentamos RGB-Stacking como un nuevo punto de referencia para la manipulación robótica basada en visión. En este punto de referencia, un robot debe aprender a agarrar diferentes objetos y equilibrarlos uno encima del otro. Lo que distingue nuestra investigación de trabajos anteriores es la diversidad de objetos utilizados y el gran número de evaluaciones empíricas realizadas para validar nuestros hallazgos. Nuestros resultados demuestran que se puede utilizar una combinación de simulación y datos del mundo real para aprender la manipulación de múltiples objetos complejos y sugieren una línea base sólida para el problema abierto de generalizar a objetos nuevos. Para apoyar a otros investigadores, estamos compartiendo de forma abierta una versión de nuestro entorno simulado, y publicando los diseños para construir nuestro entorno de apilamiento RGB de robot reales, junto con los modelos de objetos RGB e información para imprimirlos en 3D. También estamos compartiendo de forma abierta una colección de bibliotecas y herramientas utilizadas en nuestra investigación en robótica de manera más amplia.
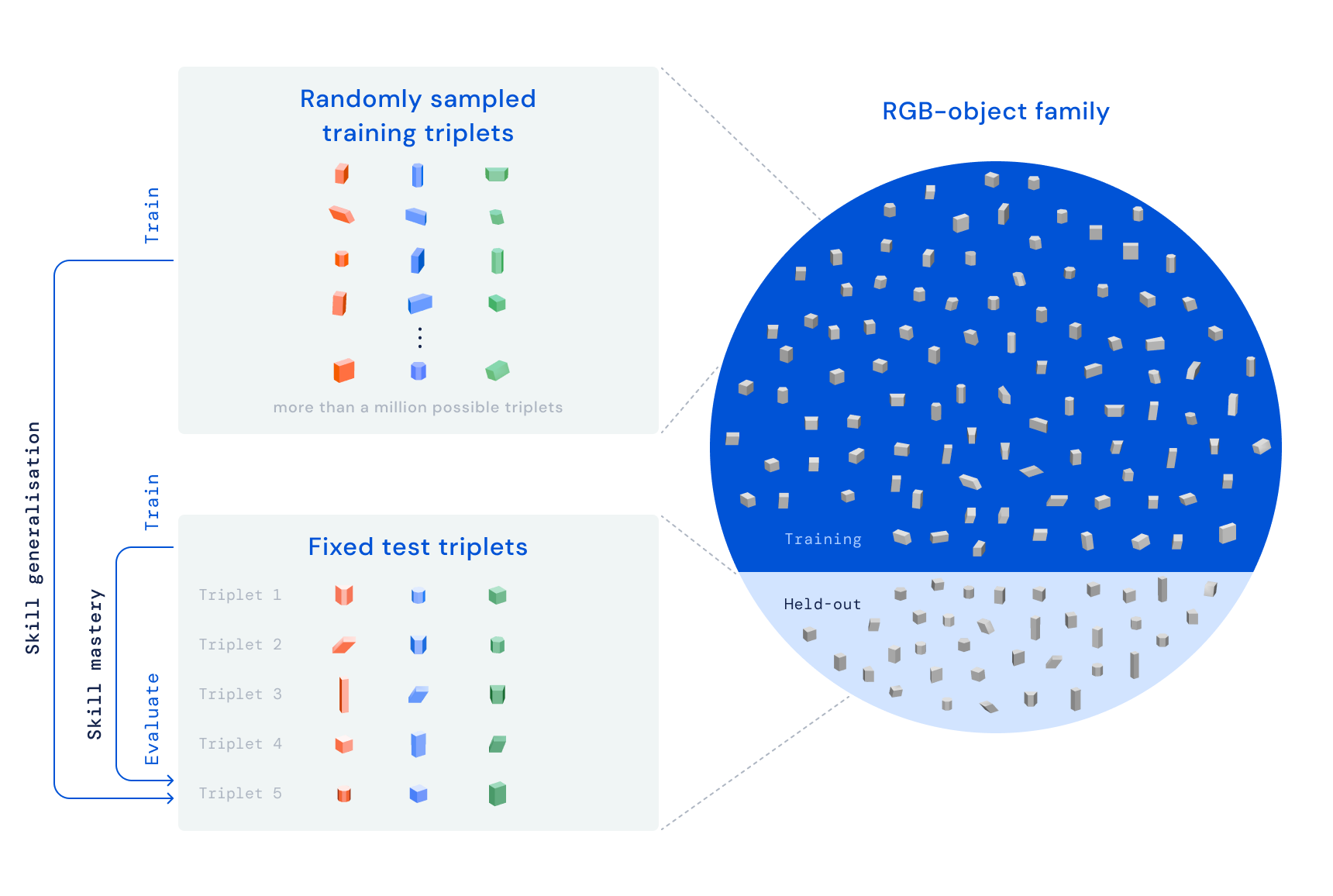
Con RGB-Stacking, nuestro objetivo es entrenar un brazo robótico mediante aprendizaje por refuerzo para apilar objetos de diferentes formas. Colocamos un agarrador paralelo conectado a un brazo de robot sobre una cesta, y tres objetos en la cesta: uno rojo, uno verde y uno azul, de ahí el nombre RGB. La tarea es simple: apilar el objeto rojo encima del objeto azul en un plazo de 20 segundos, mientras que el objeto verde sirve como obstáculo y distracción. El proceso de aprendizaje garantiza que el agente adquiera habilidades generalizadas mediante el entrenamiento en múltiples conjuntos de objetos. Variamos intencionalmente las capacidades de agarre y apilamiento, es decir, las cualidades que definen cómo el agente puede agarrar y apilar cada objeto. Este principio de diseño obliga al agente a exhibir comportamientos que van más allá de una estrategia simple de recoger y colocar.

Nuestro punto de referencia RGB-Stacking incluye dos versiones de tareas con diferentes niveles de dificultad. En “Maestría de habilidades”, nuestro objetivo es entrenar a un solo agente que sea hábil en apilar un conjunto predefinido de cinco ternas. En “Generalización de habilidades”, utilizamos las mismas ternas para la evaluación, pero entrenamos al agente en un gran conjunto de objetos de entrenamiento, que suman más de un millón de ternas posibles. Para probar la generalización, estos objetos de entrenamiento excluyen la familia de objetos de la cual se eligieron las ternas de prueba. En ambas versiones, dividimos nuestro proceso de aprendizaje en tres etapas:
- Desafíos del mundo real para la IA Generalizada (AGI)
- Sobre la Expresividad de las Recompensas de Markov
- Mejorando modelos de lenguaje mediante la recuperación de billones de tokens.
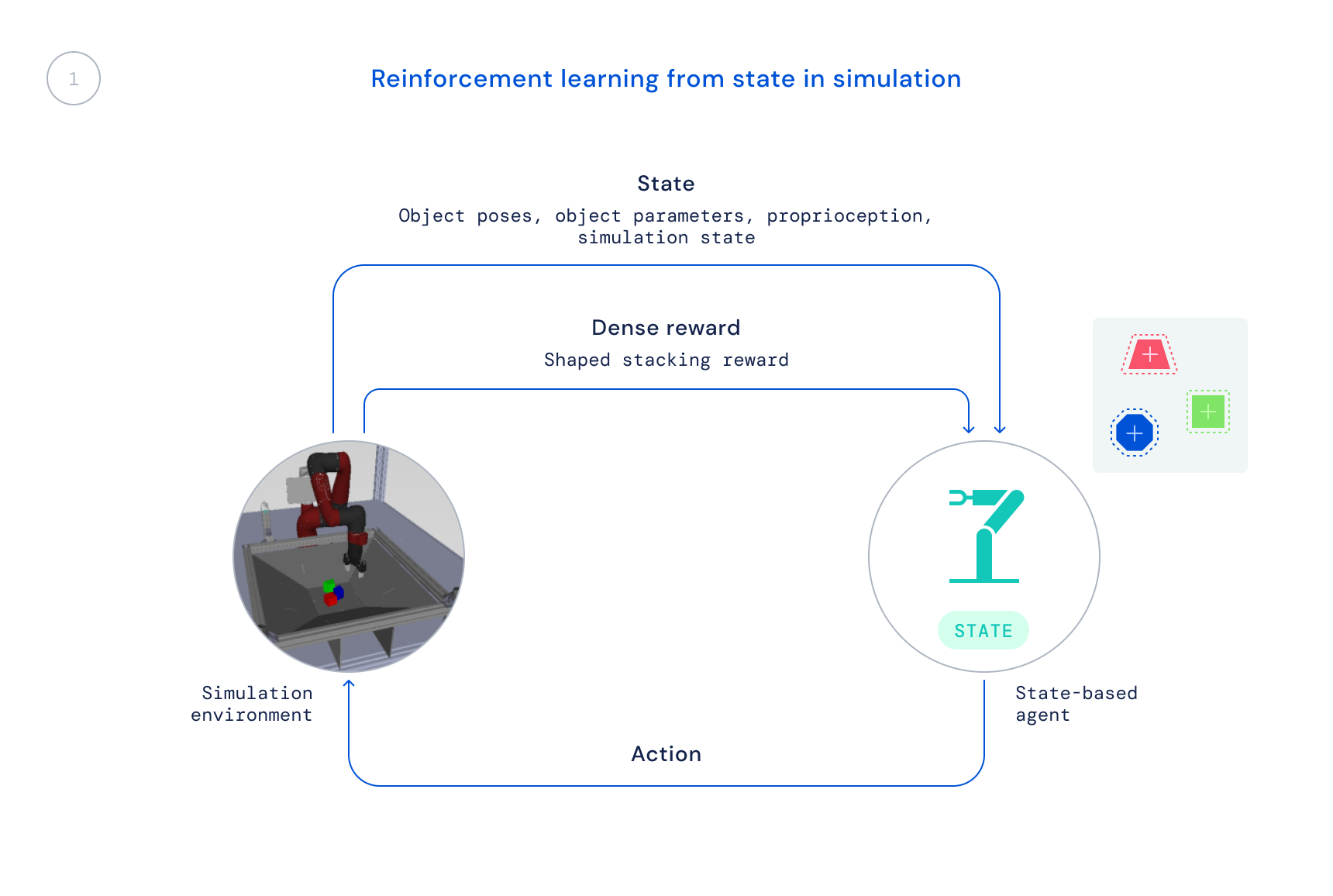
- Primero, nos entrenamos en simulación utilizando un algoritmo RL predefinido: Optimización de Política Máxima a Posteriori (MPO). En esta etapa, utilizamos el estado del simulador, lo que permite un entrenamiento rápido ya que las posiciones de los objetos se proporcionan directamente al agente en lugar de que el agente tenga que aprender a encontrar los objetos en las imágenes. La política resultante no es directamente transferible al robot real ya que esta información no está disponible en el mundo real.
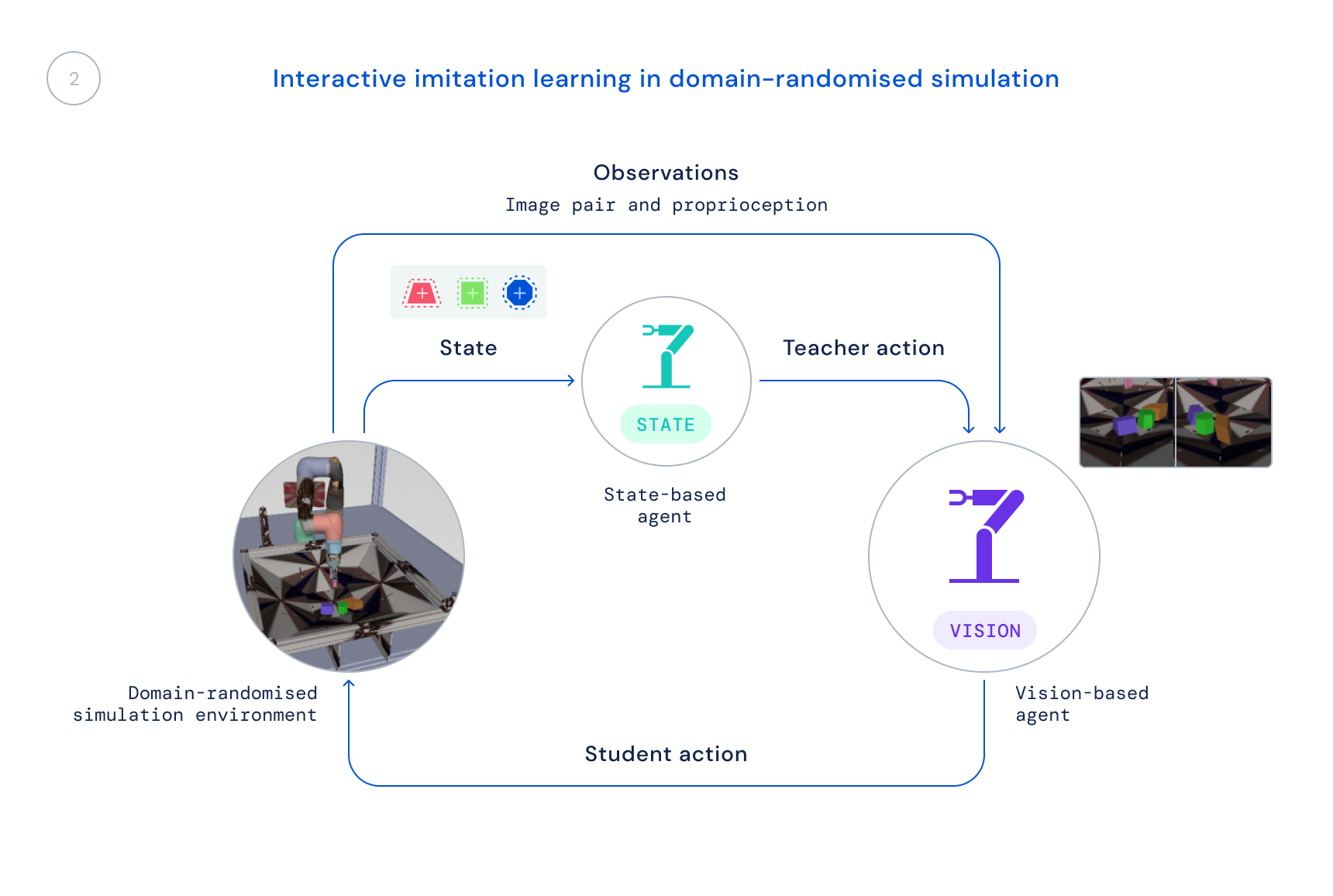
- A continuación, entrenamos una nueva política en simulación que utiliza solo observaciones realistas: imágenes y el estado propioceptivo del robot. Utilizamos una simulación con dominio aleatorizado para mejorar la transferencia a imágenes y dinámicas del mundo real. La política de estado sirve como profesor, proporcionando al agente de aprendizaje correcciones a sus comportamientos, y esas correcciones se destilan en la nueva política.
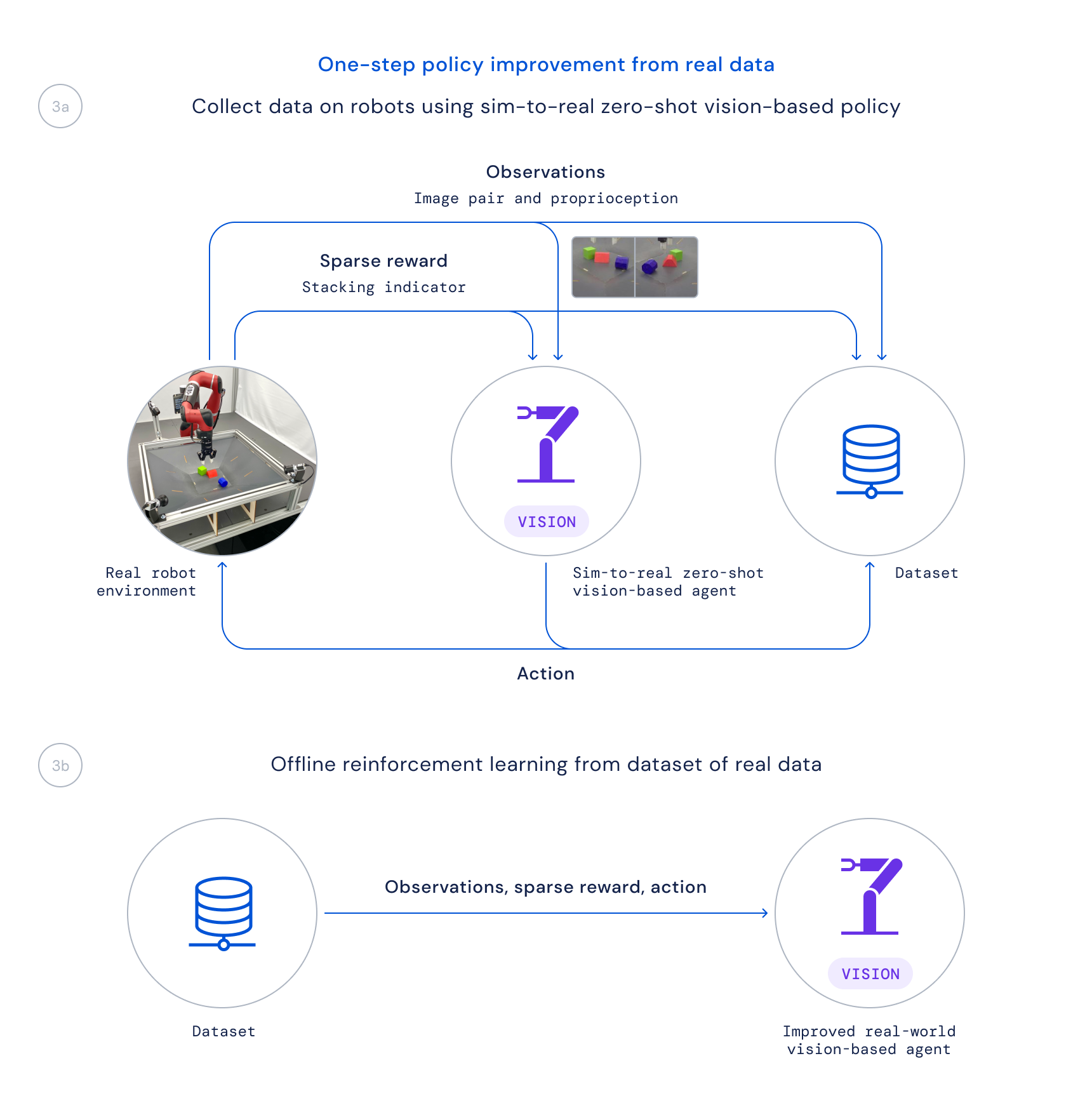
- Por último, recopilamos datos utilizando esta política en robots reales y entrenamos una política mejorada a partir de estos datos fuera de línea, dando más peso a las transiciones buenas basadas en una función Q aprendida, como se hace en la Regresión Regularizada del Crítico (CRR). Esto nos permite utilizar los datos que se recopilan de manera pasiva durante el proyecto en lugar de ejecutar un algoritmo de entrenamiento en línea que consume mucho tiempo en los robots reales.
La desvinculación de nuestro proceso de aprendizaje de esta manera resulta crucial por dos razones principales. En primer lugar, nos permite resolver el problema en su totalidad, ya que simplemente llevaría demasiado tiempo si tuviéramos que empezar desde cero directamente con los robots. En segundo lugar, aumenta nuestra velocidad de investigación, ya que diferentes personas de nuestro equipo pueden trabajar en diferentes partes del proceso antes de combinar estos cambios para una mejora general.

En los últimos años, se ha trabajado mucho en la aplicación de algoritmos de aprendizaje para resolver problemas difíciles de manipulación de robots reales a gran escala, pero el enfoque de dicho trabajo ha sido principalmente en tareas como agarrar, empujar u otras formas de manipular objetos individuales. El enfoque de RGB-Stacking que describimos en nuestro artículo, junto con nuestros recursos de robótica ahora disponibles en GitHub, resulta en estrategias sorprendentes de apilamiento y dominio del apilamiento de un subconjunto de estos objetos. Sin embargo, este paso solo rasca la superficie de lo que es posible, y el desafío de la generalización aún no está totalmente resuelto. A medida que los investigadores sigan trabajando para resolver el desafío abierto de la verdadera generalización en la robótica, esperamos que este nuevo punto de referencia, junto con el entorno, los diseños y las herramientas que hemos lanzado, contribuyan a nuevas ideas y métodos que faciliten aún más la manipulación y hagan que los robots sean más capaces.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Modelado del lenguaje a gran escala Gopher, consideraciones éticas y recuperación
- La normatividad espuria mejora el aprendizaje del comportamiento de cumplimiento y aplicación en agentes artificiales.
- Modelos de Lenguaje de Red Teaming con Modelos de Lenguaje
- El primer paso de MuZero de la investigación al mundo real.
- Acelerando la ciencia de la fusión a través del control de plasma aprendido
- Prediciendo el pasado con Ithaca
- GopherCite Enseñando a los modelos de lenguaje a respaldar respuestas con citas verificadas






